 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
Dec 13, 2019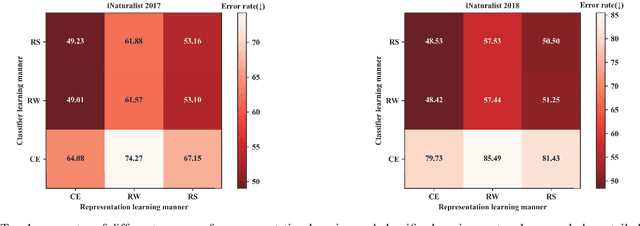

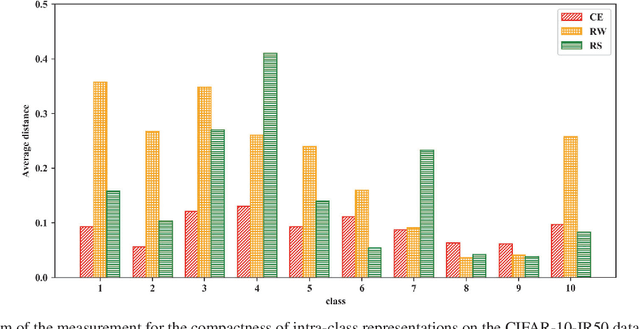
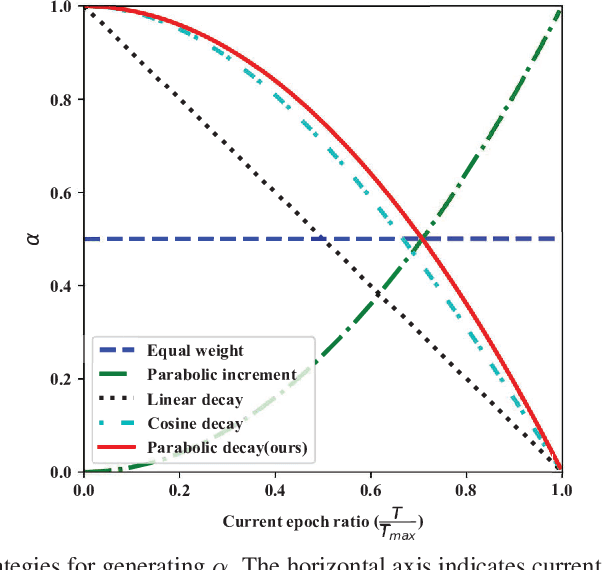
Our work focuses on tackling the challenging but natural visual recognition task of long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples). In the literature, class re-balancing strategies (e.g., re-weighting and re-sampling) are the prominent and effective methods proposed to alleviate the extreme imbalance for dealing with long-tailed problems. In this paper, we firstly discover that these re-balancing methods achieving satisfactory recognition accuracy owes to that they could significantly promote the classifier learning of deep networks. However, at the same time, they will unexpectedly damage the representative ability of the learned deep features to some extent. Therefore, we propose a unified Bilateral-Branch Network (BBN) to take care of both representation learning and classifier learning simultaneously, where each branch does perform its own duty separately. In particular, our BBN model is further equipped with a novel cumulative learning strategy, which is designed to first learn the universal patterns and then pay attention to the tail data gradually. Extensive experiments on four benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed BBN can significantly outperform state-of-the-art methods. Furthermore, validation experiments can demonstrate both our preliminary discovery and effectiveness of tailored designs in BBN for long-tailed problems. Our method won the first place in the iNaturalist 2019 large scale species classification competition, and our code is open-source and available at https://github.com/Megvii-Nanjing/BBN.
Deep Learning for Fine-Grained Image Analysis: A Survey
Jul 06, 2019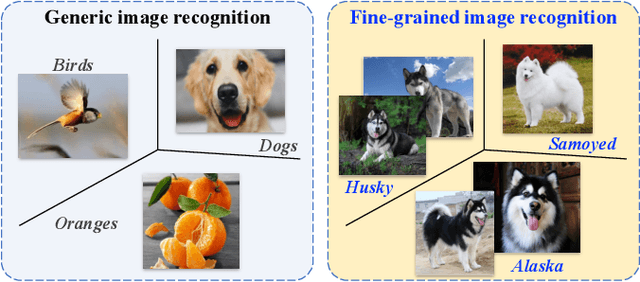
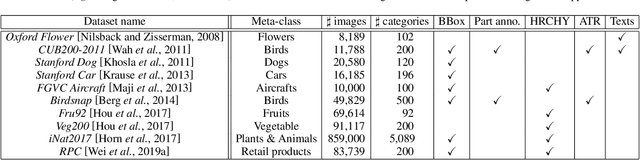
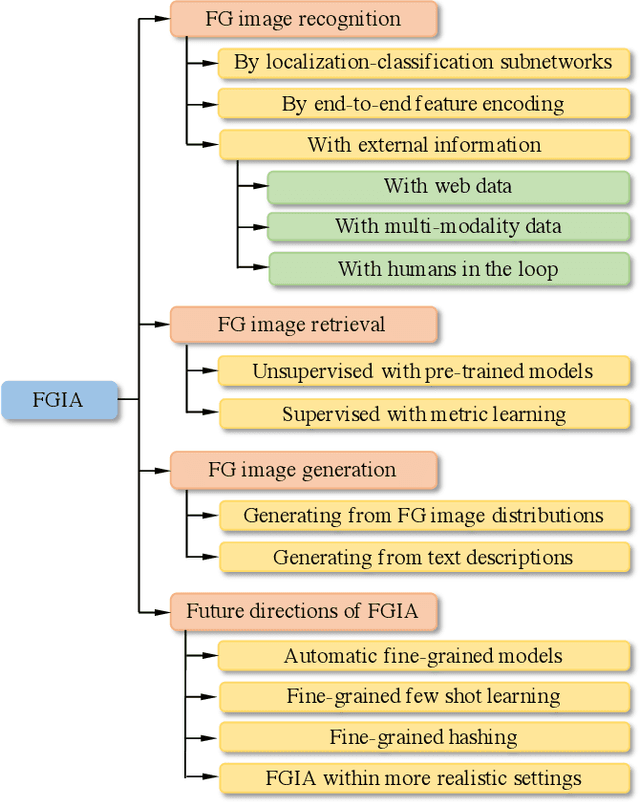

Computer vision (CV) is the process of using machines to understand and analyze imagery, which is an integral branch of artificial intelligence. Among various research areas of CV, fine-grained image analysis (FGIA) is a longstanding and fundamental problem, and has become ubiquitous in diverse real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, \eg, species of birds or models of cars. The small inter-class variations and the large intra-class variations caused by the fine-grained nature makes it a challenging problem. During the booming of deep learning, recent years have witnessed remarkable progress of FGIA using deep learning techniques. In this paper, we aim to give a survey on recent advances of deep learning based FGIA techniques in a systematic way. Specifically, we organize the existing studies of FGIA techniques into three major categories: fine-grained image recognition, fine-grained image retrieval and fine-grained image generation. In addition, we also cover some other important issues of FGIA, such as publicly available benchmark datasets and its related domain specific applications. Finally, we conclude this survey by highlighting several directions and open problems which need be further explored by the community in the future.
Multi-Label Image Recognition with Graph Convolutional Networks
Apr 07, 2019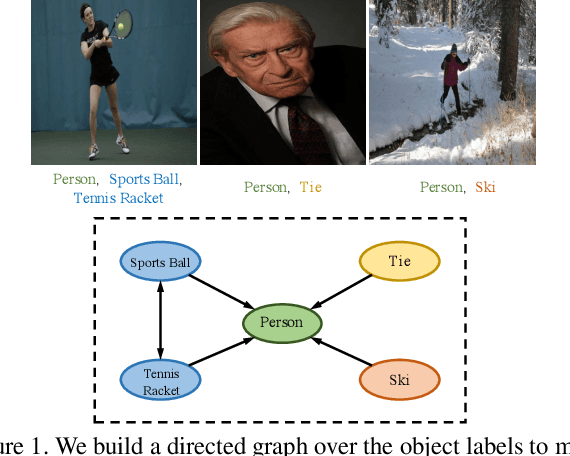
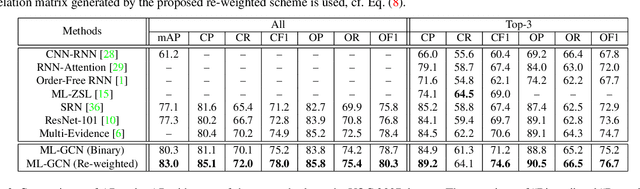
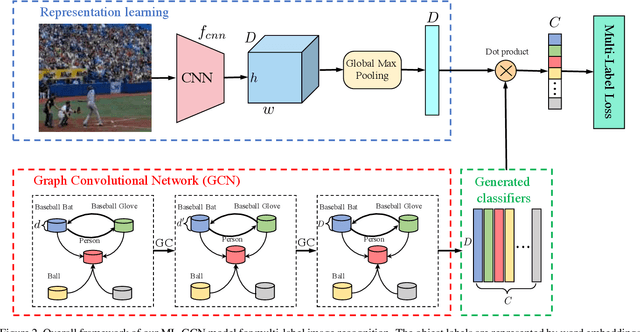
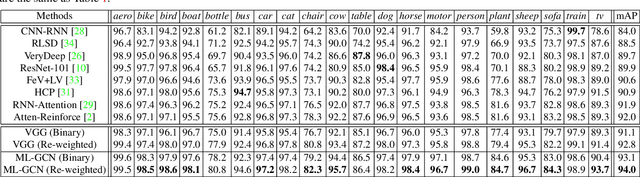
The task of multi-label image recognition is to predict a set of object labels that present in an image. As objects normally co-occur in an image, it is desirable to model the label dependencies to improve the recognition performance. To capture and explore such important dependencies, we propose a multi-label classification model based on Graph Convolutional Network (GCN). The model builds a directed graph over the object labels, where each node (label) is represented by word embeddings of a label, and GCN is learned to map this label graph into a set of inter-dependent object classifiers. These classifiers are applied to the image descriptors extracted by another sub-net, enabling the whole network to be end-to-end trainable. Furthermore, we propose a novel re-weighted scheme to create an effective label correlation matrix to guide information propagation among the nodes in GCN. Experiments on two multi-label image recognition datasets show that our approach obviously outperforms other existing state-of-the-art methods. In addition, visualization analyses reveal that the classifiers learned by our model maintain meaningful semantic topology.
RPC: A Large-Scale Retail Product Checkout Dataset
Jan 22, 2019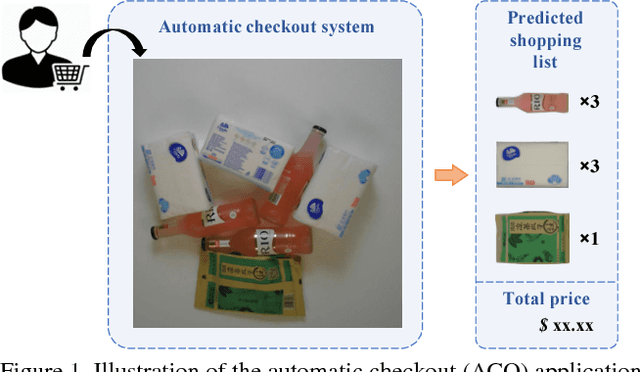
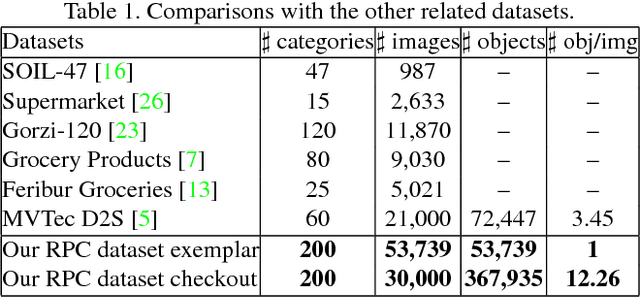
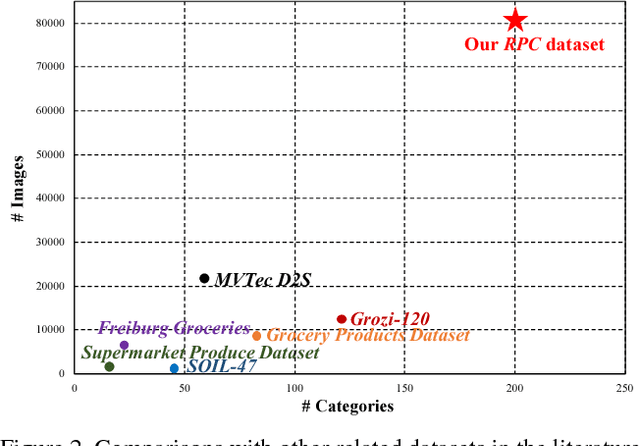

Over recent years, emerging interest has occurred in integrating computer vision technology into the retail industry. Automatic checkout (ACO) is one of the critical problems in this area which aims to automatically generate the shopping list from the images of the products to purchase. The main challenge of this problem comes from the large scale and the fine-grained nature of the product categories as well as the difficulty for collecting training images that reflect the realistic checkout scenarios due to continuous update of the products. Despite its significant practical and research value, this problem is not extensively studied in the computer vision community, largely due to the lack of a high-quality dataset. To fill this gap, in this work we propose a new dataset to facilitate relevant research. Our dataset enjoys the following characteristics: (1) It is by far the largest dataset in terms of both product image quantity and product categories. (2) It includes single-product images taken in a controlled environment and multi-product images taken by the checkout system. (3) It provides different levels of annotations for the check-out images. Comparing with the existing datasets, ours is closer to the realistic setting and can derive a variety of research problems. Besides the dataset, we also benchmark the performance on this dataset with various approaches. The dataset and related resources can be found at \url{https://rpc-dataset.github.io/}.
Coarse-to-fine: A RNN-based hierarchical attention model for vehicle re-identification
Dec 11, 2018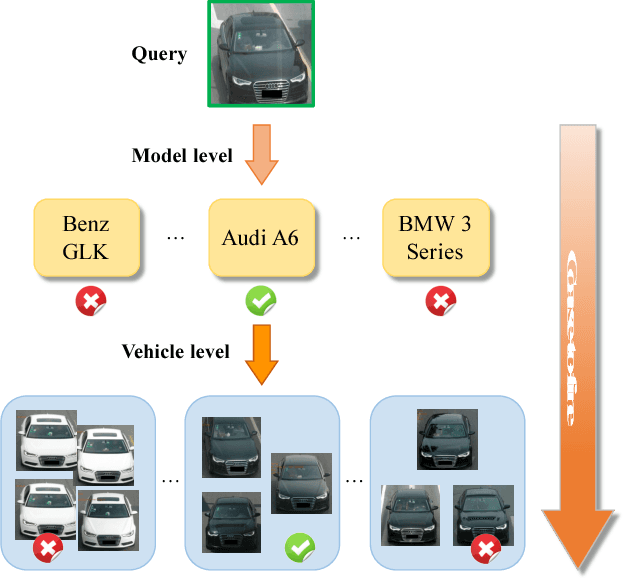

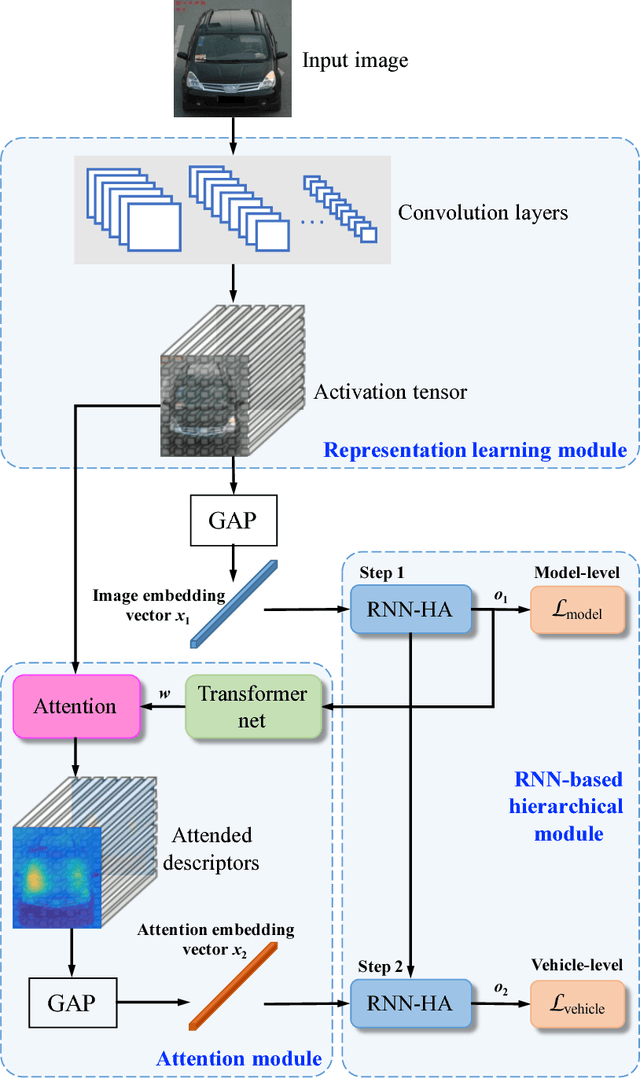
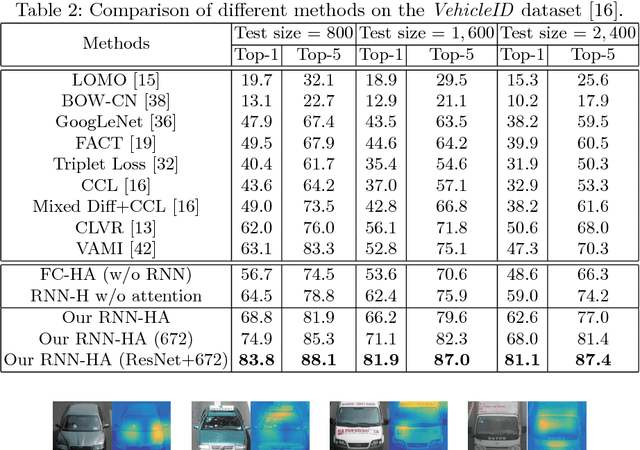
Vehicle re-identification is an important problem and becomes desirable with the rapid expansion of applications in video surveillance and intelligent transportation. By recalling the identification process of human vision, we are aware that there exists a native hierarchical dependency when humans identify different vehicles. Specifically, humans always firstly determine one vehicle's coarse-grained category, i.e., the car model/type. Then, under the branch of the predicted car model/type, they are going to identify specific vehicles by relying on subtle visual cues, e.g., customized paintings and windshield stickers, at the fine-grained level. Inspired by the coarse-to-fine hierarchical process, we propose an end-to-end RNN-based Hierarchical Attention (RNN-HA) classification model for vehicle re-identification. RNN-HA consists of three mutually coupled modules: the first module generates image representations for vehicle images, the second hierarchical module models the aforementioned hierarchical dependent relationship, and the last attention module focuses on capturing the subtle visual information distinguishing specific vehicles from each other. By conducting comprehensive experiments on two vehicle re-identification benchmark datasets VeRi and VehicleID, we demonstrate that the proposed model achieves superior performance over state-of-the-art methods.
Adversarial Learning of Structure-Aware Fully Convolutional Networks for Landmark Localization
Nov 02, 2018
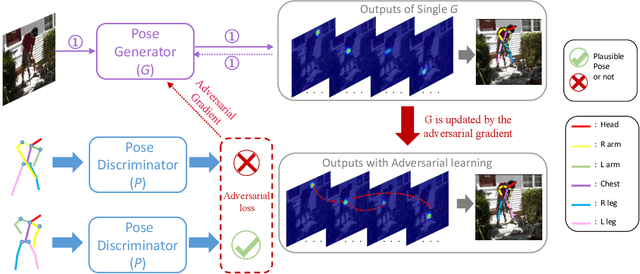
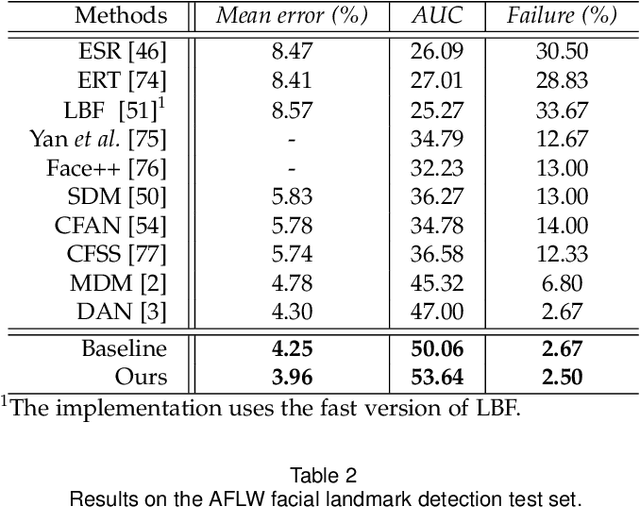
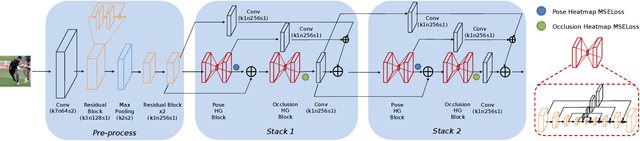
Landmark/pose estimation in single monocular images have received much effort in computer vision due to its important applications. It remains a challenging task when input images severe occlusions caused by, e.g., adverse camera views. Under such circumstances, biologically implausible pose predictions may be produced. In contrast, human vision is able to predict poses by exploiting geometric constraints of landmark point inter-connectivity. To address the problem, by incorporating priors about the structure of pose components, we propose a novel structure-aware fully convolutional network to implicitly take such priors into account during training of the deep network. Explicit learning of such constraints is typically challenging. Instead, inspired by how human identifies implausible poses, we design discriminators to distinguish the real poses from the fake ones (such as biologically implausible ones). If the pose generator G generates results that the discriminator fails to distinguish from real ones, the network successfully learns the priors. Training of the network follows the strategy of conditional Generative Adversarial Networks (GANs). The effectiveness of the proposed network is evaluated on three pose-related tasks: 2D single human pose estimation, 2D facial landmark estimation and 3D single human pose estimation. The proposed approach significantly outperforms the state-of-the-art methods and almost always generates plausible pose predictions, demonstrating the usefulness of implicit learning of structures using GANs.
Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples
May 11, 2018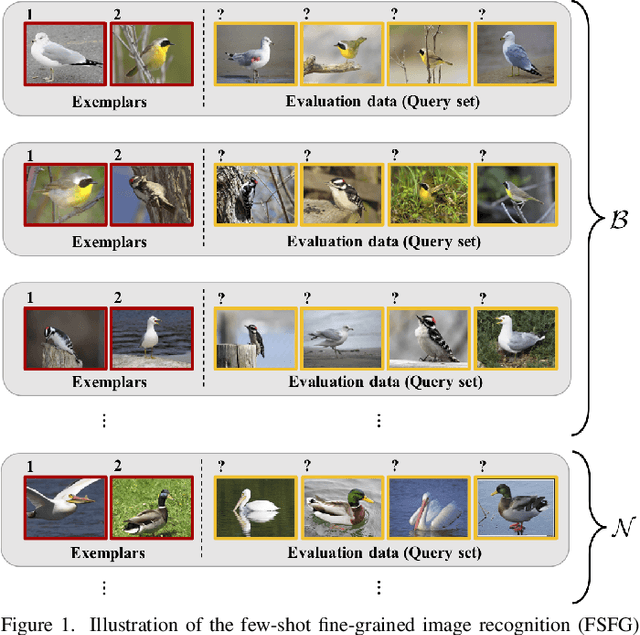
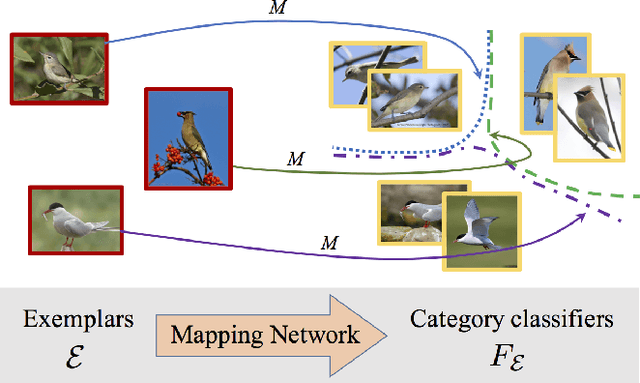
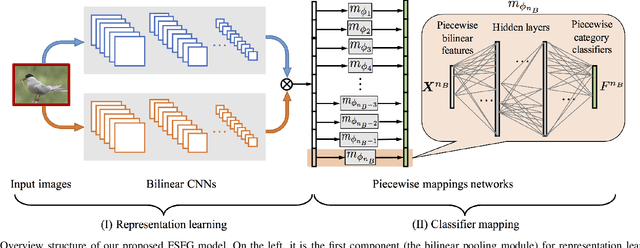

Humans are capable of learning a new fine-grained concept with very little supervision, e.g., few exemplary images for a species of bird, yet our best deep learning systems need hundreds or thousands of labeled examples. In this paper, we try to reduce this gap by studying the fine-grained image recognition problem in a challenging few-shot learning setting, termed few-shot fine-grained recognition (FSFG). The task of FSFG requires the learning systems to build classifiers for novel fine-grained categories from few examples (only one or less than five). To solve this problem, we propose an end-to-end trainable deep network which is inspired by the state-of-the-art fine-grained recognition model and is tailored for the FSFG task. Specifically, our network consists of a bilinear feature learning module and a classifier mapping module: while the former encodes the discriminative information of an exemplar image into a feature vector, the latter maps the intermediate feature into the decision boundary of the novel category. The key novelty of our model is a "piecewise mappings" function in the classifier mapping module, which generates the decision boundary via learning a set of more attainable sub-classifiers in a more parameter-economic way. We learn the exemplar-to-classifier mapping based on an auxiliary dataset in a meta-learning fashion, which is expected to be able to generalize to novel categories. By conducting comprehensive experiments on three fine-grained datasets, we demonstrate that the proposed method achieves superior performance over the competing baselines.
Unsupervised Object Discovery and Co-Localization by Deep Descriptor Transforming
Jul 20, 2017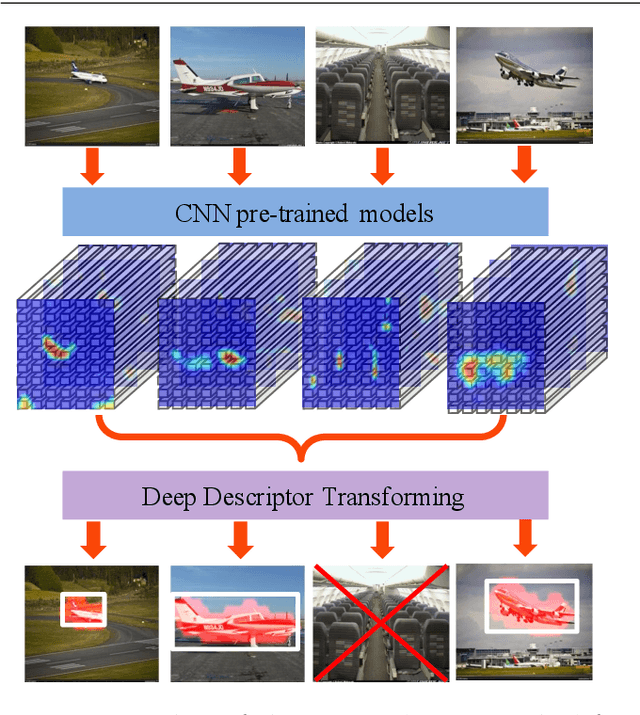
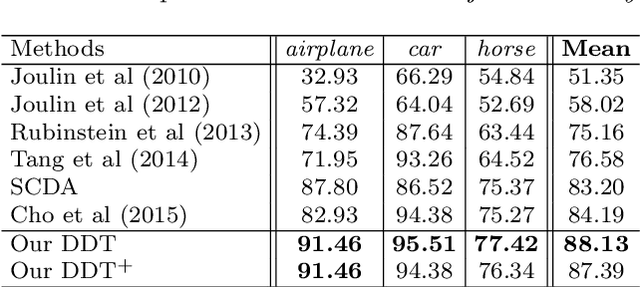
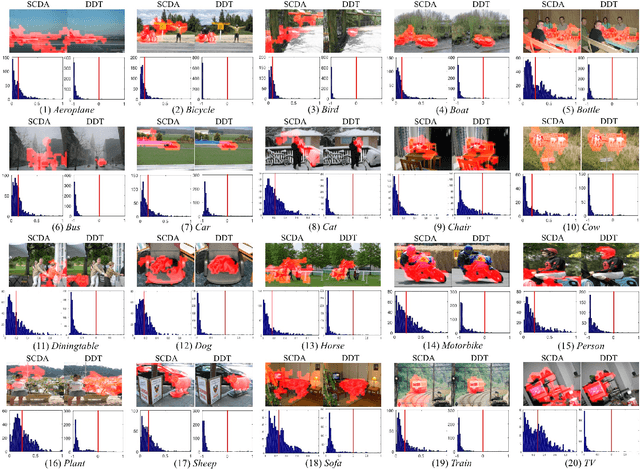

Reusable model design becomes desirable with the rapid expansion of computer vision and machine learning applications. In this paper, we focus on the reusability of pre-trained deep convolutional models. Specifically, different from treating pre-trained models as feature extractors, we reveal more treasures beneath convolutional layers, i.e., the convolutional activations could act as a detector for the common object in the image co-localization problem. We propose a simple yet effective method, termed Deep Descriptor Transforming (DDT), for evaluating the correlations of descriptors and then obtaining the category-consistent regions, which can accurately locate the common object in a set of unlabeled images, i.e., unsupervised object discovery. Empirical studies validate the effectiveness of the proposed DDT method. On benchmark image co-localization datasets, DDT consistently outperforms existing state-of-the-art methods by a large margin. Moreover, DDT also demonstrates good generalization ability for unseen categories and robustness for dealing with noisy data. Beyond those, DDT can be also employed for harvesting web images into valid external data sources for improving performance of both image recognition and object detection.
Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
Jul 13, 2017
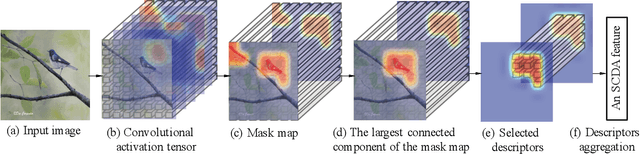


Deep convolutional neural network models pre-trained for the ImageNet classification task have been successfully adopted to tasks in other domains, such as texture description and object proposal generation, but these tasks require annotations for images in the new domain. In this paper, we focus on a novel and challenging task in the pure unsupervised setting: fine-grained image retrieval. Even with image labels, fine-grained images are difficult to classify, let alone the unsupervised retrieval task. We propose the Selective Convolutional Descriptor Aggregation (SCDA) method. SCDA firstly localizes the main object in fine-grained images, a step that discards the noisy background and keeps useful deep descriptors. The selected descriptors are then aggregated and dimensionality reduced into a short feature vector using the best practices we found. SCDA is unsupervised, using no image label or bounding box annotation. Experiments on six fine-grained datasets confirm the effectiveness of SCDA for fine-grained image retrieval. Besides, visualization of the SCDA features shows that they correspond to visual attributes (even subtle ones), which might explain SCDA's high mean average precision in fine-grained retrieval. Moreover, on general image retrieval datasets, SCDA achieves comparable retrieval results with state-of-the-art general image retrieval approaches.
Deep Descriptor Transforming for Image Co-Localization
May 08, 2017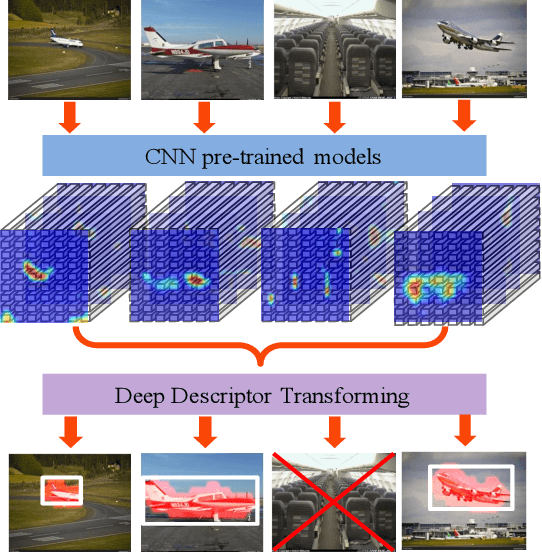
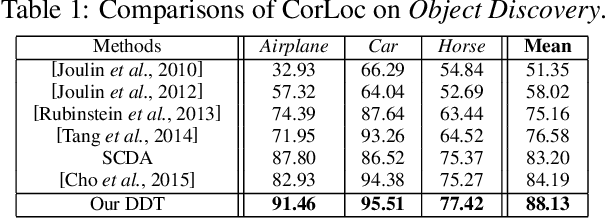
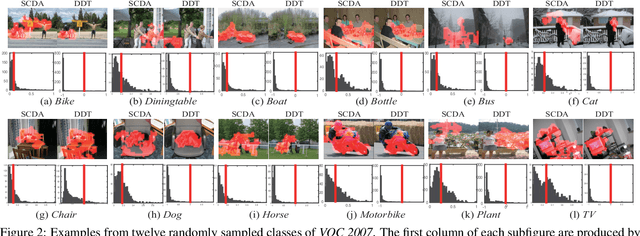

Reusable model design becomes desirable with the rapid expansion of machine learning applications. In this paper, we focus on the reusability of pre-trained deep convolutional models. Specifically, different from treating pre-trained models as feature extractors, we reveal more treasures beneath convolutional layers, i.e., the convolutional activations could act as a detector for the common object in the image co-localization problem. We propose a simple but effective method, named Deep Descriptor Transforming (DDT), for evaluating the correlations of descriptors and then obtaining the category-consistent regions, which can accurately locate the common object in a set of images. Empirical studies validate the effectiveness of the proposed DDT method. On benchmark image co-localization datasets, DDT consistently outperforms existing state-of-the-art methods by a large margin. Moreover, DDT also demonstrates good generalization ability for unseen categories and robustness for dealing with noisy data.