 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
Jun 01, 2026Parameter-efficient fine-tuning (PEFT) is usually treated as a cheaper alternative to full fine-tuning. We study a broader role: small trainable adapters as persistent local state on top of strong shared foundation models. In this framing, the base model provides shared competence while adapters carry instance-specific behavior such as preferences, skills, tool habits, and memory-like updates. We organize the problem around three scaling axes: Scale Up, where stronger shared priors make small local updates more useful; Scale Down, where we study how small adapters can be while remaining reliable; and Scale Out, where many persistent adapted instances coexist. MinT provides one infrastructure example for managing adapter identity, revision, provenance, evaluation, and serving residency. Together, the results suggest that PEFT can be a compact substrate for persistent personal models rather than only a budget substitute for full fine-tuning.
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
May 13, 2026We present MindLab Toolkit (MinT), a managed infrastructure system for Low-Rank Adaptation (LoRA) post-training and online serving. MinT targets a setting where many trained policies are produced over a small number of expensive base-model deployments. Instead of materializing each policy as a merged full checkpoint, MinT keeps the base model resident and moves exported LoRA adapter revisions through rollout, update, export, evaluation, serving, and rollback, hiding distributed training, serving, scheduling, and data movement behind a service interface. MinT scales this path along three axes. Scale Up extends LoRA RL to frontier-scale dense and MoE architectures, including MLA and DSA attention paths, with training and serving validated beyond 1T total parameters. Scale Down moves only the exported LoRA adapter, which can be under 1% of base-model size in rank-1 settings; adapter-only handoff reduces the measured step by 18.3x on a 4B dense model and 2.85x on a 30B MoE, while concurrent multi-policy GRPO shortens wall time by 1.77x and 1.45x without raising peak memory. Scale Out separates durable policy addressability from CPU/GPU working sets: a tensor-parallel deployment supports 10^6-scale addressable catalogs (measured single-engine sweeps through 100K) and thousand-adapter active waves at cluster scale, with cold loading treated as scheduled service work and packed MoE LoRA tensors improving live engine loading by 8.5-8.7x. MinT thus manages million-scale LoRA policy catalogs while training and serving selected adapter revisions over shared 1T-class base models.
ReactEMG Stroke: Healthy-to-Stroke Few-shot Adaptation for sEMG-Based Intent Detection
Jan 29, 2026Surface electromyography (sEMG) is a promising control signal for assist-as-needed hand rehabilitation after stroke, but detecting intent from paretic muscles often requires lengthy, subject-specific calibration and remains brittle to variability. We propose a healthy-to-stroke adaptation pipeline that initializes an intent detector from a model pretrained on large-scale able-bodied sEMG, then fine-tunes it for each stroke participant using only a small amount of subject-specific data. Using a newly collected dataset from three individuals with chronic stroke, we compare adaptation strategies (head-only tuning, parameter-efficient LoRA adapters, and full end-to-end fine-tuning) and evaluate on held-out test sets that include realistic distribution shifts such as within-session drift, posture changes, and armband repositioning. Across conditions, healthy-pretrained adaptation consistently improves stroke intent detection relative to both zero-shot transfer and stroke-only training under the same data budget; the best adaptation methods improve average transition accuracy from 0.42 to 0.61 and raw accuracy from 0.69 to 0.78. These results suggest that transferring a reusable healthy-domain EMG representation can reduce calibration burden while improving robustness for real-time post-stroke intent detection.
ReactEMG: Zero-Shot, Low-Latency Intent Detection via sEMG
Jun 24, 2025



Surface electromyography (sEMG) signals show promise for effective human-computer interfaces, particularly in rehabilitation and prosthetics. However, challenges remain in developing systems that respond quickly and reliably to user intent, across different subjects and without requiring time-consuming calibration. In this work, we propose a framework for EMG-based intent detection that addresses these challenges. Unlike traditional gesture recognition models that wait until a gesture is completed before classifying it, our approach uses a segmentation strategy to assign intent labels at every timestep as the gesture unfolds. We introduce a novel masked modeling strategy that aligns muscle activations with their corresponding user intents, enabling rapid onset detection and stable tracking of ongoing gestures. In evaluations against baseline methods, considering both accuracy and stability for device control, our approach surpasses state-of-the-art performance in zero-shot transfer conditions, demonstrating its potential for wearable robotics and next-generation prosthetic systems. Our project page is available at: https://reactemg.github.io
ChatEMG: Synthetic Data Generation to Control a Robotic Hand Orthosis for Stroke
Jun 17, 2024



Intent inferral on a hand orthosis for stroke patients is challenging due to the difficulty of data collection from impaired subjects. Additionally, EMG signals exhibit significant variations across different conditions, sessions, and subjects, making it hard for classifiers to generalize. Traditional approaches require a large labeled dataset from the new condition, session, or subject to train intent classifiers; however, this data collection process is burdensome and time-consuming. In this paper, we propose ChatEMG, an autoregressive generative model that can generate synthetic EMG signals conditioned on prompts (i.e., a given sequence of EMG signals). ChatEMG enables us to collect only a small dataset from the new condition, session, or subject and expand it with synthetic samples conditioned on prompts from this new context. ChatEMG leverages a vast repository of previous data via generative training while still remaining context-specific via prompting. Our experiments show that these synthetic samples are classifier-agnostic and can improve intent inferral accuracy for different types of classifiers. We demonstrate that our complete approach can be integrated into a single patient session, including the use of the classifier for functional orthosis-assisted tasks. To the best of our knowledge, this is the first time an intent classifier trained partially on synthetic data has been deployed for functional control of an orthosis by a stroke survivor. Videos and additional information can be found at https://jxu.ai/chatemg.
Tactile-based Object Retrieval From Granular Media
Feb 21, 2024



We introduce GEOTACT, a robotic manipulation method capable of retrieving objects buried in granular media. This is a challenging task due to the need to interact with granular media, and doing so based exclusively on tactile feedback, since a buried object can be completely hidden from vision. Tactile feedback is in itself challenging in this context, due to ubiquitous contact with the surrounding media, and the inherent noise level induced by the tactile readings. To address these challenges, we use a learning method trained end-to-end with simulated sensor noise. We show that our problem formulation leads to the natural emergence of learned pushing behaviors that the manipulator uses to reduce uncertainty and funnel the object to a stable grasp despite spurious and noisy tactile readings. We also introduce a training curriculum that enables learning these behaviors in simulation, followed by zero-shot transfer to real hardware. To the best of our knowledge, GEOTACT is the first method to reliably retrieve a number of different objects from a granular environment, doing so on real hardware and with integrated tactile sensing. Videos and additional information can be found at https://jxu.ai/geotact.
Data Augmentation in Emotion Classification Using Generative Adversarial Networks
Dec 14, 2017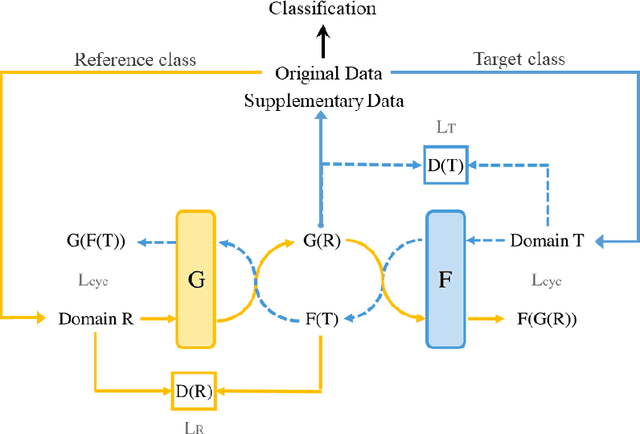
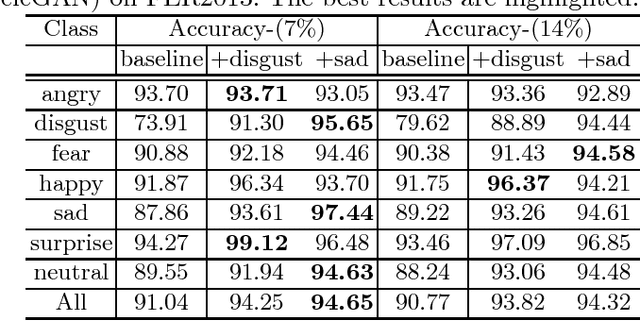
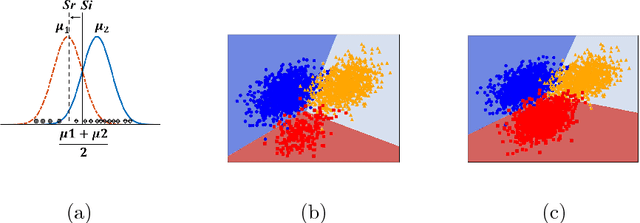

It is a difficult task to classify images with multiple class labels using only a small number of labeled examples, especially when the label (class) distribution is imbalanced. Emotion classification is such an example of imbalanced label distribution, because some classes of emotions like \emph{disgusted} are relatively rare comparing to other labels like {\it happy or sad}. In this paper, we propose a data augmentation method using generative adversarial networks (GAN). It can complement and complete the data manifold and find better margins between neighboring classes. Specifically, we design a framework with a CNN model as the classifier and a cycle-consistent adversarial networks (CycleGAN) as the generator. In order to avoid gradient vanishing problem, we employ the least-squared loss as adversarial loss. We also propose several evaluation methods on three benchmark datasets to validate GAN's performance. Empirical results show that we can obtain 5%~10% increase in the classification accuracy after employing the GAN-based data augmentation techniques.