 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboTales: ROBOTic Anthropomorphic LEarning Systems
Jun 24, 2026RoboTales is a low-cost robotic storytelling system that animates narratives using expressive sock puppetry. Implemented autonomously on a Baxter robot as a test case, RoboTales synchronizes narration, gestures, and mouth movements to perform character-driven stories. In a pilot study, puppet-based storytelling outperformed a gesture-only mode, producing higher HRIES ratings and improved story recall, suggesting that embodied puppetry enhances engagement and narrative comprehension. Designed to be modular and platform-agnostic, RoboTales can be adapted to other manipulators and offers a screen-free alternative to passive media, supporting future deployment in child-centered learning environments.
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
May 13, 2026We present MindLab Toolkit (MinT), a managed infrastructure system for Low-Rank Adaptation (LoRA) post-training and online serving. MinT targets a setting where many trained policies are produced over a small number of expensive base-model deployments. Instead of materializing each policy as a merged full checkpoint, MinT keeps the base model resident and moves exported LoRA adapter revisions through rollout, update, export, evaluation, serving, and rollback, hiding distributed training, serving, scheduling, and data movement behind a service interface. MinT scales this path along three axes. Scale Up extends LoRA RL to frontier-scale dense and MoE architectures, including MLA and DSA attention paths, with training and serving validated beyond 1T total parameters. Scale Down moves only the exported LoRA adapter, which can be under 1% of base-model size in rank-1 settings; adapter-only handoff reduces the measured step by 18.3x on a 4B dense model and 2.85x on a 30B MoE, while concurrent multi-policy GRPO shortens wall time by 1.77x and 1.45x without raising peak memory. Scale Out separates durable policy addressability from CPU/GPU working sets: a tensor-parallel deployment supports 10^6-scale addressable catalogs (measured single-engine sweeps through 100K) and thousand-adapter active waves at cluster scale, with cold loading treated as scheduled service work and packed MoE LoRA tensors improving live engine loading by 8.5-8.7x. MinT thus manages million-scale LoRA policy catalogs while training and serving selected adapter revisions over shared 1T-class base models.
Clinical Applications of Plantar Pressure Measurement
Jan 09, 2024Plantar pressure measurements can provide valuable insight into various health characteristics in patients. In this study, we describe different plantar pressure devices available on the market and their clinical relevance. Current devices are either platform-based or wearable and consist of a variety of sensor technologies: resistive, capacitive, piezoelectric, and optical. The measurements collected from any of these sensors can be utilized for a range of clinical applications including patients with diabetes, trauma, deformity and cerebral palsy, stroke, cervical myelopathy, ankle instability, sports injuries, and Parkinsons disease. However, the proper technology should be selected based on the clinical need and the type of tests being performed on the device. In this review we provide the reader with a simple overview of the existing technologies their advantages and disadvantages and provide application examples for each. Moreover, we suggest new areas in orthopaedic that plantar pressure mapping technology can be utilized for increased quality of care.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022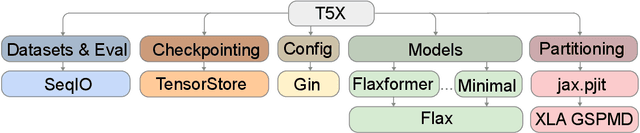
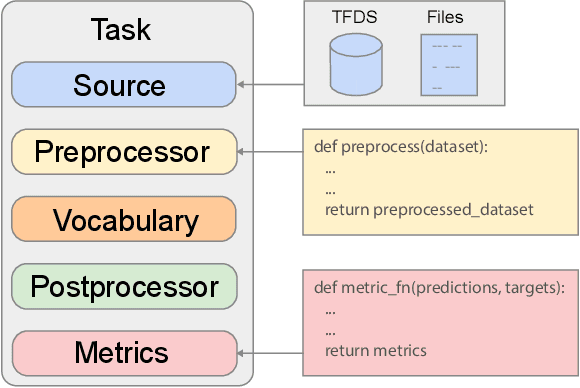
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Spatial Graph Attention and Curiosity-driven Policy for Antiviral Drug Discovery
Jun 20, 2021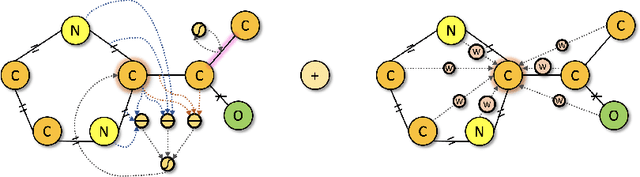
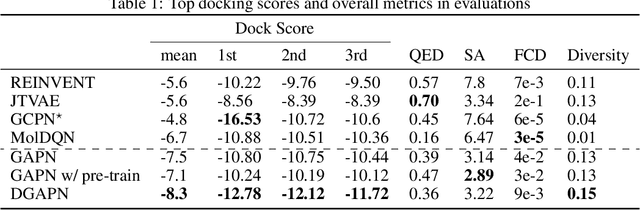
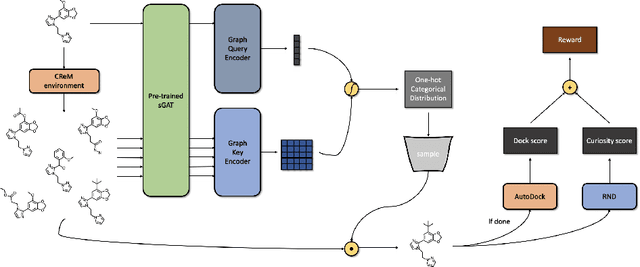
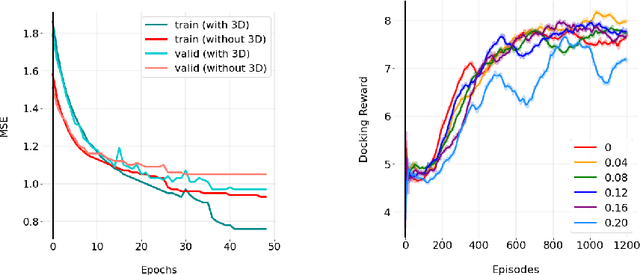
We developed Distilled Graph Attention Policy Networks (DGAPNs), a curiosity-driven reinforcement learning model to generate novel graph-structured chemical representations that optimize user-defined objectives by efficiently navigating a physically constrained domain. The framework is examined on the task of generating molecules that are designed to bind, noncovalently, to functional sites of SARS-CoV-2 proteins. We present a spatial Graph Attention Network (sGAT) that leverages self-attention over both node and edge attributes as well as encoding spatial structure -- this capability is of considerable interest in areas such as molecular and synthetic biology and drug discovery. An attentional policy network is then introduced to learn decision rules for a dynamic, fragment-based chemical environment, and state-of-the-art policy gradient techniques are employed to train the network with enhanced stability. Exploration is efficiently encouraged by incorporating innovation reward bonuses learned and proposed by random network distillation. In experiments, our framework achieved outstanding results compared to state-of-the-art algorithms, while increasing the diversity of proposed molecules and reducing the complexity of paths to chemical synthesis.