 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multimodal Planning Agent for Visual Question-Answering
Jan 28, 2026Visual Question-Answering (VQA) is a challenging multimodal task that requires integrating visual and textual information to generate accurate responses. While multimodal Retrieval-Augmented Generation (mRAG) has shown promise in enhancing VQA systems by providing more evidence on both image and text sides, the default procedure that addresses VQA queries, especially the knowledge-intensive ones, often relies on multi-stage pipelines of mRAG with inherent dependencies. To mitigate the inefficiency limitations while maintaining VQA task performance, this paper proposes a method that trains a multimodal planning agent, dynamically decomposing the mRAG pipeline to solve the VQA task. Our method optimizes the trade-off between efficiency and effectiveness by training the agent to intelligently determine the necessity of each mRAG step. In our experiments, the agent can help reduce redundant computations, cutting search time by over 60\% compared to existing methods and decreasing costly tool calls. Meanwhile, experiments demonstrate that our method outperforms all baselines, including a Deep Research agent and a carefully designed prompt-based method, on average over six various datasets. Code will be released.
Beyond Hard Writes and Rigid Preservation: Soft Recursive Least-Squares for Lifelong LLM Editing
Jan 22, 2026Model editing updates a pre-trained LLM with new facts or rules without re-training, while preserving unrelated behavior. In real deployment, edits arrive as long streams, and existing editors often face a plasticity-stability dilemma: locate-then-edit "hard writes" can accumulate interference over time, while null-space-style "hard preservation" preserves only what is explicitly constrained, so past edits can be overwritten and unconstrained behaviors may deviate, degrading general capabilities in the many-edits regime. We propose RLSEdit, a recursive least-squares editor for long sequential editing. RLSEdit formulates editing as an online quadratic optimization with soft constraints, minimizing a cumulative key-value fitting objective with two regularizers that control for both deviation from the pre-trained weights and from a designated anchor mapping. The resulting update admits an efficient online recursion via the Woodbury identity, with per-edit cost independent of history length and scaling only with the current edit size. We further provide deviation bounds and an asymptotic characterization of the adherence-preservation trade-off in the many-edits regime. Experiments on multiple model families demonstrate stable scaling to 10K edits, outperforming strong baselines in both edit success and holistic stability -- crucially retaining early edits, and preserving general capabilities on GLUE and held-out reasoning/code benchmarks.
MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification
Jan 21, 2026Speculative Decoding (SD) accelerates autoregressive large language model (LLM) inference by decoupling generation and verification. While recent methods improve draft quality by tightly coupling the drafter with the target model, the verification mechanism itself remains largely unchanged, relying on strict token-level rejection sampling. In practice, modern LLMs frequently operate in low-margin regimes where the target model exhibits weak preference among top candidates. In such cases, rejecting plausible runner-up tokens yields negligible information gain while incurring substantial rollback cost, leading to a fundamental inefficiency in verification. We propose Margin-Aware Speculative Verification, a training-free and domain-agnostic verification strategy that adapts to the target model's local decisiveness. Our method conditions verification on decision stability measured directly from the target logits and relaxes rejection only when strict verification provides minimal benefit. Importantly, the approach modifies only the verification rule and is fully compatible with existing target-coupled speculative decoding frameworks. Extensive experiments across model scales ranging from 8B to 235B demonstrate that our method delivers consistent and significant inference speedups over state-of-the-art baselines while preserving generation quality across diverse benchmarks.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
Dynamic Quantization Error Propagation in Encoder-Decoder ASR Quantization
Jan 05, 2026Running Automatic Speech Recognition (ASR) models on memory-constrained edge devices requires efficient compression. While layer-wise post-training quantization is effective, it suffers from error accumulation, especially in encoder-decoder architectures. Existing solutions like Quantization Error Propagation (QEP) are suboptimal for ASR due to the model's heterogeneity, processing acoustic features in the encoder while generating text in the decoder. To address this, we propose Fine-grained Alpha for Dynamic Quantization Error Propagation (FADE), which adaptively controls the trade-off between cross-layer error correction and local quantization. Experiments show that FADE significantly improves stability by reducing performance variance across runs, while simultaneously surpassing baselines in mean WER.
AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning
Dec 28, 2025Conducting reinforcement learning (RL) in simulated environments offers a cost-effective and highly scalable way to enhance language-based agents. However, previous work has been limited to semi-automated environment synthesis or tasks lacking sufficient difficulty, offering little breadth or depth. In addition, the instability of simulated users integrated into these environments, along with the heterogeneity across simulated environments, poses further challenges for agentic RL. In this work, we propose: (1) a unified pipeline for automated and scalable synthesis of simulated environments associated with high-difficulty but easily verifiable tasks; and (2) an environment level RL algorithm that not only effectively mitigates user instability but also performs advantage estimation at the environment level, thereby improving training efficiency and stability. Comprehensive evaluations on agentic benchmarks, including tau-bench, tau2-Bench, and VitaBench, validate the effectiveness of our proposed method. Further in-depth analyses underscore its out-of-domain generalization.
Autonomously Unweaving Multiple Cables Using Visual Feedback
Dec 13, 2025



Many cable management tasks involve separating out the different cables and removing tangles. Automating this task is challenging because cables are deformable and can have combinations of knots and multiple interwoven segments. Prior works have focused on untying knots in one cable, which is one subtask of cable management. However, in this paper, we focus on a different subtask called multi-cable unweaving, which refers to removing the intersections among multiple interwoven cables to separate them and facilitate further manipulation. We propose a method that utilizes visual feedback to unweave a bundle of loosely entangled cables. We formulate cable unweaving as a pick-and-place problem, where the grasp position is selected from discrete nodes in a graph-based cable state representation. Our cable state representation encodes both topological and geometric information about the cables from the visual image. To predict future cable states and identify valid actions, we present a novel state transition model that takes into account the straightening and bending of cables during manipulation. Using this state transition model, we select between two high-level action primitives and calculate predicted immediate costs to optimize the lower-level actions. We experimentally demonstrate that iterating the above perception-planning-action process enables unweaving electric cables and shoelaces with an 84% success rate on average.
VLM-NCD:Novel Class Discovery with Vision-Based Large Language Models
Dec 11, 2025Novel Class Discovery aims to utilise prior knowledge of known classes to classify and discover unknown classes from unlabelled data. Existing NCD methods for images primarily rely on visual features, which suffer from limitations such as insufficient feature discriminability and the long-tail distribution of data. We propose LLM-NCD, a multimodal framework that breaks this bottleneck by fusing visual-textual semantics and prototype guided clustering. Our key innovation lies in modelling cluster centres and semantic prototypes of known classes by jointly optimising known class image and text features, and a dualphase discovery mechanism that dynamically separates known or novel samples via semantic affinity thresholds and adaptive clustering. Experiments on the CIFAR-100 dataset show that compared to the current methods, this method achieves up to 25.3% improvement in accuracy for unknown classes. Notably, our method shows unique resilience to long tail distributions, a first in NCD literature.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025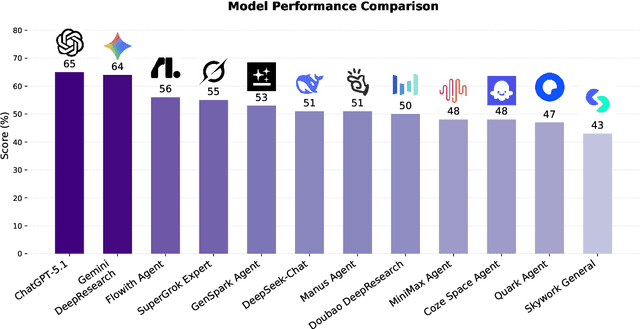
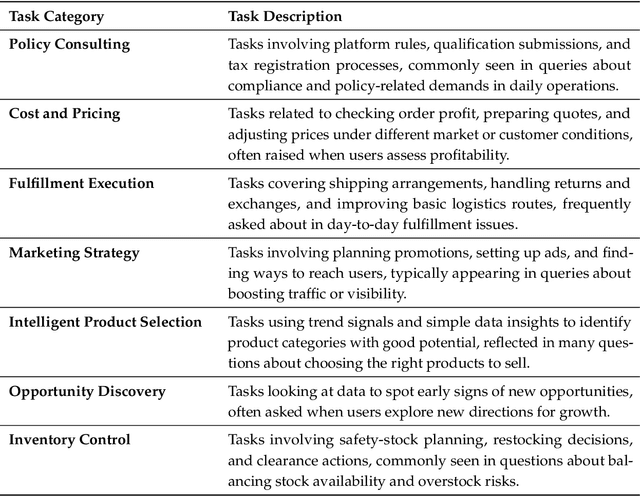

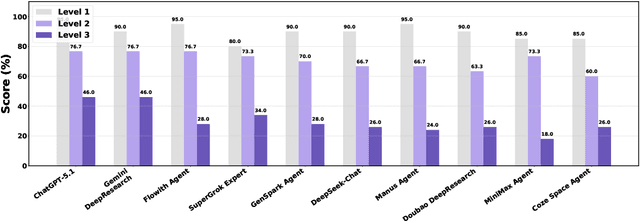
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
An ICTM-RMSAV Framework for Bias-Field Aware Image Segmentation under Poisson and Multiplicative Noise
Nov 12, 2025



Image segmentation is a core task in image processing, yet many methods degrade when images are heavily corrupted by noise and exhibit intensity inhomogeneity. Within the iterative-convolution thresholding method (ICTM) framework, we propose a variational segmentation model that integrates denoising terms. Specifically, the denoising component consists of an I-divergence term and an adaptive total-variation (TV) regularizer, making the model well suited to images contaminated by Gamma--distributed multiplicative noise and Poisson noise. A spatially adaptive weight derived from a gray-level indicator guides diffusion differently across regions of varying intensity. To further address intensity inhomogeneity, we estimate a smoothly varying bias field, which improves segmentation accuracy. Regions are represented by characteristic functions, with contour length encoded accordingly. For efficient optimization, we couple ICTM with a relaxed modified scalar auxiliary variable (RMSAV) scheme. Extensive experiments on synthetic and real-world images with intensity inhomogeneity and diverse noise types show that the proposed model achieves superior accuracy and robustness compared with competing approaches.