 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Distillation for Reference-less Summarization
Mar 20, 2024The current winning recipe for automatic summarization is using proprietary large-scale language models (LLMs) such as ChatGPT as is, or imitation learning from them as teacher models. While increasingly ubiquitous dependence on such large-scale language models is convenient, there remains an important question of whether small-scale models could have achieved competitive results, if we were to seek an alternative learning method -- that allows for a more cost-efficient, controllable, yet powerful summarizer. We present InfoSumm, a novel framework to distill a powerful summarizer based on the information-theoretic objective for summarization, without relying on either the LLM's capability or human-written references. To achieve this, we first propose a novel formulation of the desiderata of summarization (saliency, faithfulness and brevity) through the lens of mutual information between the original document and the summary. Based on this formulation, we start off from Pythia-2.8B as the teacher model, which is not yet capable of summarization, then self-train the model to optimize for the information-centric measures of ideal summaries. Distilling from the improved teacher, we arrive at a compact but powerful summarizer with only 568M parameters that performs competitively against ChatGPT, without ever relying on ChatGPT's capabilities. Extensive analysis demonstrates that our approach outperforms in-domain supervised models in human evaluation, let alone state-of-the-art unsupervised methods, and wins over ChatGPT in controllable summarization.
JAMDEC: Unsupervised Authorship Obfuscation using Constrained Decoding over Small Language Models
Feb 13, 2024



The permanence of online content combined with the enhanced authorship identification techniques calls for stronger computational methods to protect the identity and privacy of online authorship when needed, e.g., blind reviews for scientific papers, anonymous online reviews, or anonymous interactions in the mental health forums. In this paper, we propose an unsupervised inference-time approach to authorship obfuscation to address the unique challenges of authorship obfuscation: lack of supervision data for diverse authorship and domains, and the need for a sufficient level of revision beyond simple paraphrasing to obfuscate the authorship, all the while preserving the original content and fluency. We introduce JAMDEC, a user-controlled, inference-time algorithm for authorship obfuscation that can be in principle applied to any text and authorship. Our approach builds on small language models such as GPT2-XL in order to help avoid disclosing the original content to proprietary LLM's APIs, while also reducing the performance gap between small and large language models via algorithmic enhancement. The key idea behind our approach is to boost the creative power of smaller language models through constrained decoding, while also allowing for user-specified controls and flexibility. Experimental results demonstrate that our approach based on GPT2-XL outperforms previous state-of-the-art methods based on comparably small models, while performing competitively against GPT3.5 175B, a propriety model that is two orders of magnitudes larger.
A Roadmap to Pluralistic Alignment
Feb 07, 2024With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also propose and formalize three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
Localized Symbolic Knowledge Distillation for Visual Commonsense Models
Dec 12, 2023



Instruction following vision-language (VL) models offer a flexible interface that supports a broad range of multimodal tasks in a zero-shot fashion. However, interfaces that operate on full images do not directly enable the user to "point to" and access specific regions within images. This capability is important not only to support reference-grounded VL benchmarks, but also, for practical applications that require precise within-image reasoning. We build Localized Visual Commonsense models, which allow users to specify (multiple) regions as input. We train our model by sampling localized commonsense knowledge from a large language model (LLM): specifically, we prompt an LLM to collect commonsense knowledge given a global literal image description and a local literal region description automatically generated by a set of VL models. With a separately trained critic model that selects high-quality examples, we find that training on the localized commonsense corpus can successfully distill existing VL models to support a reference-as-input interface. Empirical results and human evaluations in a zero-shot setup demonstrate that our distillation method results in more precise VL models of reasoning compared to a baseline of passing a generated referring expression to an LLM.
NovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023



We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
Dec 04, 2023



The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
STEER: Unified Style Transfer with Expert Reinforcement
Nov 13, 2023



While text style transfer has many applications across natural language processing, the core premise of transferring from a single source style is unrealistic in a real-world setting. In this work, we focus on arbitrary style transfer: rewriting a text from an arbitrary, unknown style to a target style. We propose STEER: Unified Style Transfer with Expert Reinforcement, a unified frame-work developed to overcome the challenge of limited parallel data for style transfer. STEER involves automatically generating a corpus of style-transfer pairs using a product of experts during decoding. The generated offline data is then used to pre-train an initial policy before switching to online, off-policy reinforcement learning for further improvements via fine-grained reward signals. STEER is unified and can transfer to multiple target styles from an arbitrary, unknown source style, making it particularly flexible and efficient. Experimental results on a challenging dataset with text from a diverse set of styles demonstrate state-of-the-art results compared to competitive baselines. Remarkably, STEER outperforms the 175B parameter instruction-tuned GPT-3 on overall style transfer quality, despite being 226 times smaller in size. We also show STEER is robust, maintaining its style transfer capabilities on out-of-domain data, and surpassing nearly all baselines across various styles. The success of our method highlights the potential of RL algorithms when augmented with controllable decoding to overcome the challenge of limited data supervision.
In Search of the Long-Tail: Systematic Generation of Long-Tail Knowledge via Logical Rule Guided Search
Nov 13, 2023



Since large language models have approached human-level performance on many tasks, it has become increasingly harder for researchers to find tasks that are still challenging to the models. Failure cases usually come from the long-tail distribution - data that an oracle language model could assign a probability on the lower end of its distribution. Current methodology such as prompt engineering or crowdsourcing are insufficient for creating long-tail examples because humans are constrained by cognitive bias. We propose a Logic-Induced-Knowledge-Search (LINK) framework for systematically generating long-tail knowledge statements. Grounded by a symbolic rule, we search for long-tail values for each variable of the rule by first prompting a LLM, then verifying the correctness of the values with a critic, and lastly pushing for the long-tail distribution with a reranker. With this framework we construct a dataset, Logic-Induced-Long-Tail (LINT), consisting of 200 symbolic rules and 50K knowledge statements spanning across four domains. Human annotations find that 84% of the statements in LINT are factually correct. In contrast, ChatGPT and GPT4 struggle with directly generating long-tail statements under the guidance of logic rules, each only getting 56% and 78% of their statements correct. Moreover, their "long-tail" generations in fact fall into the higher likelihood range, and thus are not really long-tail. Our findings suggest that LINK is effective for generating data in the long-tail distribution while enforcing quality. LINT can be useful for systematically evaluating LLMs' capabilities in the long-tail distribution. We challenge the models with a simple entailment classification task using samples from LINT. We find that ChatGPT and GPT4's capability in identifying incorrect knowledge drop by ~3% in the long-tail distribution compared to head distribution.
Tailoring Self-Rationalizers with Multi-Reward Distillation
Nov 06, 2023Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
The Generative AI Paradox: "What It Can Create, It May Not Understand"
Oct 31, 2023
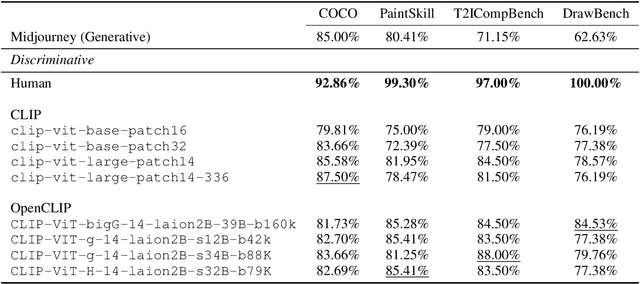
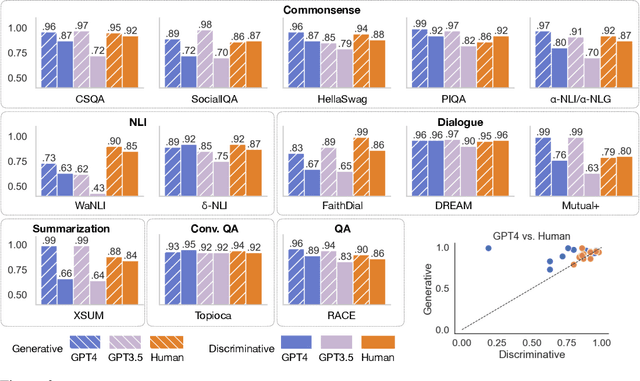
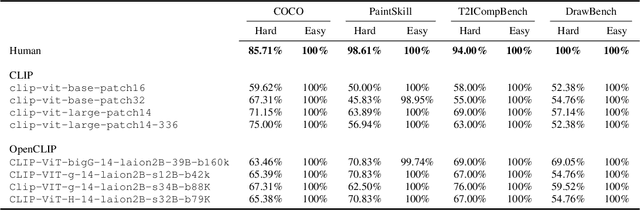
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.