 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInteraction: 3D Object Detection via Modality Interaction
Aug 24, 2022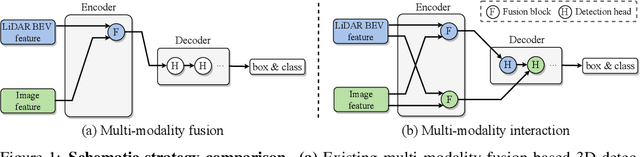
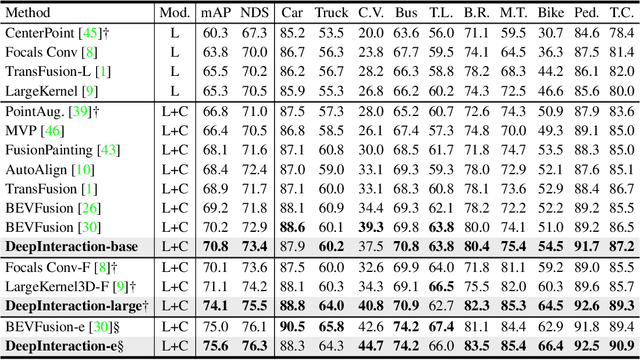
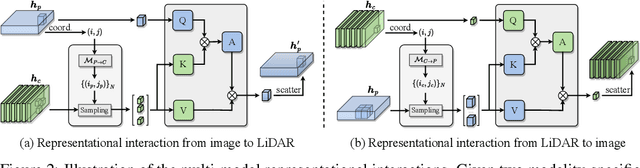
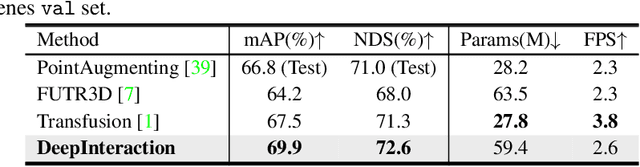
Existing top-performance 3D object detectors typically rely on the multi-modal fusion strategy. This design is however fundamentally restricted due to overlooking the modality-specific useful information and finally hampering the model performance. To address this limitation, in this work we introduce a novel modality interaction strategy where individual per-modality representations are learned and maintained throughout for enabling their unique characteristics to be exploited during object detection. To realize this proposed strategy, we design a DeepInteraction architecture characterized by a multi-modal representational interaction encoder and a multi-modal predictive interaction decoder. Experiments on the large-scale nuScenes dataset show that our proposed method surpasses all prior arts often by a large margin. Crucially, our method is ranked at the first position at the highly competitive nuScenes object detection leaderboard.
Semi-Supervised and Unsupervised Deep Visual Learning: A Survey
Aug 24, 2022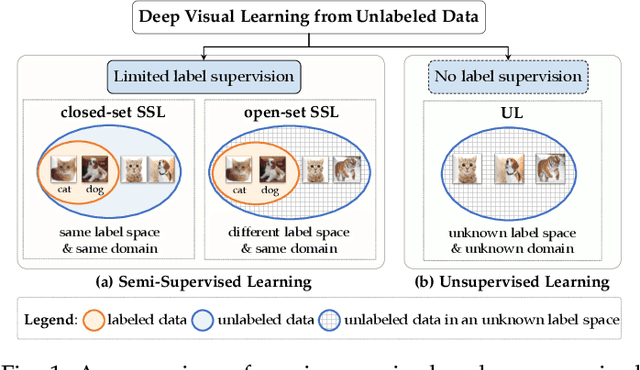
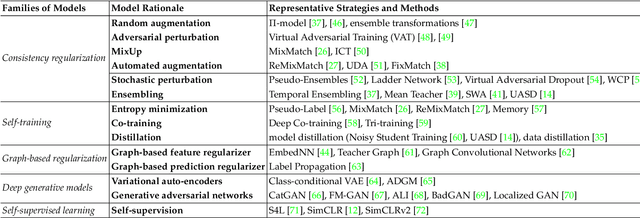
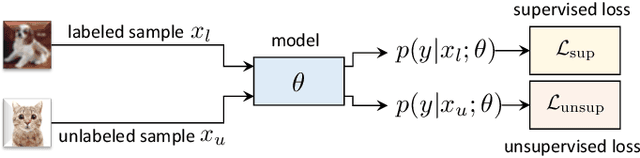

State-of-the-art deep learning models are often trained with a large amount of costly labeled training data. However, requiring exhaustive manual annotations may degrade the model's generalizability in the limited-label regime. Semi-supervised learning and unsupervised learning offer promising paradigms to learn from an abundance of unlabeled visual data. Recent progress in these paradigms has indicated the strong benefits of leveraging unlabeled data to improve model generalization and provide better model initialization. In this survey, we review the recent advanced deep learning algorithms on semi-supervised learning (SSL) and unsupervised learning (UL) for visual recognition from a unified perspective. To offer a holistic understanding of the state-of-the-art in these areas, we propose a unified taxonomy. We categorize existing representative SSL and UL with comprehensive and insightful analysis to highlight their design rationales in different learning scenarios and applications in different computer vision tasks. Lastly, we discuss the emerging trends and open challenges in SSL and UL to shed light on future critical research directions.
Accelerating Score-based Generative Models with Preconditioned Diffusion Sampling
Jul 19, 2022


Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their inference is very slow due to a need for many (e.g., 2000) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We investigate this problem by viewing the diffusion sampling process as a Metropolis adjusted Langevin algorithm, which helps reveal the underlying cause to be ill-conditioned curvature. Under this insight, we propose a model-agnostic preconditioned diffusion sampling (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. Crucially, PDS is proven theoretically to converge to the original target distribution of a SGM, no need for retraining. Extensive experiments on three image datasets with a variety of resolutions and diversity validate that PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to 29x on more challenging high resolution (1024x1024) image generation.
Visual Representation Learning with Transformer: A Sequence-to-Sequence Perspective
Jul 19, 2022Visual representation learning is the key of solving various vision problems. Relying on the seminal grid structure priors, convolutional neural networks (CNNs) have been the de facto standard architectures of most deep vision models. For instance, classical semantic segmentation methods often adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated (i.e., atrous) convolutions or inserting attention modules. However, the FCN-based architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating visual representation learning generally as a sequence-to-sequence prediction task. Specifically, we deploy a pure Transformer to encode an image as a sequence of patches, without local convolution and resolution reduction. With the global context modeled in every layer of the Transformer, stronger visual representation can be learned for better tackling vision tasks. In particular, our segmentation model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission), Pascal Context (55.83% mIoU) and reaches competitive results on Cityscapes. Further, we formulate a family of Hierarchical Local-Global (HLG) Transformers characterized by local attention within windows and global-attention across windows in a hierarchical and pyramidal architecture. Extensive experiments show that our method achieves appealing performance on a variety of visual recognition tasks (e.g., image classification, object detection and instance segmentation and semantic segmentation).
Zero-Shot Temporal Action Detection via Vision-Language Prompting
Jul 17, 2022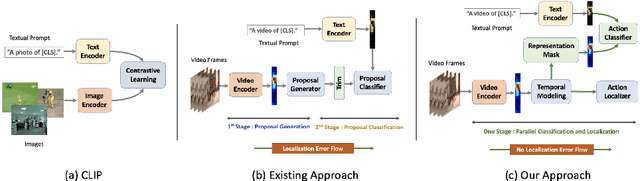
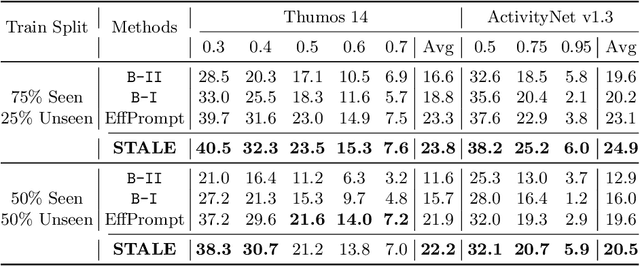
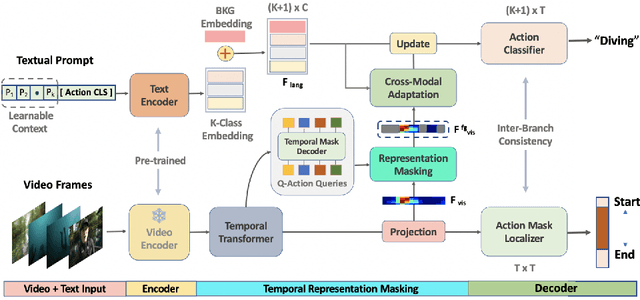
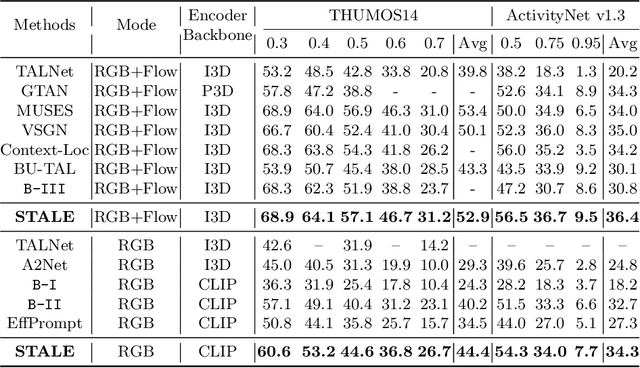
Existing temporal action detection (TAD) methods rely on large training data including segment-level annotations, limited to recognizing previously seen classes alone during inference. Collecting and annotating a large training set for each class of interest is costly and hence unscalable. Zero-shot TAD (ZS-TAD) resolves this obstacle by enabling a pre-trained model to recognize any unseen action classes. Meanwhile, ZS-TAD is also much more challenging with significantly less investigation. Inspired by the success of zero-shot image classification aided by vision-language (ViL) models such as CLIP, we aim to tackle the more complex TAD task. An intuitive method is to integrate an off-the-shelf proposal detector with CLIP style classification. However, due to the sequential localization (e.g, proposal generation) and classification design, it is prone to localization error propagation. To overcome this problem, in this paper we propose a novel zero-Shot Temporal Action detection model via Vision-LanguagE prompting (STALE). Such a novel design effectively eliminates the dependence between localization and classification by breaking the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved optimization. Extensive experiments on standard ZS-TAD video benchmarks show that our STALE significantly outperforms state-of-the-art alternatives. Besides, our model also yields superior results on supervised TAD over recent strong competitors. The PyTorch implementation of STALE is available at https://github.com/sauradip/STALE.
FashionViL: Fashion-Focused Vision-and-Language Representation Learning
Jul 17, 2022

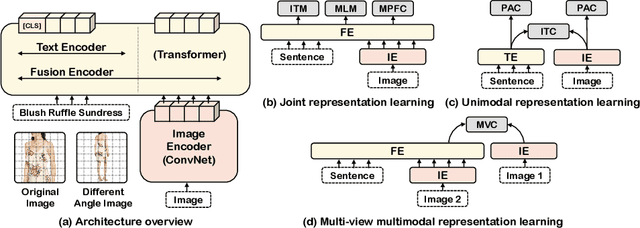
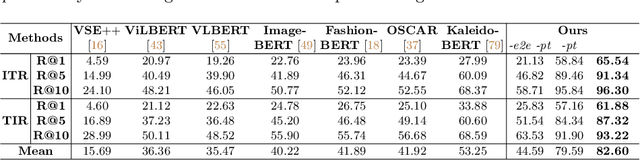
Large-scale Vision-and-Language (V+L) pre-training for representation learning has proven to be effective in boosting various downstream V+L tasks. However, when it comes to the fashion domain, existing V+L methods are inadequate as they overlook the unique characteristics of both the fashion V+L data and downstream tasks. In this work, we propose a novel fashion-focused V+L representation learning framework, dubbed as FashionViL. It contains two novel fashion-specific pre-training tasks designed particularly to exploit two intrinsic attributes with fashion V+L data. First, in contrast to other domains where a V+L data point contains only a single image-text pair, there could be multiple images in the fashion domain. We thus propose a Multi-View Contrastive Learning task for pulling closer the visual representation of one image to the compositional multimodal representation of another image+text. Second, fashion text (e.g., product description) often contains rich fine-grained concepts (attributes/noun phrases). To exploit this, a Pseudo-Attributes Classification task is introduced to encourage the learned unimodal (visual/textual) representations of the same concept to be adjacent. Further, fashion V+L tasks uniquely include ones that do not conform to the common one-stream or two-stream architectures (e.g., text-guided image retrieval). We thus propose a flexible, versatile V+L model architecture consisting of a modality-agnostic Transformer so that it can be flexibly adapted to any downstream tasks. Extensive experiments show that our FashionViL achieves a new state of the art across five downstream tasks. Code is available at https://github.com/BrandonHanx/mmf.
Semi-Supervised Temporal Action Detection with Proposal-Free Masking
Jul 14, 2022
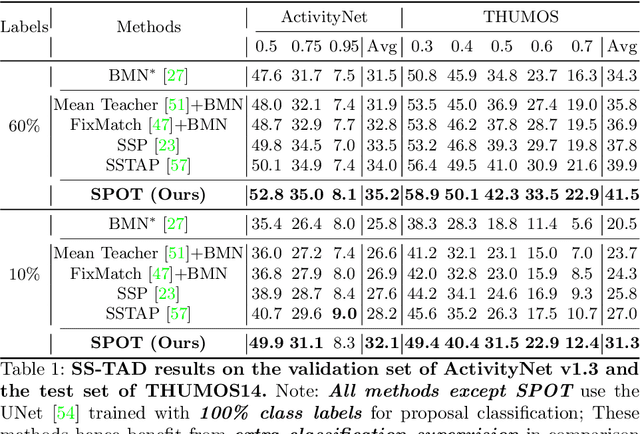
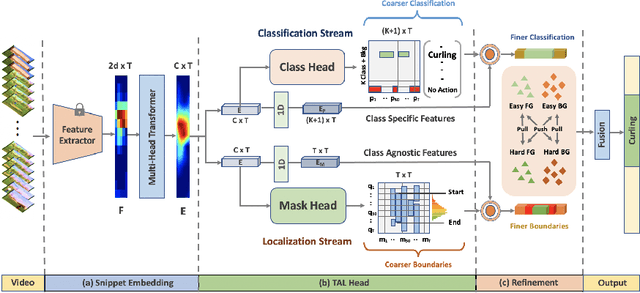
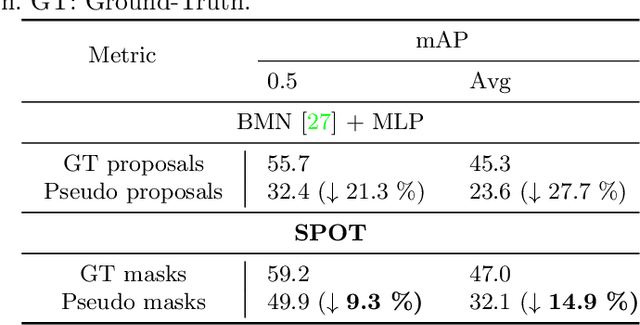
Existing temporal action detection (TAD) methods rely on a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAD (SS-TAD) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SS-TAD is also a much more challenging problem than supervised TAD, and consequently much under-studied. Prior SS-TAD methods directly combine an existing proposal-based TAD method and a SSL method. Due to their sequential localization (e.g, proposal generation) and classification design, they are prone to proposal error propagation. To overcome this limitation, in this work we propose a novel Semi-supervised Temporal action detection model based on PropOsal-free Temporal mask (SPOT) with a parallel localization (mask generation) and classification architecture. Such a novel design effectively eliminates the dependence between localization and classification by cutting off the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for prediction refinement, and a new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our SPOT outperforms state-of-the-art alternatives, often by a large margin. The PyTorch implementation of SPOT is available at https://github.com/sauradip/SPOT
Temporal Action Detection with Global Segmentation Mask Learning
Jul 14, 2022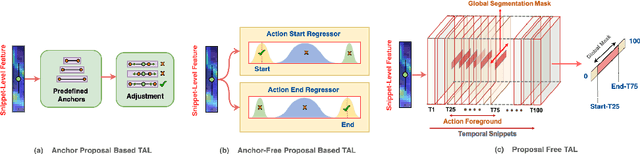
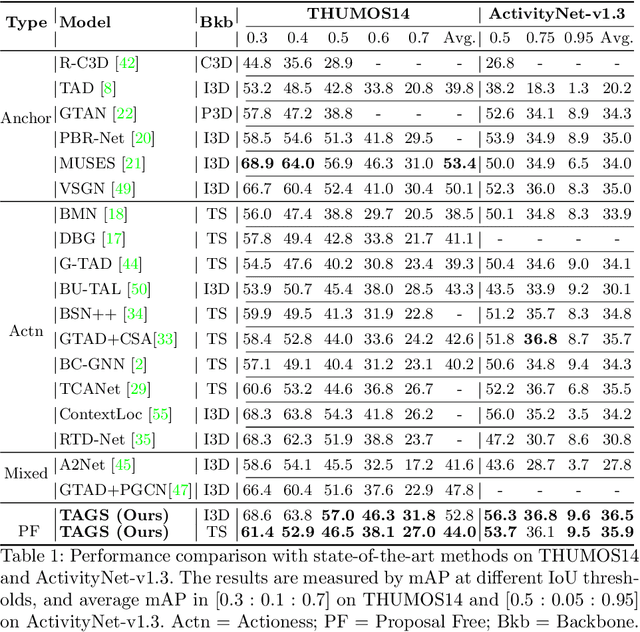
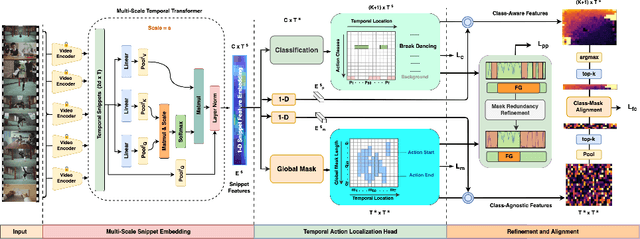
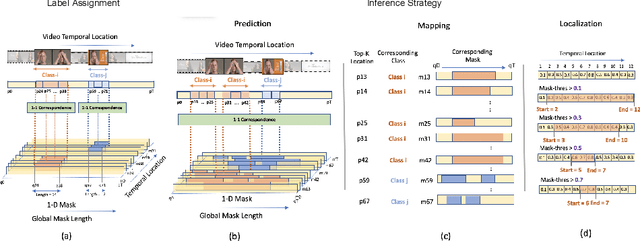
Existing temporal action detection (TAD) methods rely on generating an overwhelmingly large number of proposals per video. This leads to complex model designs due to proposal generation and/or per-proposal action instance evaluation and the resultant high computational cost. In this work, for the first time, we propose a proposal-free Temporal Action detection model with Global Segmentation mask (TAGS). Our core idea is to learn a global segmentation mask of each action instance jointly at the full video length. The TAGS model differs significantly from the conventional proposal-based methods by focusing on global temporal representation learning to directly detect local start and end points of action instances without proposals. Further, by modeling TAD holistically rather than locally at the individual proposal level, TAGS needs a much simpler model architecture with lower computational cost. Extensive experiments show that despite its simpler design, TAGS outperforms existing TAD methods, achieving new state-of-the-art performance on two benchmarks. Importantly, it is ~ 20x faster to train and ~1.6x more efficient for inference. Our PyTorch implementation of TAGS is available at https://github.com/sauradip/TAGS .
PolarFormer: Multi-camera 3D Object Detection with Polar Transformers
Jul 12, 2022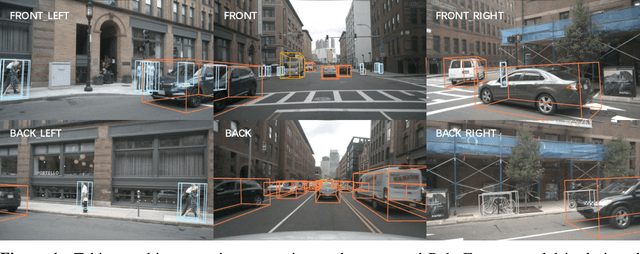
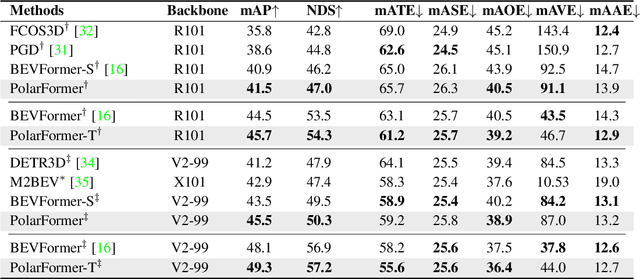
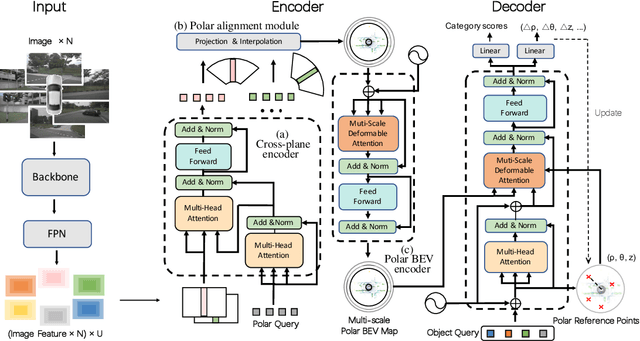
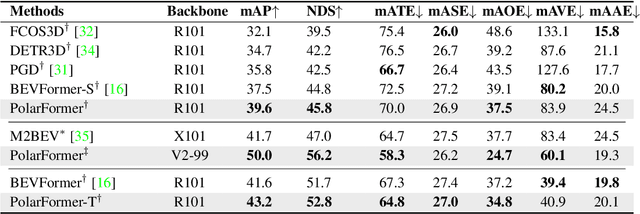
3D object detection in autonomous driving aims to reason "what" and "where" the objects of interest present in a 3D world. Following the conventional wisdom of previous 2D object detection, existing methods often adopt the canonical Cartesian coordinate system with perpendicular axis. However, we conjugate that this does not fit the nature of the ego car's perspective, as each onboard camera perceives the world in shape of wedge intrinsic to the imaging geometry with radical (non-perpendicular) axis. Hence, in this paper we advocate the exploitation of the Polar coordinate system and propose a new Polar Transformer (PolarFormer) for more accurate 3D object detection in the bird's-eye-view (BEV) taking as input only multi-camera 2D images. Specifically, we design a cross attention based Polar detection head without restriction to the shape of input structure to deal with irregular Polar grids. For tackling the unconstrained object scale variations along Polar's distance dimension, we further introduce a multi-scalePolar representation learning strategy. As a result, our model can make best use of the Polar representation rasterized via attending to the corresponding image observation in a sequence-to-sequence fashion subject to the geometric constraints. Thorough experiments on the nuScenes dataset demonstrate that our PolarFormer outperforms significantly state-of-the-art 3D object detection alternatives, as well as yielding competitive performance on BEV semantic segmentation task.
Softmax-free Linear Transformers
Jul 05, 2022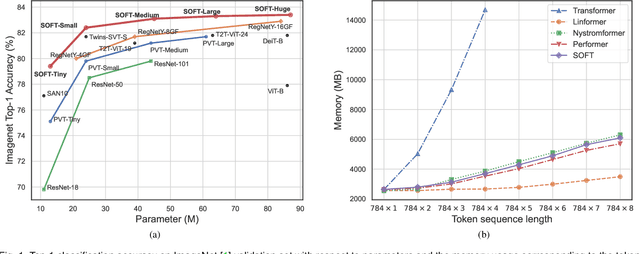

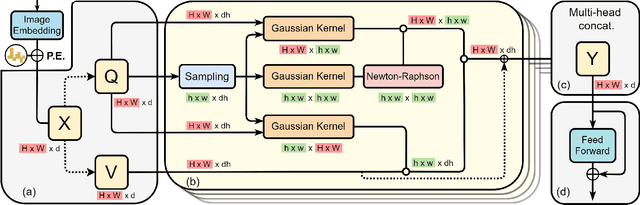
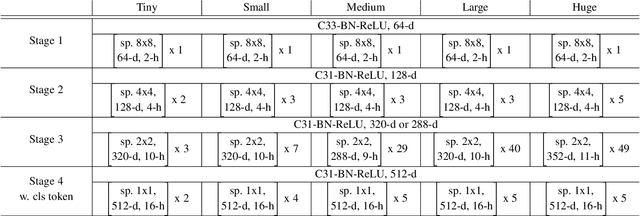
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by stacked self-attention operations. Employing self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have thus been made in Natural Language Processing. However, an in-depth analysis in this work reveals that they are either theoretically flawed or empirically ineffective for visual recognition. We identify that their limitations are rooted in retaining the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Preserving the softmax operation challenges any subsequent linearization efforts. Under this insight, a SOftmax-Free Transformer (abbreviated as SOFT) is proposed for the first time. To eliminate the softmax operator in self-attention, a Gaussian kernel function is adopted to replace the dot-product similarity. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of our approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Further, an efficient symmetric normalization is introduced on the low-rank self-attention for enhancing model generalizability and transferability. Extensive experiments on ImageNet, COCO and ADE20K show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.