 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICNet for Real-Time Semantic Segmentation on High-Resolution Images
Aug 20, 2018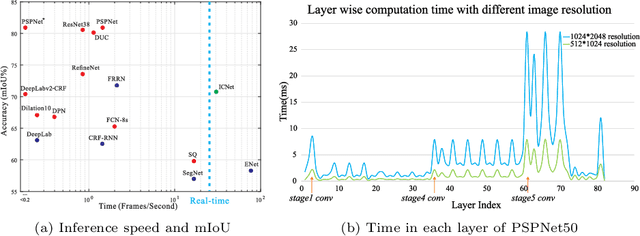

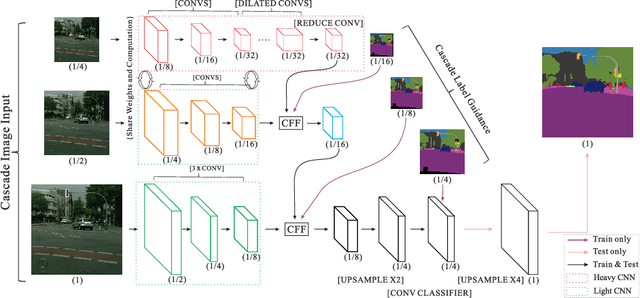
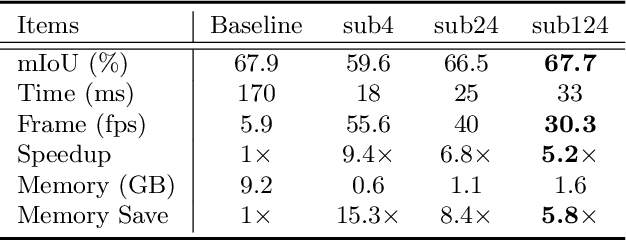
We focus on the challenging task of real-time semantic segmentation in this paper. It finds many practical applications and yet is with fundamental difficulty of reducing a large portion of computation for pixel-wise label inference. We propose an image cascade network (ICNet) that incorporates multi-resolution branches under proper label guidance to address this challenge. We provide in-depth analysis of our framework and introduce the cascade feature fusion unit to quickly achieve high-quality segmentation. Our system yields real-time inference on a single GPU card with decent quality results evaluated on challenging datasets like Cityscapes, CamVid and COCO-Stuff.
Facelet-Bank for Fast Portrait Manipulation
Mar 30, 2018
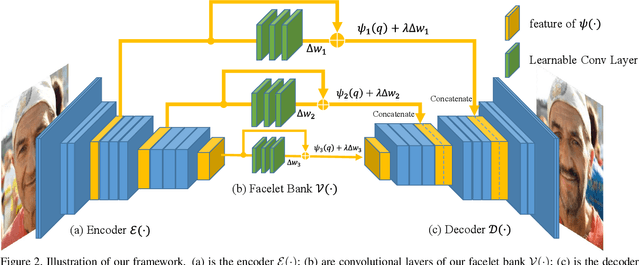


Digital face manipulation has become a popular and fascinating way to touch images with the prevalence of smartphones and social networks. With a wide variety of user preferences, facial expressions, and accessories, a general and flexible model is necessary to accommodate different types of facial editing. In this paper, we propose a model to achieve this goal based on an end-to-end convolutional neural network that supports fast inference, edit-effect control, and quick partial-model update. In addition, this model learns from unpaired image sets with different attributes. Experimental results show that our framework can handle a wide range of expressions, accessories, and makeup effects. It produces high-resolution and high-quality results in fast speed.
Scale-recurrent Network for Deep Image Deblurring
Feb 06, 2018
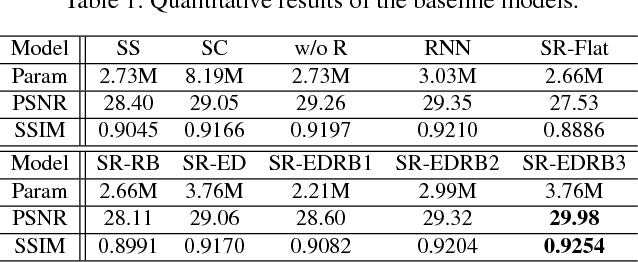
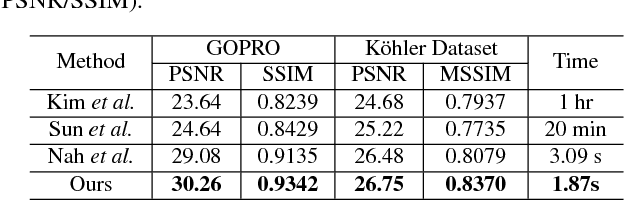
In single image deblurring, the "coarse-to-fine" scheme, i.e. gradually restoring the sharp image on different resolutions in a pyramid, is very successful in both traditional optimization-based methods and recent neural-network-based approaches. In this paper, we investigate this strategy and propose a Scale-recurrent Network (SRN-DeblurNet) for this deblurring task. Compared with the many recent learning-based approaches in [25], it has a simpler network structure, a smaller number of parameters and is easier to train. We evaluate our method on large-scale deblurring datasets with complex motion. Results show that our method can produce better quality results than state-of-the-arts, both quantitatively and qualitatively.
Automatic Real-time Background Cut for Portrait Videos
Apr 28, 2017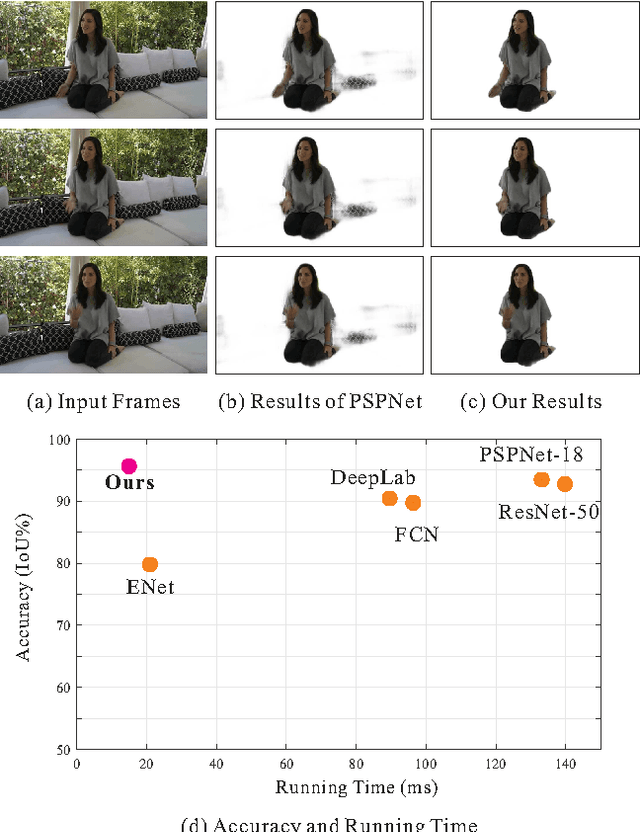
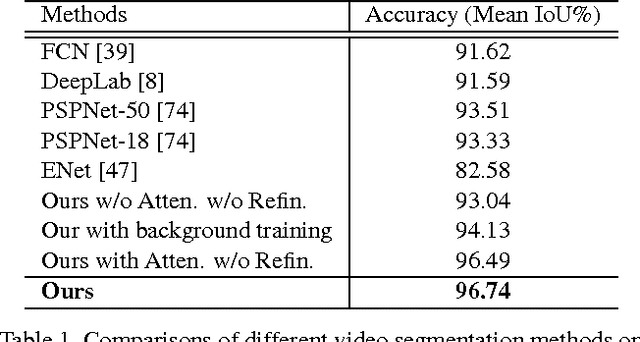

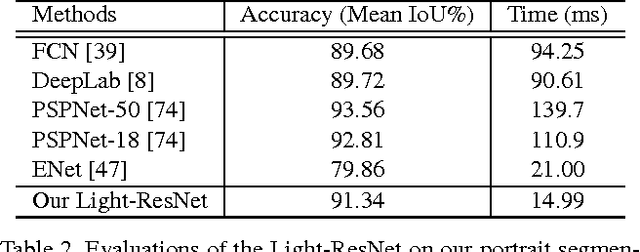
We in this paper solve the problem of high-quality automatic real-time background cut for 720p portrait videos. We first handle the background ambiguity issue in semantic segmentation by proposing a global background attenuation model. A spatial-temporal refinement network is developed to further refine the segmentation errors in each frame and ensure temporal coherence in the segmentation map. We form an end-to-end network for training and testing. Each module is designed considering efficiency and accuracy. We build a portrait dataset, which includes 8,000 images with high-quality labeled map for training and testing. To further improve the performance, we build a portrait video dataset with 50 sequences to fine-tune video segmentation. Our framework benefits many video processing applications.
Zero-order Reverse Filtering
Apr 13, 2017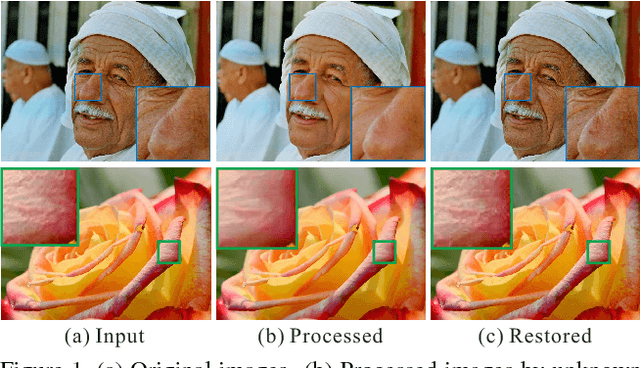

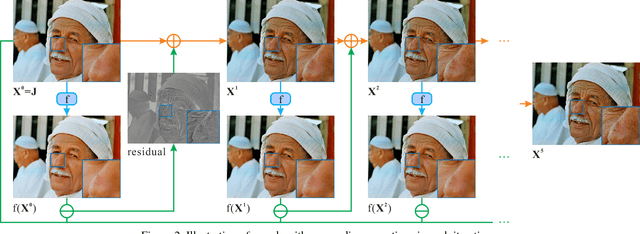

In this paper, we study an unconventional but practically meaningful reversibility problem of commonly used image filters. We broadly define filters as operations to smooth images or to produce layers via global or local algorithms. And we raise the intriguingly problem if they are reservable to the status before filtering. To answer it, we present a novel strategy to understand general filter via contraction mappings on a metric space. A very simple yet effective zero-order algorithm is proposed. It is able to practically reverse most filters with low computational cost. We present quite a few experiments in the paper and supplementary file to thoroughly verify its performance. This method can also be generalized to solve other inverse problems and enables new applications.
High-Quality Correspondence and Segmentation Estimation for Dual-Lens Smart-Phone Portraits
Apr 07, 2017
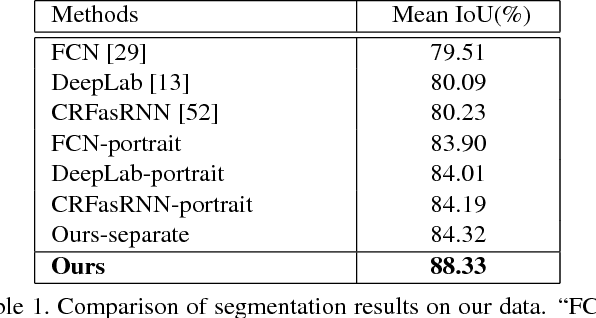

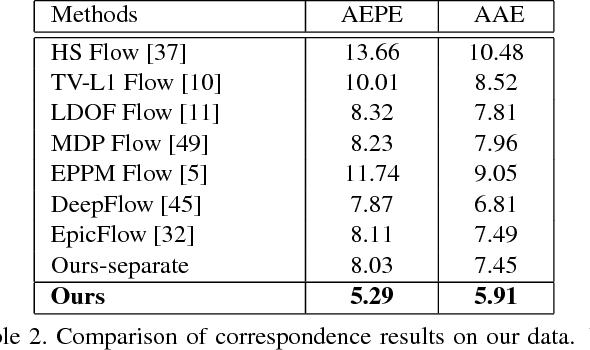
Estimating correspondence between two images and extracting the foreground object are two challenges in computer vision. With dual-lens smart phones, such as iPhone 7Plus and Huawei P9, coming into the market, two images of slightly different views provide us new information to unify the two topics. We propose a joint method to tackle them simultaneously via a joint fully connected conditional random field (CRF) framework. The regional correspondence is used to handle textureless regions in matching and make our CRF system computationally efficient. Our method is evaluated over 2,000 new image pairs, and produces promising results on challenging portrait images.
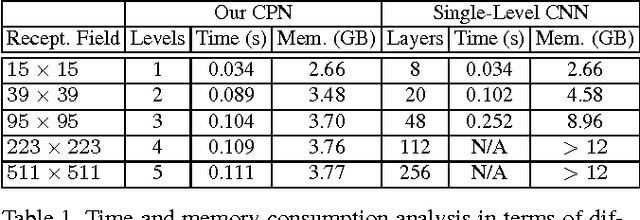
Convolutional Neural Pyramid for Image Processing
Apr 07, 2017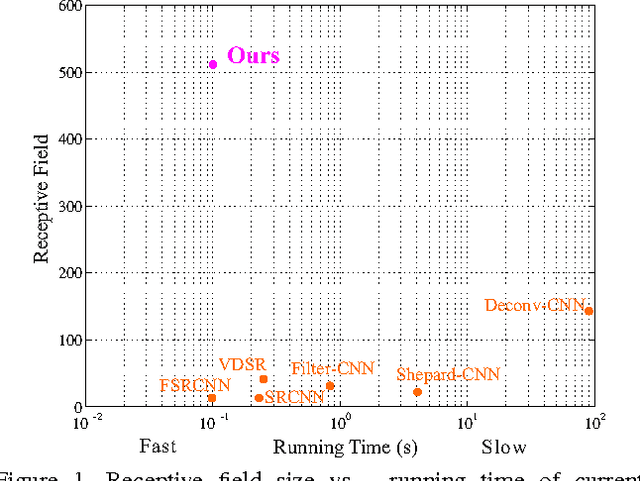


We propose a principled convolutional neural pyramid (CNP) framework for general low-level vision and image processing tasks. It is based on the essential finding that many applications require large receptive fields for structure understanding. But corresponding neural networks for regression either stack many layers or apply large kernels to achieve it, which is computationally very costly. Our pyramid structure can greatly enlarge the field while not sacrificing computation efficiency. Extra benefit includes adaptive network depth and progressive upsampling for quasi-realtime testing on VGA-size input. Our method profits a broad set of applications, such as depth/RGB image restoration, completion, noise/artifact removal, edge refinement, image filtering, image enhancement and colorization.