 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on ALOS2 SAR Utilization: Dataset Preparation, Self-Supervised Pretraining, and Semantic Segmentation
Mar 16, 2026Masked auto-encoders (MAE) and related approaches have shown promise for satellite imagery, but their application to synthetic aperture radar (SAR) remains limited due to challenges in semantic labeling and high noise levels. Building on our prior work with SAR-W-MixMAE, which adds SAR-specific intensity-weighted loss to standard MixMAE for pretraining, we also introduce SAR-W-SimMIM; a weighted variant of SimMIM applied to ALOS-2 single-channel SAR imagery. This method aims to reduce the impact of speckle and extreme intensity values during self-supervised pretraining. We evaluate its effect on semantic segmentation compared to our previous trial with SAR-W-MixMAE and random initialization, observing notable improvements. In addition, pretraining and fine-tuning models on satellite imagery pose unique challenges, particularly when developing region-specific models. Imbalanced land cover distributions such as dominant water, forest, or desert areas can introduce bias, affecting both pretraining and downstream tasks like land cover segmentation. To address this, we constructed a SAR dataset using ALOS-2 single-channel (HH polarization) imagery focused on the Japan region, marking the initial phase toward a national-scale foundation model. This dataset was used to pretrain a vision transformer-based autoencoder, with the resulting encoder fine-tuned for semantic segmentation using a task-specific decoder. Initial results demonstrate significant performance improvements compared to training from scratch with random initialization. In summary, this work provides a guide to process and prepare ALOS2 observations to create dataset so that it can be taken advantage of self-supervised pretraining of models and finetuning downstream tasks such as semantic segmentation.
Enhanced LULC Segmentation via Lightweight Model Refinements on ALOS-2 SAR Data
Jan 22, 2026This work focuses on national-scale land-use/land-cover (LULC) semantic segmentation using ALOS-2 single-polarization (HH) SAR data over Japan, together with a companion binary water detection task. Building on SAR-W-MixMAE self-supervised pretraining [1], we address common SAR dense-prediction failure modes, boundary over-smoothing, missed thin/slender structures, and rare-class degradation under long-tailed labels, without increasing pipeline complexity. We introduce three lightweight refinements: (i) injecting high-resolution features into multi-scale decoding, (ii) a progressive refine-up head that alternates convolutional refinement and stepwise upsampling, and (iii) an $α$-scale factor that tempers class reweighting within a focal+dice objective. The resulting model yields consistent improvements on the Japan-wide ALOS-2 LULC benchmark, particularly for under-represented classes, and improves water detection across standard evaluation metrics.
SAR-W-MixMAE: SAR Foundation Model Training Using Backscatter Power Weighting
Mar 04, 2025Foundation model approaches such as masked auto-encoders (MAE) or its variations are now being successfully applied to satellite imagery. Most of the ongoing technical validation of foundation models have been applied to optical images like RGB or multi-spectral images. Due to difficulty in semantic labeling to create datasets and higher noise content with respect to optical images, Synthetic Aperture Radar (SAR) data has not been explored a lot in the field for foundation models. Therefore, in this work as a pre-training approach, we explored masked auto-encoder, specifically MixMAE on Sentinel-1 SAR images and its impact on SAR image classification tasks. Moreover, we proposed to use the physical characteristic of SAR data for applying weighting parameter on the auto-encoder training loss (MSE) to reduce the effect of speckle noise and very high values on the SAR images. Proposed SAR intensity-based weighting of the reconstruction loss demonstrates promising results both on SAR pre-training and downstream tasks specifically on flood detection compared with the baseline model.
Salient object detection on hyperspectral images using features learned from unsupervised segmentation task
Feb 28, 2019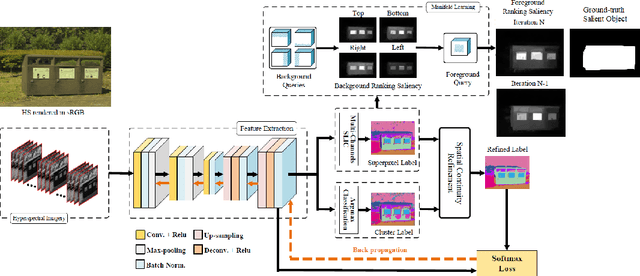
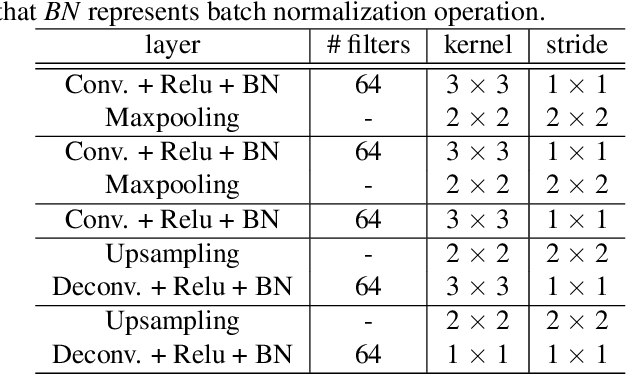
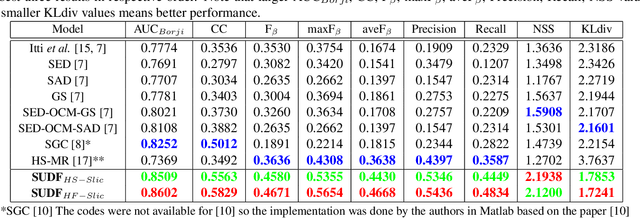

Various saliency detection algorithms from color images have been proposed to mimic eye fixation or attentive object detection response of human observers for the same scenes. However, developments on hyperspectral imaging systems enable us to obtain redundant spectral information of the observed scenes from the reflected light source from objects. A few studies using low-level features on hyperspectral images demonstrated that salient object detection can be achieved. In this work, we proposed a salient object detection model on hyperspectral images by applying manifold ranking (MR) on self-supervised Convolutional Neural Network (CNN) features (high-level features) from unsupervised image segmentation task. Self-supervision of CNN continues until clustering loss or saliency maps converges to a defined error between each iteration. Finally, saliency estimations is done as the saliency map at last iteration when the self-supervision procedure terminates with convergence. Experimental evaluations demonstrated that proposed saliency detection algorithm on hyperspectral images is outperforming state-of-the-arts hyperspectral saliency models including the original MR based saliency model.
Object Detection in Satellite Imagery using 2-Step Convolutional Neural Networks
Aug 09, 2018
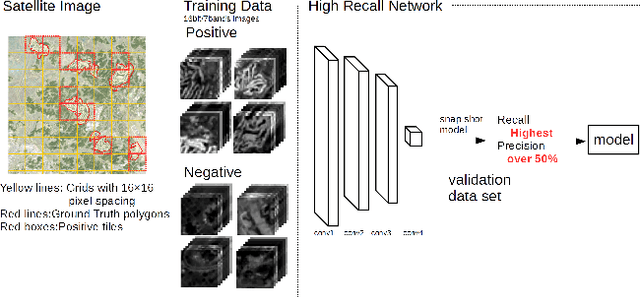
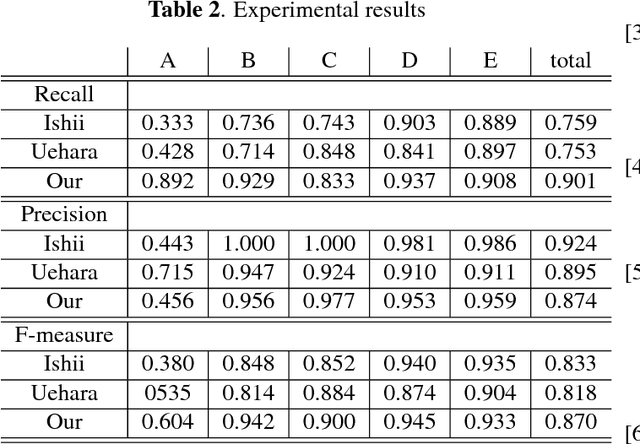
This paper presents an efficient object detection method from satellite imagery. Among a number of machine learning algorithms, we proposed a combination of two convolutional neural networks (CNN) aimed at high precision and high recall, respectively. We validated our models using golf courses as target objects. The proposed deep learning method demonstrated higher accuracy than previous object identification methods.
Hyperspectral Image Dataset for Benchmarking on Salient Object Detection
Jul 02, 2018


Many works have been done on salient object detection using supervised or unsupervised approaches on colour images. Recently, a few studies demonstrated that efficient salient object detection can also be implemented by using spectral features in visible spectrum of hyperspectral images from natural scenes. However, these models on hyperspectral salient object detection were tested with a very few number of data selected from various online public dataset, which are not specifically created for object detection purposes. Therefore, here, we aim to contribute to the field by releasing a hyperspectral salient object detection dataset with a collection of 60 hyperspectral images with their respective ground-truth binary images and representative rendered colour images (sRGB). We took several aspects in consideration during the data collection such as variation in object size, number of objects, foreground-background contrast, object position on the image, and etc. Then, we prepared ground truth binary images for each hyperspectral data, where salient objects are labelled on the images. Finally, we did performance evaluation using Area Under Curve (AUC) metric on some existing hyperspectral saliency detection models in literature.