 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Distributed Algorithm for Generalized Eigenvalue Problem
Oct 22, 2020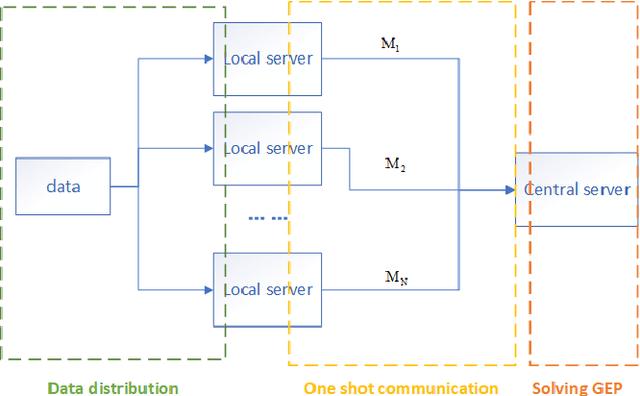
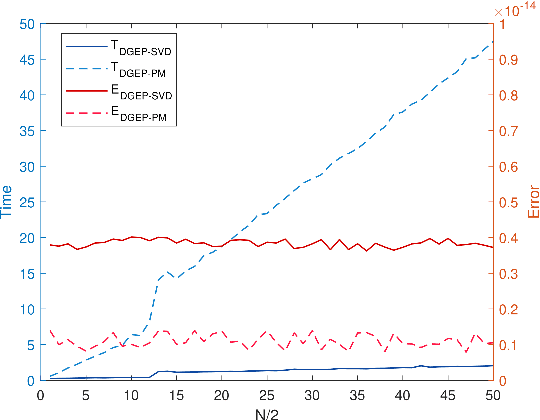
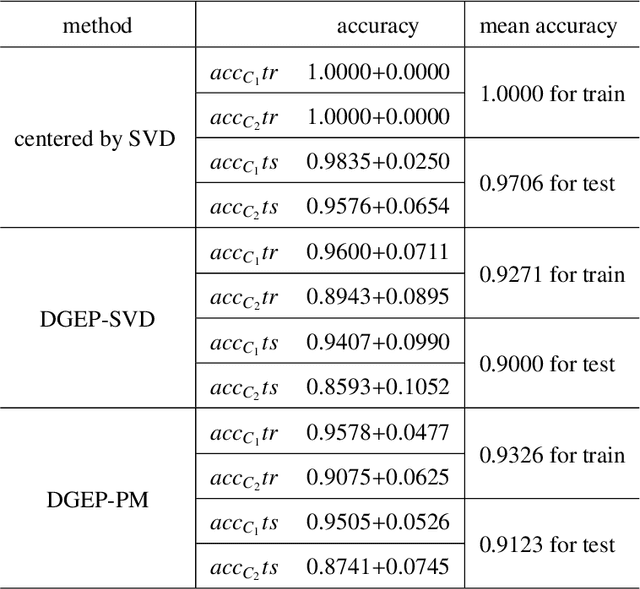

Nowadays, more and more datasets are stored in a distributed way for the sake of memory storage or data privacy. The generalized eigenvalue problem (GEP) plays a vital role in a large family of high-dimensional statistical models. However, the existing distributed method for eigenvalue decomposition cannot be applied in GEP for the divergence of the empirical covariance matrix. Here we propose a general distributed GEP framework with one-shot communication for GEP. If the symmetric data covariance has repeated eigenvalues, e.g., in canonical component analysis, we further modify the method for better convergence. The theoretical analysis on approximation error is conducted and the relation to the divergence of the data covariance, the eigenvalues of the empirical data covariance, and the number of local servers is analyzed. Numerical experiments also show the effectiveness of the proposed algorithms.
End-to-end Kernel Learning via Generative Random Fourier Features
Sep 10, 2020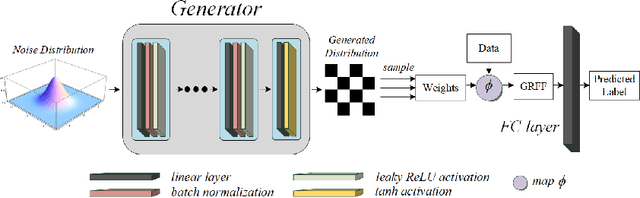
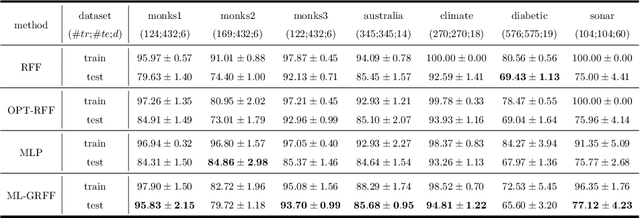
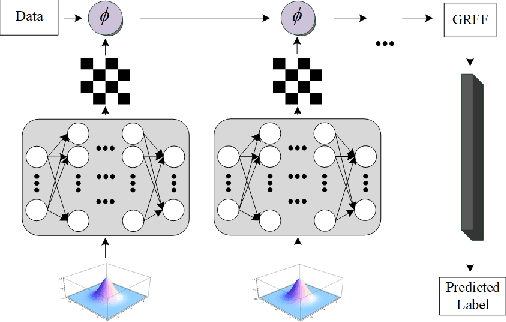
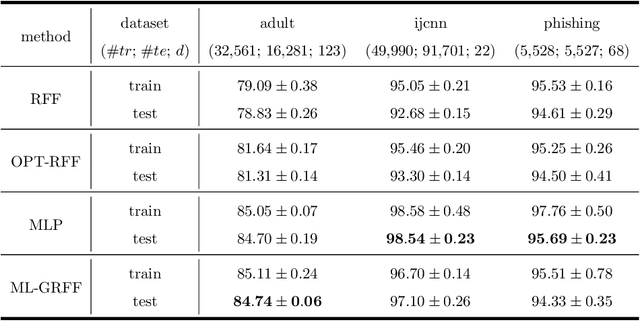
Random Fourier features enable researchers to build feature map to learn the spectral distribution of the underlying kernel. Current distribution-based methods follow a two-stage scheme: they first learn and optimize the feature map by solving the kernel alignment problem, then learn a linear classifier on the features. However, since the ideal kernel in kernel alignment problem is not necessarily optimal in classification tasks, the generalization performance of the random features learned in this two-stage manner can perhaps be further improved. To address this issue, we propose an end-to-end, one-stage kernel learning approach, called generative random Fourier features, which jointly learns the features and the classifier. A generative network is involved to implicitly learn and to sample from the distribution of the latent kernel. Random features are then built via the generative weights and followed by a linear classifier parameterized as a full-connected layer. We jointly train the generative network and the classifier by solving the empirical risk minimization problem for a one-stage solution. Straightly minimizing the loss between predictive and true labels brings better generalization performance. Besides, this end-to-end strategy allows us to increase the depth of features, resulting in multi-layer architecture and exhibiting strong linear-separable pattern. Empirical results demonstrate the superiority of our method in classification tasks over other two-stage kernel learning methods. Finally, we investigate the robustness of proposed method in defending adversarial attacks, which shows that the randomization and resampling mechanism associated with the learned distribution can alleviate the performance decrease brought by adversarial examples.
Attack on Multi-Node Attention for Object Detection
Aug 16, 2020
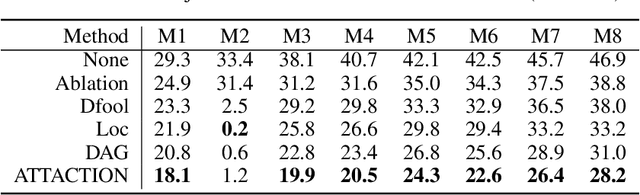
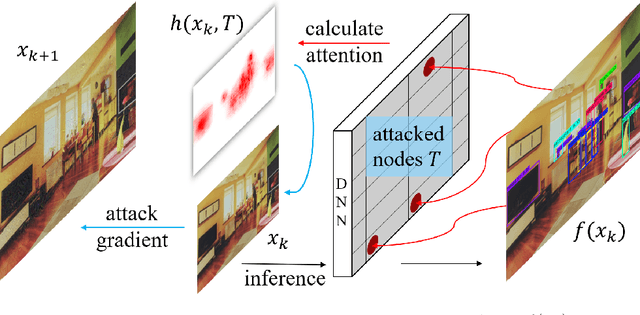
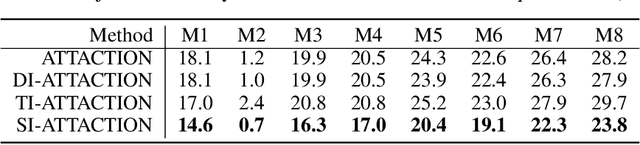
This paper focuses on high-transferable adversarial attacks on detection networks, which are crucial for life-concerning systems such as autonomous driving and security surveillance. Detection networks are hard to attack in a black-box manner, because of their multiple-output property and diversity across architectures. To pursue a high attacking transferability, one needs to find a common property shared by different models. Multi-node attention heat map obtained by our newly proposed method is such a property. Based on it, we design the ATTACk on multi-node attenTION for object detecTION (ATTACTION). ATTACTION achieves a state-of-the-art transferability in numerical experiments. On MS COCO, the detection mAP for all 7 tested black-box architectures is halved and the performance of semantic segmentation is greatly influenced. Given the great transferability of ATTACTION, we generate Adversarial Objects in COntext (AOCO), the first adversarial dataset on object detection networks, which could help designers to quickly evaluate and improve the robustness of detection networks.
Analysis of Least Squares Regularized Regression in Reproducing Kernel Krein Spaces
Jun 01, 2020
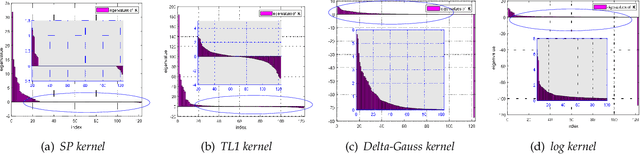
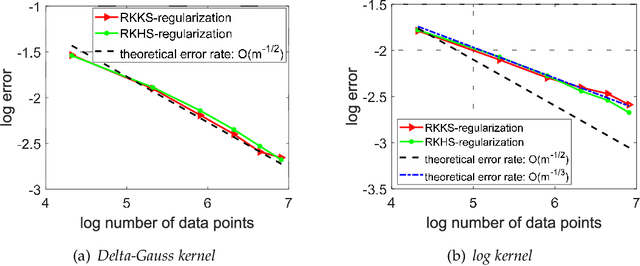
In this paper, we study the asymptotical properties of least squares regularized regression with indefinite kernels in reproducing kernel Kre\u{\i}n spaces (RKKS). The classical approximation analysis cannot be directly applied to study its asymptotical behavior under the framework of learning theory as this problem is in essence non-convex and outputs stationary points. By introducing a bounded hyper-sphere constraint to such non-convex regularized risk minimization problem, we theoretically demonstrate that this problem has a globally optimal solution with a closed form on the sphere, which makes our approximation analysis feasible in RKKS. Accordingly, we modify traditional error decomposition techniques, prove convergence results for the introduced hypothesis error based on matrix perturbation theory, and derive learning rates of such regularized regression problem in RKKS. Under some conditions, the derived learning rates in RKKS are the same as that in reproducing kernel Hilbert spaces (RKHS), which is actually the first work on approximation analysis of regularized learning algorithms in RKKS.
Generalizing Random Fourier Features via Generalized Measures
May 30, 2020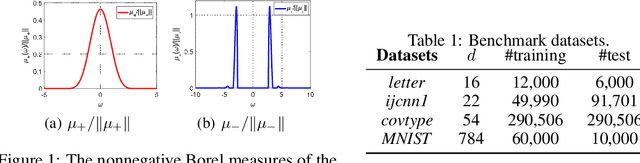
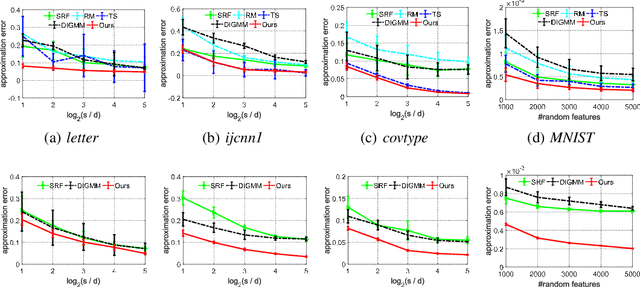
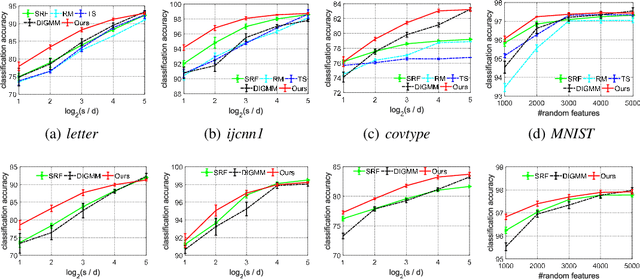
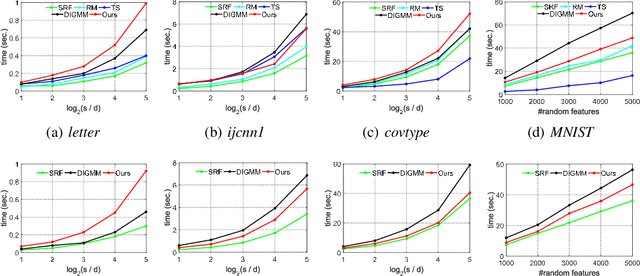
We generalize random Fourier features, that usually require kernel functions to be both stationary and positive definite (PD), to a more general range of non-stationary or/and non-PD kernels, e.g., dot-product kernels on the unit sphere and a linear combination of positive definite kernels. Specifically, we find that the popular neural tangent kernel in two-layer ReLU network, a typical dot-product kernel, is shift-invariant but not positive definite if we consider $\ell_2$-normalized data. By introducing the signed measure, we propose a general framework that covers the above kernels by associating them with specific finite Borel measures, i.e., probability distributions. In this manner, we are able to provide the first random features algorithm to obtain unbiased estimation of these kernels. Experiments on several benchmark datasets verify the effectiveness of our algorithm over the existing methods. Last but not least, our work provides a sufficient and necessary condition, which is also computationally implementable, to solve a long-lasting open question: does any indefinite kernel have a positive decomposition?
A Communication-Efficient Distributed Algorithm for Kernel Principal Component Analysis
May 06, 2020
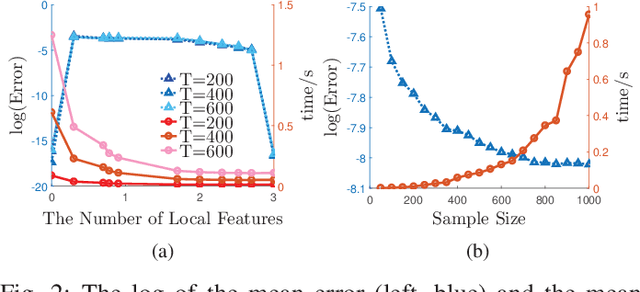
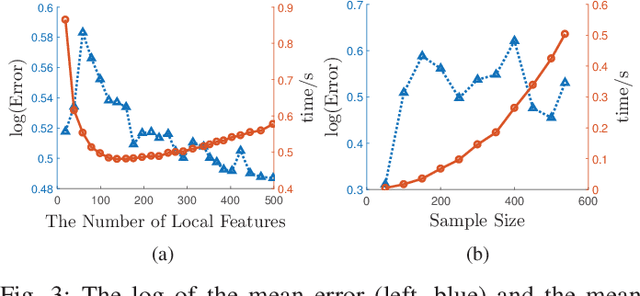
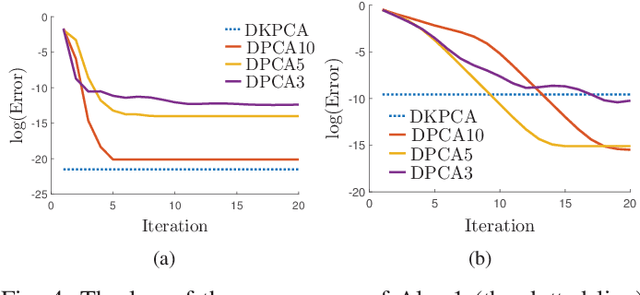
Principal Component Analysis (PCA) is a fundamental technology in machine learning. Nowadays many high-dimension large datasets are acquired in a distributed manner, which precludes the use of centralized PCA due to the high communication cost and privacy risk. Thus, many distributed PCA algorithms are proposed, most of which, however, focus on linear cases. To efficiently extract non-linear features, this brief proposes a communication-efficient distributed kernel PCA algorithm, where linear and RBF kernels are applied. The key is to estimate the global empirical kernel matrix from the eigenvectors of local kernel matrices. The approximate error of the estimators is theoretically analyzed for both linear and RBF kernels. The result suggests that when eigenvalues decay fast, which is common for RBF kernels, the proposed algorithm gives high quality results with low communication cost. Results of simulation experiments verify our theory analysis and experiments on GSE2187 dataset show the effectiveness of the proposed algorithm.
Random Features for Kernel Approximation: A Survey in Algorithms, Theory, and Beyond
Apr 24, 2020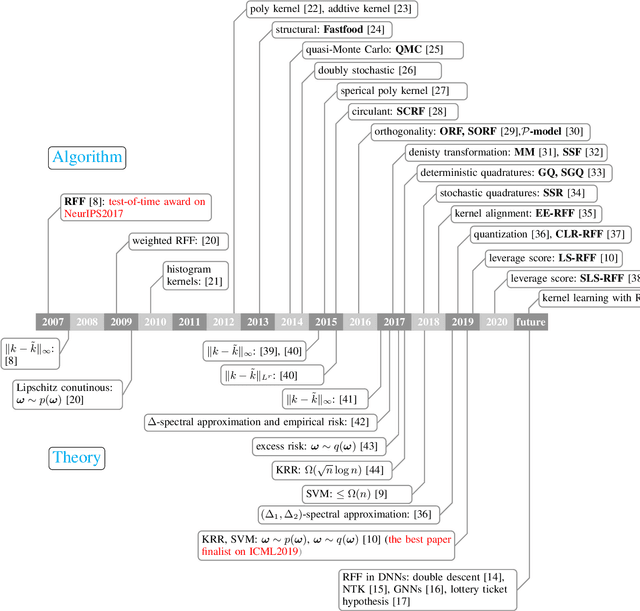
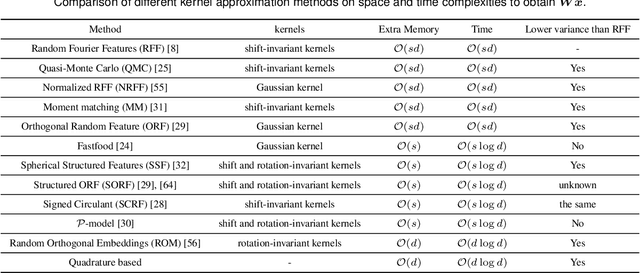


Random features is one of the most sought-after research topics in statistical machine learning to speed up kernel methods in large-scale situations. Related works have won the NeurIPS test-of-time award in 2017 and the ICML best paper finalist in 2019. However, comprehensive studies on this topic seem to be missing, which results in different, sometimes conflicting, statements. In this survey, we attempt to throughout and systematically review the past ten years work on random features regarding to algorithmic and theoretical aspects. First, the fundamental characteristics, primary motivations, and contributions of representative random features based algorithms are summarized according to their sampling scheme, learning procedure, variance reduction, and exploitation of training data. Second, we review theoretical results of random features to answer the key question: how many random features are needed to ensure a high approximation quality or no loss of empirical risk and expected risk in a learning estimator. Third, popular random features based algorithms are comprehensively evaluated on several large scale benchmark datasets on the approximation quality and the prediction performance for classification and regression. Last, we link random features to current over-parameterized deep neural networks (DNNs) by investigating their relationships, the usage of random features to analysis over-parameterized networks, and the gap in the current theoretical results. As a result, this survey could be a gentle use guide for practitioners to follow this topic, apply representative algorithms, and grasp theoretical results under various technical assumptions. We think that this survey helps to facilitate a discussion on ongoing issues for this topic, and specifically, it sheds light on promising research directions.
Sparse Generalized Canonical Correlation Analysis: Distributed Alternating Iteration based Approach
Apr 23, 2020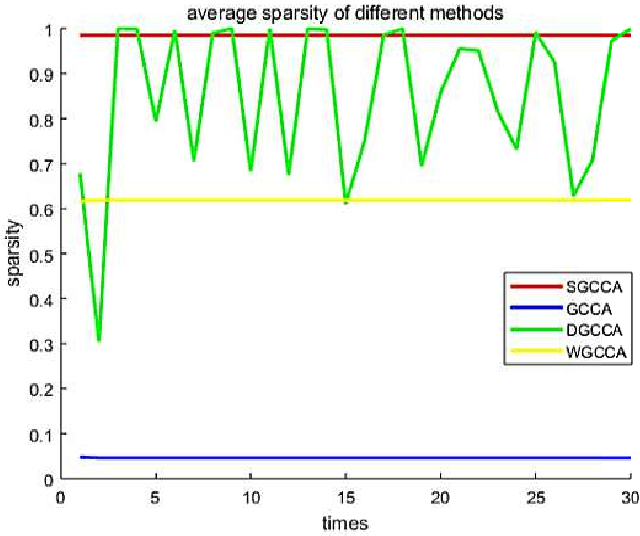
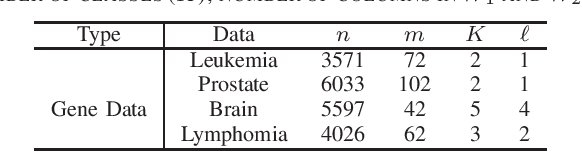
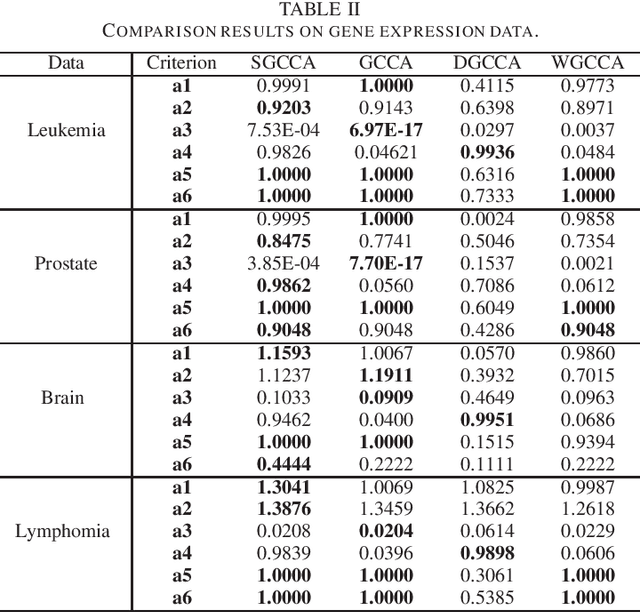
Sparse canonical correlation analysis (CCA) is a useful statistical tool to detect latent information with sparse structures. However, sparse CCA works only for two datasets, i.e., there are only two views or two distinct objects. To overcome this limitation, in this paper, we propose a sparse generalized canonical correlation analysis (GCCA), which could detect the latent relations of multiview data with sparse structures. Moreover, the introduced sparsity could be considered as Laplace prior on the canonical variates. Specifically, we convert the GCCA into a linear system of equations and impose $\ell_1$ minimization penalty for sparsity pursuit. This results in a nonconvex problem on Stiefel manifold, which is difficult to solve. Motivated by Boyd's consensus problem, an algorithm based on distributed alternating iteration approach is developed and theoretical consistency analysis is investigated elaborately under mild conditions. Experiments on several synthetic and real world datasets demonstrate the effectiveness of the proposed algorithm.
Adversarial Imitation Attack
Mar 31, 2020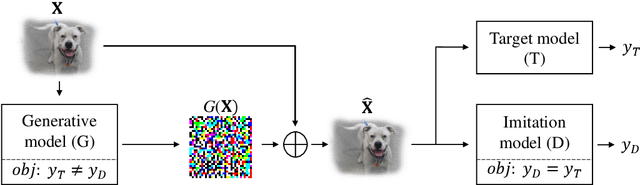
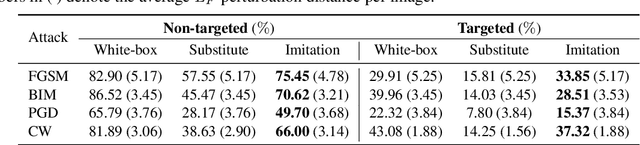
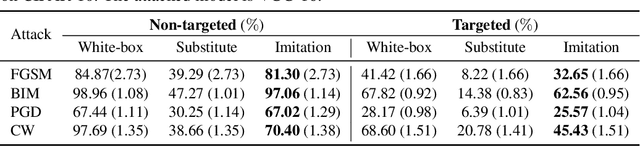

Deep learning models are known to be vulnerable to adversarial examples. A practical adversarial attack should require as little as possible knowledge of attacked models. Current substitute attacks need pre-trained models to generate adversarial examples and their attack success rates heavily rely on the transferability of adversarial examples. Current score-based and decision-based attacks require lots of queries for the attacked models. In this study, we propose a novel adversarial imitation attack. First, it produces a replica of the attacked model by a two-player game like the generative adversarial networks (GANs). The objective of the generative model is to generate examples that lead the imitation model returning different outputs with the attacked model. The objective of the imitation model is to output the same labels with the attacked model under the same inputs. Then, the adversarial examples generated by the imitation model are utilized to fool the attacked model. Compared with the current substitute attacks, imitation attacks can use less training data to produce a replica of the attacked model and improve the transferability of adversarial examples. Experiments demonstrate that our imitation attack requires less training data than the black-box substitute attacks, but achieves an attack success rate close to the white-box attack on unseen data with no query.
Stereo Endoscopic Image Super-Resolution Using Disparity-Constrained Parallel Attention
Mar 19, 2020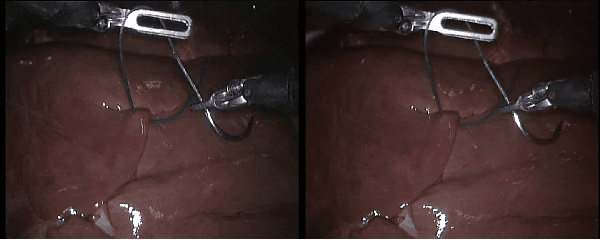
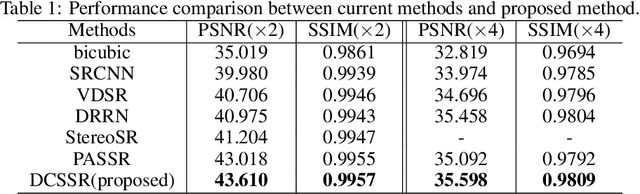
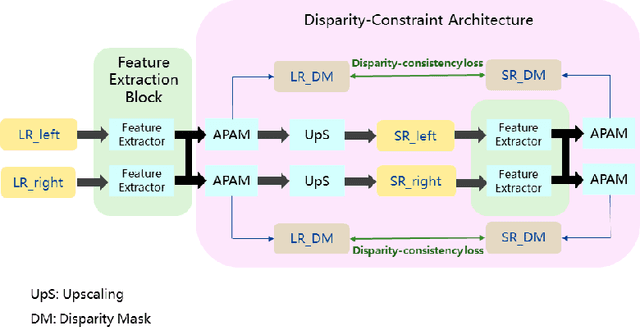
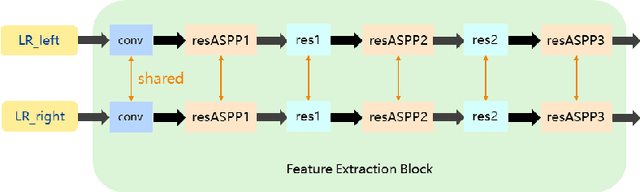
With the popularity of stereo cameras in computer assisted surgery techniques, a second viewpoint would provide additional information in surgery. However, how to effectively access and use stereo information for the super-resolution (SR) purpose is often a challenge. In this paper, we propose a disparity-constrained stereo super-resolution network (DCSSRnet) to simultaneously compute a super-resolved image in a stereo image pair. In particular, we incorporate a disparity-based constraint mechanism into the generation of SR images in a deep neural network framework with an additional atrous parallax-attention modules. Experiment results on laparoscopic images demonstrate that the proposed framework outperforms current SR methods on both quantitative and qualitative evaluations. Our DCSSRnet provides a promising solution on enhancing spatial resolution of stereo image pairs, which will be extremely beneficial for the endoscopic surgery.