 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Node Matching for Multi-Target Cross Domain Recommendation
Feb 12, 2023



Multi-Target Cross Domain Recommendation(CDR) has attracted a surge of interest recently, which intends to improve the recommendation performance in multiple domains (or systems) simultaneously. Most existing multi-target CDR frameworks primarily rely on the existence of the majority of overlapped users across domains. However, general practical CDR scenarios cannot meet the strictly overlapping requirements and only share a small margin of common users across domains}. Additionally, the majority of users have quite a few historical behaviors in such small-overlapping CDR scenarios}. To tackle the aforementioned issues, we propose a simple-yet-effective neural node matching based framework for more general CDR settings, i.e., only (few) partially overlapped users exist across domains and most overlapped as well as non-overlapped users do have sparse interactions. The present framework} mainly contains two modules: (i) intra-to-inter node matching module, and (ii) intra node complementing module. Concretely, the first module conducts intra-knowledge fusion within each domain and subsequent inter-knowledge fusion across domains by fully connected user-user homogeneous graph information aggregating.
* 13pages
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023



Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
Adaptive Pattern Extraction Multi-Task Learning for Multi-Step Conversion Estimations
Jan 23, 2023



Multi-task learning (MTL) has been successfully used in many real-world applications, which aims to simultaneously solve multiple tasks with a single model. The general idea of multi-task learning is designing kinds of global parameter sharing mechanism and task-specific feature extractor to improve the performance of all tasks. However, challenge still remains in balancing the trade-off of various tasks since model performance is sensitive to the relationships between them. Less correlated or even conflict tasks will deteriorate the performance by introducing unhelpful or negative information. Therefore, it is important to efficiently exploit and learn fine-grained feature representation corresponding to each task. In this paper, we propose an Adaptive Pattern Extraction Multi-task (APEM) framework, which is adaptive and flexible for large-scale industrial application. APEM is able to fully utilize the feature information by learning the interactions between the input feature fields and extracted corresponding tasks-specific information. We first introduce a DeepAuto Group Transformer module to automatically and efficiently enhance the feature expressivity with a modified set attention mechanism and a Squeeze-and-Excitation operation. Second, explicit Pattern Selector is introduced to further enable selectively feature representation learning by adaptive task-indicator vectors. Empirical evaluations show that APEM outperforms the state-of-the-art MTL methods on public and real-world financial services datasets. More importantly, we explore the online performance of APEM in a real industrial-level recommendation scenario.
Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation
Nov 30, 2022In recent years, semi-supervised graph learning with data augmentation (DA) is currently the most commonly used and best-performing method to enhance model robustness in sparse scenarios with few labeled samples. Differing from homogeneous graph, DA in heterogeneous graph has greater challenges: heterogeneity of information requires DA strategies to effectively handle heterogeneous relations, which considers the information contribution of different types of neighbors and edges to the target nodes. Furthermore, over-squashing of information is caused by the negative curvature that formed by the non-uniformity distribution and strong clustering in complex graph. To address these challenges, this paper presents a novel method named Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation (HG-MDA). For the problem of heterogeneity of information in DA, node and topology augmentation strategies are proposed for the characteristics of heterogeneous graph. And meta-relation-based attention is applied as one of the indexes for selecting augmented nodes and edges. For the problem of over-squashing of information, triangle based edge adding and removing are designed to alleviate the negative curvature and bring the gain of topology. Finally, the loss function consists of the cross-entropy loss for labeled data and the consistency regularization for unlabeled data. In order to effectively fuse the prediction results of various DA strategies, the sharpening is used. Existing experiments on public datasets, i.e., ACM, DBLP, OGB, and industry dataset MB show that HG-MDA outperforms current SOTA models. Additionly, HG-MDA is applied to user identification in internet finance scenarios, helping the business to add 30% key users, and increase loans and balances by 3.6%, 11.1%, and 9.8%.
HGV4Risk: Hierarchical Global View-guided Sequence Representation Learning for Risk Prediction
Nov 15, 2022



Risk prediction, as a typical time series modeling problem, is usually achieved by learning trends in markers or historical behavior from sequence data, and has been widely applied in healthcare and finance. In recent years, deep learning models, especially Long Short-Term Memory neural networks (LSTMs), have led to superior performances in such sequence representation learning tasks. Despite that some attention or self-attention based models with time-aware or feature-aware enhanced strategies have achieved better performance compared with other temporal modeling methods, such improvement is limited due to a lack of guidance from global view. To address this issue, we propose a novel end-to-end Hierarchical Global View-guided (HGV) sequence representation learning framework. Specifically, the Global Graph Embedding (GGE) module is proposed to learn sequential clip-aware representations from temporal correlation graph at instance level. Furthermore, following the way of key-query attention, the harmonic $\beta$-attention ($\beta$-Attn) is also developed for making a global trade-off between time-aware decay and observation significance at channel level adaptively. Moreover, the hierarchical representations at both instance level and channel level can be coordinated by the heterogeneous information aggregation under the guidance of global view. Experimental results on a benchmark dataset for healthcare risk prediction, and a real-world industrial scenario for Small and Mid-size Enterprises (SMEs) credit overdue risk prediction in MYBank, Ant Group, have illustrated that the proposed model can achieve competitive prediction performance compared with other known baselines.
Cross-Architecture Self-supervised Video Representation Learning
May 26, 2022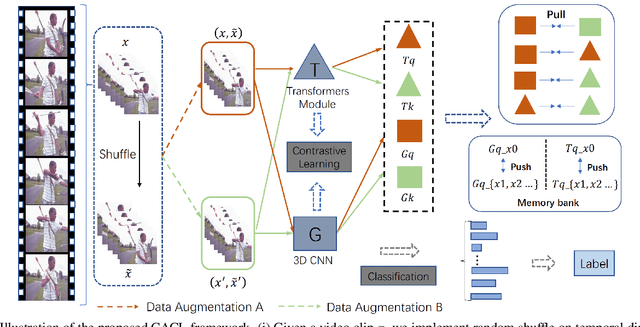
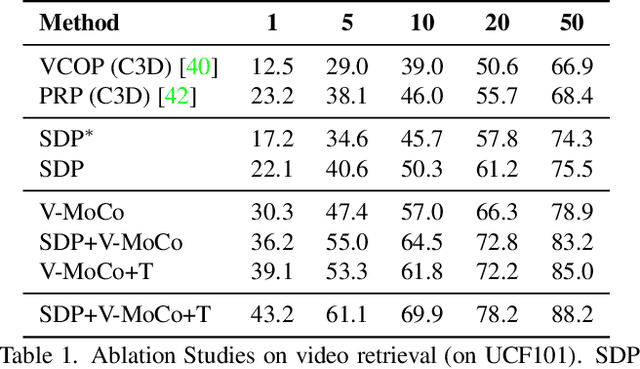
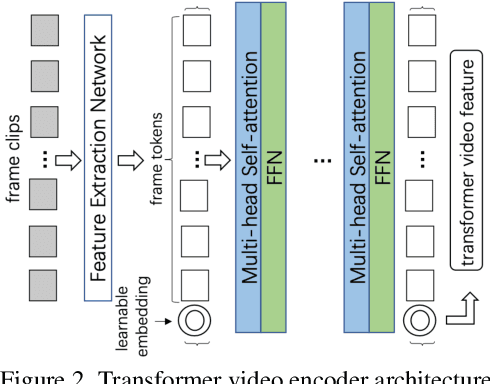
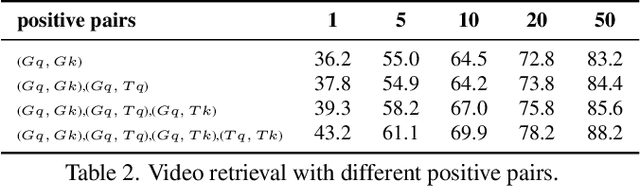
In this paper, we present a new cross-architecture contrastive learning (CACL) framework for self-supervised video representation learning. CACL consists of a 3D CNN and a video transformer which are used in parallel to generate diverse positive pairs for contrastive learning. This allows the model to learn strong representations from such diverse yet meaningful pairs. Furthermore, we introduce a temporal self-supervised learning module able to predict an Edit distance explicitly between two video sequences in the temporal order. This enables the model to learn a rich temporal representation that compensates strongly to the video-level representation learned by the CACL. We evaluate our method on the tasks of video retrieval and action recognition on UCF101 and HMDB51 datasets, where our method achieves excellent performance, surpassing the state-of-the-art methods such as VideoMoCo and MoCo+BE by a large margin. The code is made available at https://github.com/guoshengcv/CACL.
Poincaré Heterogeneous Graph Neural Networks for Sequential Recommendation
May 16, 2022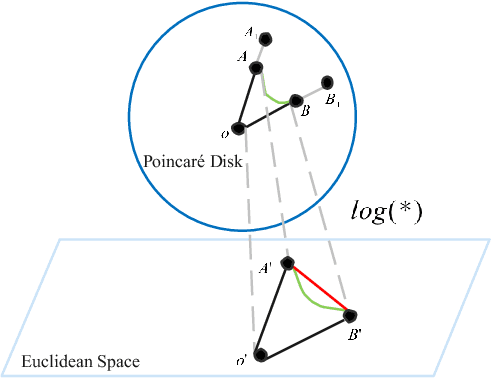

Sequential recommendation (SR) learns users' preferences by capturing the sequential patterns from users' behaviors evolution. As discussed in many works, user-item interactions of SR generally present the intrinsic power-law distribution, which can be ascended to hierarchy-like structures. Previous methods usually handle such hierarchical information by making user-item sectionalization empirically under Euclidean space, which may cause distortion of user-item representation in real online scenarios. In this paper, we propose a Poincar\'{e}-based heterogeneous graph neural network named PHGR to model the sequential pattern information as well as hierarchical information contained in the data of SR scenarios simultaneously. Specifically, for the purpose of explicitly capturing the hierarchical information, we first construct a weighted user-item heterogeneous graph by aliening all the user-item interactions to improve the perception domain of each user from a global view. Then the output of the global representation would be used to complement the local directed item-item homogeneous graph convolution. By defining a novel hyperbolic inner product operator, the global and local graph representation learning are directly conducted in Poincar\'{e} ball instead of commonly used projection operation between Poincar\'{e} ball and Euclidean space, which could alleviate the cumulative error issue of general bidirectional translation process. Moreover, for the purpose of explicitly capturing the sequential dependency information, we design two types of temporal attention operations under Poincar\'{e} ball space. Empirical evaluations on datasets from the public and financial industry show that PHGR outperforms several comparison methods.
MHSCNet: A Multimodal Hierarchical Shot-aware Convolutional Network for Video Summarization
Apr 19, 2022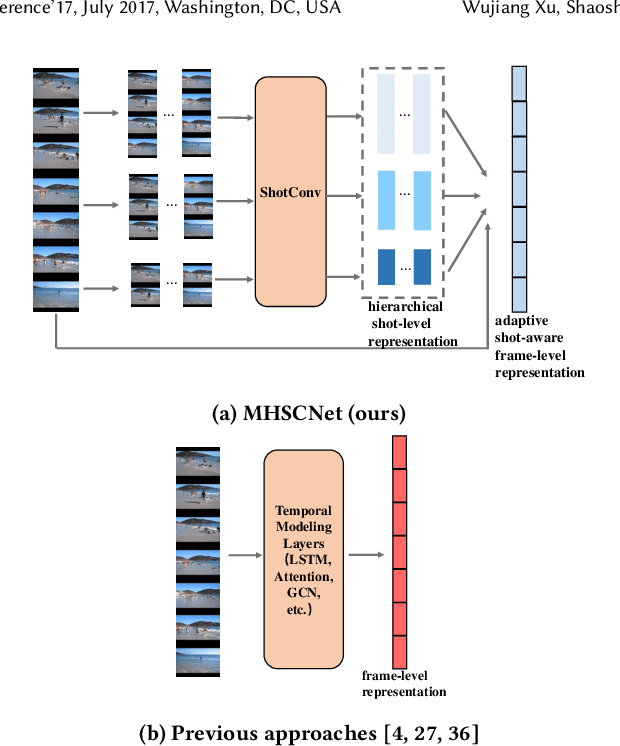
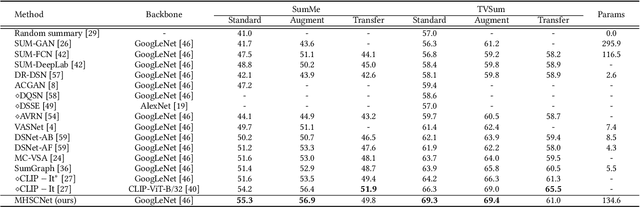
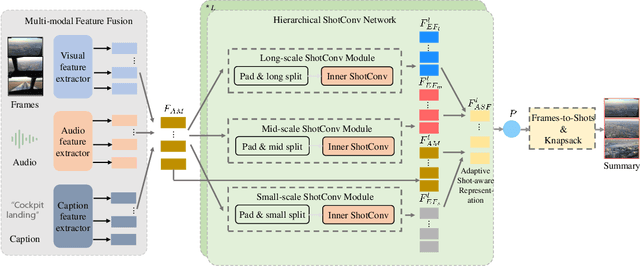
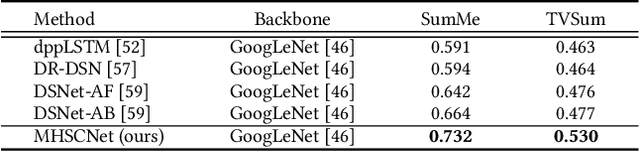
Video summarization intends to produce a concise video summary by effectively capturing and combining the most informative parts of the whole content. Existing approaches for video summarization regard the task as a frame-wise keyframe selection problem and generally construct the frame-wise representation by combining the long-range temporal dependency with the unimodal or bimodal information. However, the optimal video summaries need to reflect the most valuable keyframe with its own information, and one with semantic power of the whole content. Thus, it is critical to construct a more powerful and robust frame-wise representation and predict the frame-level importance score in a fair and comprehensive manner. To tackle the above issues, we propose a multimodal hierarchical shot-aware convolutional network, denoted as MHSCNet, to enhance the frame-wise representation via combining the comprehensive available multimodal information. Specifically, we design a hierarchical ShotConv network to incorporate the adaptive shot-aware frame-level representation by considering the short-range and long-range temporal dependency. Based on the learned shot-aware representations, MHSCNet can predict the frame-level importance score in the local and global view of the video. Extensive experiments on two standard video summarization datasets demonstrate that our proposed method consistently outperforms state-of-the-art baselines. Source code will be made publicly available.
Emotion-based Modeling of Mental Disorders on Social Media
Jan 24, 2022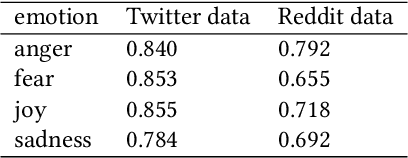
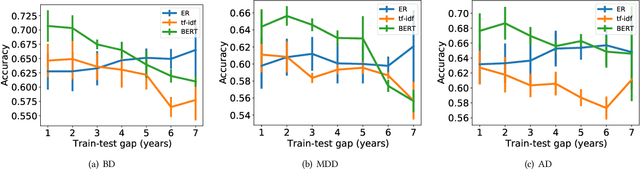

According to the World Health Organization (WHO), one in four people will be affected by mental disorders at some point in their lives. However, in many parts of the world, patients do not actively seek professional diagnosis because of stigma attached to mental illness, ignorance of mental health and its associated symptoms. In this paper, we propose a model for passively detecting mental disorders using conversations on Reddit. Specifically, we focus on a subset of mental disorders that are characterized by distinct emotional patterns (henceforth called emotional disorders): major depressive, anxiety, and bipolar disorders. Through passive (i.e., unprompted) detection, we can encourage patients to seek diagnosis and treatment for mental disorders. Our proposed model is different from other work in this area in that our model is based entirely on the emotional states, and the transition between these states of users on Reddit, whereas prior work is typically based on content-based representations (e.g., n-grams, language model embeddings, etc). We show that content-based representation is affected by domain and topic bias and thus does not generalize, while our model, on the other hand, suppresses topic-specific information and thus generalizes well across different topics and times. We conduct experiments on our model's ability to detect different emotional disorders and on the generalizability of our model. Our experiments show that while our model performs comparably to content-based models, such as BERT, it generalizes much better across time and topic.
HCGR: Hyperbolic Contrastive Graph Representation Learning for Session-based Recommendation
Jul 06, 2021

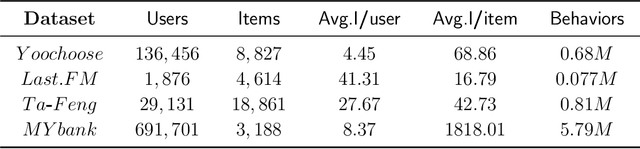
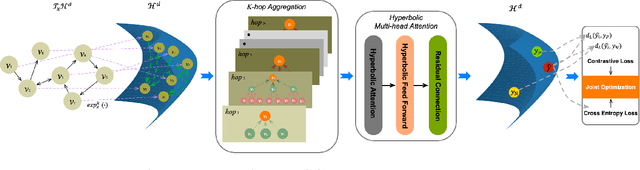
Session-based recommendation (SBR) learns users' preferences by capturing the short-term and sequential patterns from the evolution of user behaviors. Among the studies in the SBR field, graph-based approaches are a relatively powerful kind of way, which generally extract item information by message aggregation under Euclidean space. However, such methods can't effectively extract the hierarchical information contained among consecutive items in a session, which is critical to represent users' preferences. In this paper, we present a hyperbolic contrastive graph recommender (HCGR), a principled session-based recommendation framework involving Lorentz hyperbolic space to adequately capture the coherence and hierarchical representations of the items. Within this framework, we design a novel adaptive hyperbolic attention computation to aggregate the graph message of each user's preference in a session-based behavior sequence. In addition, contrastive learning is leveraged to optimize the item representation by considering the geodesic distance between positive and negative samples in hyperbolic space. Extensive experiments on four real-world datasets demonstrate that HCGR consistently outperforms state-of-the-art baselines by 0.43$\%$-28.84$\%$ in terms of $HitRate$, $NDCG$ and $MRR$.