 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiMiGUE: An Identity-free Video Dataset for Micro-Gesture Understanding and Emotion Analysis
Jul 01, 2021
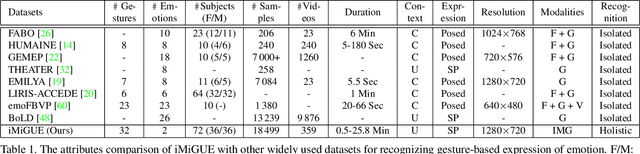
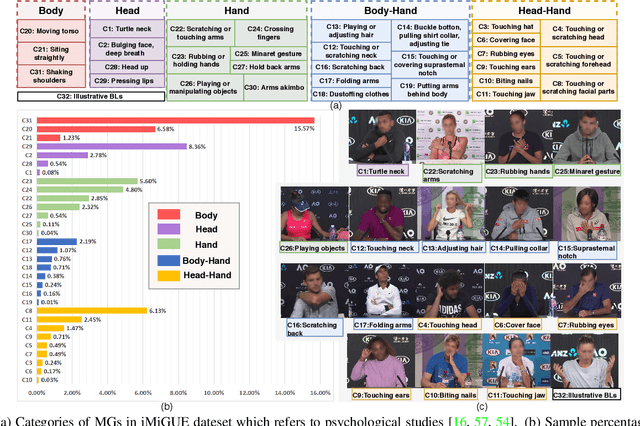
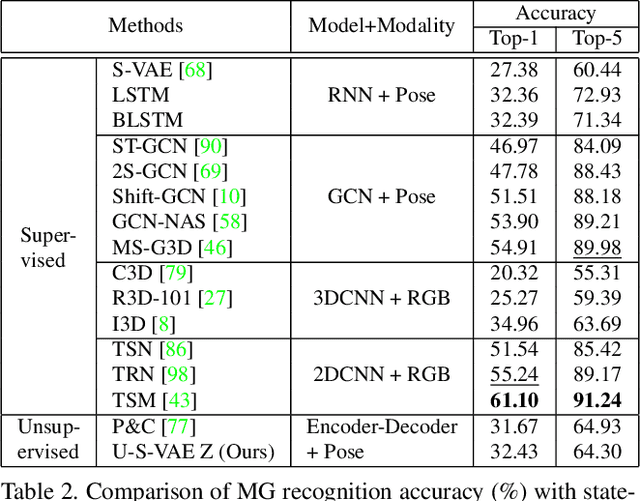
We introduce a new dataset for the emotional artificial intelligence research: identity-free video dataset for Micro-Gesture Understanding and Emotion analysis (iMiGUE). Different from existing public datasets, iMiGUE focuses on nonverbal body gestures without using any identity information, while the predominant researches of emotion analysis concern sensitive biometric data, like face and speech. Most importantly, iMiGUE focuses on micro-gestures, i.e., unintentional behaviors driven by inner feelings, which are different from ordinary scope of gestures from other gesture datasets which are mostly intentionally performed for illustrative purposes. Furthermore, iMiGUE is designed to evaluate the ability of models to analyze the emotional states by integrating information of recognized micro-gesture, rather than just recognizing prototypes in the sequences separately (or isolatedly). This is because the real need for emotion AI is to understand the emotional states behind gestures in a holistic way. Moreover, to counter for the challenge of imbalanced sample distribution of this dataset, an unsupervised learning method is proposed to capture latent representations from the micro-gesture sequences themselves. We systematically investigate representative methods on this dataset, and comprehensive experimental results reveal several interesting insights from the iMiGUE, e.g., micro-gesture-based analysis can promote emotion understanding. We confirm that the new iMiGUE dataset could advance studies of micro-gesture and emotion AI.
Deep Learning for Face Anti-Spoofing: A Survey
Jun 28, 2021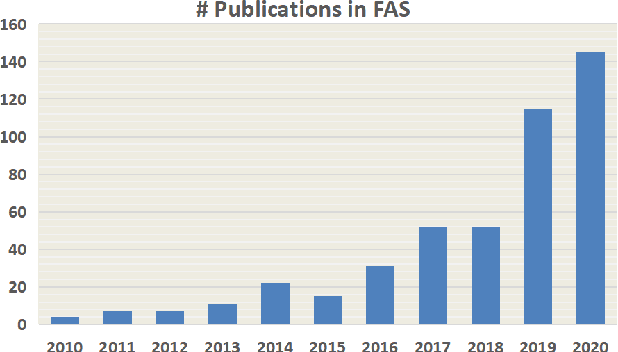
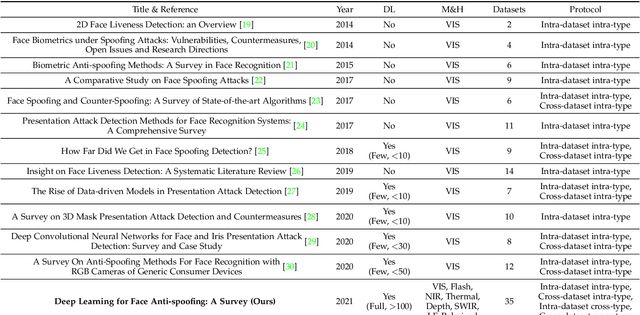
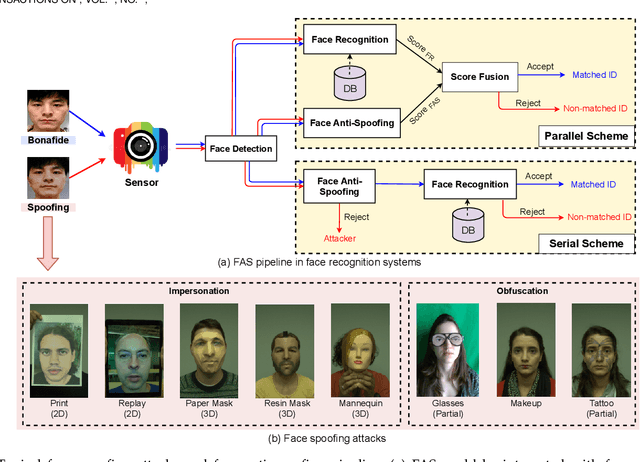
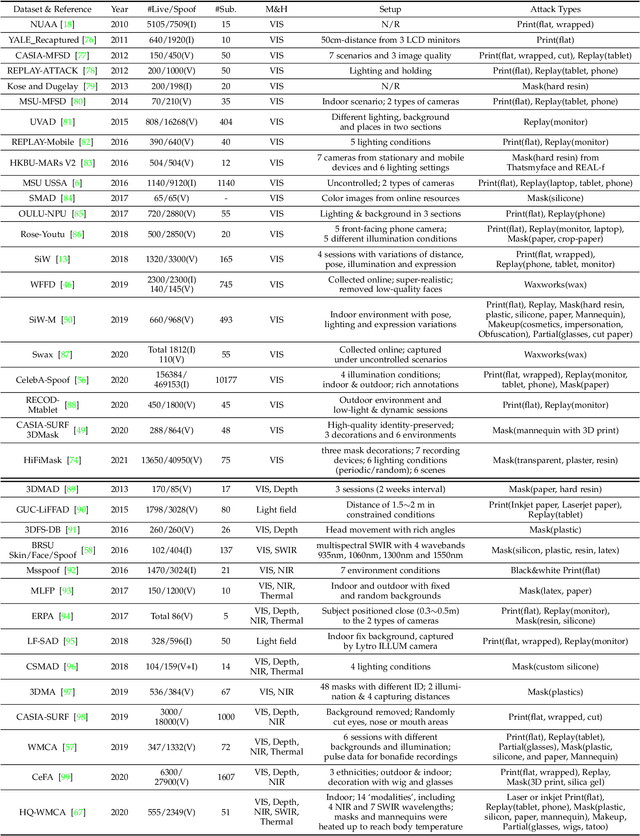
Face anti-spoofing (FAS) has lately attracted increasing attention due to its vital role in securing face recognition systems from presentation attacks (PAs). As more and more realistic PAs with novel types spring up, traditional FAS methods based on handcrafted features become unreliable due to their limited representation capacity. With the emergence of large-scale academic datasets in the recent decade, deep learning based FAS achieves remarkable performance and dominates this area. However, existing reviews in this field mainly focus on the handcrafted features, which are outdated and uninspiring for the progress of FAS community. In this paper, to stimulate future research, we present the first comprehensive review of recent advances in deep learning based FAS. It covers several novel and insightful components: 1) besides supervision with binary label (e.g., '0' for bonafide vs. '1' for PAs), we also investigate recent methods with pixel-wise supervision (e.g., pseudo depth map); 2) in addition to traditional intra-dataset evaluation, we collect and analyze the latest methods specially designed for domain generalization and open-set FAS; and 3) besides commercial RGB camera, we summarize the deep learning applications under multi-modal (e.g., depth and infrared) or specialized (e.g., light field and flash) sensors. We conclude this survey by emphasizing current open issues and highlighting potential prospects.
Dual-Cross Central Difference Network for Face Anti-Spoofing
May 04, 2021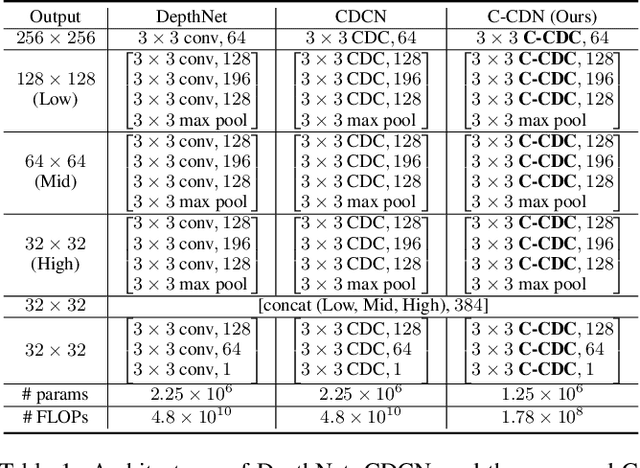
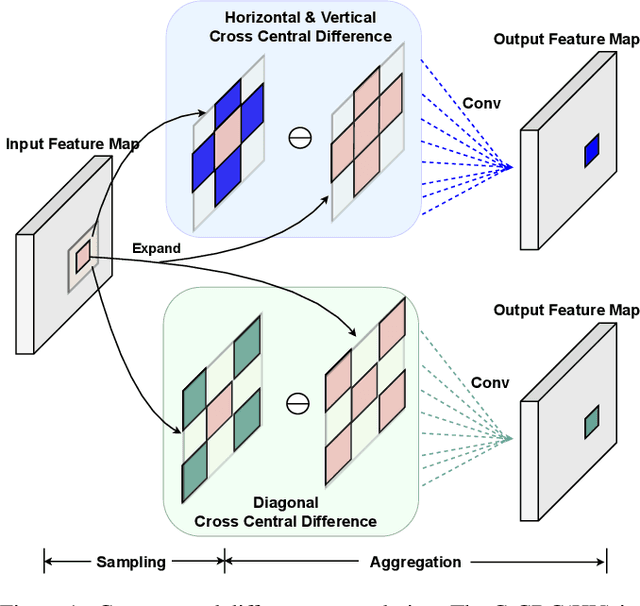
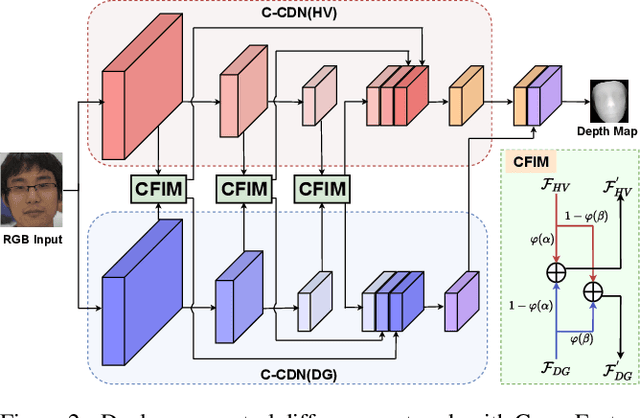
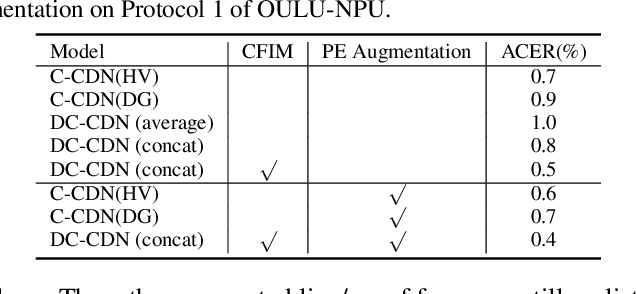
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems. Recently, central difference convolution (CDC) has shown its excellent representation capacity for the FAS task via leveraging local gradient features. However, aggregating central difference clues from all neighbors/directions simultaneously makes the CDC redundant and sub-optimized in the training phase. In this paper, we propose two Cross Central Difference Convolutions (C-CDC), which exploit the difference of the center and surround sparse local features from the horizontal/vertical and diagonal directions, respectively. It is interesting to find that, with only five ninth parameters and less computational cost, C-CDC even outperforms the full directional CDC. Based on these two decoupled C-CDC, a powerful Dual-Cross Central Difference Network (DC-CDN) is established with Cross Feature Interaction Modules (CFIM) for mutual relation mining and local detailed representation enhancement. Furthermore, a novel Patch Exchange (PE) augmentation strategy for FAS is proposed via simply exchanging the face patches as well as their dense labels from random samples. Thus, the augmented samples contain richer live/spoof patterns and diverse domain distributions, which benefits the intrinsic and robust feature learning. Comprehensive experiments are performed on four benchmark datasets with three testing protocols to demonstrate our state-of-the-art performance.
TransRPPG: Remote Photoplethysmography Transformer for 3D Mask Face Presentation Attack Detection
Apr 15, 2021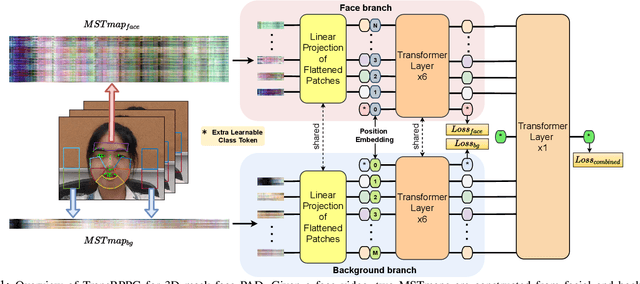

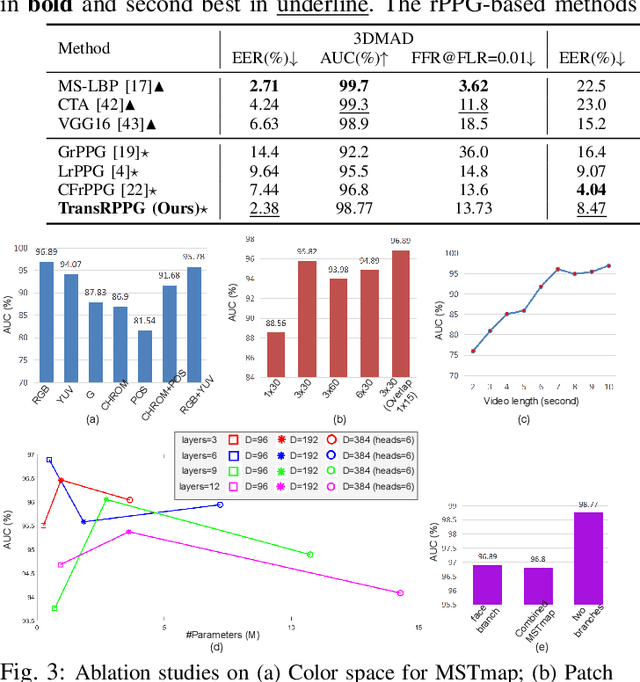

3D mask face presentation attack detection (PAD) plays a vital role in securing face recognition systems from emergent 3D mask attacks. Recently, remote photoplethysmography (rPPG) has been developed as an intrinsic liveness clue for 3D mask PAD without relying on the mask appearance. However, the rPPG features for 3D mask PAD are still needed expert knowledge to design manually, which limits its further progress in the deep learning and big data era. In this letter, we propose a pure rPPG transformer (TransRPPG) framework for learning intrinsic liveness representation efficiently. At first, rPPG-based multi-scale spatial-temporal maps (MSTmap) are constructed from facial skin and background regions. Then the transformer fully mines the global relationship within MSTmaps for liveness representation, and gives a binary prediction for 3D mask detection. Comprehensive experiments are conducted on two benchmark datasets to demonstrate the efficacy of the TransRPPG on both intra- and cross-dataset testings. Our TransRPPG is lightweight and efficient (with only 547K parameters and 763M FLOPs), which is promising for mobile-level applications.
Revisiting Pixel-Wise Supervision for Face Anti-Spoofing
Nov 24, 2020
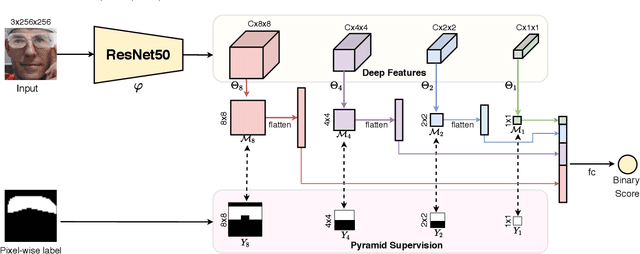
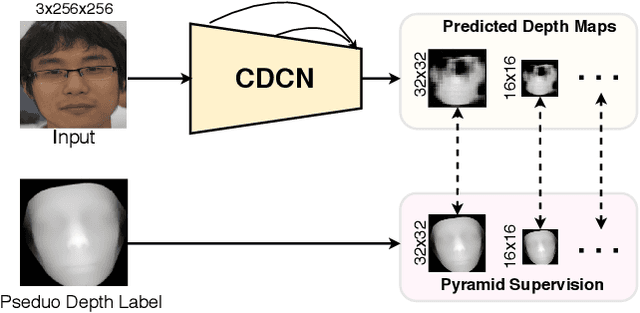
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from the presentation attacks (PAs). As more and more realistic PAs with novel types spring up, it is necessary to develop robust algorithms for detecting unknown attacks even in unseen scenarios. However, deep models supervised by traditional binary loss (e.g., `0' for bonafide vs. `1' for PAs) are weak in describing intrinsic and discriminative spoofing patterns. Recently, pixel-wise supervision has been proposed for the FAS task, intending to provide more fine-grained pixel/patch-level cues. In this paper, we firstly give a comprehensive review and analysis about the existing pixel-wise supervision methods for FAS. Then we propose a novel pyramid supervision, which guides deep models to learn both local details and global semantics from multi-scale spatial context. Extensive experiments are performed on five FAS benchmark datasets to show that, without bells and whistles, the proposed pyramid supervision could not only improve the performance beyond existing pixel-wise supervision frameworks, but also enhance the model's interpretability (i.e., locating the patch-level positions of PAs more reasonably). Furthermore, elaborate studies are conducted for exploring the efficacy of different architecture configurations with two kinds of pixel-wise supervisions (binary mask and depth map supervisions), which provides inspirable insights for future architecture/supervision design.
NAS-FAS: Static-Dynamic Central Difference Network Search for Face Anti-Spoofing
Nov 03, 2020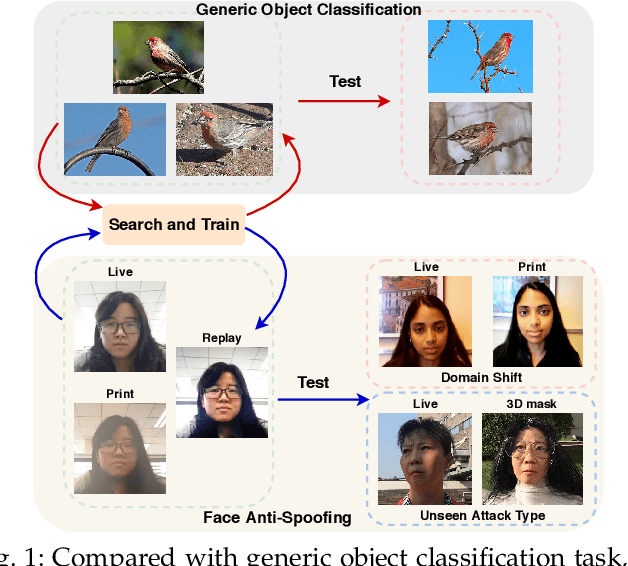
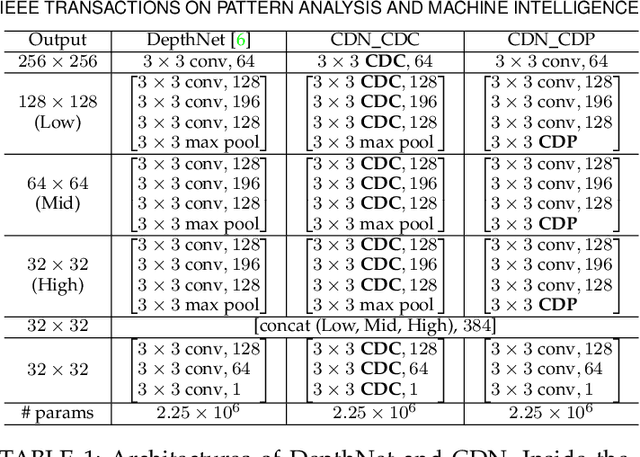
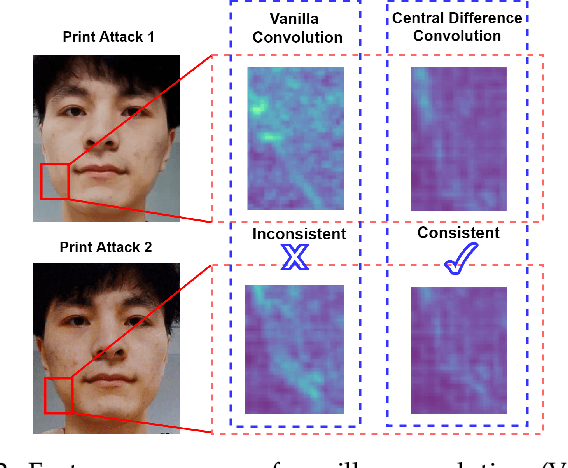
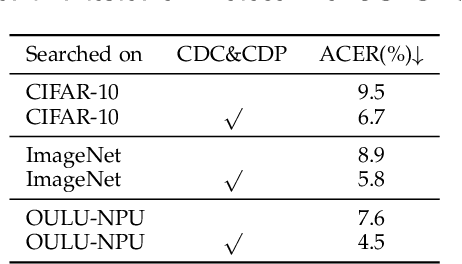
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems. Existing methods heavily rely on the expert-designed networks, which may lead to a sub-optimal solution for FAS task. Here we propose the first FAS method based on neural architecture search (NAS), called NAS-FAS, to discover the well-suited task-aware networks. Unlike previous NAS works mainly focus on developing efficient search strategies in generic object classification, we pay more attention to study the search spaces for FAS task. The challenges of utilizing NAS for FAS are in two folds: the networks searched on 1) a specific acquisition condition might perform poorly in unseen conditions, and 2) particular spoofing attacks might generalize badly for unseen attacks. To overcome these two issues, we develop a novel search space consisting of central difference convolution and pooling operators. Moreover, an efficient static-dynamic representation is exploited for fully mining the FAS-aware spatio-temporal discrepancy. Besides, we propose Domain/Type-aware Meta-NAS, which leverages cross-domain/type knowledge for robust searching. Finally, in order to evaluate the NAS transferability for cross datasets and unknown attack types, we release a large-scale 3D mask dataset, namely CASIA-SURF 3DMask, for supporting the new 'cross-dataset cross-type' testing protocol. Experiments demonstrate that the proposed NAS-FAS achieves state-of-the-art performance on nine FAS benchmark datasets with four testing protocols.
Micro-expression spotting: A new benchmark
Jul 24, 2020
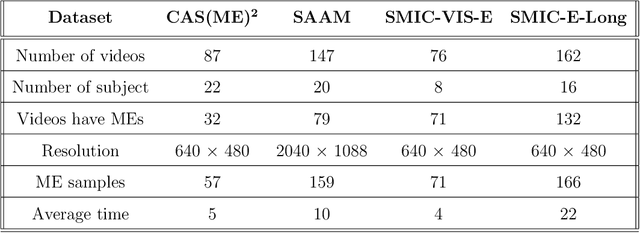

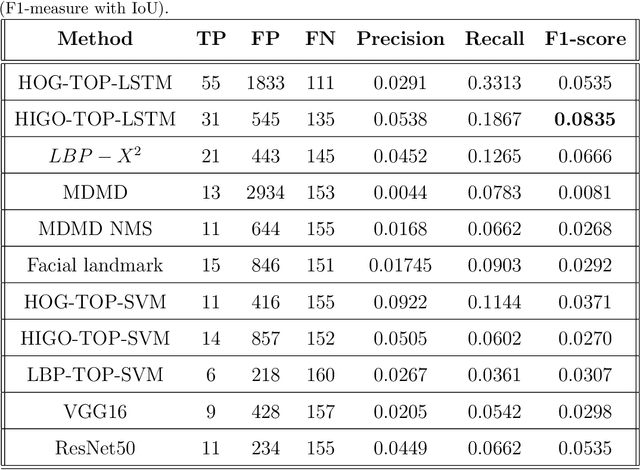
Micro-expressions (MEs) are brief and involuntary facial expressions that occur when people are trying to hide their true feelings or conceal their emotions. Based on psychology research, MEs play an important role in understanding genuine emotions, which leads to many potential applications. Therefore, ME analysis has been becoming an attractive topic for various research areas, such as psychology, law enforcement, and psychotherapy. In the computer vision field, the study of MEs can be divided into two main tasks: spotting and recognition, which are to identify positions of MEs in videos and determine the emotion category of detected MEs, respectively. Recently, although much research has been done, the construction of a fully automatic system for analyzing MEs is still far away from practice. This is because of two main reasons: most of the research in MEs only focuses on the recognition part while abandons the spotting task; current public datasets for ME spotting are not challenging enough to support developing a robust spotting algorithm. Our contributions in this paper are three folds: (1) We introduce an extension of the SMIC-E database, namely SMIC-E-Long database, which is a new challenging benchmark for ME spotting. (2) We suggest a new evaluation protocol that standardizes the comparison of various ME spotting techniques. (3) Extensive experiments with handcrafted and deep learning-based approaches on the SMIC-E-Long database are performed for baseline evaluation.
Video-based Remote Physiological Measurement via Cross-verified Feature Disentangling
Jul 16, 2020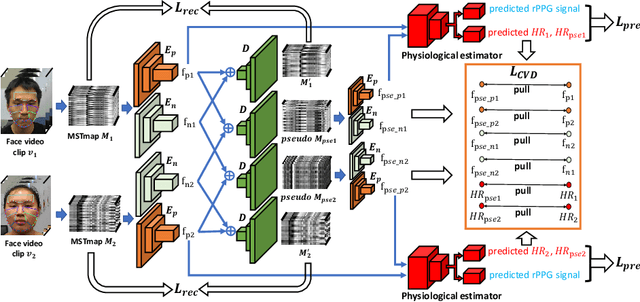
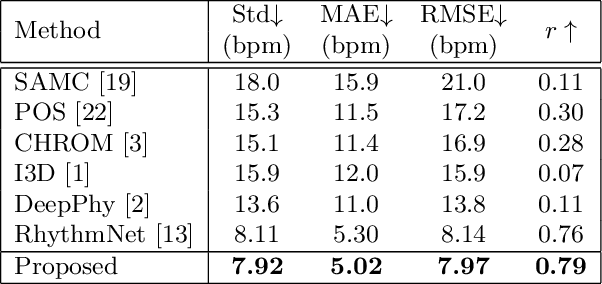
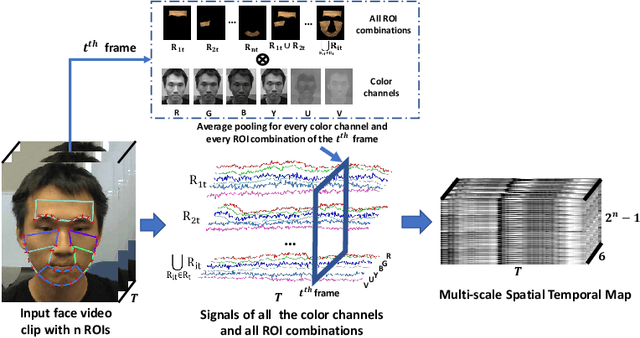
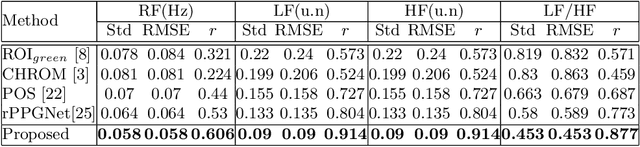
Remote physiological measurements, e.g., remote photoplethysmography (rPPG) based heart rate (HR), heart rate variability (HRV) and respiration frequency (RF) measuring, are playing more and more important roles under the application scenarios where contact measurement is inconvenient or impossible. Since the amplitude of the physiological signals is very small, they can be easily affected by head movements, lighting conditions, and sensor diversities. To address these challenges, we propose a cross-verified feature disentangling strategy to disentangle the physiological features with non-physiological representations, and then use the distilled physiological features for robust multi-task physiological measurements. We first transform the input face videos into a multi-scale spatial-temporal map (MSTmap), which can suppress the irrelevant background and noise features while retaining most of the temporal characteristics of the periodic physiological signals. Then we take pairwise MSTmaps as inputs to an autoencoder architecture with two encoders (one for physiological signals and the other for non-physiological information) and use a cross-verified scheme to obtain physiological features disentangled with the non-physiological features. The disentangled features are finally used for the joint prediction of multiple physiological signals like average HR values and rPPG signals. Comprehensive experiments on different large-scale public datasets of multiple physiological measurement tasks as well as the cross-database testing demonstrate the robustness of our approach.
Face Anti-Spoofing with Human Material Perception
Jul 04, 2020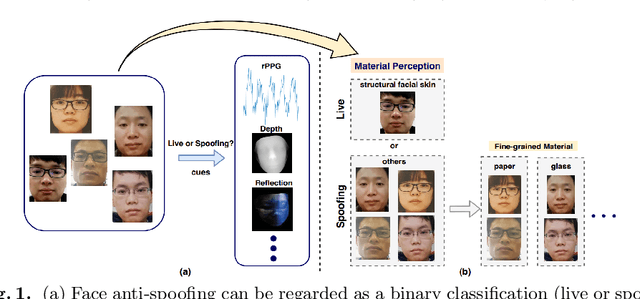
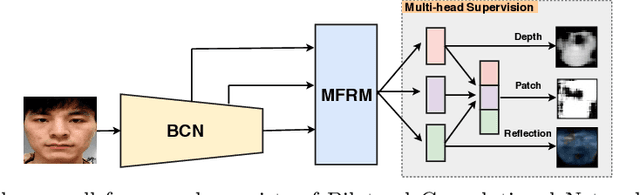


Face anti-spoofing (FAS) plays a vital role in securing the face recognition systems from presentation attacks. Most existing FAS methods capture various cues (e.g., texture, depth and reflection) to distinguish the live faces from the spoofing faces. All these cues are based on the discrepancy among physical materials (e.g., skin, glass, paper and silicone). In this paper we rephrase face anti-spoofing as a material recognition problem and combine it with classical human material perception [1], intending to extract discriminative and robust features for FAS. To this end, we propose the Bilateral Convolutional Networks (BCN), which is able to capture intrinsic material-based patterns via aggregating multi-level bilateral macro- and micro- information. Furthermore, Multi-level Feature Refinement Module (MFRM) and multi-head supervision are utilized to learn more robust features. Comprehensive experiments are performed on six benchmark datasets, and the proposed method achieves superior performance on both intra- and cross-dataset testings. One highlight is that we achieve overall 11.3$\pm$9.5\% EER for cross-type testing in SiW-M dataset, which significantly outperforms previous results. We hope this work will facilitate future cooperation between FAS and material communities.
AutoHR: A Strong End-to-end Baseline for Remote Heart Rate Measurement with Neural Searching
Apr 26, 2020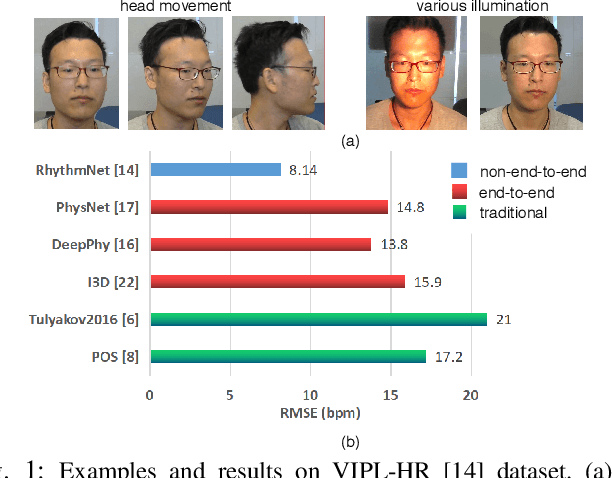
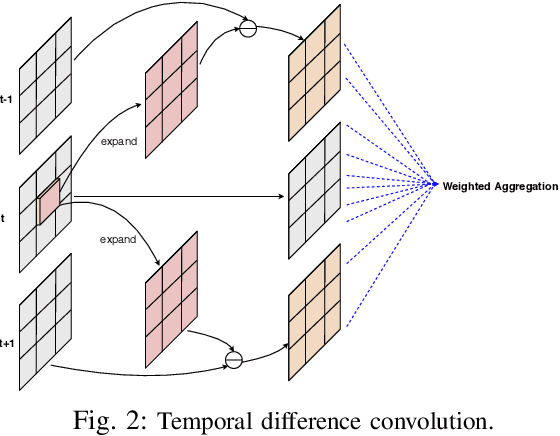
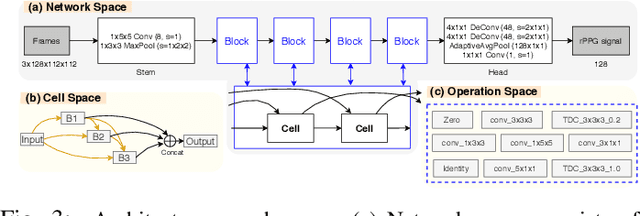
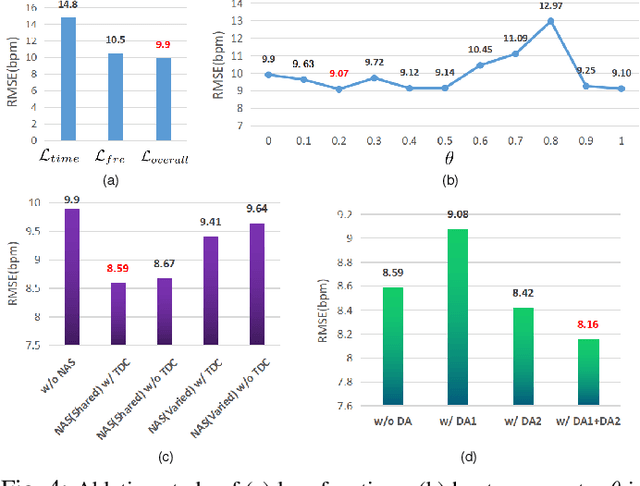
Remote photoplethysmography (rPPG), which aims at measuring heart activities without any contact, has great potential in many applications (e.g., remote healthcare). Existing end-to-end rPPG and heart rate (HR) measurement methods from facial videos are vulnerable to the less-constrained scenarios (e.g., with head movement and bad illumination). In this letter, we explore the reason why existing end-to-end networks perform poorly in challenging conditions and establish a strong end-to-end baseline (AutoHR) for remote HR measurement with neural architecture search (NAS). The proposed method includes three parts: 1) a powerful searched backbone with novel Temporal Difference Convolution (TDC), intending to capture intrinsic rPPG-aware clues between frames; 2) a hybrid loss function considering constraints from both time and frequency domains; and 3) spatio-temporal data augmentation strategies for better representation learning. Comprehensive experiments are performed on three benchmark datasets to show our superior performance on both intra- and cross-dataset testing.