 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Value Metrics: Evaluating and Enhancing LLM Unlearning with Cognitive Diagnosis
Feb 19, 2025Due to the widespread use of LLMs and the rising critical ethical and safety concerns, LLM unlearning methods have been developed to remove harmful knowledge and undesirable capabilities. In this context, evaluations are mostly based on single-value metrics such as QA accuracy. However, these metrics often fail to capture the nuanced retention of harmful knowledge components, making it difficult to assess the true effectiveness of unlearning. To address this issue, we propose UNCD (UNlearning evaluation via Cognitive Diagnosis), a novel framework that leverages Cognitive Diagnosis Modeling for fine-grained evaluation of LLM unlearning. Our dedicated benchmark, UNCD-Cyber, provides a detailed assessment of the removal of dangerous capabilities. Moreover, we introduce UNCD-Agent, which refines unlearning by diagnosing knowledge remnants and generating targeted unlearning data. Extensive experiments across eight unlearning methods and two base models demonstrate that UNCD not only enhances evaluation but also effectively facilitates the removal of harmful LLM abilities.
Preference Leakage: A Contamination Problem in LLM-as-a-judge
Feb 03, 2025



Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development. While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm. In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators. To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family. Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks. Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge. We release all codes and data at: https://github.com/David-Li0406/Preference-Leakage.
Breaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
Shaping the Safety Boundaries: Understanding and Defending Against Jailbreaks in Large Language Models
Dec 22, 2024



Jailbreaking in Large Language Models (LLMs) is a major security concern as it can deceive LLMs to generate harmful text. Yet, there is still insufficient understanding of how jailbreaking works, which makes it hard to develop effective defense strategies. We aim to shed more light into this issue: we conduct a detailed large-scale analysis of seven different jailbreak methods and find that these disagreements stem from insufficient observation samples. In particular, we introduce \textit{safety boundary}, and we find that jailbreaks shift harmful activations outside that safety boundary, where LLMs are less sensitive to harmful information. We also find that the low and the middle layers are critical in such shifts, while deeper layers have less impact. Leveraging on these insights, we propose a novel defense called \textbf{Activation Boundary Defense} (ABD), which adaptively constrains the activations within the safety boundary. We further use Bayesian optimization to selectively apply the defense method to the low and the middle layers. Our experiments on several benchmarks show that ABD achieves an average DSR of over 98\% against various forms of jailbreak attacks, with less than 2\% impact on the model's general capabilities.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
UOE: Unlearning One Expert Is Enough For Mixture-of-experts LLMS
Nov 27, 2024



Recent advancements in large language model (LLM) unlearning have shown remarkable success in removing unwanted data-model influences while preserving the model's utility for legitimate knowledge. However, despite these strides, sparse Mixture-of-Experts (MoE) LLMs--a key subset of the LLM family--have received little attention and remain largely unexplored in the context of unlearning. As MoE LLMs are celebrated for their exceptional performance and highly efficient inference processes, we ask: How can unlearning be performed effectively and efficiently on MoE LLMs? And will traditional unlearning methods be applicable to MoE architectures? Our pilot study shows that the dynamic routing nature of MoE LLMs introduces unique challenges, leading to substantial utility drops when existing unlearning methods are applied. Specifically, unlearning disrupts the router's expert selection, causing significant selection shift from the most unlearning target-related experts to irrelevant ones. As a result, more experts than necessary are affected, leading to excessive forgetting and loss of control over which knowledge is erased. To address this, we propose a novel single-expert unlearning framework, referred to as UOE, for MoE LLMs. Through expert attribution, unlearning is concentrated on the most actively engaged expert for the specified knowledge. Concurrently, an anchor loss is applied to the router to stabilize the active state of this targeted expert, ensuring focused and controlled unlearning that preserves model utility. The proposed UOE framework is also compatible with various unlearning algorithms. Extensive experiments demonstrate that UOE enhances both forget quality up to 5% and model utility by 35% on MoE LLMs across various benchmarks, LLM architectures, while only unlearning 0.06% of the model parameters.
SaSR-Net: Source-Aware Semantic Representation Network for Enhancing Audio-Visual Question Answering
Nov 07, 2024



Audio-Visual Question Answering (AVQA) is a challenging task that involves answering questions based on both auditory and visual information in videos. A significant challenge is interpreting complex multi-modal scenes, which include both visual objects and sound sources, and connecting them to the given question. In this paper, we introduce the Source-aware Semantic Representation Network (SaSR-Net), a novel model designed for AVQA. SaSR-Net utilizes source-wise learnable tokens to efficiently capture and align audio-visual elements with the corresponding question. It streamlines the fusion of audio and visual information using spatial and temporal attention mechanisms to identify answers in multi-modal scenes. Extensive experiments on the Music-AVQA and AVQA-Yang datasets show that SaSR-Net outperforms state-of-the-art AVQA methods.
CLIPErase: Efficient Unlearning of Visual-Textual Associations in CLIP
Oct 30, 2024



Machine unlearning (MU) has gained significant attention as a means to remove specific data from trained models without requiring a full retraining process. While progress has been made in unimodal domains like text and image classification, unlearning in multimodal models remains relatively underexplored. In this work, we address the unique challenges of unlearning in CLIP, a prominent multimodal model that aligns visual and textual representations. We introduce CLIPErase, a novel approach that disentangles and selectively forgets both visual and textual associations, ensuring that unlearning does not compromise model performance. CLIPErase consists of three key modules: a Forgetting Module that disrupts the associations in the forget set, a Retention Module that preserves performance on the retain set, and a Consistency Module that maintains consistency with the original model. Extensive experiments on the CIFAR-100 and Flickr30K datasets across four CLIP downstream tasks demonstrate that CLIPErase effectively forgets designated associations in zero-shot tasks for multimodal samples, while preserving the model's performance on the retain set after unlearning.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


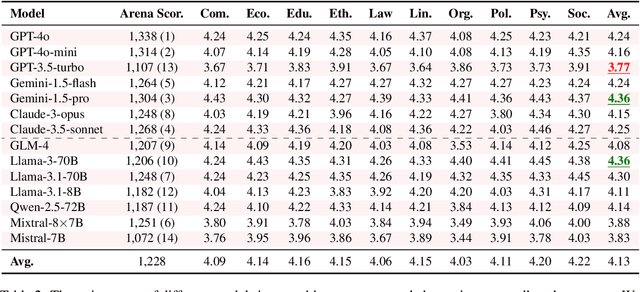
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
AutoBench-V: Can Large Vision-Language Models Benchmark Themselves?
Oct 29, 2024Large Vision-Language Models (LVLMs) have become essential for advancing the integration of visual and linguistic information, facilitating a wide range of complex applications and tasks. However, the evaluation of LVLMs presents significant challenges as the evaluation benchmark always demands lots of human cost for its construction, and remains static, lacking flexibility once constructed. Even though automatic evaluation has been explored in textual modality, the visual modality remains under-explored. As a result, in this work, we address a question: "Can LVLMs serve as a path to automatic benchmarking?". We introduce AutoBench-V, an automated framework for serving evaluation on demand, i.e., benchmarking LVLMs based on specific aspects of model capability. Upon receiving an evaluation capability, AutoBench-V leverages text-to-image models to generate relevant image samples and then utilizes LVLMs to orchestrate visual question-answering (VQA) tasks, completing the evaluation process efficiently and flexibly. Through an extensive evaluation of seven popular LVLMs across five demanded user inputs (i.e., evaluation capabilities), the framework shows effectiveness and reliability. We observe the following: (1) Our constructed benchmark accurately reflects varying task difficulties; (2) As task difficulty rises, the performance gap between models widens; (3) While models exhibit strong performance in abstract level understanding, they underperform in details reasoning tasks; and (4) Constructing a dataset with varying levels of difficulties is critical for a comprehensive and exhaustive evaluation. Overall, AutoBench-V not only successfully utilizes LVLMs for automated benchmarking but also reveals that LVLMs as judges have significant potential in various domains.