 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Orthogonal Decomposition for Maximum Inner Product Search
Mar 25, 2019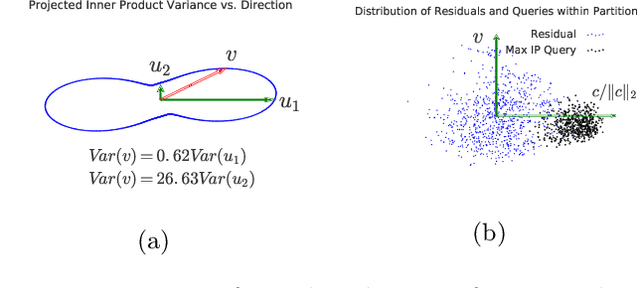

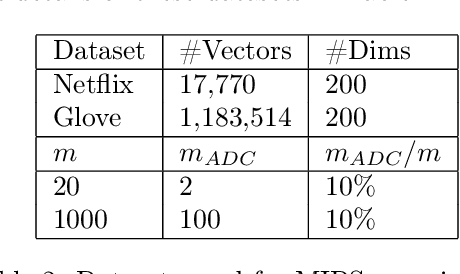
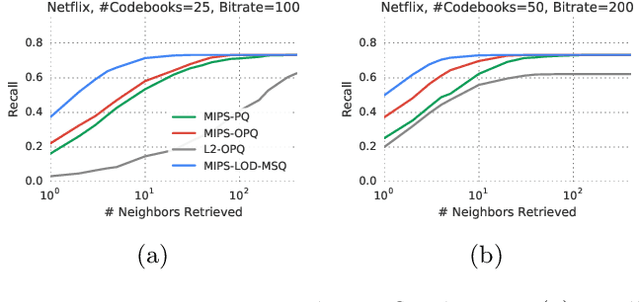
Inverted file and asymmetric distance computation (IVFADC) have been successfully applied to approximate nearest neighbor search and subsequently maximum inner product search. In such a framework, vector quantization is used for coarse partitioning while product quantization is used for quantizing residuals. In the original IVFADC as well as all of its variants, after residuals are computed, the second production quantization step is completely independent of the first vector quantization step. In this work, we seek to exploit the connection between these two steps when we perform non-exhaustive search. More specifically, we decompose a residual vector locally into two orthogonal components and perform uniform quantization and multiscale quantization to each component respectively. The proposed method, called local orthogonal decomposition, combined with multiscale quantization consistently achieves higher recall than previous methods under the same bitrates. We conduct comprehensive experiments on large scale datasets as well as detailed ablation tests, demonstrating effectiveness of our method.
Dual Variational Generation for Low-Shot Heterogeneous Face Recognition
Mar 25, 2019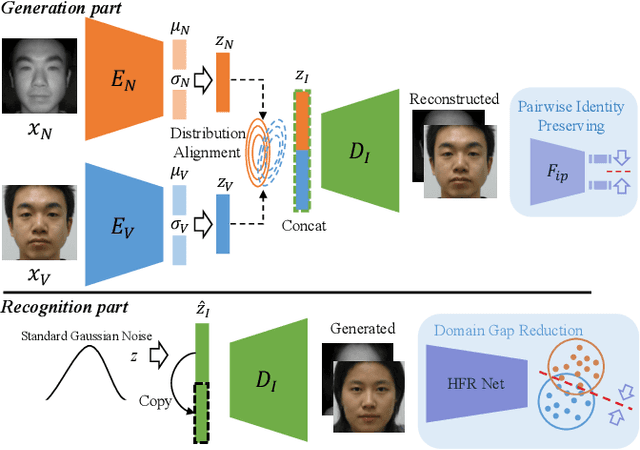
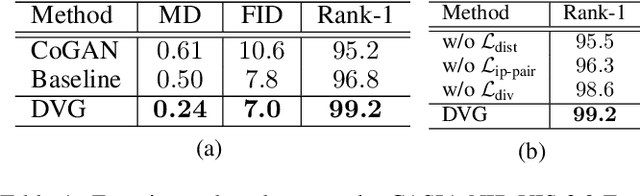

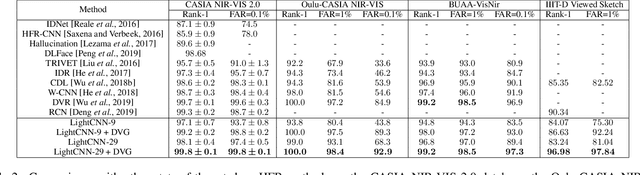
Heterogeneous Face Recognition (HFR) is a challenging issue because of the large domain discrepancy and a lack of heterogeneous data. This paper considers HFR as a dual generation problem, and proposes a new Dual Variational Generation (DVG) framework. It generates large-scale paired heterogeneous images with the same identity from noise, for the sake of reducing the domain gap of HFR, which provides a new insight into the two challenging issues in HFR. Specifically, we first introduce a dual variational autoencoder to represent a joint distribution of paired heterogeneous images. Then, we impose a distribution alignment loss in the latent space and a pairwise identity preserving loss in the image space. These ensure that DVG can generate diverse paired heterogeneous images of the same identity. Moreover, a pairwise distance loss between the generated paired heterogeneous images contributes to the optimization of the HFR network, aiming at reducing the domain discrepancy. Significant recognition improvements are observed on four HFR databases, paving a new way to address the low-shot HFR problems.
Efficient Inner Product Approximation in Hybrid Spaces
Mar 20, 2019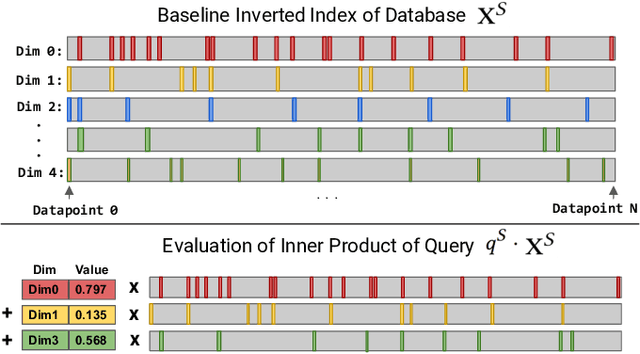
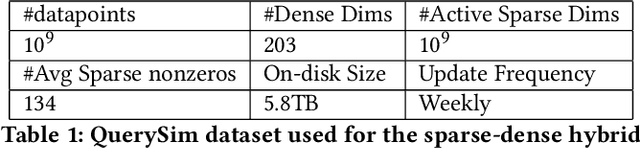
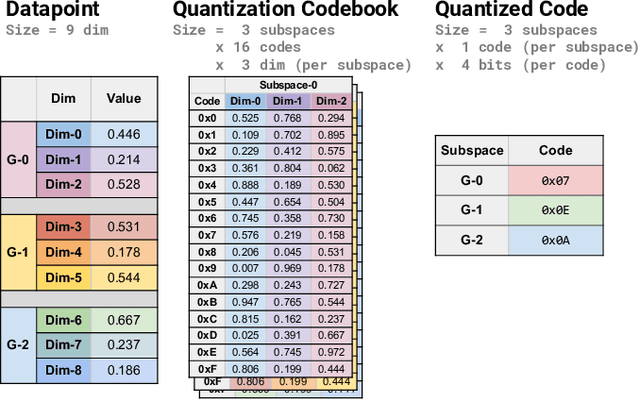
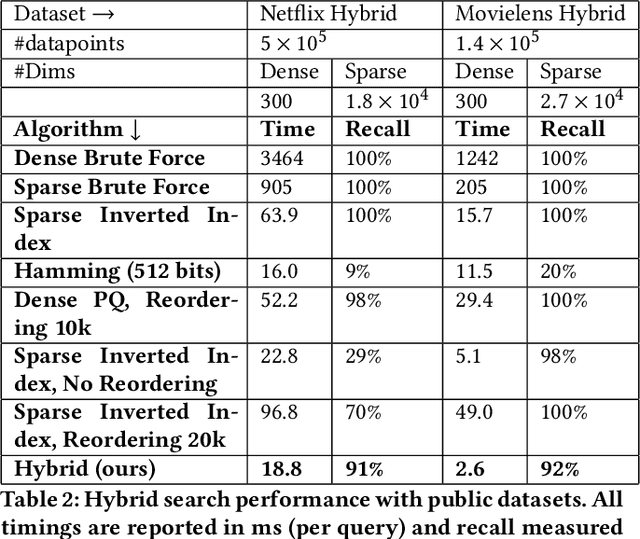
Many emerging use cases of data mining and machine learning operate on large datasets with data from heterogeneous sources, specifically with both sparse and dense components. For example, dense deep neural network embedding vectors are often used in conjunction with sparse textual features to provide high dimensional hybrid representation of documents. Efficient search in such hybrid spaces is very challenging as the techniques that perform well for sparse vectors have little overlap with those that work well for dense vectors. Popular techniques like Locality Sensitive Hashing (LSH) and its data-dependent variants also do not give good accuracy in high dimensional hybrid spaces. Even though hybrid scenarios are becoming more prevalent, currently there exist no efficient techniques in literature that are both fast and accurate. In this paper, we propose a technique that approximates the inner product computation in hybrid vectors, leading to substantial speedup in search while maintaining high accuracy. We also propose efficient data structures that exploit modern computer architectures, resulting in orders of magnitude faster search than the existing baselines. The performance of the proposed method is demonstrated on several datasets including a very large scale industrial dataset containing one billion vectors in a billion dimensional space, achieving over 10x speedup and higher accuracy against competitive baselines.
Disentangled Variational Representation for Heterogeneous Face Recognition
Nov 04, 2018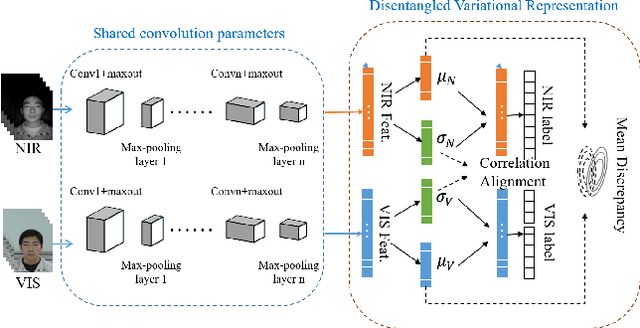

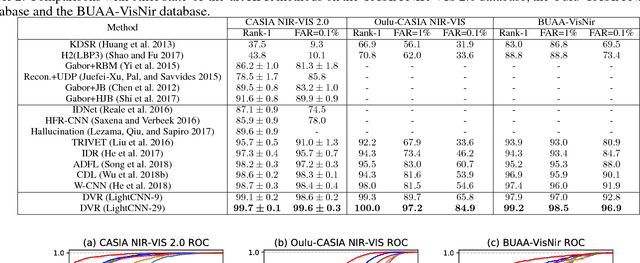
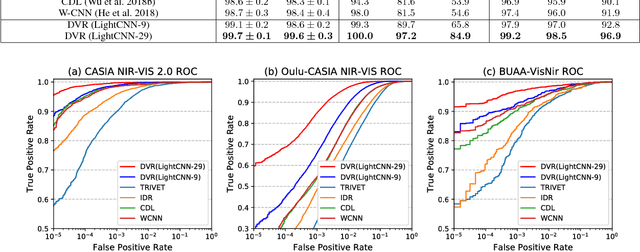
Visible (VIS) to near infrared (NIR) face matching is a challenging problem due to the significant domain discrepancy between the domains and a lack of sufficient data for training cross-modal matching algorithms. Existing approaches attempt to tackle this problem by either synthesizing visible faces from NIR faces, extracting domain-invariant features from these modalities, or projecting heterogeneous data onto a common latent space for cross-modal matching. In this paper, we take a different approach in which we make use of the Disentangled Variational Representation (DVR) for cross-modal matching. First, we model a face representation with an intrinsic identity information and its within-person variations. By exploring the disentangled latent variable space, a variational lower bound is employed to optimize the approximate posterior for NIR and VIS representations. Second, aiming at obtaining more compact and discriminative disentangled latent space, we impose a minimization of the identity information for the same subject and a relaxed correlation alignment constraint between the NIR and VIS modality variations. An alternative optimization scheme is proposed for the disentangled variational representation part and the heterogeneous face recognition network part. The mutual promotion between these two parts effectively reduces the NIR and VIS domain discrepancy and alleviates over-fitting. Extensive experiments on three challenging NIR-VIS heterogeneous face recognition databases demonstrate that the proposed method achieves significant improvements over the state-of-the-art methods.
A Blended Deep Learning Approach for Predicting User Intended Actions
Oct 11, 2018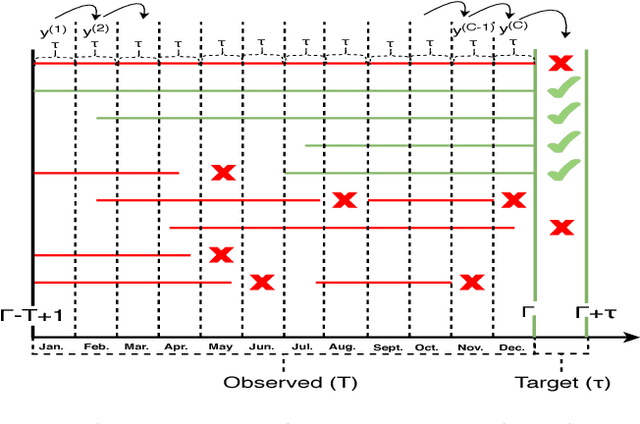
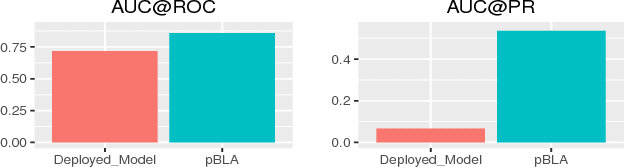
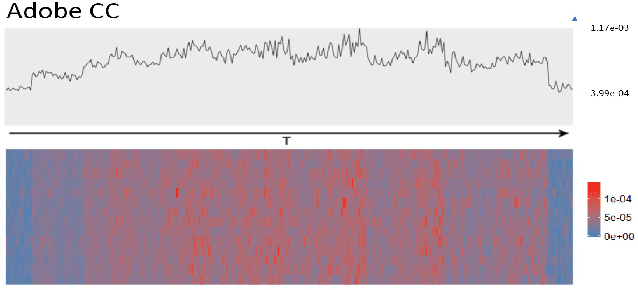
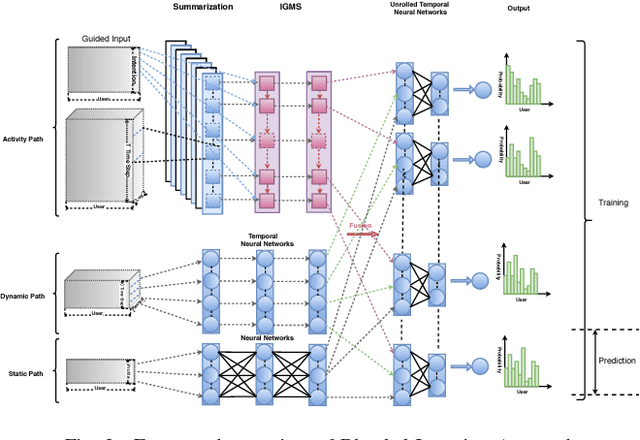
User intended actions are widely seen in many areas. Forecasting these actions and taking proactive measures to optimize business outcome is a crucial step towards sustaining the steady business growth. In this work, we focus on pre- dicting attrition, which is one of typical user intended actions. Conventional attrition predictive modeling strategies suffer a few inherent drawbacks. To overcome these limitations, we propose a novel end-to-end learning scheme to keep track of the evolution of attrition patterns for the predictive modeling. It integrates user activity logs, dynamic and static user profiles based on multi-path learning. It exploits historical user records by establishing a decaying multi-snapshot technique. And finally it employs the precedent user intentions via guiding them to the subsequent learning procedure. As a result, it addresses all disadvantages of conventional methods. We evaluate our methodology on two public data repositories and one private user usage dataset provided by Adobe Creative Cloud. The extensive experiments demonstrate that it can offer the appealing performance in comparison with several existing approaches as rated by different popular metrics. Furthermore, we introduce an advanced interpretation and visualization strategy to effectively characterize the periodicity of user activity logs. It can help to pinpoint important factors that are critical to user attrition and retention and thus suggests actionable improvement targets for business practice. Our work will provide useful insights into the prediction and elucidation of other user intended actions as well.
Neurons Merging Layer: Towards Progressive Redundancy Reduction for Deep Supervised Hashing
Sep 07, 2018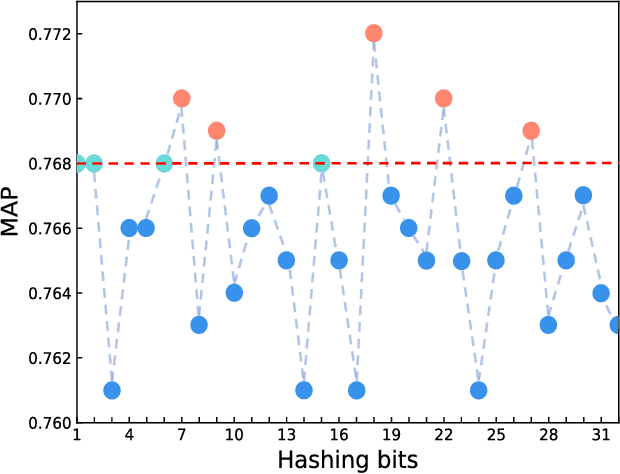
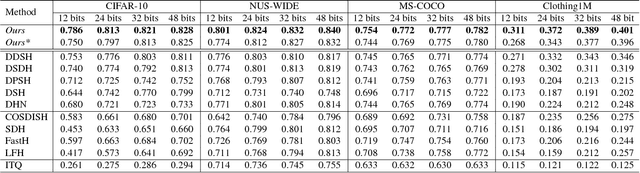

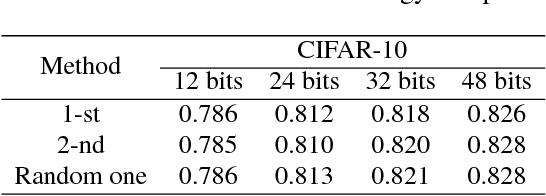
Deep supervised hashing has become an active topic in web search and information retrieval. It generates hashing bits by the output neurons of a deep hashing network. During binary discretization, there often exists much redundancy among hashing bits that degenerates retrieval performance in terms of both storage and accuracy. This paper formulates the redundancy problem in deep supervised hashing as a graph learning problem and proposes a novel layer, named Neurons Merging Layer (NMLayer). The NMLayer constructs a graph to model the adjacency relationship among different neurons. Specifically, it learns the relationship by the defined active and frozen phases. According to the learned relationship, the NMLayer merges the redundant neurons together to balance the importance of each output neuron. Based on the NMLayer, we further propose a progressive optimization strategy for training a deep hashing network. That is, multiple NMLayers are progressively trained to learn a more compact hashing code from a long redundant code. Extensive experiments on four datasets demonstrate that our proposed method outperforms state-of-the-art hashing methods.
A Light CNN for Deep Face Representation with Noisy Labels
Aug 12, 2018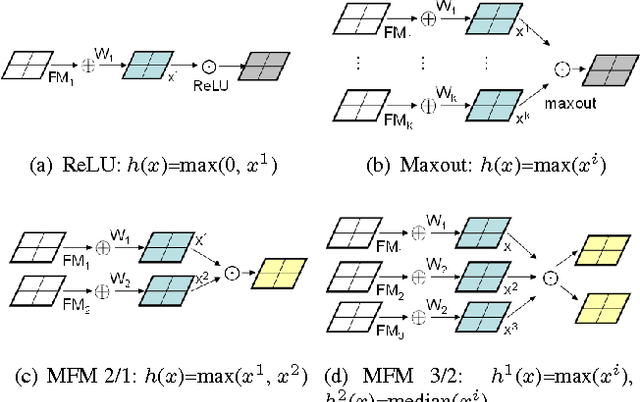
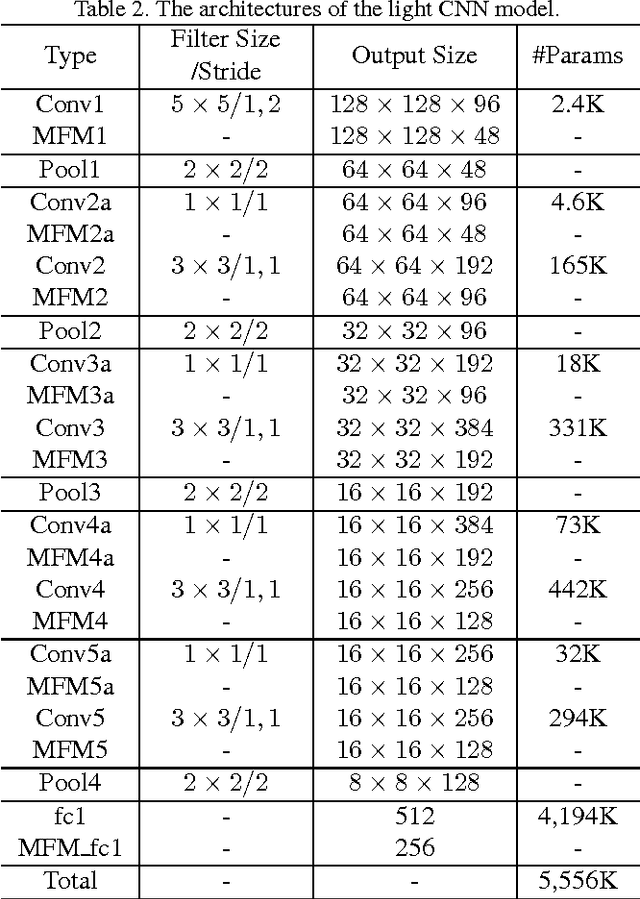

The volume of convolutional neural network (CNN) models proposed for face recognition has been continuously growing larger to better fit large amount of training data. When training data are obtained from internet, the labels are likely to be ambiguous and inaccurate. This paper presents a Light CNN framework to learn a compact embedding on the large-scale face data with massive noisy labels. First, we introduce a variation of maxout activation, called Max-Feature-Map (MFM), into each convolutional layer of CNN. Different from maxout activation that uses many feature maps to linearly approximate an arbitrary convex activation function, MFM does so via a competitive relationship. MFM can not only separate noisy and informative signals but also play the role of feature selection between two feature maps. Second, three networks are carefully designed to obtain better performance meanwhile reducing the number of parameters and computational costs. Lastly, a semantic bootstrapping method is proposed to make the prediction of the networks more consistent with noisy labels. Experimental results show that the proposed framework can utilize large-scale noisy data to learn a Light model that is efficient in computational costs and storage spaces. The learned single network with a 256-D representation achieves state-of-the-art results on various face benchmarks without fine-tuning. The code is released on https://github.com/AlfredXiangWu/LightCNN.
Learning Scene-specific Object Detectors Based on a Generative-Discriminative Model with Minimal Supervision
Mar 13, 2018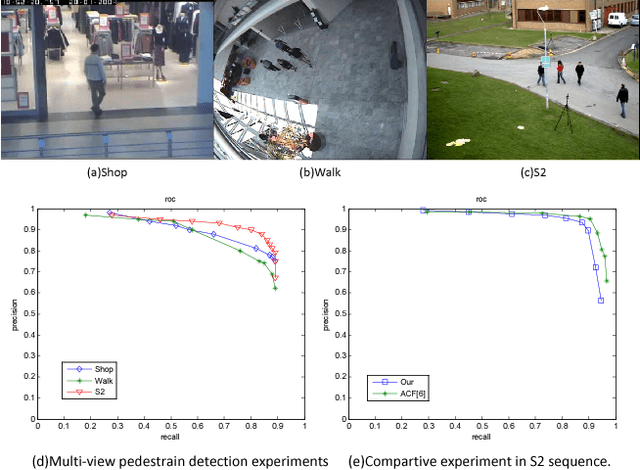
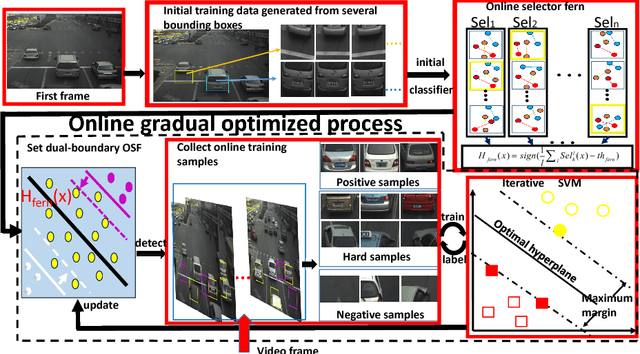

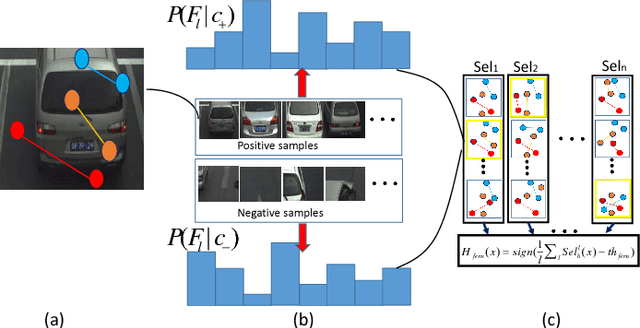
One object class may show large variations due to diverse illuminations, backgrounds and camera viewpoints. Traditional object detection methods often perform worse under unconstrained video environments. To address this problem, many modern approaches model deep hierarchical appearance representations for object detection. Most of these methods require a timeconsuming training process on large manual labelling sample set. In this paper, the proposed framework takes a remarkably different direction to resolve the multi-scene detection problem in a bottom-up fashion. First, a scene-specific objector is obtained from a fully autonomous learning process triggered by marking several bounding boxes around the object in the first video frame via a mouse. Here the human labeled training data or a generic detector are not needed. Second, this learning process is conveniently replicated many times in different surveillance scenes and results in particular detectors under various camera viewpoints. Thus, the proposed framework can be employed in multi-scene object detection applications with minimal supervision. Obviously, the initial scene-specific detector, initialized by several bounding boxes, exhibits poor detection performance and is difficult to improve with traditional online learning algorithm. Consequently, we propose Generative-Discriminative model to partition detection response space and assign each partition an individual descriptor that progressively achieves high classification accuracy. A novel online gradual optimized process is proposed to optimize the Generative-Discriminative model and focus on the hard samples.Experimental results on six video datasets show our approach achieves comparable performance to robust supervised methods, and outperforms the state of the art self-learning methods under varying imaging conditions.
Anti-Makeup: Learning A Bi-Level Adversarial Network for Makeup-Invariant Face Verification
Nov 22, 2017
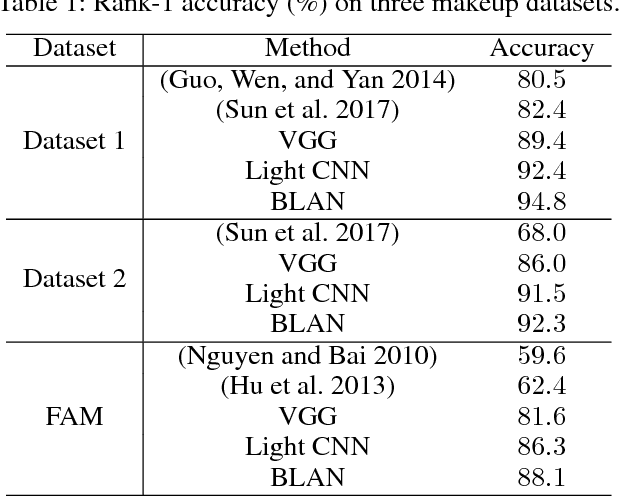
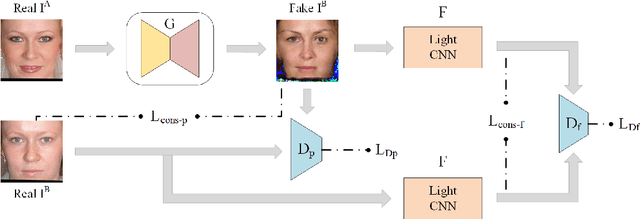
Makeup is widely used to improve facial attractiveness and is well accepted by the public. However, different makeup styles will result in significant facial appearance changes. It remains a challenging problem to match makeup and non-makeup face images. This paper proposes a learning from generation approach for makeup-invariant face verification by introducing a bi-level adversarial network (BLAN). To alleviate the negative effects from makeup, we first generate non-makeup images from makeup ones, and then use the synthesized non-makeup images for further verification. Two adversarial networks in BLAN are integrated in an end-to-end deep network, with the one on pixel level for reconstructing appealing facial images and the other on feature level for preserving identity information. These two networks jointly reduce the sensing gap between makeup and non-makeup images. Moreover, we make the generator well constrained by incorporating multiple perceptual losses. Experimental results on three benchmark makeup face datasets demonstrate that our method achieves state-of-the-art verification accuracy across makeup status and can produce photo-realistic non-makeup face images.
Coupled Deep Learning for Heterogeneous Face Recognition
Nov 16, 2017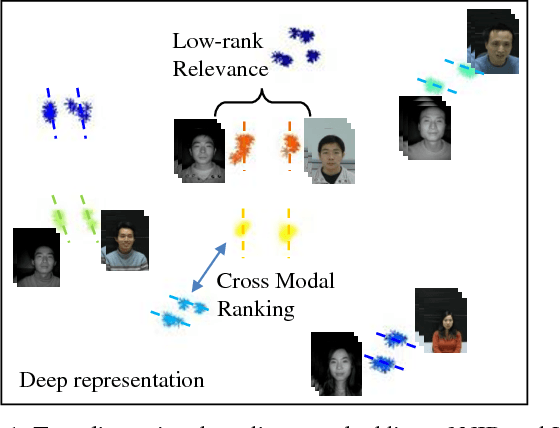

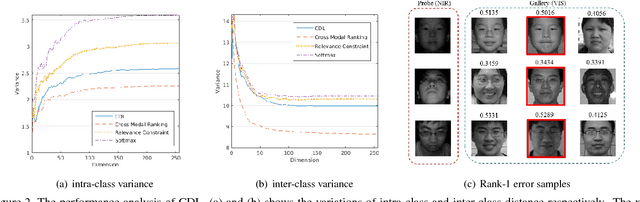
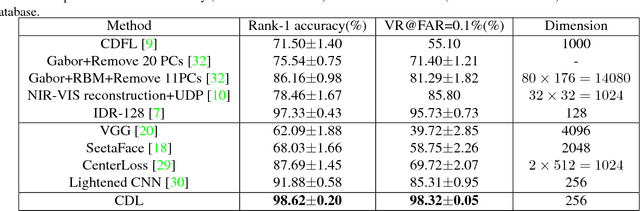
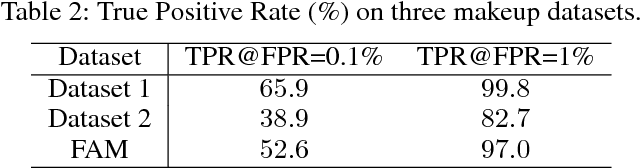
Heterogeneous face matching is a challenge issue in face recognition due to large domain difference as well as insufficient pairwise images in different modalities during training. This paper proposes a coupled deep learning (CDL) approach for the heterogeneous face matching. CDL seeks a shared feature space in which the heterogeneous face matching problem can be approximately treated as a homogeneous face matching problem. The objective function of CDL mainly includes two parts. The first part contains a trace norm and a block-diagonal prior as relevance constraints, which not only make unpaired images from multiple modalities be clustered and correlated, but also regularize the parameters to alleviate overfitting. An approximate variational formulation is introduced to deal with the difficulties of optimizing low-rank constraint directly. The second part contains a cross modal ranking among triplet domain specific images to maximize the margin for different identities and increase data for a small amount of training samples. Besides, an alternating minimization method is employed to iteratively update the parameters of CDL. Experimental results show that CDL achieves better performance on the challenging CASIA NIR-VIS 2.0 face recognition database, the IIIT-D Sketch database, the CUHK Face Sketch (CUFS), and the CUHK Face Sketch FERET (CUFSF), which significantly outperforms state-of-the-art heterogeneous face recognition methods.