 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of graph network inferences in higher-order probabilistic graphical models
Jul 12, 2021
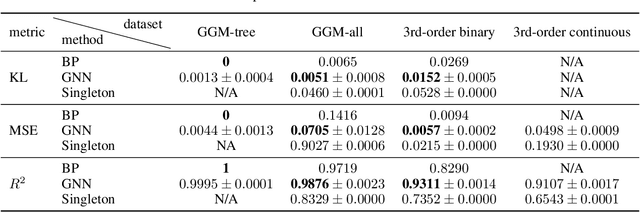
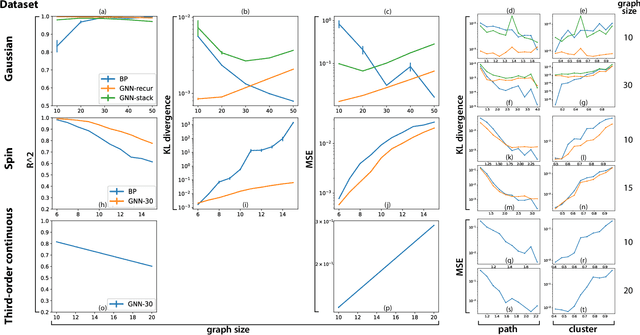
Probabilistic graphical models provide a powerful tool to describe complex statistical structure, with many real-world applications in science and engineering from controlling robotic arms to understanding neuronal computations. A major challenge for these graphical models is that inferences such as marginalization are intractable for general graphs. These inferences are often approximated by a distributed message-passing algorithm such as Belief Propagation, which does not always perform well on graphs with cycles, nor can it always be easily specified for complex continuous probability distributions. Such difficulties arise frequently in expressive graphical models that include intractable higher-order interactions. In this paper we construct iterative message-passing algorithms using Graph Neural Networks defined on factor graphs to achieve fast approximate inference on graphical models that involve many-variable interactions. Experimental results on several families of graphical models demonstrate the out-of-distribution generalization capability of our method to different sized graphs, and indicate the domain in which our method gains advantage over Belief Propagation.
AvaTr: One-Shot Speaker Extraction with Transformers
May 03, 2021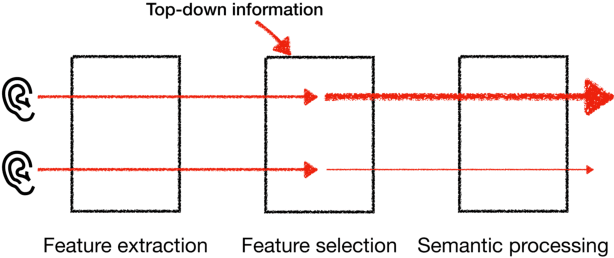

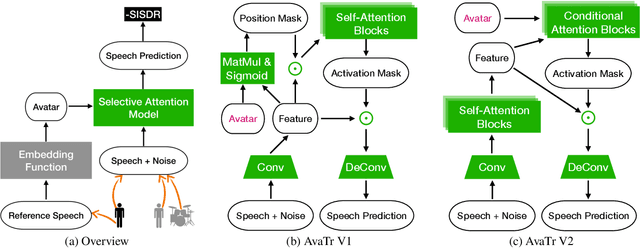
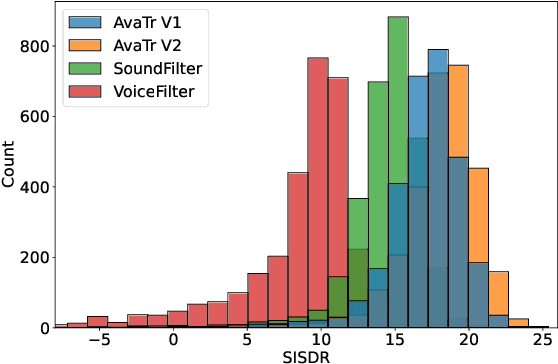
To extract the voice of a target speaker when mixed with a variety of other sounds, such as white and ambient noises or the voices of interfering speakers, we extend the Transformer network to attend the most relevant information with respect to the target speaker given the characteristics of his or her voices as a form of contextual information. The idea has a natural interpretation in terms of the selective attention theory. Specifically, we propose two models to incorporate the voice characteristics in Transformer based on different insights of where the feature selection should take place. Both models yield excellent performance, on par or better than published state-of-the-art models on the speaker extraction task, including separating speech of novel speakers not seen during training.
Flexible Few-Shot Learning with Contextual Similarity
Dec 10, 2020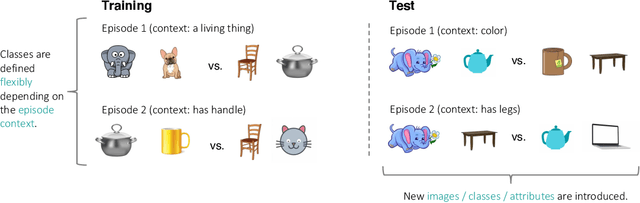


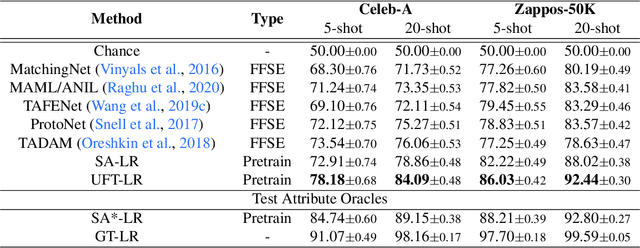
Existing approaches to few-shot learning deal with tasks that have persistent, rigid notions of classes. Typically, the learner observes data only from a fixed number of classes at training time and is asked to generalize to a new set of classes at test time. Two examples from the same class would always be assigned the same labels in any episode. In this work, we consider a realistic setting where the similarities between examples can change from episode to episode depending on the task context, which is not given to the learner. We define new benchmark datasets for this flexible few-shot scenario, where the tasks are based on images of faces (Celeb-A), shoes (Zappos50K), and general objects (ImageNet-with-Attributes). While classification baselines and episodic approaches learn representations that work well for standard few-shot learning, they suffer in our flexible tasks as novel similarity definitions arise during testing. We propose to build upon recent contrastive unsupervised learning techniques and use a combination of instance and class invariance learning, aiming to obtain general and flexible features. We find that our approach performs strongly on our new flexible few-shot learning benchmarks, demonstrating that unsupervised learning obtains more generalizable representations.
Inverse Rational Control with Partially Observable Continuous Nonlinear Dynamics
Sep 26, 2020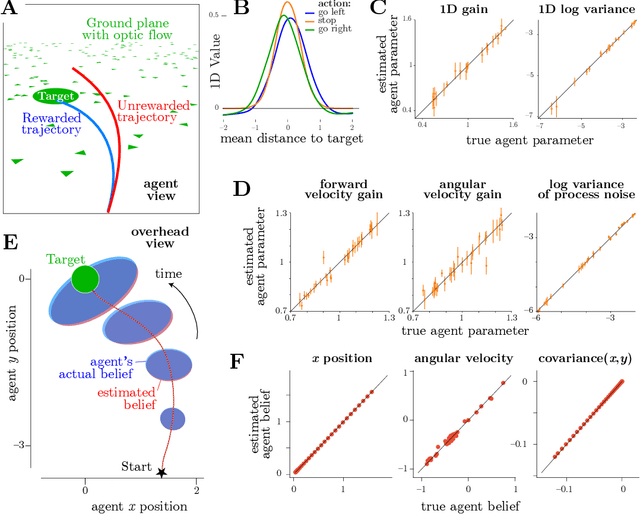
A fundamental question in neuroscience is how the brain creates an internal model of the world to guide actions using sequences of ambiguous sensory information. This is naturally formulated as a reinforcement learning problem under partial observations, where an agent must estimate relevant latent variables in the world from its evidence, anticipate possible future states, and choose actions that optimize total expected reward. This problem can be solved by control theory, which allows us to find the optimal actions for a given system dynamics and objective function. However, animals often appear to behave suboptimally. Why? We hypothesize that animals have their own flawed internal model of the world, and choose actions with the highest expected subjective reward according to that flawed model. We describe this behavior as rational but not optimal. The problem of Inverse Rational Control (IRC) aims to identify which internal model would best explain an agent's actions. Our contribution here generalizes past work on Inverse Rational Control which solved this problem for discrete control in partially observable Markov decision processes. Here we accommodate continuous nonlinear dynamics and continuous actions, and impute sensory observations corrupted by unknown noise that is private to the animal. We first build an optimal Bayesian agent that learns an optimal policy generalized over the entire model space of dynamics and subjective rewards using deep reinforcement learning. Crucially, this allows us to compute a likelihood over models for experimentally observable action trajectories acquired from a suboptimal agent. We then find the model parameters that maximize the likelihood using gradient ascent.
Learning From Brains How to Regularize Machines
Nov 11, 2019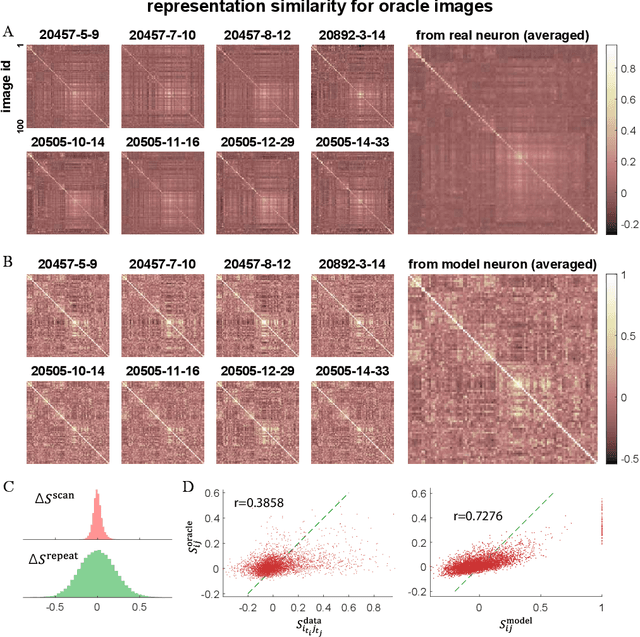
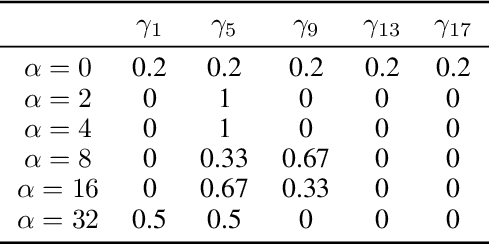

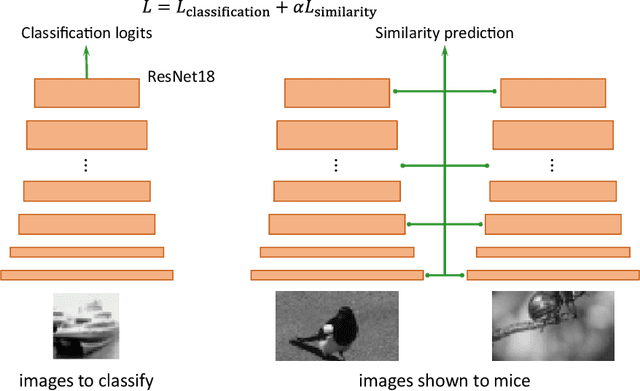
Despite impressive performance on numerous visual tasks, Convolutional Neural Networks (CNNs) --- unlike brains --- are often highly sensitive to small perturbations of their input, e.g. adversarial noise leading to erroneous decisions. We propose to regularize CNNs using large-scale neuroscience data to learn more robust neural features in terms of representational similarity. We presented natural images to mice and measured the responses of thousands of neurons from cortical visual areas. Next, we denoised the notoriously variable neural activity using strong predictive models trained on this large corpus of responses from the mouse visual system, and calculated the representational similarity for millions of pairs of images from the model's predictions. We then used the neural representation similarity to regularize CNNs trained on image classification by penalizing intermediate representations that deviated from neural ones. This preserved performance of baseline models when classifying images under standard benchmarks, while maintaining substantially higher performance compared to baseline or control models when classifying noisy images. Moreover, the models regularized with cortical representations also improved model robustness in terms of adversarial attacks. This demonstrates that regularizing with neural data can be an effective tool to create an inductive bias towards more robust inference.
Improved memory in recurrent neural networks with sequential non-normal dynamics
May 31, 2019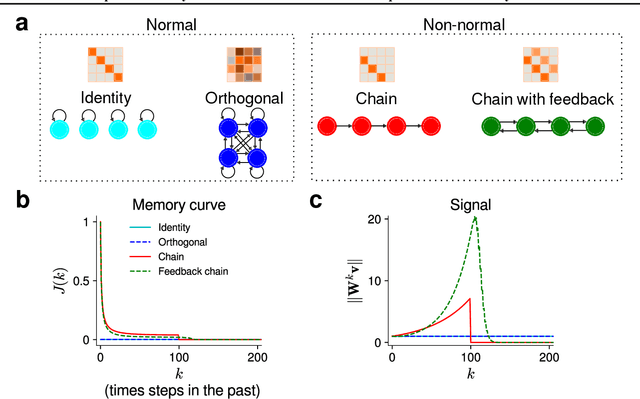
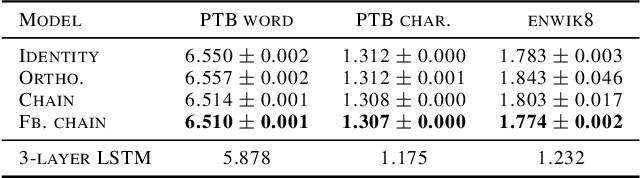
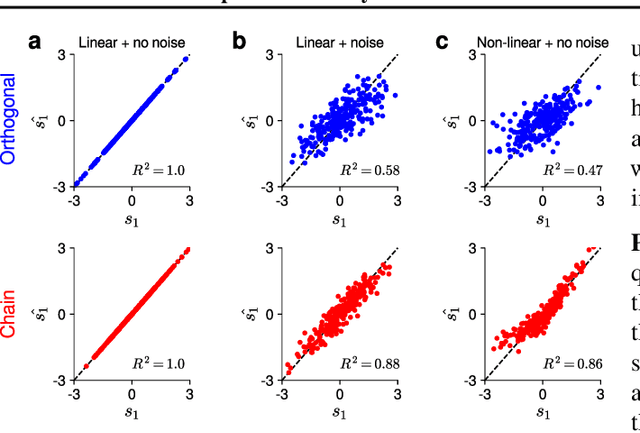

Training recurrent neural networks (RNNs) is a hard problem due to degeneracies in the optimization landscape, a problem also known as the vanishing/exploding gradients problem. Short of designing new RNN architectures, various methods for dealing with this problem that have been previously proposed usually boil down to orthogonalization of the recurrent dynamics, either at initialization or during the entire training period. The basic motivation behind these methods is that orthogonal transformations are isometries of the Euclidean space, hence they preserve (Euclidean) norms and effectively deal with the vanishing/exploding gradients problem. However, this idea ignores the crucial effects of non-linearity and noise. In the presence of a non-linearity, orthogonal transformations no longer preserve norms, suggesting that alternative transformations might be better suited to non-linear networks. Moreover, in the presence of noise, norm preservation itself ceases to be the ideal objective. A more sensible objective is maximizing the signal-to-noise ratio (SNR) of the propagated signal instead. Previous work has shown that in the linear case, recurrent networks that maximize the SNR display strongly non-normal dynamics and orthogonal networks are highly suboptimal by this measure. Motivated by this finding, in this paper, we investigate the potential of non-normal RNNs, i.e. RNNs with a non-normal recurrent connectivity matrix, in sequential processing tasks. Our experimental results show that non-normal RNNs significantly outperform their orthogonal counterparts in a diverse range of benchmarks. We also find evidence for increased non-normality and hidden chain-like feedforward structures in trained RNNs initialized with orthogonal recurrent connectivity matrices.
Belief dynamics extraction
Feb 02, 2019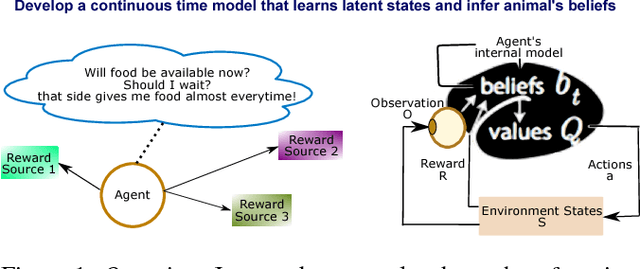
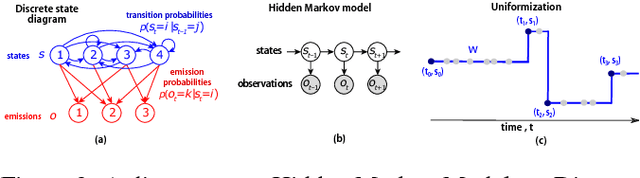
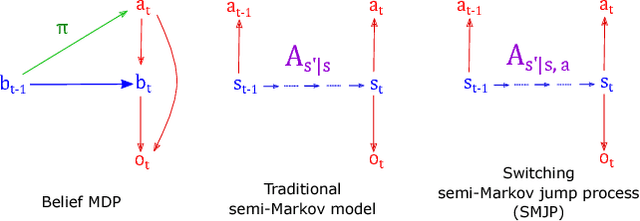

Animal behavior is not driven simply by its current observations, but is strongly influenced by internal states. Estimating the structure of these internal states is crucial for understanding the neural basis of behavior. In principle, internal states can be estimated by inverting behavior models, as in inverse model-based Reinforcement Learning. However, this requires careful parameterization and risks model-mismatch to the animal. Here we take a data-driven approach to infer latent states directly from observations of behavior, using a partially observable switching semi-Markov process. This process has two elements critical for capturing animal behavior: it captures non-exponential distribution of times between observations, and transitions between latent states depend on the animal's actions, features that require more complex non-markovian models to represent. To demonstrate the utility of our approach, we apply it to the observations of a simulated optimal agent performing a foraging task, and find that latent dynamics extracted by the model has correspondences with the belief dynamics of the agent. Finally, we apply our model to identify latent states in the behaviors of monkey performing a foraging task, and find clusters of latent states that identify periods of time consistent with expectant waiting. This data-driven behavioral model will be valuable for inferring latent cognitive states, and thereby for measuring neural representations of those states.
Inverse POMDP: Inferring What You Think from What You Do
Oct 07, 2018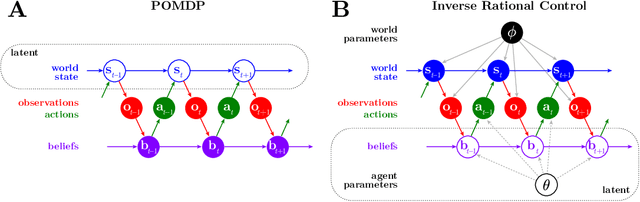
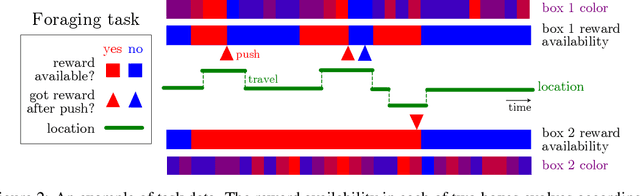
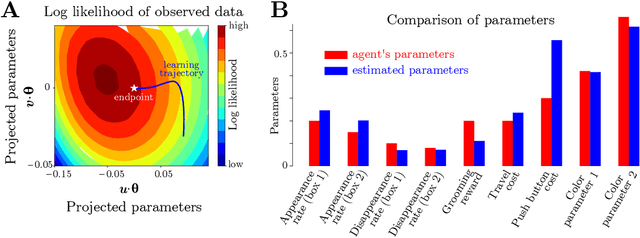
Complex behaviors are often driven by an internal model, which integrates sensory information over time and facilitates long-term planning. Inferring the internal model is a crucial ingredient for interpreting neural activities of agents and is beneficial for imitation learning. Here we describe a method to infer an agent's internal model and dynamic beliefs, and apply it to a simulated agent performing a foraging task. We assume the agent behaves rationally according to their understanding of the task and the relevant causal variables that cannot be fully observed. We model this rational solution as a Partially Observable Markov Decision Process (POMDP). However, we allow that the agent may have wrong assumptions about the task, and our method learns these assumptions from the agent's actions. Given the agent's sensory observations and actions, we learn its internal model by maximum likelihood estimation over a set of task-relevant parameters. The Markov property of the POMDP enables us to characterize the transition probabilities between internal states and iteratively estimate the agent's policy using a constrained Expectation-Maximization(EM) algorithm. We validate our method on simulated agents performing suboptimally on a foraging task, and successfully recover the agent's actual model.
Reviving and Improving Recurrent Back-Propagation
Aug 13, 2018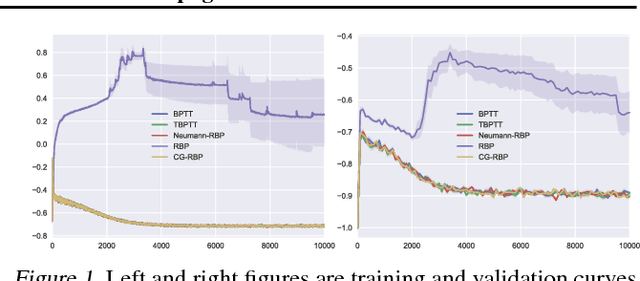
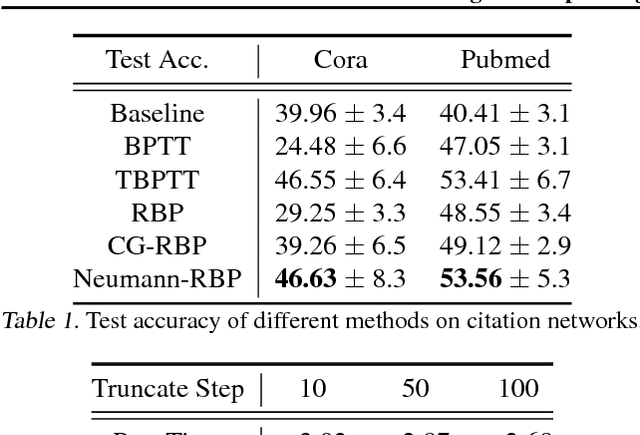
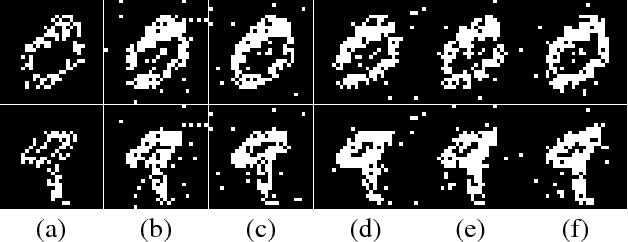

In this paper, we revisit the recurrent back-propagation (RBP) algorithm, discuss the conditions under which it applies as well as how to satisfy them in deep neural networks. We show that RBP can be unstable and propose two variants based on conjugate gradient on the normal equations (CG-RBP) and Neumann series (Neumann-RBP). We further investigate the relationship between Neumann-RBP and back propagation through time (BPTT) and its truncated version (TBPTT). Our Neumann-RBP has the same time complexity as TBPTT but only requires constant memory, whereas TBPTT's memory cost scales linearly with the number of truncation steps. We examine all RBP variants along with BPTT and TBPTT in three different application domains: associative memory with continuous Hopfield networks, document classification in citation networks using graph neural networks and hyperparameter optimization for fully connected networks. All experiments demonstrate that RBPs, especially the Neumann-RBP variant, are efficient and effective for optimizing convergent recurrent neural networks.