 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Apr 20, 2026Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
Learning From Brains How to Regularize Machines
Nov 11, 2019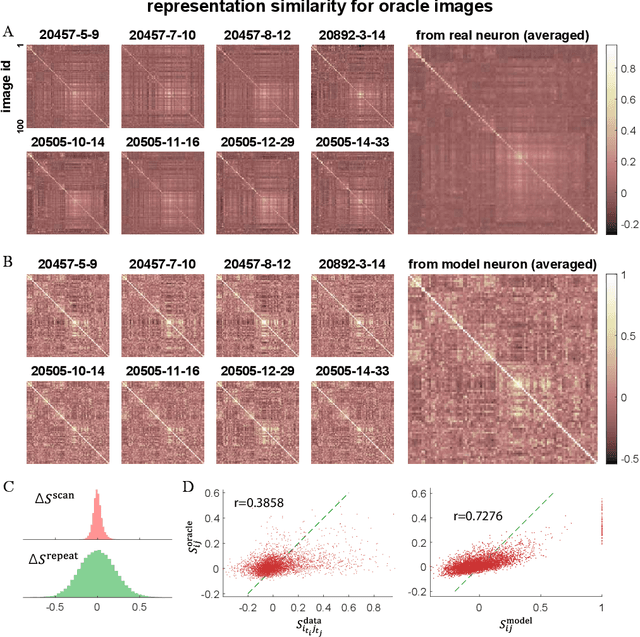
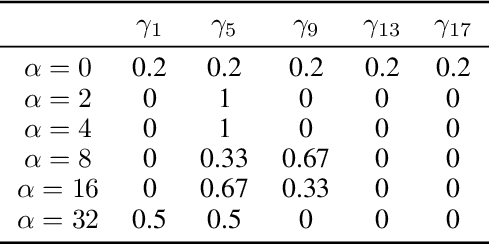

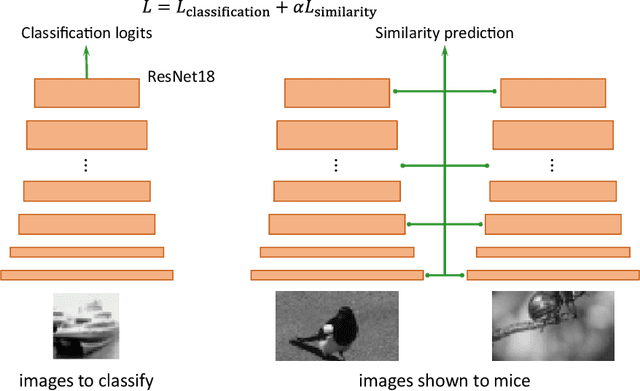
Despite impressive performance on numerous visual tasks, Convolutional Neural Networks (CNNs) --- unlike brains --- are often highly sensitive to small perturbations of their input, e.g. adversarial noise leading to erroneous decisions. We propose to regularize CNNs using large-scale neuroscience data to learn more robust neural features in terms of representational similarity. We presented natural images to mice and measured the responses of thousands of neurons from cortical visual areas. Next, we denoised the notoriously variable neural activity using strong predictive models trained on this large corpus of responses from the mouse visual system, and calculated the representational similarity for millions of pairs of images from the model's predictions. We then used the neural representation similarity to regularize CNNs trained on image classification by penalizing intermediate representations that deviated from neural ones. This preserved performance of baseline models when classifying images under standard benchmarks, while maintaining substantially higher performance compared to baseline or control models when classifying noisy images. Moreover, the models regularized with cortical representations also improved model robustness in terms of adversarial attacks. This demonstrates that regularizing with neural data can be an effective tool to create an inductive bias towards more robust inference.
A rotation-equivariant convolutional neural network model of primary visual cortex
Sep 27, 2018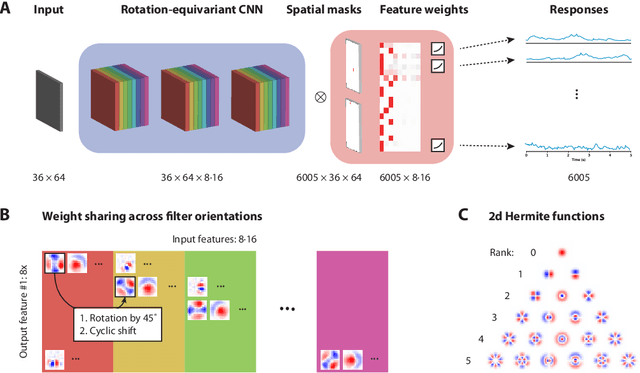
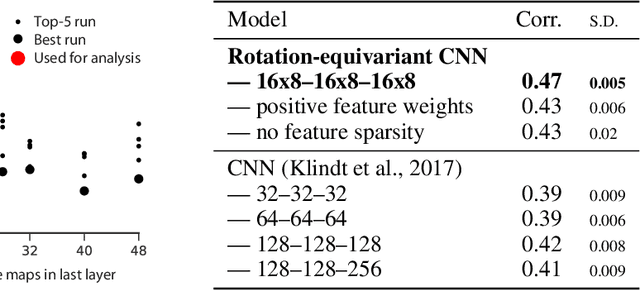
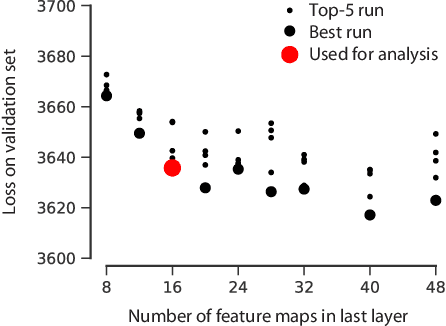
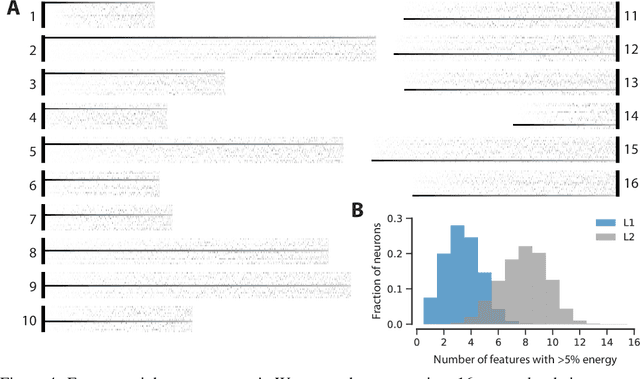
Classical models describe primary visual cortex (V1) as a filter bank of orientation-selective linear-nonlinear (LN) or energy models, but these models fail to predict neural responses to natural stimuli accurately. Recent work shows that models based on convolutional neural networks (CNNs) lead to much more accurate predictions, but it remains unclear which features are extracted by V1 neurons beyond orientation selectivity and phase invariance. Here we work towards systematically studying V1 computations by categorizing neurons into groups that perform similar computations. We present a framework to identify common features independent of individual neurons' orientation selectivity by using a rotation-equivariant convolutional neural network, which automatically extracts every feature at multiple different orientations. We fit this model to responses of a population of 6000 neurons to natural images recorded in mouse primary visual cortex using two-photon imaging. We show that our rotation-equivariant network not only outperforms a regular CNN with the same number of feature maps, but also reveals a number of common features shared by many V1 neurons, which deviate from the typical textbook idea of V1 as a bank of Gabor filters. Our findings are a first step towards a powerful new tool to study the nonlinear computations in V1.