 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Panoptic Segmentation
Jul 06, 2022
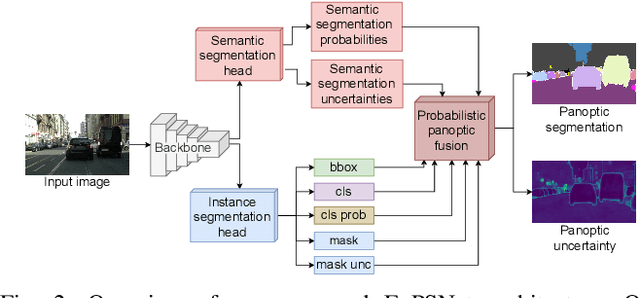
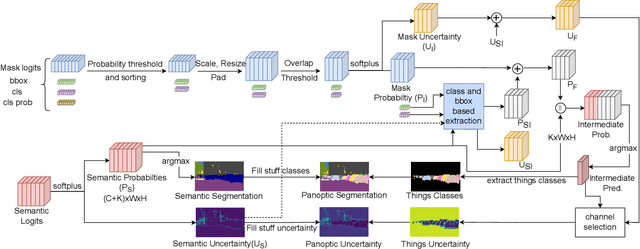

Reliable scene understanding is indispensable for modern autonomous systems. Current learning-based methods typically try to maximize their performance based on segmentation metrics that only consider the quality of the segmentation. However, for the safe operation of a system in the real world it is crucial to consider the uncertainty in the prediction as well. In this work, we introduce the novel task of uncertainty-aware panoptic segmentation, which aims to predict per-pixel semantic and instance segmentations, together with per-pixel uncertainty estimates. We define two novel metrics to facilitate its quantitative analysis, the uncertainty-aware Panoptic Quality (uPQ) and the panoptic Expected Calibration Error (pECE). We further propose the novel top-down Evidential Panoptic Segmentation Network (EvPSNet) to solve this task. Our architecture employs a simple yet effective probabilistic fusion module that leverages the predicted uncertainties. Additionally, we propose a new Lov\'asz evidential loss function to optimize the IoU for the segmentation utilizing the probabilities provided by deep evidential learning. Furthermore, we provide several strong baselines combining state-of-the-art panoptic segmentation networks with sampling-free uncertainty estimation techniques. Extensive evaluations show that our EvPSNet achieves the new state-of-the-art for the standard Panoptic Quality (PQ), as well as for our uncertainty-aware panoptic metrics.
What Matters in Language Conditioned Robotic Imitation Learning
Apr 13, 2022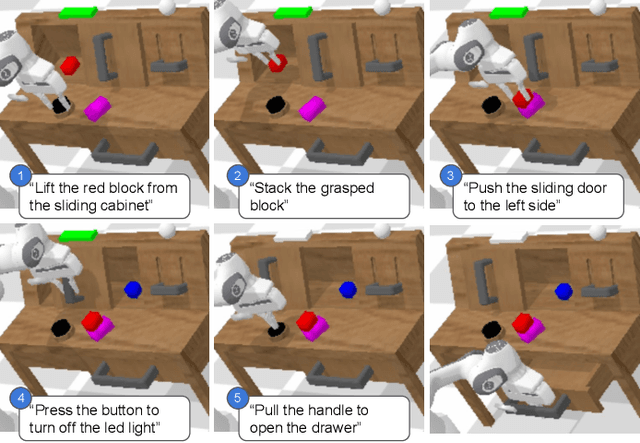
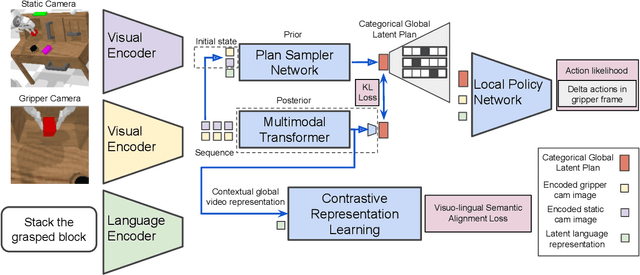
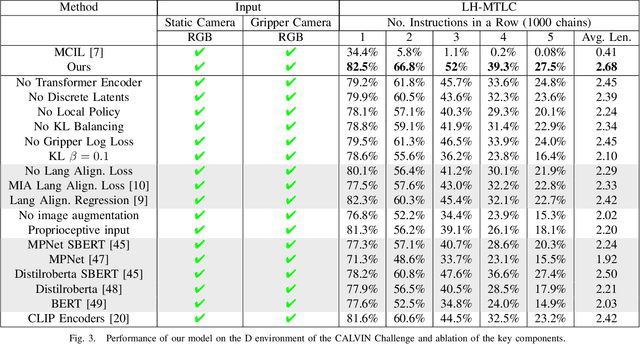
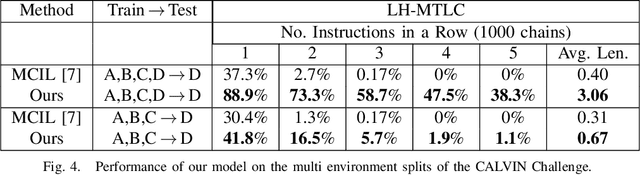
A long-standing goal in robotics is to build robots that can perform a wide range of daily tasks from perceptions obtained with their onboard sensors and specified only via natural language. While recently substantial advances have been achieved in language-driven robotics by leveraging end-to-end learning from pixels, there is no clear and well-understood process for making various design choices due to the underlying variation in setups. In this paper, we conduct an extensive study of the most critical challenges in learning language conditioned policies from offline free-form imitation datasets. We further identify architectural and algorithmic techniques that improve performance, such as a hierarchical decomposition of the robot control learning, a multimodal transformer encoder, discrete latent plans and a self-supervised contrastive loss that aligns video and language representations. By combining the results of our investigation with our improved model components, we are able to present a novel approach that significantly outperforms the state of the art on the challenging language conditioned long-horizon robot manipulation CALVIN benchmark. We have open-sourced our implementation to facilitate future research in learning to perform many complex manipulation skills in a row specified with natural language. Codebase and trained models available at http://hulc.cs.uni-freiburg.de
Continual SLAM: Beyond Lifelong Simultaneous Localization and Mapping through Continual Learning
Mar 03, 2022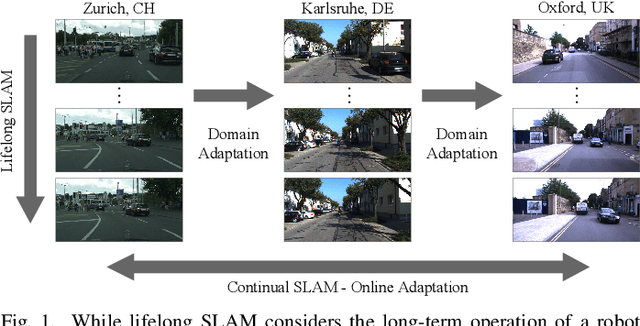
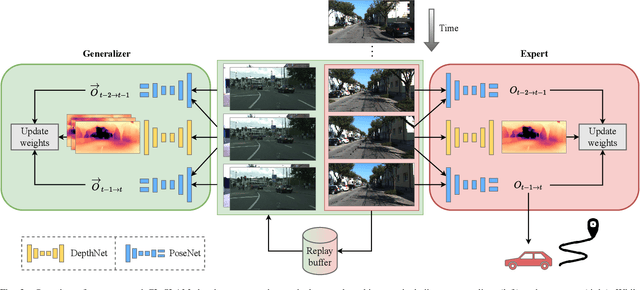
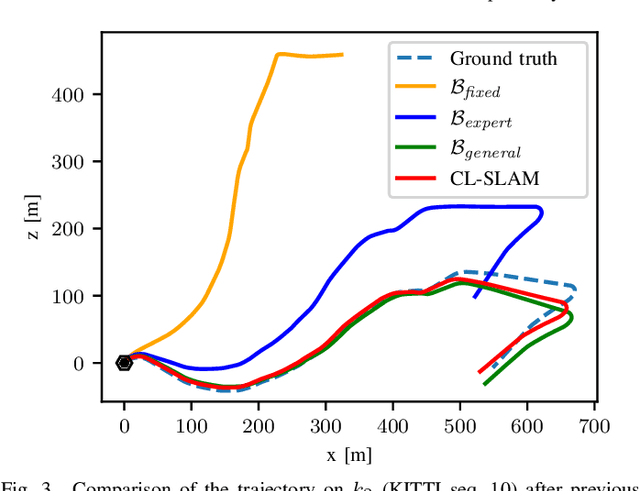
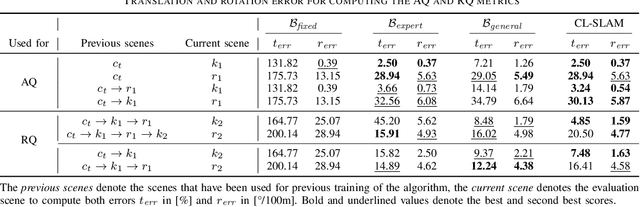
While lifelong SLAM addresses the capability of a robot to adapt to changes within a single environment over time, in this paper we introduce the task of continual SLAM. Here, a robot is deployed sequentially in a variety of different environments and has to transfer its knowledge of previously experienced environments to thus far unseen environments, while avoiding catastrophic forgetting. This is particularly relevant in the context of vision-based approaches, where the relevant features vary widely between different environments. We propose a novel approach for solving the continual SLAM problem by introducing CL-SLAM. Our approach consists of a dual-network architecture that handles both short-term adaptation and long-term memory retention by incorporating a replay buffer. Extensive evaluations of CL-SLAM in three different environments demonstrate that it outperforms several baselines inspired by existing continual learning-based visual odometry methods. The code of our work is publicly available at http://continual-slam.cs.uni-freiburg.de.
Affordance Learning from Play for Sample-Efficient Policy Learning
Mar 01, 2022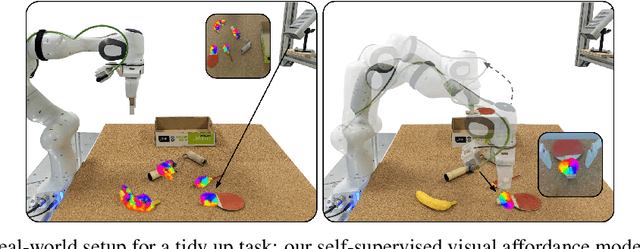
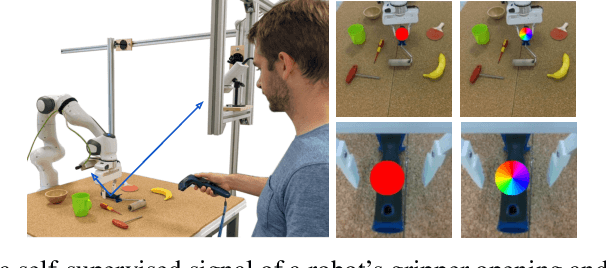
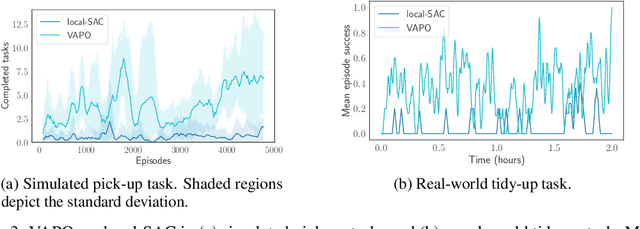
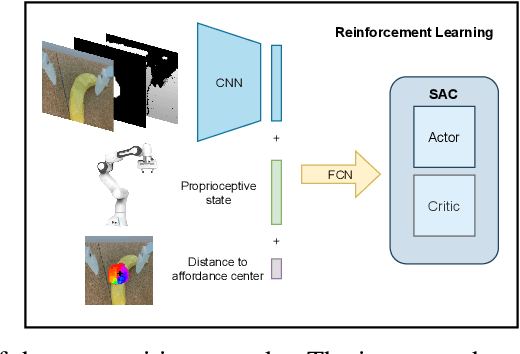
Robots operating in human-centered environments should have the ability to understand how objects function: what can be done with each object, where this interaction may occur, and how the object is used to achieve a goal. To this end, we propose a novel approach that extracts a self-supervised visual affordance model from human teleoperated play data and leverages it to enable efficient policy learning and motion planning. We combine model-based planning with model-free deep reinforcement learning (RL) to learn policies that favor the same object regions favored by people, while requiring minimal robot interactions with the environment. We evaluate our algorithm, Visual Affordance-guided Policy Optimization (VAPO), with both diverse simulation manipulation tasks and real world robot tidy-up experiments to demonstrate the effectiveness of our affordance-guided policies. We find that our policies train 4x faster than the baselines and generalize better to novel objects because our visual affordance model can anticipate their affordance regions.
Self-Supervised Moving Vehicle Detection from Audio-Visual Cues
Jan 30, 2022
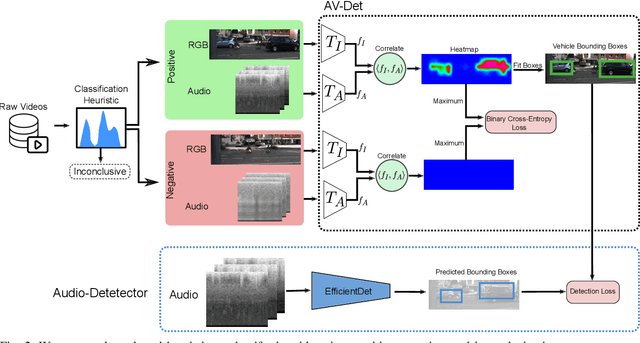

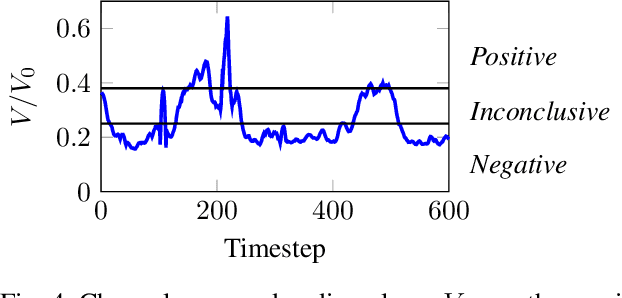
Robust detection of moving vehicles is a critical task for any autonomously operating outdoor robot or self-driving vehicle. Most modern approaches for solving this task rely on training image-based detectors using large-scale vehicle detection datasets such as nuScenes or the Waymo Open Dataset. Providing manual annotations is an expensive and laborious exercise that does not scale well in practice. To tackle this problem, we propose a self-supervised approach that leverages audio-visual cues to detect moving vehicles in videos. Our approach employs contrastive learning for localizing vehicles in images from corresponding pairs of images and recorded audio. In extensive experiments carried out with a real-world dataset, we demonstrate that our approach provides accurate detections of moving vehicles and does not require manual annotations. We furthermore show that our model can be used as a teacher to supervise an audio-only detection model. This student model is invariant to illumination changes and thus effectively bridges the domain gap inherent to models leveraging exclusively vision as the predominant modality.
CALVIN: A Benchmark for Language-conditioned Policy Learning for Long-horizon Robot Manipulation Tasks
Dec 08, 2021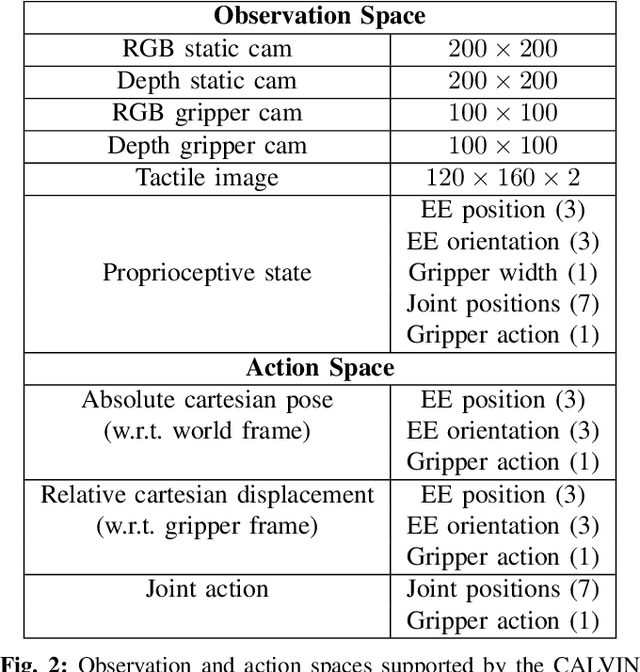
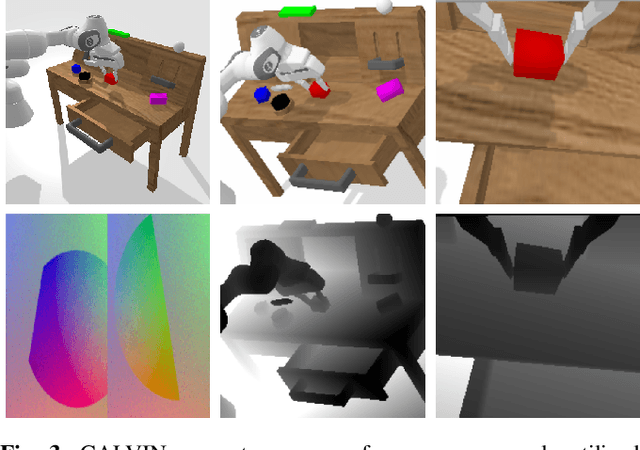
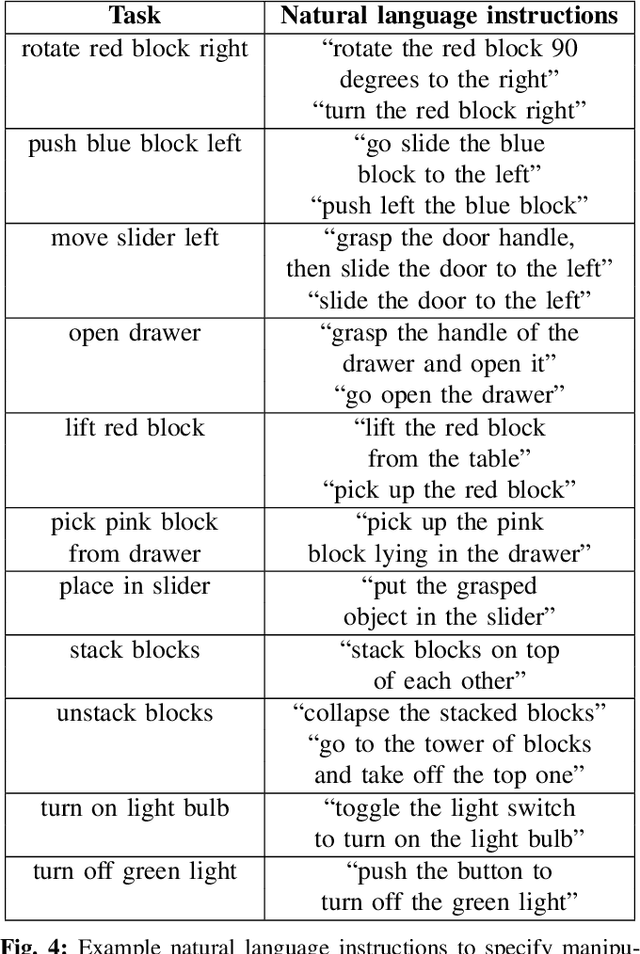

General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions. In this paper, we present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites. We evaluate the agents in zero-shot to novel language instructions and to novel environments and objects. We show that a baseline model based on multi-context imitation learning performs poorly on CALVIN, suggesting that there is significant room for developing innovative agents that learn to relate human language to their world models with this benchmark.
Robot Skill Adaptation via Soft Actor-Critic Gaussian Mixture Models
Nov 25, 2021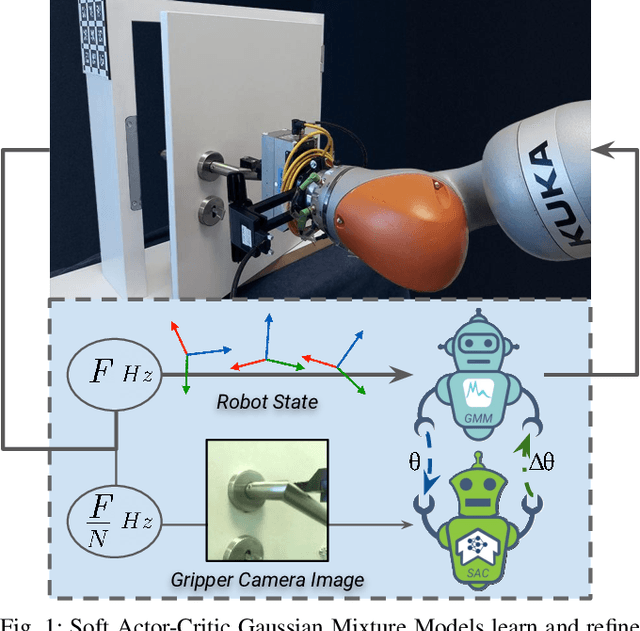
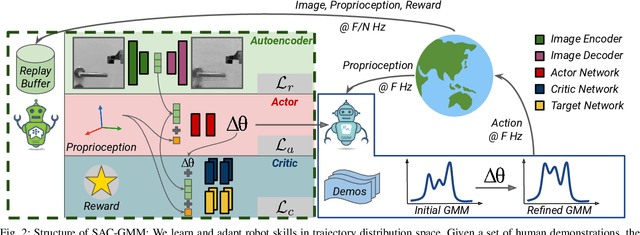


A core challenge for an autonomous agent acting in the real world is to adapt its repertoire of skills to cope with its noisy perception and dynamics. To scale learning of skills to long-horizon tasks, robots should be able to learn and later refine their skills in a structured manner through trajectories rather than making instantaneous decisions individually at each time step. To this end, we propose the Soft Actor-Critic Gaussian Mixture Model (SAC-GMM), a novel hybrid approach that learns robot skills through a dynamical system and adapts the learned skills in their own trajectory distribution space through interactions with the environment. Our approach combines classical robotics techniques of learning from demonstration with the deep reinforcement learning framework and exploits their complementary nature. We show that our method utilizes sensors solely available during the execution of preliminarily learned skills to extract relevant features that lead to faster skill refinement. Extensive evaluations in both simulation and real-world environments demonstrate the effectiveness of our method in refining robot skills by leveraging physical interactions, high-dimensional sensory data, and sparse task completion rewards. Videos, code, and pre-trained models are available at \url{http://sac-gmm.cs.uni-freiburg.de}.
Adaptively Calibrated Critic Estimates for Deep Reinforcement Learning
Nov 24, 2021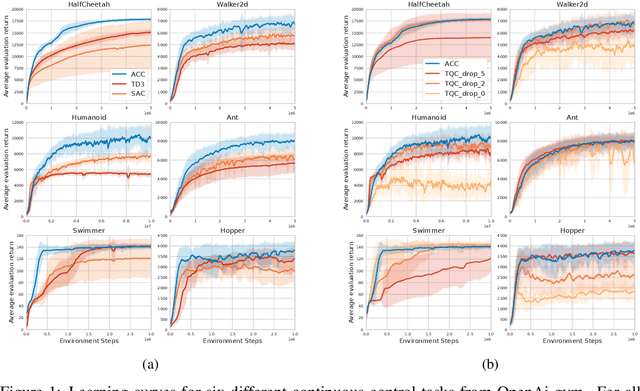
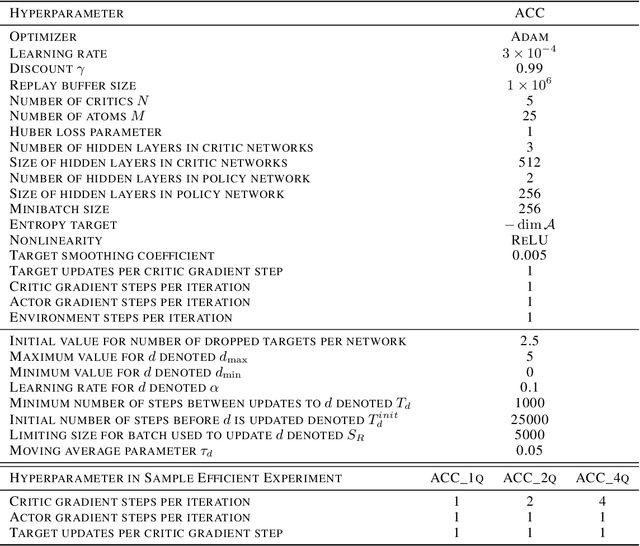
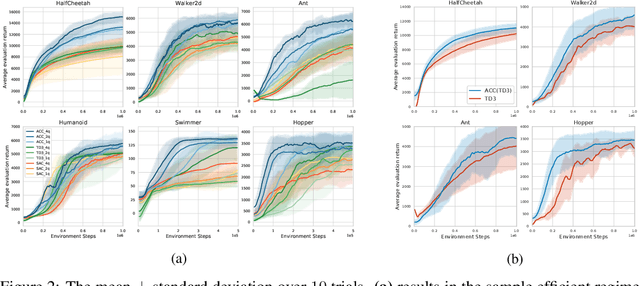
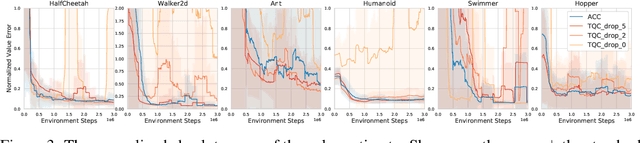
Accurate value estimates are important for off-policy reinforcement learning. Algorithms based on temporal difference learning typically are prone to an over- or underestimation bias building up over time. In this paper, we propose a general method called Adaptively Calibrated Critics (ACC) that uses the most recent high variance but unbiased on-policy rollouts to alleviate the bias of the low variance temporal difference targets. We apply ACC to Truncated Quantile Critics, which is an algorithm for continuous control that allows regulation of the bias with a hyperparameter tuned per environment. The resulting algorithm adaptively adjusts the parameter during training rendering hyperparameter search unnecessary and sets a new state of the art on the OpenAI gym continuous control benchmark among all algorithms that do not tune hyperparameters for each environment. Additionally, we demonstrate that ACC is quite general by further applying it to TD3 and showing an improved performance also in this setting.
Robust Monocular Localization in Sparse HD Maps Leveraging Multi-Task Uncertainty Estimation
Oct 20, 2021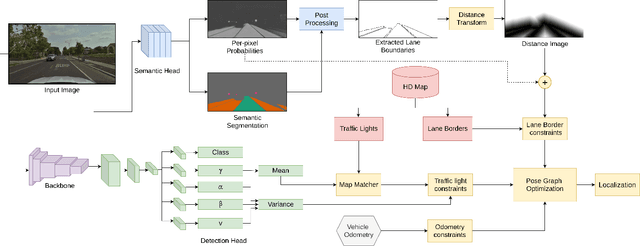


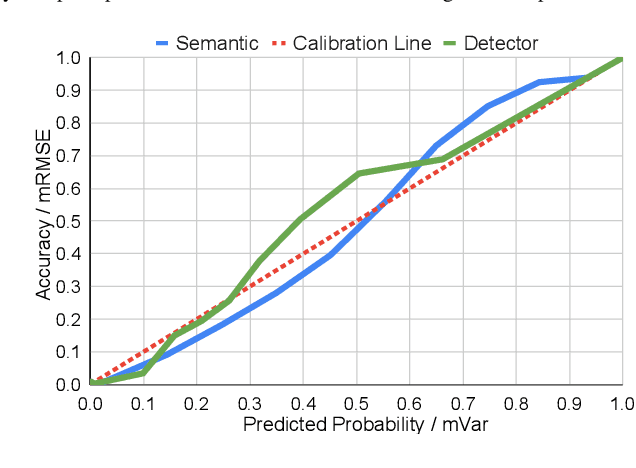
Robust localization in dense urban scenarios using a low-cost sensor setup and sparse HD maps is highly relevant for the current advances in autonomous driving, but remains a challenging topic in research. We present a novel monocular localization approach based on a sliding-window pose graph that leverages predicted uncertainties for increased precision and robustness against challenging scenarios and per frame failures. To this end, we propose an efficient multi-task uncertainty-aware perception module, which covers semantic segmentation, as well as bounding box detection, to enable the localization of vehicles in sparse maps, containing only lane borders and traffic lights. Further, we design differentiable cost maps that are directly generated from the estimated uncertainties. This opens up the possibility to minimize the reprojection loss of amorphous map elements in an association free and uncertainty-aware manner. Extensive evaluation on the Lyft 5 dataset shows that, despite the sparsity of the map, our approach enables robust and accurate 6D localization in challenging urban scenarios
Correct Me if I am Wrong: Interactive Learning for Robotic Manipulation
Oct 07, 2021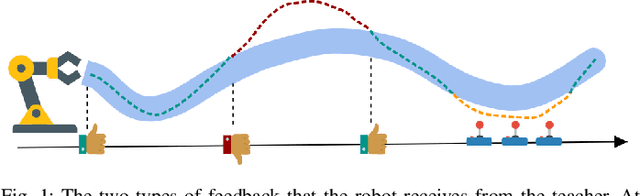
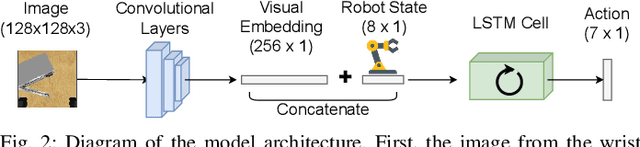

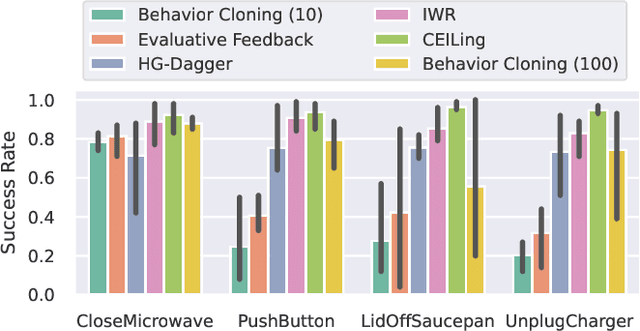
Learning to solve complex manipulation tasks from visual observations is a dominant challenge for real-world robot learning. Deep reinforcement learning algorithms have recently demonstrated impressive results, although they still require an impractical amount of time-consuming trial-and-error iterations. In this work, we consider the promising alternative paradigm of interactive learning where a human teacher provides feedback to the policy during execution, as opposed to imitation learning where a pre-collected dataset of perfect demonstrations is used. Our proposed CEILing (Corrective and Evaluative Interactive Learning) framework combines both corrective and evaluative feedback from the teacher to train a stochastic policy in an asynchronous manner, and employs a dedicated mechanism to trade off human corrections with the robot's own experience. We present results obtained with our framework in extensive simulation and real-world experiments that demonstrate that CEILing can effectively solve complex robot manipulation tasks directly from raw images in less than one hour of real-world training.