 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation
May 21, 2025Large language models are able to exploit in-context learning to access external knowledge beyond their training data through retrieval-augmentation. While promising, its inner workings remain unclear. In this work, we shed light on the mechanism of in-context retrieval augmentation for question answering by viewing a prompt as a composition of informational components. We propose an attribution-based method to identify specialized attention heads, revealing in-context heads that comprehend instructions and retrieve relevant contextual information, and parametric heads that store entities' relational knowledge. To better understand their roles, we extract function vectors and modify their attention weights to show how they can influence the answer generation process. Finally, we leverage the gained insights to trace the sources of knowledge used during inference, paving the way towards more safe and transparent language models.
Steering CLIP's vision transformer with sparse autoencoders
Apr 11, 2025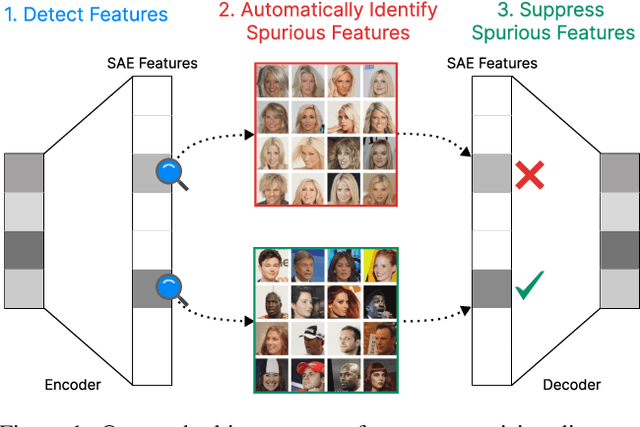
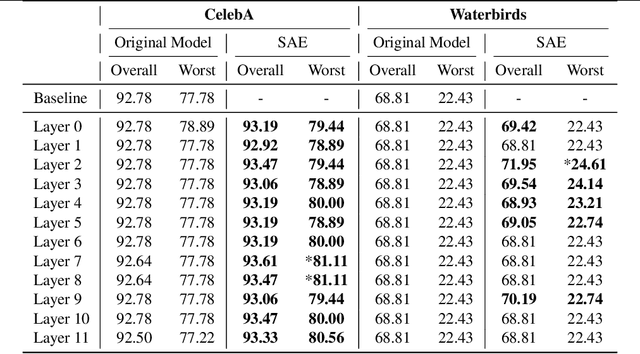

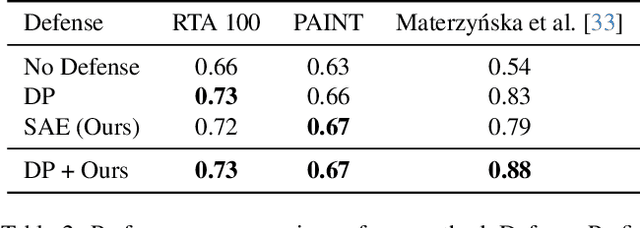
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
Efficient Federated Learning Tiny Language Models for Mobile Network Feature Prediction
Apr 02, 2025In telecommunications, Autonomous Networks (ANs) automatically adjust configurations based on specific requirements (e.g., bandwidth) and available resources. These networks rely on continuous monitoring and intelligent mechanisms for self-optimization, self-repair, and self-protection, nowadays enhanced by Neural Networks (NNs) to enable predictive modeling and pattern recognition. Here, Federated Learning (FL) allows multiple AN cells - each equipped with NNs - to collaboratively train models while preserving data privacy. However, FL requires frequent transmission of large neural data and thus an efficient, standardized compression strategy for reliable communication. To address this, we investigate NNCodec, a Fraunhofer implementation of the ISO/IEC Neural Network Coding (NNC) standard, within a novel FL framework that integrates tiny language models (TLMs) for various mobile network feature prediction (e.g., ping, SNR or band frequency). Our experimental results on the Berlin V2X dataset demonstrate that NNCodec achieves transparent compression (i.e., negligible performance loss) while reducing communication overhead to below 1%, showing the effectiveness of combining NNC with FL in collaboratively learned autonomous mobile networks.
ASIDE: Architectural Separation of Instructions and Data in Language Models
Mar 13, 2025



Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose an architectural change, ASIDE, that allows the model to clearly separate between instructions and data by using separate embeddings for them. Instead of training the embeddings from scratch, we propose a method to convert an existing model to ASIDE form by using two copies of the original model's embeddings layer, and applying an orthogonal rotation to one of them. We demonstrate the effectiveness of our method by showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
Post-Hoc Concept Disentanglement: From Correlated to Isolated Concept Representations
Mar 07, 2025Concept Activation Vectors (CAVs) are widely used to model human-understandable concepts as directions within the latent space of neural networks. They are trained by identifying directions from the activations of concept samples to those of non-concept samples. However, this method often produces similar, non-orthogonal directions for correlated concepts, such as "beard" and "necktie" within the CelebA dataset, which frequently co-occur in images of men. This entanglement complicates the interpretation of concepts in isolation and can lead to undesired effects in CAV applications, such as activation steering. To address this issue, we introduce a post-hoc concept disentanglement method that employs a non-orthogonality loss, facilitating the identification of orthogonal concept directions while preserving directional correctness. We evaluate our approach with real-world and controlled correlated concepts in CelebA and a synthetic FunnyBirds dataset with VGG16 and ResNet18 architectures. We further demonstrate the superiority of orthogonalized concept representations in activation steering tasks, allowing (1) the insertion of isolated concepts into input images through generative models and (2) the removal of concepts for effective shortcut suppression with reduced impact on correlated concepts in comparison to baseline CAVs.
FADE: Why Bad Descriptions Happen to Good Features
Feb 24, 2025Recent advances in mechanistic interpretability have highlighted the potential of automating interpretability pipelines in analyzing the latent representations within LLMs. While they may enhance our understanding of internal mechanisms, the field lacks standardized evaluation methods for assessing the validity of discovered features. We attempt to bridge this gap by introducing FADE: Feature Alignment to Description Evaluation, a scalable model-agnostic framework for evaluating feature-description alignment. FADE evaluates alignment across four key metrics - Clarity, Responsiveness, Purity, and Faithfulness - and systematically quantifies the causes for the misalignment of feature and their description. We apply FADE to analyze existing open-source feature descriptions, and assess key components of automated interpretability pipelines, aiming to enhance the quality of descriptions. Our findings highlight fundamental challenges in generating feature descriptions, particularly for SAEs as compared to MLP neurons, providing insights into the limitations and future directions of automated interpretability. We release FADE as an open-source package at: https://github.com/brunibrun/FADE.
A Close Look at Decomposition-based XAI-Methods for Transformer Language Models
Feb 21, 2025Various XAI attribution methods have been recently proposed for the transformer architecture, allowing for insights into the decision-making process of large language models by assigning importance scores to input tokens and intermediate representations. One class of methods that seems very promising in this direction includes decomposition-based approaches, i.e., XAI-methods that redistribute the model's prediction logit through the network, as this value is directly related to the prediction. In the previous literature we note though that two prominent methods of this category, namely ALTI-Logit and LRP, have not yet been analyzed in juxtaposition and hence we propose to close this gap by conducting a careful quantitative evaluation w.r.t. ground truth annotations on a subject-verb agreement task, as well as various qualitative inspections, using BERT, GPT-2 and LLaMA-3 as a testbed. Along the way we compare and extend the ALTI-Logit and LRP methods, including the recently proposed AttnLRP variant, from an algorithmic and implementation perspective. We further incorporate in our benchmark two widely-used gradient-based attribution techniques. Finally, we make our carefullly constructed benchmark dataset for evaluating attributions on language models, as well as our code, publicly available in order to foster evaluation of XAI-methods on a well-defined common ground.
Synthetic Datasets for Machine Learning on Spatio-Temporal Graphs using PDEs
Feb 06, 2025Many physical processes can be expressed through partial differential equations (PDEs). Real-world measurements of such processes are often collected at irregularly distributed points in space, which can be effectively represented as graphs; however, there are currently only a few existing datasets. Our work aims to make advancements in the field of PDE-modeling accessible to the temporal graph machine learning community, while addressing the data scarcity problem, by creating and utilizing datasets based on PDEs. In this work, we create and use synthetic datasets based on PDEs to support spatio-temporal graph modeling in machine learning for different applications. More precisely, we showcase three equations to model different types of disasters and hazards in the fields of epidemiology, atmospheric particles, and tsunami waves. Further, we show how such created datasets can be used by benchmarking several machine learning models on the epidemiological dataset. Additionally, we show how pre-training on this dataset can improve model performance on real-world epidemiological data. The presented methods enable others to create datasets and benchmarks customized to individual requirements. The source code for our methodology and the three created datasets can be found on https://github.com/github-usr-ano/Temporal_Graph_Data_PDEs.
Ensuring Medical AI Safety: Explainable AI-Driven Detection and Mitigation of Spurious Model Behavior and Associated Data
Jan 23, 2025



Deep neural networks are increasingly employed in high-stakes medical applications, despite their tendency for shortcut learning in the presence of spurious correlations, which can have potentially fatal consequences in practice. Detecting and mitigating shortcut behavior is a challenging task that often requires significant labeling efforts from domain experts. To alleviate this problem, we introduce a semi-automated framework for the identification of spurious behavior from both data and model perspective by leveraging insights from eXplainable Artificial Intelligence (XAI). This allows the retrieval of spurious data points and the detection of model circuits that encode the associated prediction rules. Moreover, we demonstrate how these shortcut encodings can be used for XAI-based sample- and pixel-level data annotation, providing valuable information for bias mitigation methods to unlearn the undesired shortcut behavior. We show the applicability of our framework using four medical datasets across two modalities, featuring controlled and real-world spurious correlations caused by data artifacts. We successfully identify and mitigate these biases in VGG16, ResNet50, and contemporary Vision Transformer models, ultimately increasing their robustness and applicability for real-world medical tasks.
Mechanistic understanding and validation of large AI models with SemanticLens
Jan 09, 2025

Unlike human-engineered systems such as aeroplanes, where each component's role and dependencies are well understood, the inner workings of AI models remain largely opaque, hindering verifiability and undermining trust. This paper introduces SemanticLens, a universal explanation method for neural networks that maps hidden knowledge encoded by components (e.g., individual neurons) into the semantically structured, multimodal space of a foundation model such as CLIP. In this space, unique operations become possible, including (i) textual search to identify neurons encoding specific concepts, (ii) systematic analysis and comparison of model representations, (iii) automated labelling of neurons and explanation of their functional roles, and (iv) audits to validate decision-making against requirements. Fully scalable and operating without human input, SemanticLens is shown to be effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data. By enabling component-level understanding and validation, the proposed approach helps bridge the "trust gap" between AI models and traditional engineered systems. We provide code for SemanticLens on https://github.com/jim-berend/semanticlens and a demo on https://semanticlens.hhi-research-insights.eu.