 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAt the Edge of Understanding: Sparse Autoencoders Trace The Limits of Transformer Generalization
Jun 24, 2026Pre-trained transformers have demonstrated remarkable generalization abilities, at times extending beyond the scope of their training data. Yet, real-world deployments often face unexpected or adversarial data that diverges from training data distributions. Without explicit mechanisms for handling such shifts, model reliability and safety degrade, urging more disciplined study of out-of-distribution (OOD) settings for transformers. By systematic experiments, we present a mechanistic framework for delineating the precise contours of transformer model robustness. We find that OOD inputs, including subtle typos and jailbreak prompts, drive language models to operate on an increased number of fallacious concepts in their internals. We leverage this device to quantify and understand the degree of distributional shift in prompts, enabling a mechanistically grounded fine-tuning strategy to robustify LLMs. Expanding the very notion of OOD from input data to a model's private computational processes, a new transformer diagnostic at inference time is a critical step toward making AI systems safe for deployment across science, business, and government.
Interpreting Physics in Video World Models
Feb 04, 2026A long-standing question in physical reasoning is whether video-based models need to rely on factorized representations of physical variables in order to make physically accurate predictions, or whether they can implicitly represent such variables in a task-specific, distributed manner. While modern video world models achieve strong performance on intuitive physics benchmarks, it remains unclear which of these representational regimes they implement internally. Here, we present the first interpretability study to directly examine physical representations inside large-scale video encoders. Using layerwise probing, subspace geometry, patch-level decoding, and targeted attention ablations, we characterize where physical information becomes accessible and how it is organized within encoder-based video transformers. Across architectures, we identify a sharp intermediate-depth transition -- which we call the Physics Emergence Zone -- at which physical variables become accessible. Physics-related representations peak shortly after this transition and degrade toward the output layers. Decomposing motion into explicit variables, we find that scalar quantities such as speed and acceleration are available from early layers onwards, whereas motion direction becomes accessible only at the Physics Emergence Zone. Notably, we find that direction is encoded through a high-dimensional population structure with circular geometry, requiring coordinated multi-feature intervention to control. These findings suggest that modern video models do not use factorized representations of physical variables like a classical physics engine. Instead, they use a distributed representation that is nonetheless sufficient for making physical predictions.
Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
Jan 27, 2026Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in vision-language representation learning, powering diverse downstream tasks and serving as the default vision backbone in multimodal large language models (MLLMs). Despite its success, CLIP's dense and opaque latent representations pose significant interpretability challenges. A common assumption is that interpretability and performance are in tension: enforcing sparsity during training degrades accuracy, motivating recent post-hoc approaches such as Sparse Autoencoders (SAEs). However, these post-hoc approaches often suffer from degraded downstream performance and loss of CLIP's inherent multimodal capabilities, with most learned features remaining unimodal. We propose a simple yet effective approach that integrates sparsity directly into CLIP training, yielding representations that are both interpretable and performant. Compared to SAEs, our Sparse CLIP representations preserve strong downstream task performance, achieve superior interpretability, and retain multimodal capabilities. We show that multimodal sparse features enable straightforward semantic concept alignment and reveal training dynamics of how cross-modal knowledge emerges. Finally, as a proof of concept, we train a vision-language model on sparse CLIP representations that enables interpretable, vision-based steering capabilities. Our findings challenge conventional wisdom that interpretability requires sacrificing accuracy and demonstrate that interpretability and performance can be co-optimized, offering a promising design principle for future models.
From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers
Sep 08, 2025As generative AI systems become competent and democratized in science, business, and government, deeper insight into their failure modes now poses an acute need. The occasional volatility in their behavior, such as the propensity of transformer models to hallucinate, impedes trust and adoption of emerging AI solutions in high-stakes areas. In the present work, we establish how and when hallucinations arise in pre-trained transformer models through concept representations captured by sparse autoencoders, under scenarios with experimentally controlled uncertainty in the input space. Our systematic experiments reveal that the number of semantic concepts used by the transformer model grows as the input information becomes increasingly unstructured. In the face of growing uncertainty in the input space, the transformer model becomes prone to activate coherent yet input-insensitive semantic features, leading to hallucinated output. At its extreme, for pure-noise inputs, we identify a wide variety of robustly triggered and meaningful concepts in the intermediate activations of pre-trained transformer models, whose functional integrity we confirm through targeted steering. We also show that hallucinations in the output of a transformer model can be reliably predicted from the concept patterns embedded in transformer layer activations. This collection of insights on transformer internal processing mechanics has immediate consequences for aligning AI models with human values, AI safety, opening the attack surface for potential adversarial attacks, and providing a basis for automatic quantification of a model's hallucination risk.
How Visual Representations Map to Language Feature Space in Multimodal LLMs
Jun 13, 2025Effective multimodal reasoning depends on the alignment of visual and linguistic representations, yet the mechanisms by which vision-language models (VLMs) achieve this alignment remain poorly understood. We introduce a methodological framework that deliberately maintains a frozen large language model (LLM) and a frozen vision transformer (ViT), connected solely by training a linear adapter during visual instruction tuning. This design is fundamental to our approach: by keeping the language model frozen, we ensure it maintains its original language representations without adaptation to visual data. Consequently, the linear adapter must map visual features directly into the LLM's existing representational space rather than allowing the language model to develop specialized visual understanding through fine-tuning. Our experimental design uniquely enables the use of pre-trained sparse autoencoders (SAEs) of the LLM as analytical probes. These SAEs remain perfectly aligned with the unchanged language model and serve as a snapshot of the learned language feature-representations. Through systematic analysis of SAE reconstruction error, sparsity patterns, and feature SAE descriptions, we reveal the layer-wise progression through which visual representations gradually align with language feature representations, converging in middle-to-later layers. This suggests a fundamental misalignment between ViT outputs and early LLM layers, raising important questions about whether current adapter-based architectures optimally facilitate cross-modal representation learning.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
Decoding Vision Transformers: the Diffusion Steering Lens
Apr 18, 2025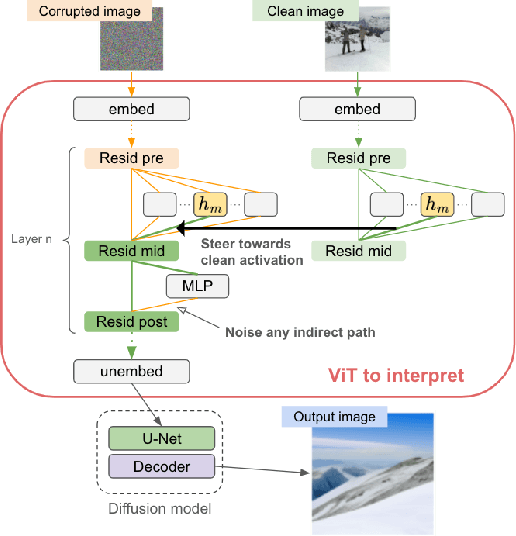


Logit Lens is a widely adopted method for mechanistic interpretability of transformer-based language models, enabling the analysis of how internal representations evolve across layers by projecting them into the output vocabulary space. Although applying Logit Lens to Vision Transformers (ViTs) is technically straightforward, its direct use faces limitations in capturing the richness of visual representations. Building on the work of Toker et al. (2024)~\cite{Toker2024-ve}, who introduced Diffusion Lens to visualize intermediate representations in the text encoders of text-to-image diffusion models, we demonstrate that while Diffusion Lens can effectively visualize residual stream representations in image encoders, it fails to capture the direct contributions of individual submodules. To overcome this limitation, we propose \textbf{Diffusion Steering Lens} (DSL), a novel, training-free approach that steers submodule outputs and patches subsequent indirect contributions. We validate our method through interventional studies, showing that DSL provides an intuitive and reliable interpretation of the internal processing in ViTs.
Steering CLIP's vision transformer with sparse autoencoders
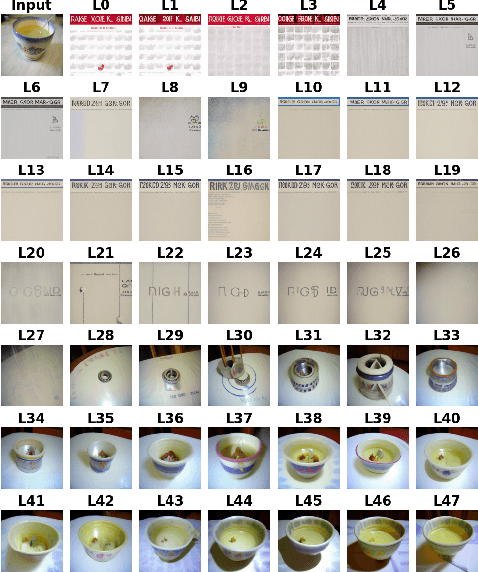
Apr 11, 2025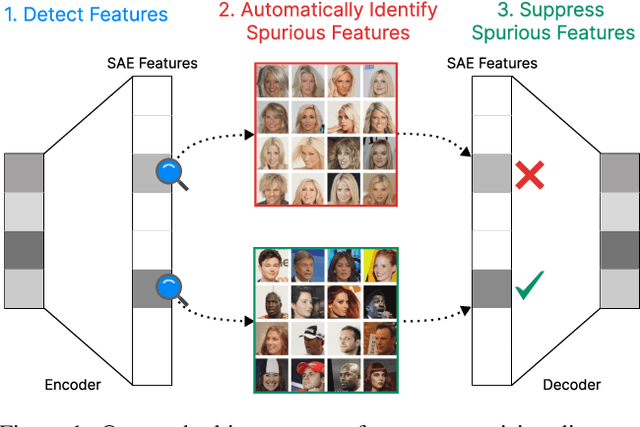
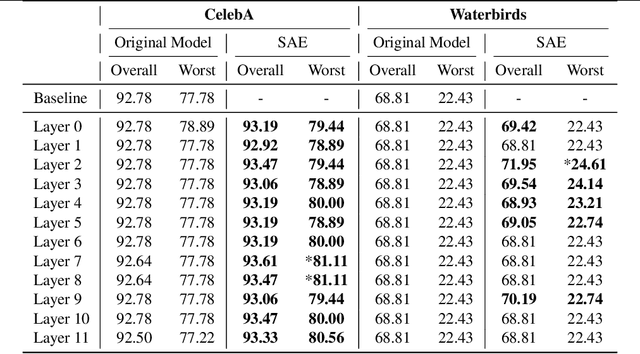

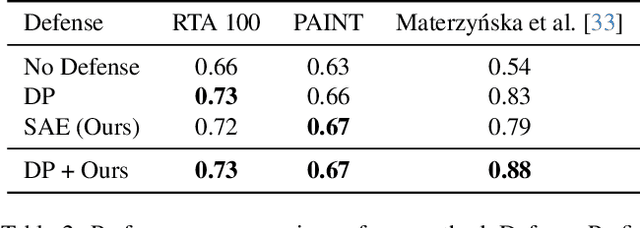
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024



Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.