 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Pareto-Front Optimization for Efficient Adaptive VVC Streaming
Jan 15, 2026Adaptive video streaming has facilitated improved video streaming over the past years. A balance among coding performance objectives such as bitrate, video quality, and decoding complexity is required to achieve efficient, content- and codec-dependent, adaptive video streaming. This paper proposes a multi-objective Pareto-front (PF) optimization framework to construct quality-monotonic, content-adaptive bitrate ladders Versatile Video Coding (VVC) streaming that jointly optimize video quality, bitrate, and decoding time, which is used as a practical proxy for decoding energy. Two strategies are introduced: the Joint Rate-Quality-Time Pareto Front (JRQT-PF) and the Joint Quality-Time Pareto Front (JQT-PF), each exploring different tradeoff formulations and objective prioritizations. The ladders are constructed under quality monotonicity constraints during adaptive streaming to ensure a consistent Quality of Experience (QoE). Experiments are conducted on a large-scale UHD dataset (Inter-4K), with quality assessed using PSNR, VMAF, and XPSNR, and complexity measured via decoding time and energy consumption. The JQT-PF method achieves 11.76% average bitrate savings while reducing average decoding time by 0.29% to maintain the same XPSNR, compared to a widely-used fixed ladder. More aggressive configurations yield up to 27.88% bitrate savings at the cost of increased complexity. The JRQT-PF strategy, on the other hand, offers more controlled tradeoffs, achieving 6.38 % bitrate savings and 6.17 % decoding time reduction. This framework outperforms existing methods, including fixed ladders, VMAF- and XPSNR-based dynamic resolution selection, and complexity-aware benchmarks. The results confirm that PF optimization with decoding time constraints enables sustainable, high-quality streaming tailored to network and device capabilities.
Optimizing Learned Image Compression on Scalar and Entropy-Constraint Quantization
Jun 10, 2025The continuous improvements on image compression with variational autoencoders have lead to learned codecs competitive with conventional approaches in terms of rate-distortion efficiency. Nonetheless, taking the quantization into account during the training process remains a problem, since it produces zero derivatives almost everywhere and needs to be replaced with a differentiable approximation which allows end-to-end optimization. Though there are different methods for approximating the quantization, none of them model the quantization noise correctly and thus, result in suboptimal networks. Hence, we propose an additional finetuning training step: After conventional end-to-end training, parts of the network are retrained on quantized latents obtained at the inference stage. For entropy-constraint quantizers like Trellis-Coded Quantization, the impact of the quantizer is particularly difficult to approximate by rounding or adding noise as the quantized latents are interdependently chosen through a trellis search based on both the entropy model and a distortion measure. We show that retraining on correctly quantized data consistently yields additional coding gain for both uniform scalar and especially for entropy-constraint quantization, without increasing inference complexity. For the Kodak test set, we obtain average savings between 1% and 2%, and for the TecNick test set up to 2.2% in terms of Bj{\o}ntegaard-Delta bitrate.
* Accepted at ICIP2024, the IEEE International Conference on Image Processing
Efficient Federated Learning Tiny Language Models for Mobile Network Feature Prediction
Apr 02, 2025In telecommunications, Autonomous Networks (ANs) automatically adjust configurations based on specific requirements (e.g., bandwidth) and available resources. These networks rely on continuous monitoring and intelligent mechanisms for self-optimization, self-repair, and self-protection, nowadays enhanced by Neural Networks (NNs) to enable predictive modeling and pattern recognition. Here, Federated Learning (FL) allows multiple AN cells - each equipped with NNs - to collaboratively train models while preserving data privacy. However, FL requires frequent transmission of large neural data and thus an efficient, standardized compression strategy for reliable communication. To address this, we investigate NNCodec, a Fraunhofer implementation of the ISO/IEC Neural Network Coding (NNC) standard, within a novel FL framework that integrates tiny language models (TLMs) for various mobile network feature prediction (e.g., ping, SNR or band frequency). Our experimental results on the Berlin V2X dataset demonstrate that NNCodec achieves transparent compression (i.e., negligible performance loss) while reducing communication overhead to below 1%, showing the effectiveness of combining NNC with FL in collaboratively learned autonomous mobile networks.
Decoding Complexity-Rate-Quality Pareto-Front for Adaptive VVC Streaming
Sep 27, 2024



Pareto-front optimization is crucial for addressing the multi-objective challenges in video streaming, enabling the identification of optimal trade-offs between conflicting goals such as bitrate, video quality, and decoding complexity. This paper explores the construction of efficient bitrate ladders for adaptive Versatile Video Coding (VVC) streaming, focusing on optimizing these trade-offs. We investigate various ladder construction methods based on Pareto-front optimization, including exhaustive Rate-Quality and fixed ladder approaches. We propose a joint decoding time-rate-quality Pareto-front, providing a comprehensive framework to balance bitrate, decoding time, and video quality in video streaming. This allows streaming services to tailor their encoding strategies to meet specific requirements, prioritizing low decoding latency, bandwidth efficiency, or a balanced approach, thus enhancing the overall user experience. The experimental results confirm and demonstrate these opportunities for navigating the decoding time-rate-quality space to support various use cases. For example, when prioritizing low decoding latency, the proposed method achieves decoding time reduction of 14.86% while providing Bjontegaard delta rate savings of 4.65% and 0.32dB improvement in the eXtended Peak Signal-to-Noise Ratio (XPSNR)-Rate domain over the traditional fixed ladder solution.
Convex-hull Estimation using XPSNR for Versatile Video Coding
Jun 19, 2024As adaptive streaming becomes crucial for delivering high-quality video content across diverse network conditions, accurate metrics to assess perceptual quality are essential. This paper explores using the eXtended Peak Signal-to-Noise Ratio (XPSNR) metric as an alternative to the popular Video Multimethod Assessment Fusion (VMAF) metric for determining optimized bitrate-resolution pairs in the context of Versatile Video Coding (VVC). Our study is rooted in the observation that XPSNR shows a superior correlation with subjective quality scores for VVC-coded Ultra-High Definition (UHD) content compared to VMAF. We predict the average XPSNR of VVC-coded bitstreams using spatiotemporal complexity features of the video and the target encoding configuration and then determine the convex-hull online. On average, the proposed convex-hull using XPSNR (VEXUS) achieves an overall quality improvement of 5.84 dB PSNR and 0.62 dB XPSNR while maintaining the same bitrate, compared to the default UHD encoding using the VVenC encoder, accompanied by an encoding time reduction of 44.43% and a decoding time reduction of 65.46%. This shift towards XPSNR as a guiding metric shall enhance the effectiveness of adaptive streaming algorithms, ensuring an optimal balance between bitrate efficiency and perceptual fidelity with advanced video coding standards.
Optimized Decoding-Energy-Aware Encoding in Practical VVC Implementations
Jun 27, 2022
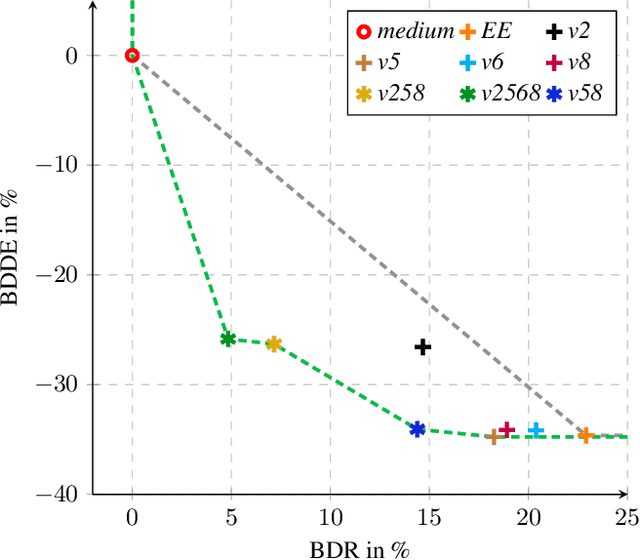
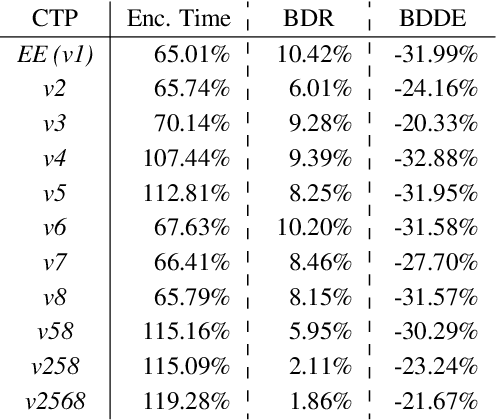
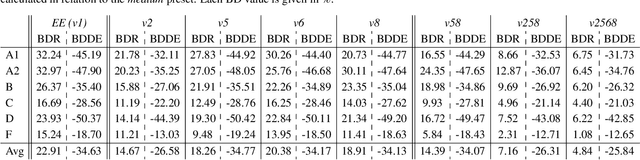
The optimization of the energy demand is crucial for modern video codecs. Previous studies show that the energy demand of VVC decoders can be improved by more than 50% if specific coding tools are disabled in the encoder. However, those approaches increase the bit rate by over 20% if the concept is applied to practical encoder implementations such as VVenC. Therefore, in this work, we investigate VVenC and study possibilities to reduce the additional bit rate, while still achieving low-energy decoding at reasonable encoding times. We show that encoding using our proposed coding tool profiles, the decoding energy efficiency is improved by over 25% with a bit rate increase of less than 5% with respect to standard encoding. Furthermore, we propose a second coding tool profile targeting maximum energy savings, which achieves 34% of energy savings at bitrate increases below 15%.
A Complete End-To-End Open Source Toolchain for the Versatile Video Coding Standard
Jul 28, 2021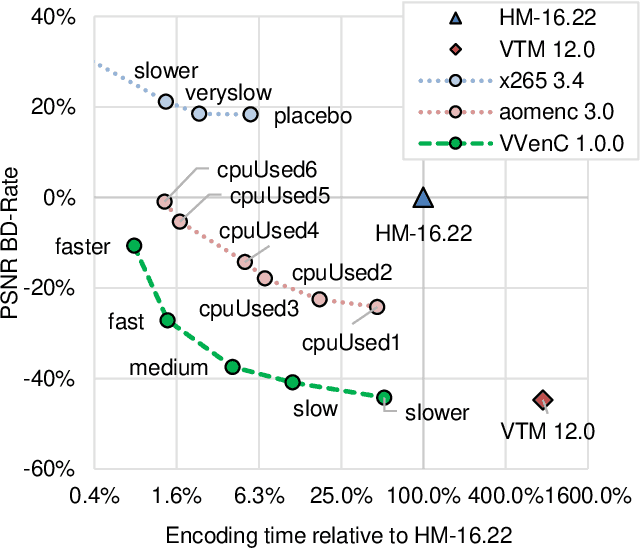
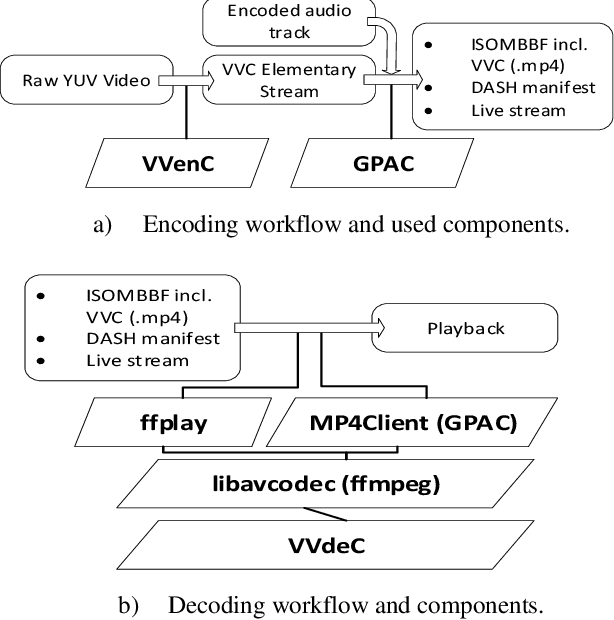
Versatile Video Coding (VVC) is the most recent international video coding standard jointly developed by ITU-T and ISO/IEC, which has been finalized in July 2020. VVC allows for significant bit-rate reductions around 50% for the same subjective video quality compared to its predecessor, High Efficiency Video Coding (HEVC). One year after finalization, VVC support in devices and chipsets is still under development, which is aligned with the typical development cycles of new video coding standards. This paper presents open-source software packages that allow building a complete VVC end-to-end toolchain already one year after its finalization. This includes the Fraunhofer HHI VVenC library for fast and efficient VVC encoding as well as HHI's VVdeC library for live decoding. An experimental integration of VVC in the GPAC software tools and FFmpeg media framework allows packaging VVC bitstreams, e.g. encoded with VVenC, in MP4 file format and using DASH for content creation and streaming. The integration of VVdeC allows playback on the receiver. Given these packages, step-by-step tutorials are provided for two possible application scenarios: VVC file encoding plus playback and adaptive streaming with DASH.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019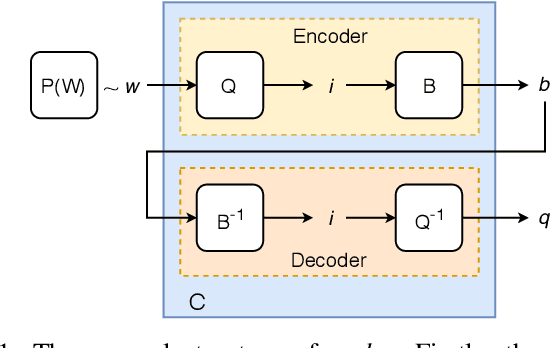
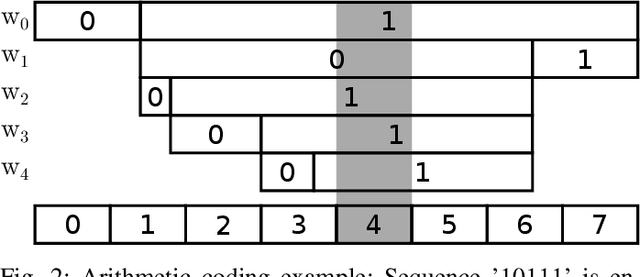
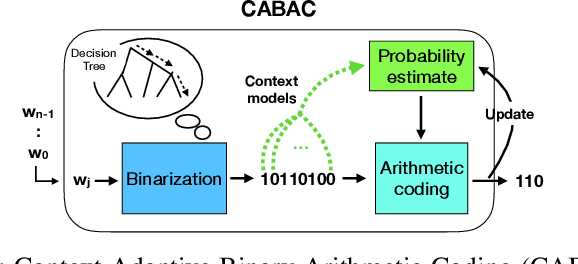
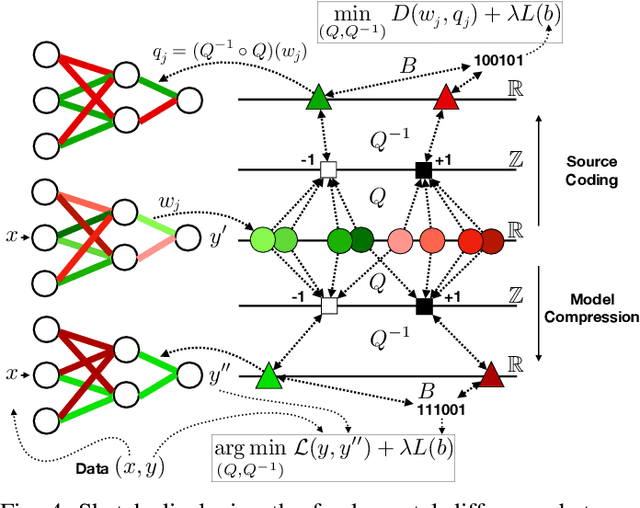
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019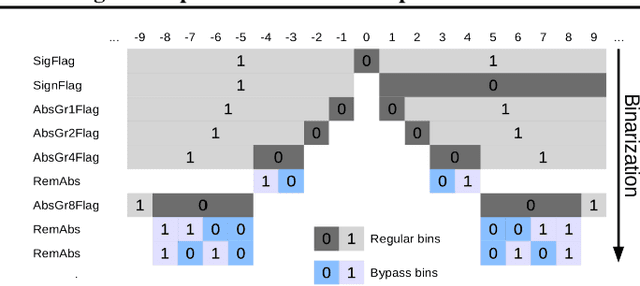
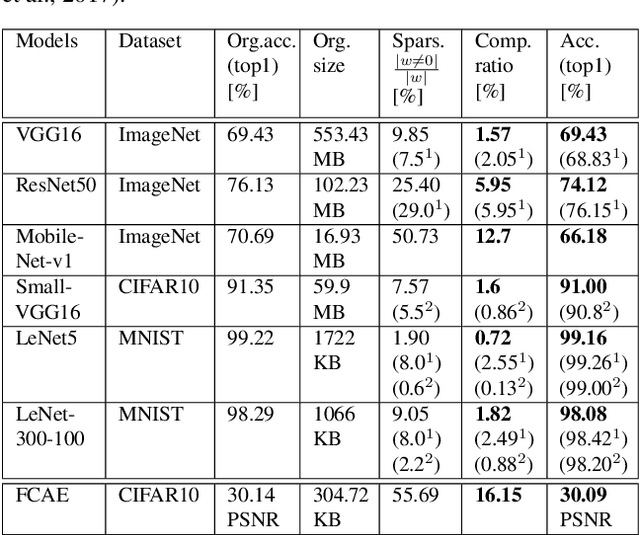
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.