 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Preferences of LLMs Under Directed Contextual Influence
Feb 26, 2026Moral benchmarks for LLMs typically use context-free prompts, implicitly assuming stable preferences. In deployment, however, prompts routinely include contextual signals such as user requests, cues on social norms, etc. that may steer decisions. We study how directed contextual influences reshape decisions in trolley-problem-style moral triage settings. We introduce a pilot evaluation harness for directed contextual influence in trolley-problem-style moral triage: for each demographic factor, we apply matched, direction-flipped contextual influences that differ only in which group they favor, enabling systematic measurement of directional response. We find that: (i) contextual influences often significantly shift decisions, even when only superficially relevant; (ii) baseline preferences are a poor predictor of directional steerability, as models can appear baseline-neutral yet exhibit systematic steerability asymmetry under influence; (iii) influences can backfire: models may explicitly claim neutrality or discount the contextual cue, yet their choices still shift, sometimes in the opposite direction; and (iv) reasoning reduces average sensitivity, but amplifies the effect of biased few-shot examples. Our findings motivate extending moral evaluations with controlled, direction-flipped context manipulations to better characterize model behavior.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
Steering CLIP's vision transformer with sparse autoencoders
Apr 11, 2025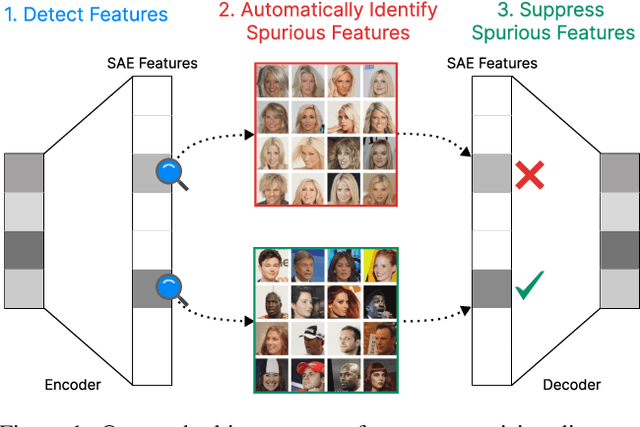
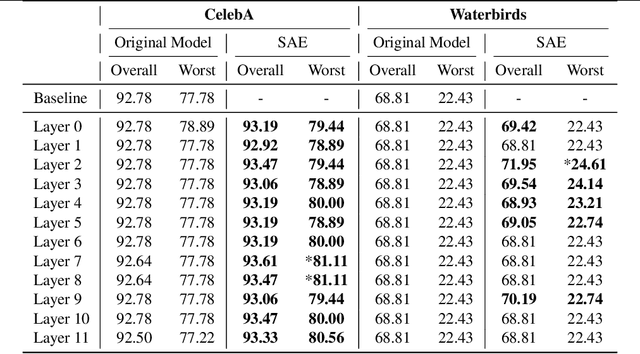

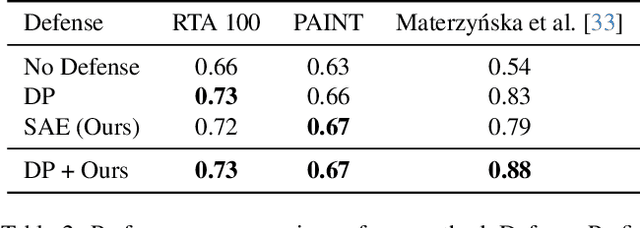
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.