 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAt the Edge of Understanding: Sparse Autoencoders Trace The Limits of Transformer Generalization
Jun 24, 2026Pre-trained transformers have demonstrated remarkable generalization abilities, at times extending beyond the scope of their training data. Yet, real-world deployments often face unexpected or adversarial data that diverges from training data distributions. Without explicit mechanisms for handling such shifts, model reliability and safety degrade, urging more disciplined study of out-of-distribution (OOD) settings for transformers. By systematic experiments, we present a mechanistic framework for delineating the precise contours of transformer model robustness. We find that OOD inputs, including subtle typos and jailbreak prompts, drive language models to operate on an increased number of fallacious concepts in their internals. We leverage this device to quantify and understand the degree of distributional shift in prompts, enabling a mechanistically grounded fine-tuning strategy to robustify LLMs. Expanding the very notion of OOD from input data to a model's private computational processes, a new transformer diagnostic at inference time is a critical step toward making AI systems safe for deployment across science, business, and government.
Quantifying LLM Attention-Head Stability: Implications for Circuit Universality
Feb 17, 2026In mechanistic interpretability, recent work scrutinizes transformer "circuits" - sparse, mono or multi layer sub computations, that may reflect human understandable functions. Yet, these network circuits are rarely acid-tested for their stability across different instances of the same deep learning architecture. Without this, it remains unclear whether reported circuits emerge universally across labs or turn out to be idiosyncratic to a particular estimation instance, potentially limiting confidence in safety-critical settings. Here, we systematically study stability across-refits in increasingly complex transformer language models of various sizes. We quantify, layer by layer, how similarly attention heads learn representations across independently initialized training runs. Our rigorous experiments show that (1) middle-layer heads are the least stable yet the most representationally distinct; (2) deeper models exhibit stronger mid-depth divergence; (3) unstable heads in deeper layers become more functionally important than their peers from the same layer; (4) applying weight decay optimization substantially improves attention-head stability across random model initializations; and (5) the residual stream is comparatively stable. Our findings establish the cross-instance robustness of circuits as an essential yet underappreciated prerequisite for scalable oversight, drawing contours around possible white-box monitorability of AI systems.
From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers
Sep 08, 2025As generative AI systems become competent and democratized in science, business, and government, deeper insight into their failure modes now poses an acute need. The occasional volatility in their behavior, such as the propensity of transformer models to hallucinate, impedes trust and adoption of emerging AI solutions in high-stakes areas. In the present work, we establish how and when hallucinations arise in pre-trained transformer models through concept representations captured by sparse autoencoders, under scenarios with experimentally controlled uncertainty in the input space. Our systematic experiments reveal that the number of semantic concepts used by the transformer model grows as the input information becomes increasingly unstructured. In the face of growing uncertainty in the input space, the transformer model becomes prone to activate coherent yet input-insensitive semantic features, leading to hallucinated output. At its extreme, for pure-noise inputs, we identify a wide variety of robustly triggered and meaningful concepts in the intermediate activations of pre-trained transformer models, whose functional integrity we confirm through targeted steering. We also show that hallucinations in the output of a transformer model can be reliably predicted from the concept patterns embedded in transformer layer activations. This collection of insights on transformer internal processing mechanics has immediate consequences for aligning AI models with human values, AI safety, opening the attack surface for potential adversarial attacks, and providing a basis for automatic quantification of a model's hallucination risk.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
Steering CLIP's vision transformer with sparse autoencoders
Apr 11, 2025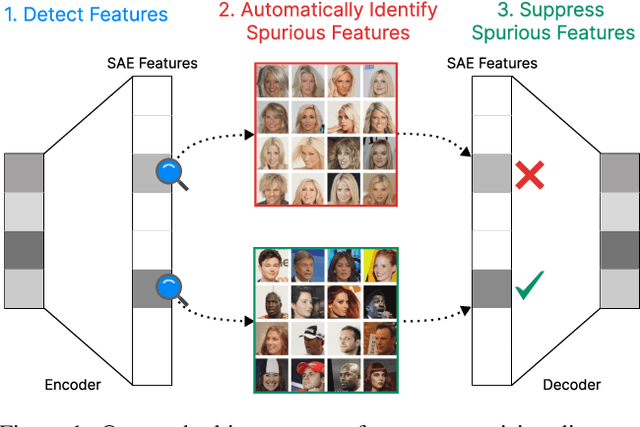
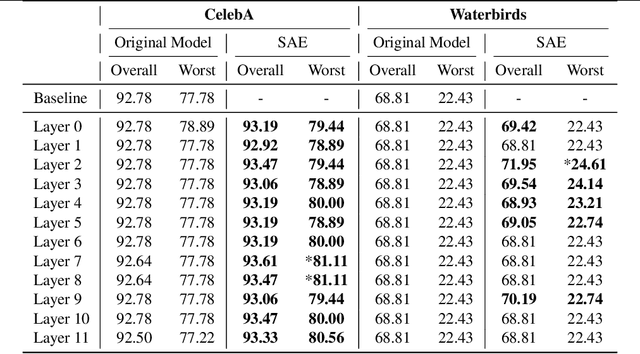

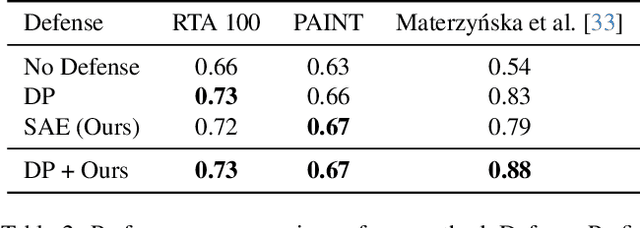
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.