 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraQA: Question Answering under Contradicting Contexts
Nov 04, 2021
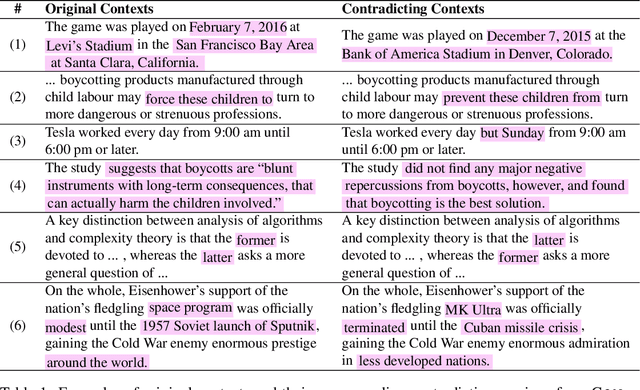

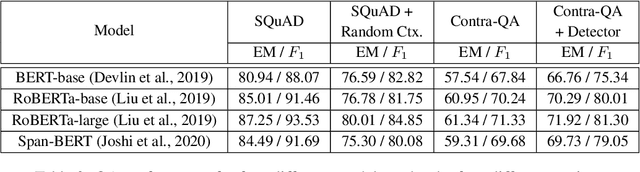
With a rise in false, inaccurate, and misleading information in propaganda, news, and social media, real-world Question Answering (QA) systems face the challenges of synthesizing and reasoning over contradicting information to derive correct answers. This urgency gives rise to the need to make QA systems robust to misinformation, a topic previously unexplored. We study the risk of misinformation to QA models by investigating the behavior of the QA model under contradicting contexts that are mixed with both real and fake information. We create the first large-scale dataset for this problem, namely Contra-QA, which contains over 10K human-written and model-generated contradicting pairs of contexts. Experiments show that QA models are vulnerable under contradicting contexts brought by misinformation. To defend against such a threat, we build a misinformation-aware QA system as a counter-measure that integrates question answering and misinformation detection in a joint fashion.
Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction
Oct 27, 2021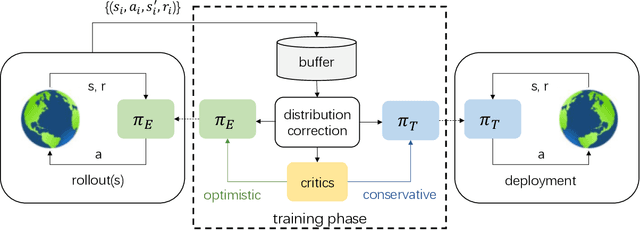
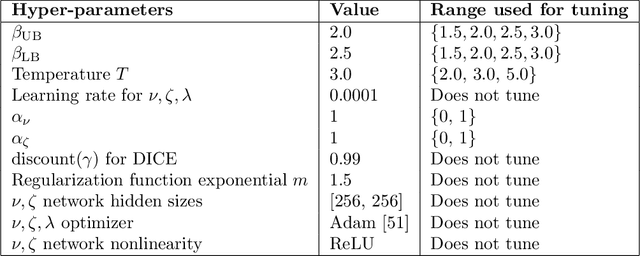

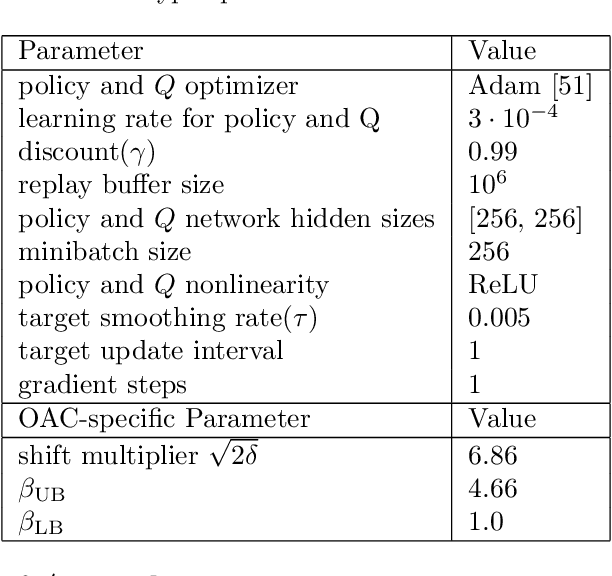
Improving sample efficiency of reinforcement learning algorithms requires effective exploration. Following the principle of $\textit{optimism in the face of uncertainty}$, we train a separate exploration policy to maximize an approximate upper confidence bound of the critics in an off-policy actor-critic framework. However, this introduces extra differences between the replay buffer and the target policy in terms of their stationary state-action distributions. To mitigate the off-policy-ness, we adapt the recently introduced DICE framework to learn a distribution correction ratio for off-policy actor-critic training. In particular, we correct the training distribution for both policies and critics. Empirically, we evaluate our proposed method in several challenging continuous control tasks and show superior performance compared to state-of-the-art methods. We also conduct extensive ablation studies to demonstrate the effectiveness and the rationality of the proposed method.
MIC: Model-agnostic Integrated Cross-channel Recommenders
Oct 22, 2021
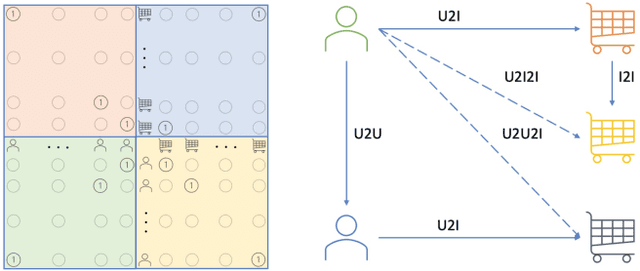
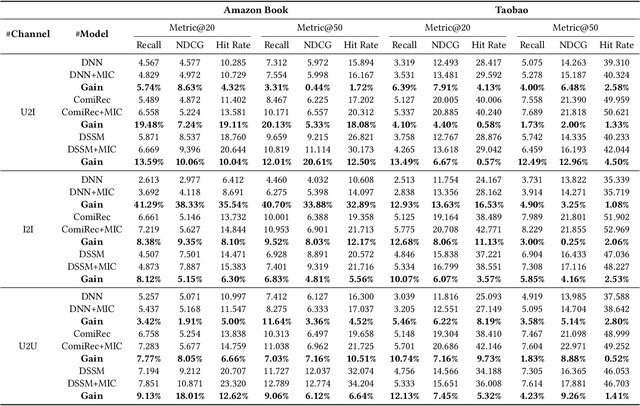
Semantically connecting users and items is a fundamental problem for the matching stage of an industrial recommender system. Recent advances in this topic are based on multi-channel retrieval to efficiently measure users' interest on items from the massive candidate pool. However, existing work are primarily built upon pre-defined retrieval channels, including User-CF (U2U), Item-CF (I2I), and Embedding-based Retrieval (U2I), thus access to the limited correlation between users and items which solely entail from partial information of latent interactions. In this paper, we propose a model-agnostic integrated cross-channel (MIC) approach for the large-scale recommendation, which maximally leverages the inherent multi-channel mutual information to enhance the matching performance. Specifically, MIC robustly models correlation within user-item, user-user, and item-item from latent interactions in a universal schema. For each channel, MIC naturally aligns pairs with semantic similarity and distinguishes them otherwise with more uniform anisotropic representation space. While state-of-the-art methods require specific architectural design, MIC intuitively considers them as a whole by enabling the complete information flow among users and items. Thus MIC can be easily plugged into other retrieval recommender systems. Extensive experiments show that our MIC helps several state-of-the-art models boost their performance on two real-world benchmarks. The satisfactory deployment of the proposed MIC on industrial online services empirically proves its scalability and flexibility.
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains
Oct 13, 2021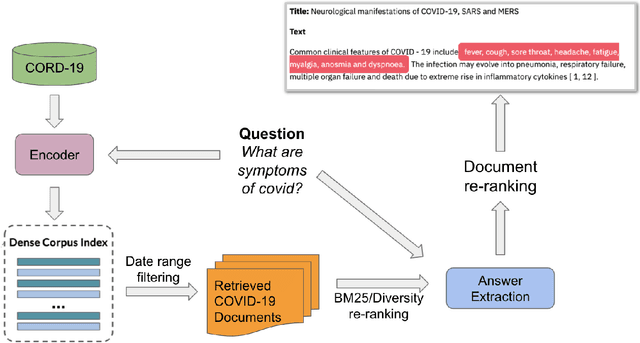
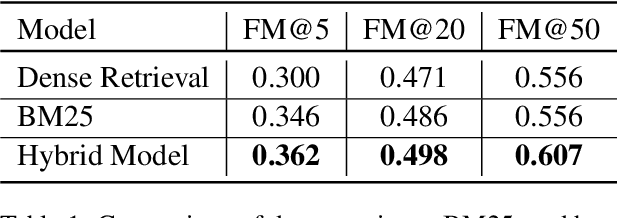
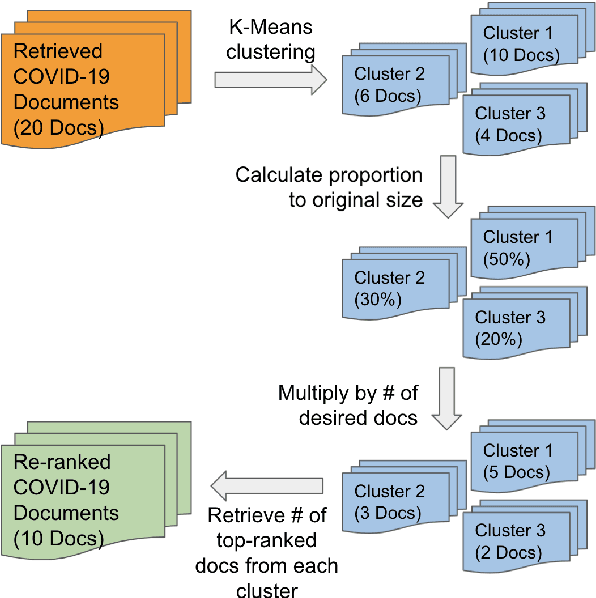
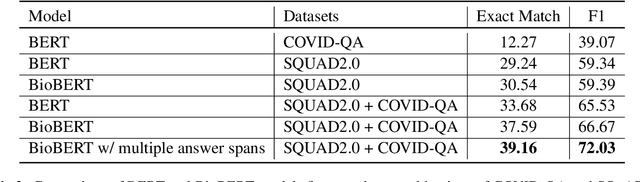
Since late 2019, COVID-19 has quickly emerged as the newest biomedical domain, resulting in a surge of new information. As with other emergent domains, the discussion surrounding the topic has been rapidly changing, leading to the spread of misinformation. This has created the need for a public space for users to ask questions and receive credible, scientific answers. To fulfill this need, we turn to the task of open-domain question-answering, which we can use to efficiently find answers to free-text questions from a large set of documents. In this work, we present such a system for the emergent domain of COVID-19. Despite the small data size available, we are able to successfully train the system to retrieve answers from a large-scale corpus of published COVID-19 scientific papers. Furthermore, we incorporate effective re-ranking and question-answering techniques, such as document diversity and multiple answer spans. Our open-domain question-answering system can further act as a model for the quick development of similar systems that can be adapted and modified for other developing emergent domains.
Self-Supervised Knowledge Assimilation for Expert-Layman Text Style Transfer
Oct 06, 2021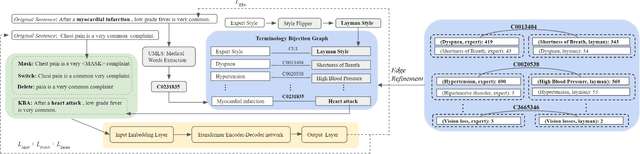
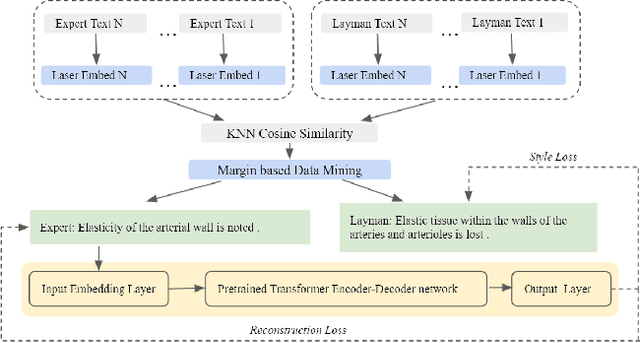
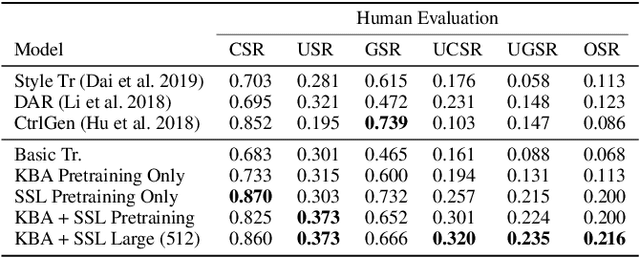
Expert-layman text style transfer technologies have the potential to improve communication between members of scientific communities and the general public. High-quality information produced by experts is often filled with difficult jargon laypeople struggle to understand. This is a particularly notable issue in the medical domain, where layman are often confused by medical text online. At present, two bottlenecks interfere with the goal of building high-quality medical expert-layman style transfer systems: a dearth of pretrained medical-domain language models spanning both expert and layman terminologies and a lack of parallel corpora for training the transfer task itself. To mitigate the first issue, we propose a novel language model (LM) pretraining task, Knowledge Base Assimilation, to synthesize pretraining data from the edges of a graph of expert- and layman-style medical terminology terms into an LM during self-supervised learning. To mitigate the second issue, we build a large-scale parallel corpus in the medical expert-layman domain using a margin-based criterion. Our experiments show that transformer-based models pretrained on knowledge base assimilation and other well-established pretraining tasks fine-tuning on our new parallel corpus leads to considerable improvement against expert-layman transfer benchmarks, gaining an average relative improvement of our human evaluation, the Overall Success Rate (OSR), by 106%.
A Massively Multilingual Analysis of Cross-linguality in Shared Embedding Space
Sep 13, 2021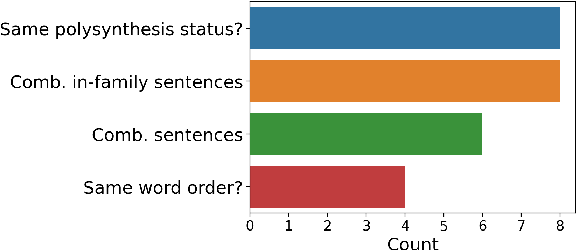
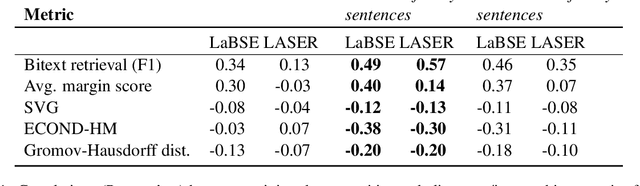
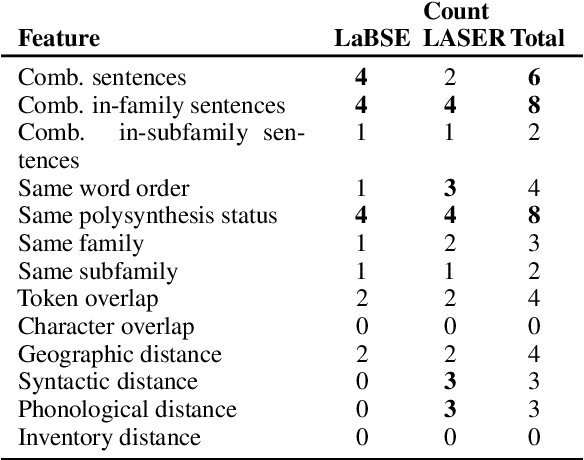
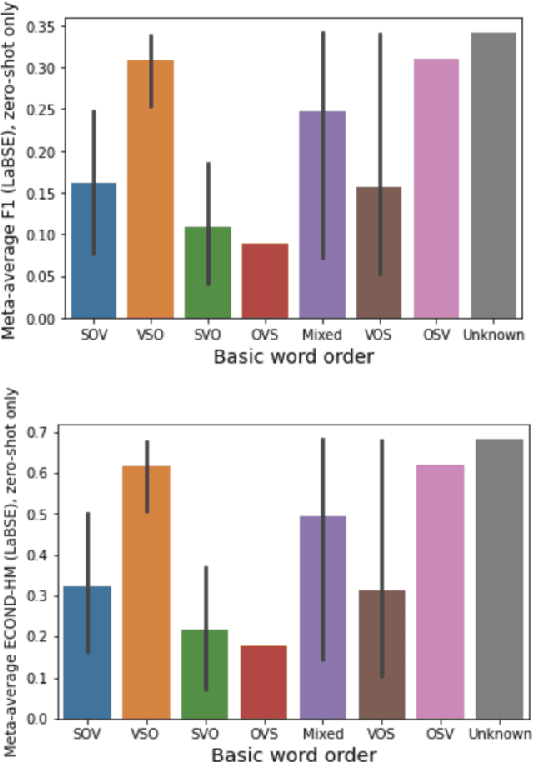
In cross-lingual language models, representations for many different languages live in the same space. Here, we investigate the linguistic and non-linguistic factors affecting sentence-level alignment in cross-lingual pretrained language models for 101 languages and 5,050 language pairs. Using BERT-based LaBSE and BiLSTM-based LASER as our models, and the Bible as our corpus, we compute a task-based measure of cross-lingual alignment in the form of bitext retrieval performance, as well as four intrinsic measures of vector space alignment and isomorphism. We then examine a range of linguistic, quasi-linguistic, and training-related features as potential predictors of these alignment metrics. The results of our analyses show that word order agreement and agreement in morphological complexity are two of the strongest linguistic predictors of cross-linguality. We also note in-family training data as a stronger predictor than language-specific training data across the board. We verify some of our linguistic findings by looking at the effect of morphological segmentation on English-Inuktitut alignment, in addition to examining the effect of word order agreement on isomorphism for 66 zero-shot language pairs from a different corpus. We make the data and code for our experiments publicly available.
D-REX: Dialogue Relation Extraction with Explanations
Sep 10, 2021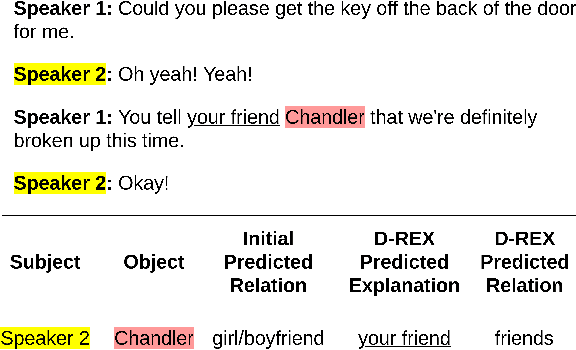

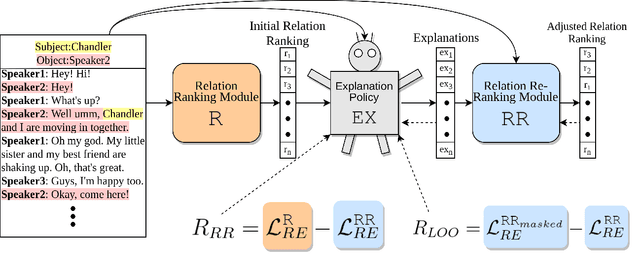
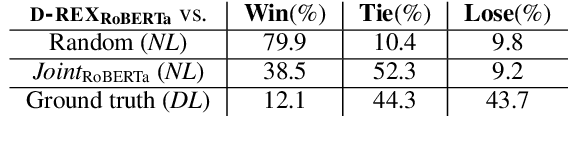
Existing research studies on cross-sentence relation extraction in long-form multi-party conversations aim to improve relation extraction without considering the explainability of such methods. This work addresses that gap by focusing on extracting explanations that indicate that a relation exists while using only partially labeled data. We propose our model-agnostic framework, D-REX, a policy-guided semi-supervised algorithm that explains and ranks relations. We frame relation extraction as a re-ranking task and include relation- and entity-specific explanations as an intermediate step of the inference process. We find that about 90% of the time, human annotators prefer D-REX's explanations over a strong BERT-based joint relation extraction and explanation model. Finally, our evaluations on a dialogue relation extraction dataset show that our method is simple yet effective and achieves a state-of-the-art F1 score on relation extraction, improving upon existing methods by 13.5%.
FinQA: A Dataset of Numerical Reasoning over Financial Data
Sep 07, 2021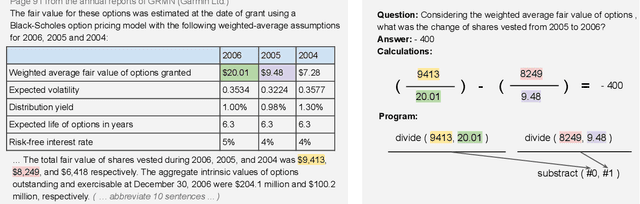

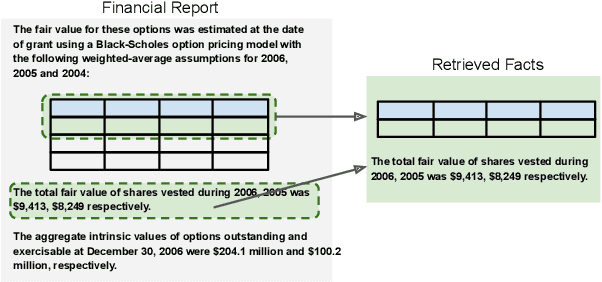
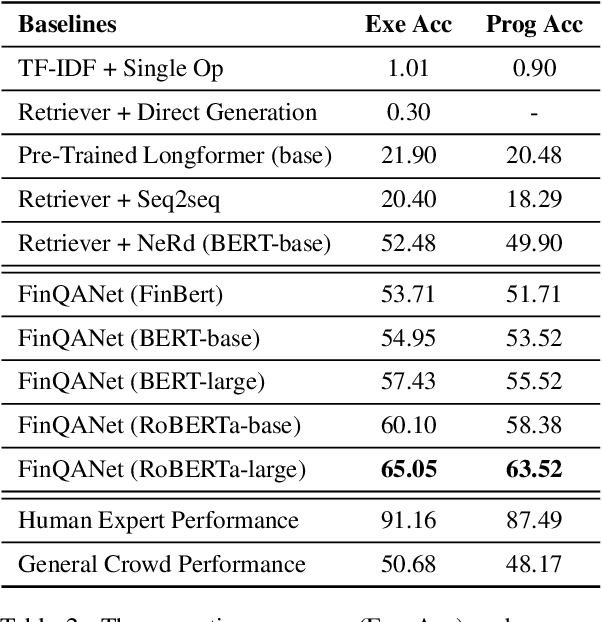
The sheer volume of financial statements makes it difficult for humans to access and analyze a business's financials. Robust numerical reasoning likewise faces unique challenges in this domain. In this work, we focus on answering deep questions over financial data, aiming to automate the analysis of a large corpus of financial documents. In contrast to existing tasks on general domain, the finance domain includes complex numerical reasoning and understanding of heterogeneous representations. To facilitate analytical progress, we propose a new large-scale dataset, FinQA, with Question-Answering pairs over Financial reports, written by financial experts. We also annotate the gold reasoning programs to ensure full explainability. We further introduce baselines and conduct comprehensive experiments in our dataset. The results demonstrate that popular, large, pre-trained models fall far short of expert humans in acquiring finance knowledge and in complex multi-step numerical reasoning on that knowledge. Our dataset -- the first of its kind -- should therefore enable significant, new community research into complex application domains. The dataset and code are publicly available\url{https://github.com/czyssrs/FinQA}.
A Dataset for Answering Time-Sensitive Questions
Sep 03, 2021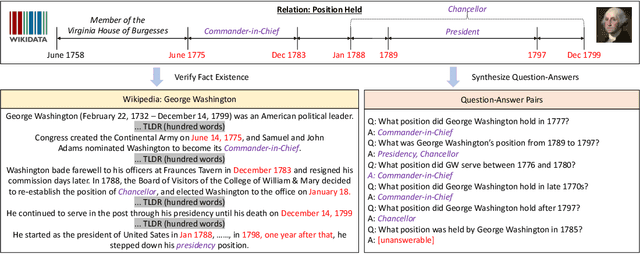
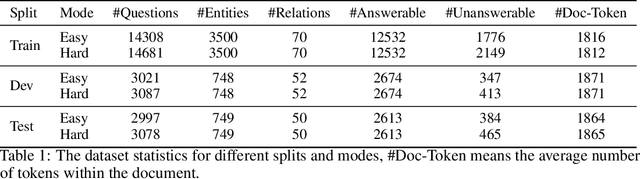
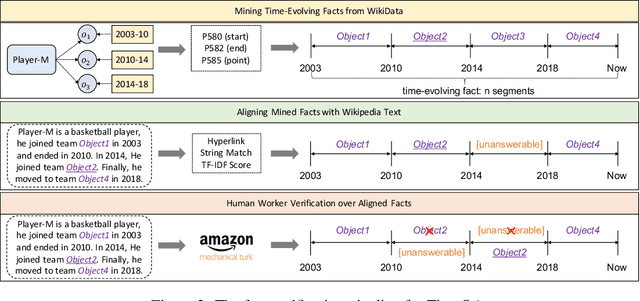
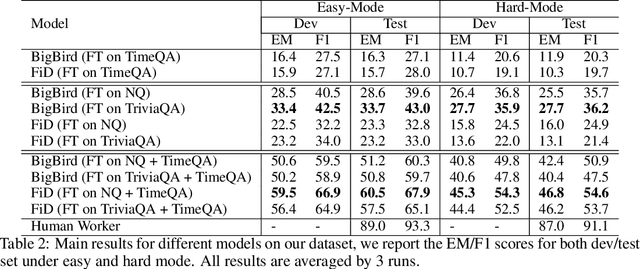
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses challenges in the aspect of both temporal understanding and temporal reasoning. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform consistent temporal reasoning. Therefore, we believe that our dataset could serve as a benchmark to develop NLP models more sensitive to temporal shift. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Local Explanation of Dialogue Response Generation
Jun 11, 2021
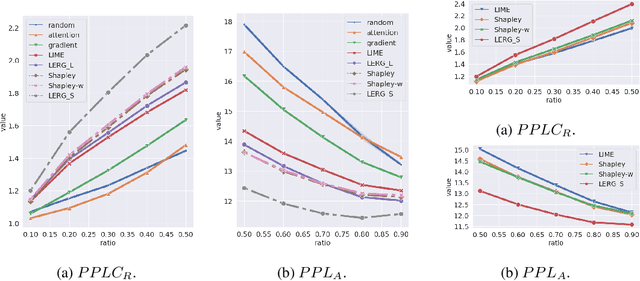
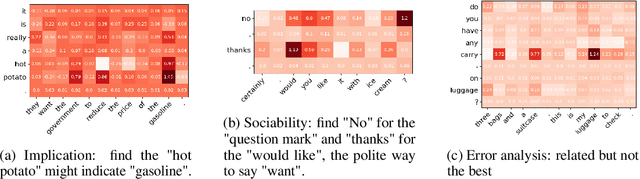

In comparison to the interpretation of classification models, the explanation of sequence generation models is also an important problem, however it has seen little attention. In this work, we study model-agnostic explanations of a representative text generation task -- dialogue response generation. Dialog response generation is challenging with its open-ended sentences and multiple acceptable responses. To gain insights into the reasoning process of a generation model, we propose anew method, local explanation of response generation (LERG) that regards the explanations as the mutual interaction of segments in input and output sentences. LERG views the sequence prediction as uncertainty estimation of a human response and then creates explanations by perturbing the input and calculating the certainty change over the human response. We show that LERG adheres to desired properties of explanations for text generation including unbiased approximation, consistency and cause identification. Empirically, our results show that our method consistently improves other widely used methods on proposed automatic- and human- evaluation metrics for this new task by 4.4-12.8%. Our analysis demonstrates that LERG can extract both explicit and implicit relations between input and output segments.