 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralised Policy Improvement with Geometric Policy Composition
Jun 17, 2022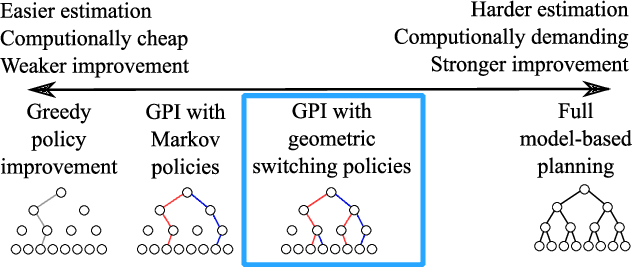

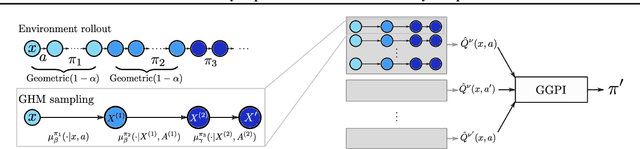
We introduce a method for policy improvement that interpolates between the greedy approach of value-based reinforcement learning (RL) and the full planning approach typical of model-based RL. The new method builds on the concept of a geometric horizon model (GHM, also known as a gamma-model), which models the discounted state-visitation distribution of a given policy. We show that we can evaluate any non-Markov policy that switches between a set of base Markov policies with fixed probability by a careful composition of the base policy GHMs, without any additional learning. We can then apply generalised policy improvement (GPI) to collections of such non-Markov policies to obtain a new Markov policy that will in general outperform its precursors. We provide a thorough theoretical analysis of this approach, develop applications to transfer and standard RL, and empirically demonstrate its effectiveness over standard GPI on a challenging deep RL continuous control task. We also provide an analysis of GHM training methods, proving a novel convergence result regarding previously proposed methods and showing how to train these models stably in deep RL settings.
Learning Dynamics and Generalization in Reinforcement Learning
Jun 05, 2022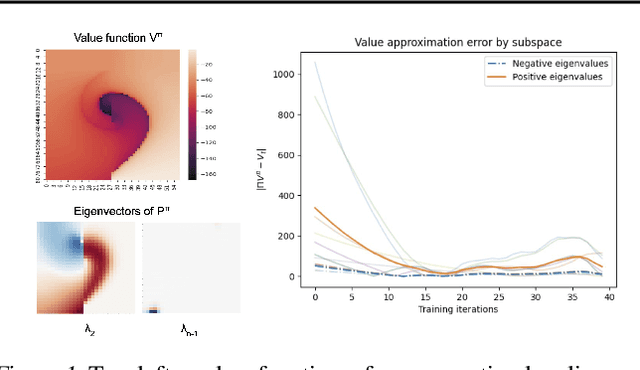
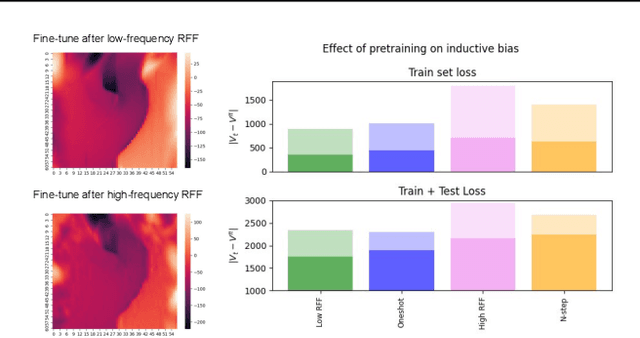
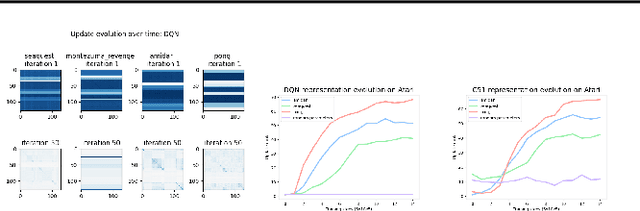
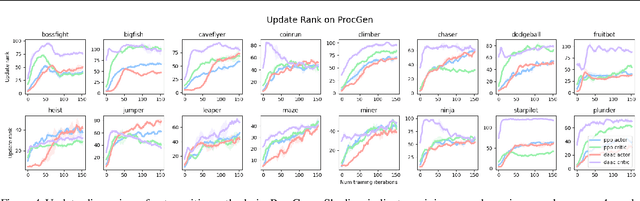
Solving a reinforcement learning (RL) problem poses two competing challenges: fitting a potentially discontinuous value function, and generalizing well to new observations. In this paper, we analyze the learning dynamics of temporal difference algorithms to gain novel insight into the tension between these two objectives. We show theoretically that temporal difference learning encourages agents to fit non-smooth components of the value function early in training, and at the same time induces the second-order effect of discouraging generalization. We corroborate these findings in deep RL agents trained on a range of environments, finding that neural networks trained using temporal difference algorithms on dense reward tasks exhibit weaker generalization between states than randomly initialized networks and networks trained with policy gradient methods. Finally, we investigate how post-training policy distillation may avoid this pitfall, and show that this approach improves generalization to novel environments in the ProcGen suite and improves robustness to input perturbations.
Understanding and Preventing Capacity Loss in Reinforcement Learning
Apr 20, 2022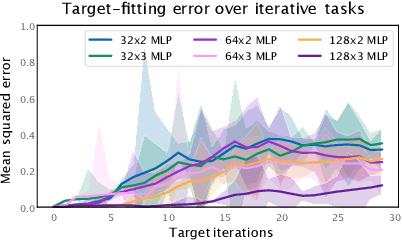
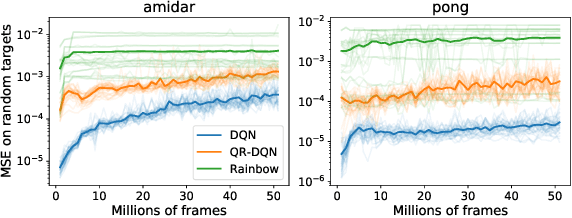

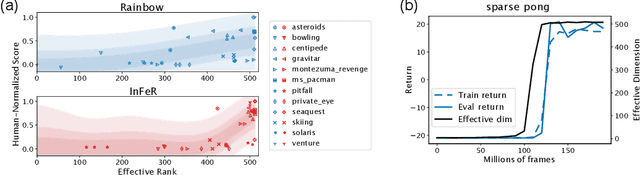
The reinforcement learning (RL) problem is rife with sources of non-stationarity, making it a notoriously difficult problem domain for the application of neural networks. We identify a mechanism by which non-stationary prediction targets can prevent learning progress in deep RL agents: \textit{capacity loss}, whereby networks trained on a sequence of target values lose their ability to quickly update their predictions over time. We demonstrate that capacity loss occurs in a range of RL agents and environments, and is particularly damaging to performance in sparse-reward tasks. We then present a simple regularizer, Initial Feature Regularization (InFeR), that mitigates this phenomenon by regressing a subspace of features towards its value at initialization, leading to significant performance improvements in sparse-reward environments such as Montezuma's Revenge. We conclude that preventing capacity loss is crucial to enable agents to maximally benefit from the learning signals they obtain throughout the entire training trajectory.
On the Expressivity of Markov Reward
Nov 01, 2021


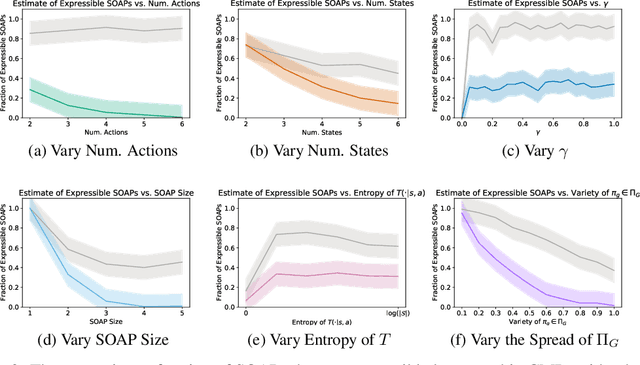
Reward is the driving force for reinforcement-learning agents. This paper is dedicated to understanding the expressivity of reward as a way to capture tasks that we would want an agent to perform. We frame this study around three new abstract notions of "task" that might be desirable: (1) a set of acceptable behaviors, (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Our main results prove that while reward can express many of these tasks, there exist instances of each task type that no Markov reward function can capture. We then provide a set of polynomial-time algorithms that construct a Markov reward function that allows an agent to optimize tasks of each of these three types, and correctly determine when no such reward function exists. We conclude with an empirical study that corroborates and illustrates our theoretical findings.
The Difficulty of Passive Learning in Deep Reinforcement Learning
Oct 26, 2021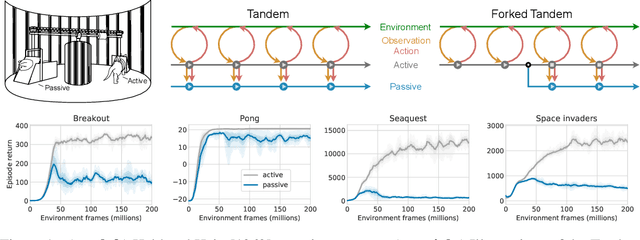

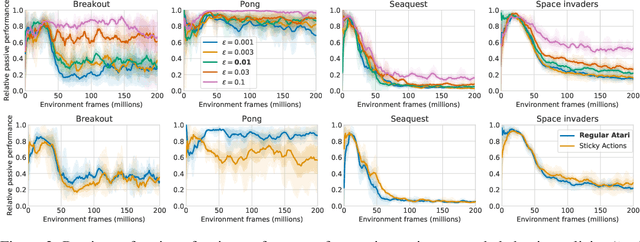

Learning to act from observational data without active environmental interaction is a well-known challenge in Reinforcement Learning (RL). Recent approaches involve constraints on the learned policy or conservative updates, preventing strong deviations from the state-action distribution of the dataset. Although these methods are evaluated using non-linear function approximation, theoretical justifications are mostly limited to the tabular or linear cases. Given the impressive results of deep reinforcement learning, we argue for a need to more clearly understand the challenges in this setting. In the vein of Held & Hein's classic 1963 experiment, we propose the "tandem learning" experimental paradigm which facilitates our empirical analysis of the difficulties in offline reinforcement learning. We identify function approximation in conjunction with fixed data distributions as the strongest factors, thereby extending but also challenging hypotheses stated in past work. Our results provide relevant insights for offline deep reinforcement learning, while also shedding new light on phenomena observed in the online case of learning control.
Revisiting Peng's Q for Modern Reinforcement Learning
Feb 27, 2021
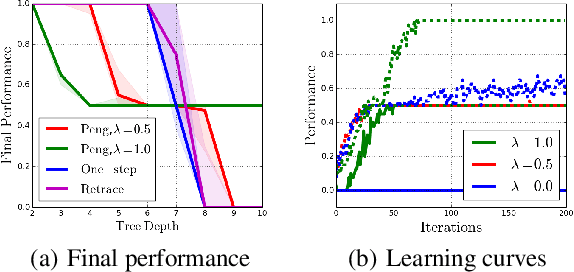

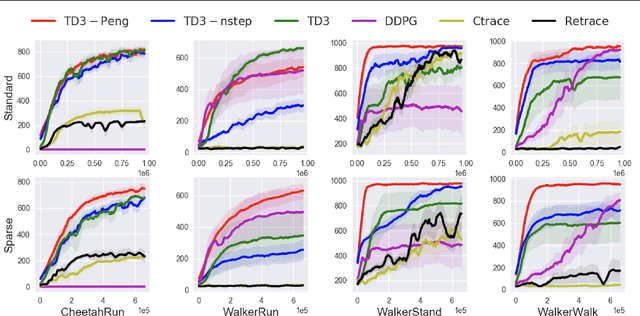
Off-policy multi-step reinforcement learning algorithms consist of conservative and non-conservative algorithms: the former actively cut traces, whereas the latter do not. Recently, Munos et al. (2016) proved the convergence of conservative algorithms to an optimal Q-function. In contrast, non-conservative algorithms are thought to be unsafe and have a limited or no theoretical guarantee. Nonetheless, recent studies have shown that non-conservative algorithms empirically outperform conservative ones. Motivated by the empirical results and the lack of theory, we carry out theoretical analyses of Peng's Q($\lambda$), a representative example of non-conservative algorithms. We prove that it also converges to an optimal policy provided that the behavior policy slowly tracks a greedy policy in a way similar to conservative policy iteration. Such a result has been conjectured to be true but has not been proven. We also experiment with Peng's Q($\lambda$) in complex continuous control tasks, confirming that Peng's Q($\lambda$) often outperforms conservative algorithms despite its simplicity. These results indicate that Peng's Q($\lambda$), which was thought to be unsafe, is a theoretically-sound and practically effective algorithm.
On The Effect of Auxiliary Tasks on Representation Dynamics
Feb 25, 2021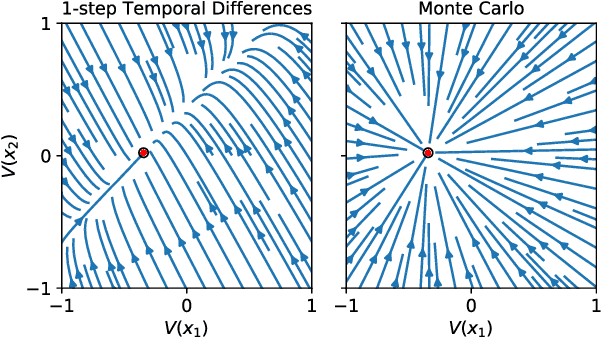

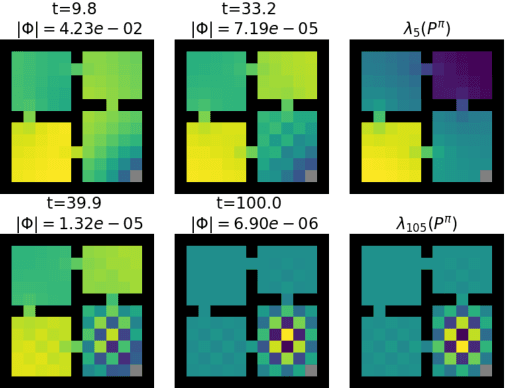

While auxiliary tasks play a key role in shaping the representations learnt by reinforcement learning agents, much is still unknown about the mechanisms through which this is achieved. This work develops our understanding of the relationship between auxiliary tasks, environment structure, and representations by analysing the dynamics of temporal difference algorithms. Through this approach, we establish a connection between the spectral decomposition of the transition operator and the representations induced by a variety of auxiliary tasks. We then leverage insights from these theoretical results to inform the selection of auxiliary tasks for deep reinforcement learning agents in sparse-reward environments.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020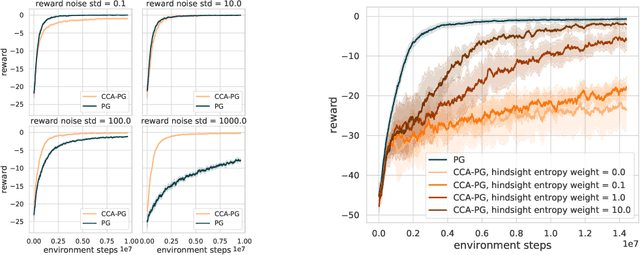
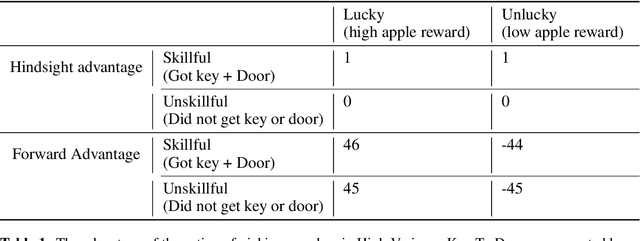

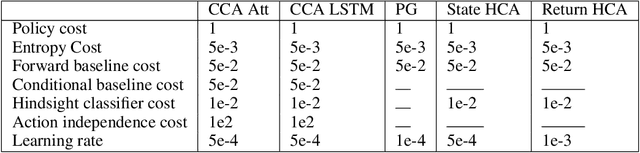
Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
Revisiting Fundamentals of Experience Replay
Jul 13, 2020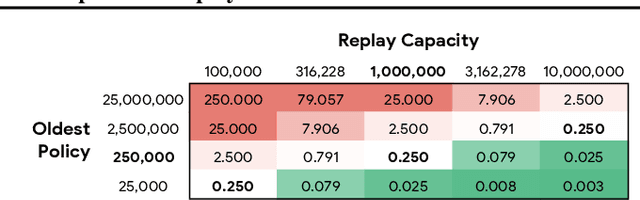

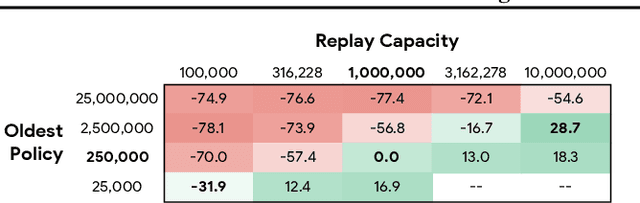
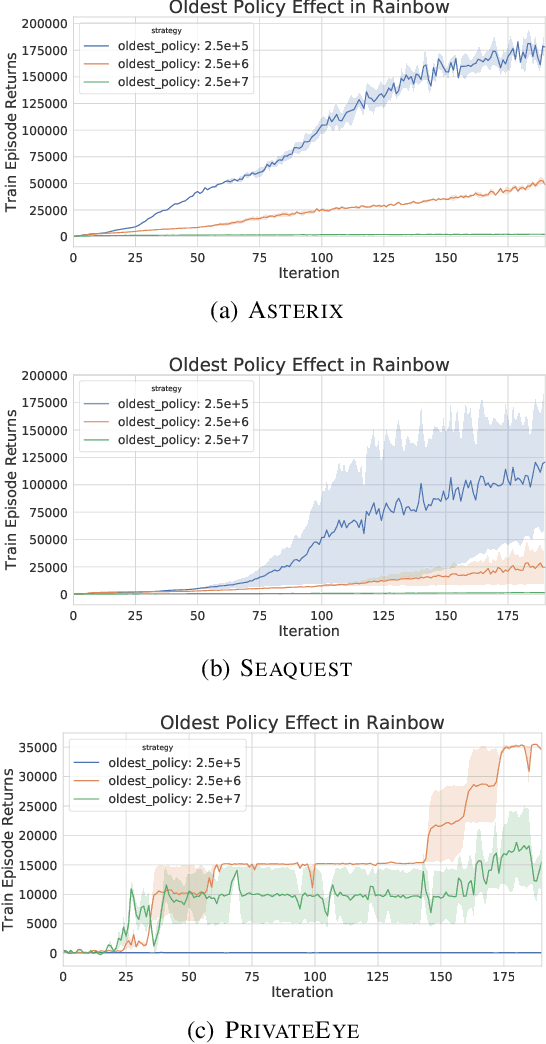
Experience replay is central to off-policy algorithms in deep reinforcement learning (RL), but there remain significant gaps in our understanding. We therefore present a systematic and extensive analysis of experience replay in Q-learning methods, focusing on two fundamental properties: the replay capacity and the ratio of learning updates to experience collected (replay ratio). Our additive and ablative studies upend conventional wisdom around experience replay -- greater capacity is found to substantially increase the performance of certain algorithms, while leaving others unaffected. Counterintuitively we show that theoretically ungrounded, uncorrected n-step returns are uniquely beneficial while other techniques confer limited benefit for sifting through larger memory. Separately, by directly controlling the replay ratio we contextualize previous observations in the literature and empirically measure its importance across a variety of deep RL algorithms. Finally, we conclude by testing a set of hypotheses on the nature of these performance benefits.
Deep Reinforcement Learning and its Neuroscientific Implications
Jul 07, 2020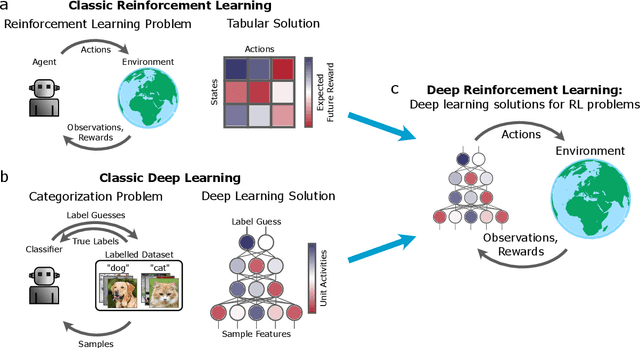
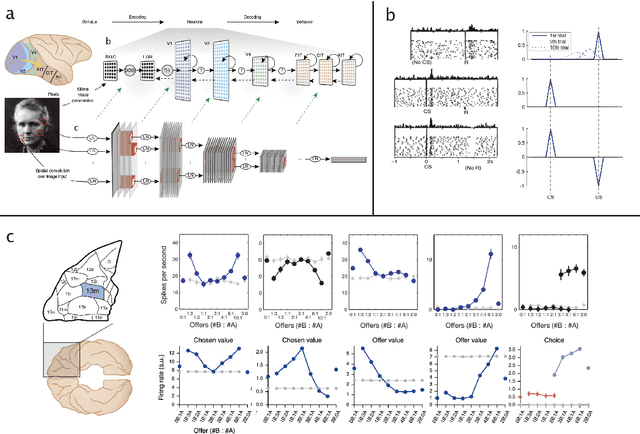
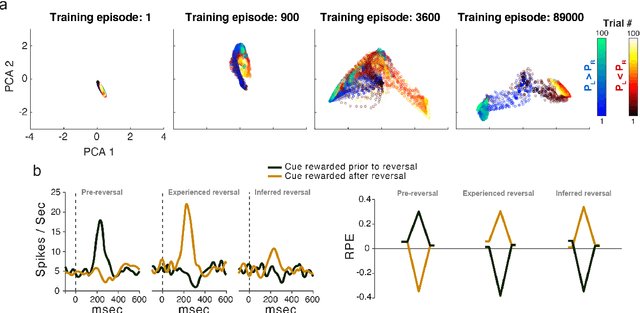
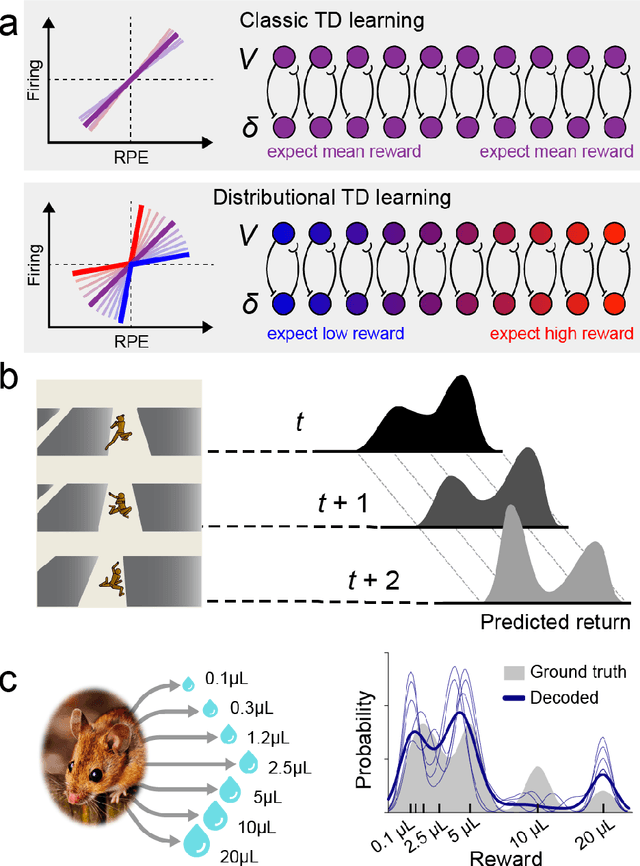
The emergence of powerful artificial intelligence is defining new research directions in neuroscience. To date, this research has focused largely on deep neural networks trained using supervised learning, in tasks such as image classification. However, there is another area of recent AI work which has so far received less attention from neuroscientists, but which may have profound neuroscientific implications: deep reinforcement learning. Deep RL offers a comprehensive framework for studying the interplay among learning, representation and decision-making, offering to the brain sciences a new set of research tools and a wide range of novel hypotheses. In the present review, we provide a high-level introduction to deep RL, discuss some of its initial applications to neuroscience, and survey its wider implications for research on brain and behavior, concluding with a list of opportunities for next-stage research.