 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllowing Safe Contact in Robotic Goal-Reaching: Planning and Tracking in Operational and Null Spaces
Oct 31, 2022



In recent years, impressive results have been achieved in robotic manipulation. While many efforts focus on generating collision-free reference signals, few allow safe contact between the robot bodies and the environment. However, in human's daily manipulation, contact between arms and obstacles is prevalent and even necessary. This paper investigates the benefit of allowing safe contact during robotic manipulation and advocates generating and tracking compliance reference signals in both operational and null spaces. In addition, to optimize the collision-allowed trajectories, we present a hybrid solver that integrates sampling- and gradient-based approaches. We evaluate the proposed method on a goal-reaching task in five simulated and real-world environments with different collisional conditions. We show that allowing safe contact improves goal-reaching efficiency and provides feasible solutions in highly collisional scenarios where collision-free constraints cannot be enforced. Moreover, we demonstrate that planning in null space, in addition to operational space, improves trajectory safety.
Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning
Oct 01, 2022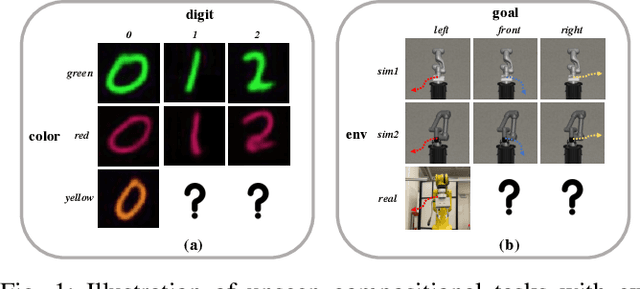
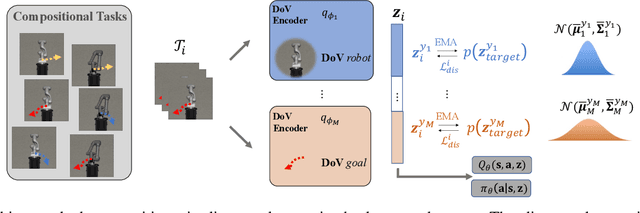
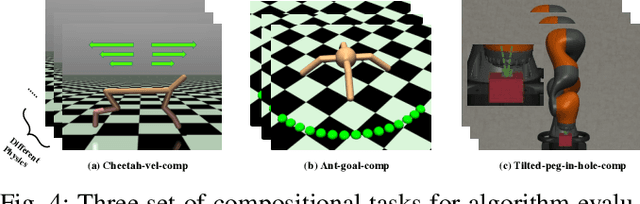
Humans are capable of abstracting various tasks as different combinations of multiple attributes. This perspective of compositionality is vital for human rapid learning and adaption since previous experiences from related tasks can be combined to generalize across novel compositional settings. In this work, we aim to achieve zero-shot policy generalization of Reinforcement Learning (RL) agents by leveraging the task compositionality. Our proposed method is a meta- RL algorithm with disentangled task representation, explicitly encoding different aspects of the tasks. Policy generalization is then performed by inferring unseen compositional task representations via the obtained disentanglement without extra exploration. The evaluation is conducted on three simulated tasks and a challenging real-world robotic insertion task. Experimental results demonstrate that our proposed method achieves policy generalization to unseen compositional tasks in a zero-shot manner.
Symbolic State Estimation with Predicates for Contact-Rich Manipulation Tasks
Mar 04, 2022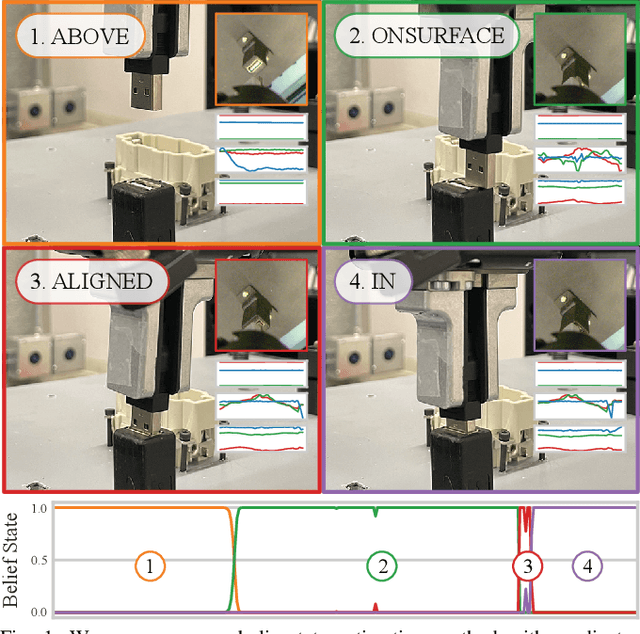

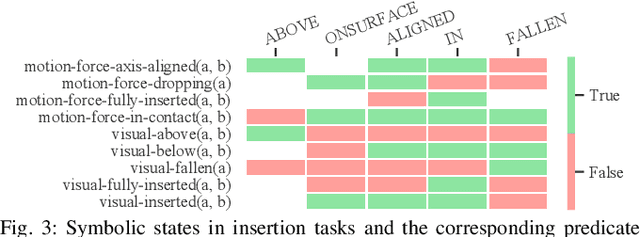
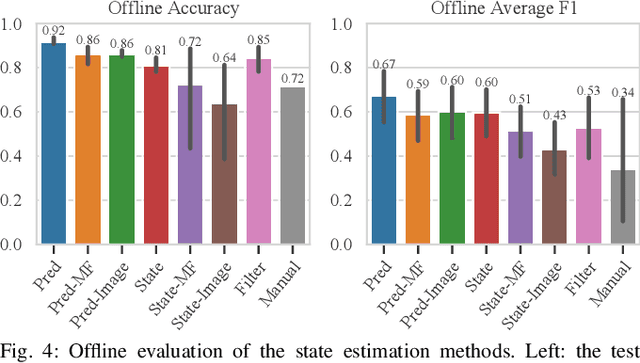
Manipulation tasks often require a robot to adjust its sensorimotor skills based on the state it finds itself in. Taking peg-in-hole as an example: once the peg is aligned with the hole, the robot should push the peg downwards. While high level execution frameworks such as state machines and behavior trees are commonly used to formalize such decision-making problems, these frameworks require a mechanism to detect the high-level symbolic state. Handcrafting heuristics to identify symbolic states can be brittle, and using data-driven methods can produce noisy predictions, particularly when working with limited datasets, as is common in real-world robotic scenarios. This paper proposes a Bayesian state estimation method to predict symbolic states with predicate classifiers. This method requires little training data and allows fusing noisy observations from multiple sensor modalities. We evaluate our framework on a set of real-world peg-in-hole and connector-socket insertion tasks, demonstrating its ability to classify symbolic states and to generalize to unseen tasks, outperforming baseline methods. We also demonstrate the ability of our method to improve the robustness of manipulation policies on a real robot.
You Only Demonstrate Once: Category-Level Manipulation from Single Visual Demonstration
Jan 30, 2022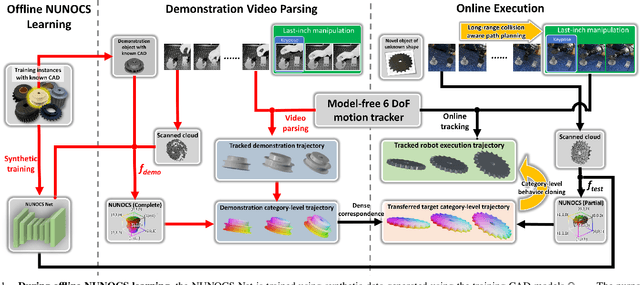
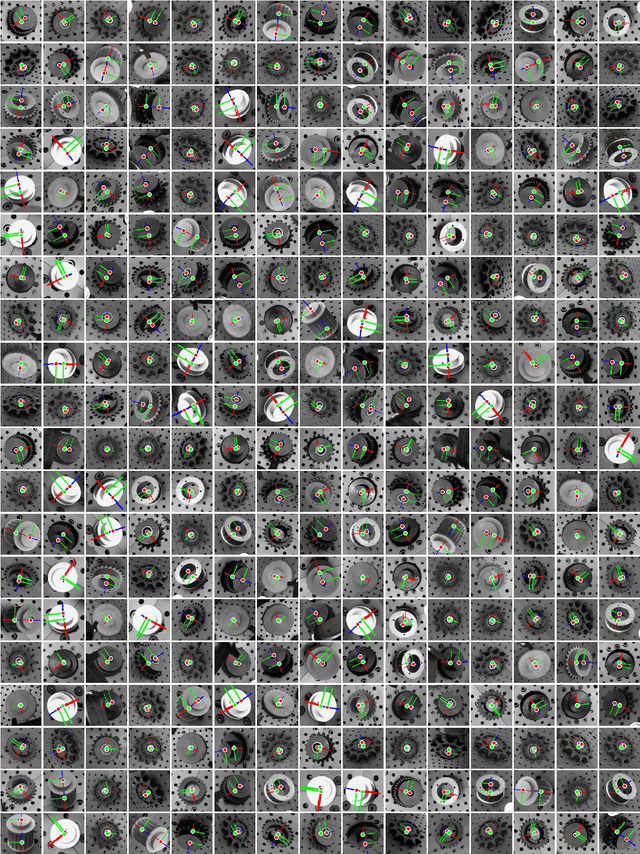


Promising results have been achieved recently in category-level manipulation that generalizes across object instances. Nevertheless, it often requires expensive real-world data collection and manual specification of semantic keypoints for each object category and task. Additionally, coarse keypoint predictions and ignoring intermediate action sequences hinder adoption in complex manipulation tasks beyond pick-and-place. This work proposes a novel, category-level manipulation framework that leverages an object-centric, category-level representation and model-free 6 DoF motion tracking. The canonical object representation is learned solely in simulation and then used to parse a category-level, task trajectory from a single demonstration video. The demonstration is reprojected to a target trajectory tailored to a novel object via the canonical representation. During execution, the manipulation horizon is decomposed into long-range, collision-free motion and last-inch manipulation. For the latter part, a category-level behavior cloning (CatBC) method leverages motion tracking to perform closed-loop control. CatBC follows the target trajectory, projected from the demonstration and anchored to a dynamically selected category-level coordinate frame. The frame is automatically selected along the manipulation horizon by a local attention mechanism. This framework allows to teach different manipulation strategies by solely providing a single demonstration, without complicated manual programming. Extensive experiments demonstrate its efficacy in a range of challenging industrial tasks in high-precision assembly, which involve learning complex, long-horizon policies. The process exhibits robustness against uncertainty due to dynamics as well as generalization across object instances and scene configurations.
CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation
Sep 19, 2021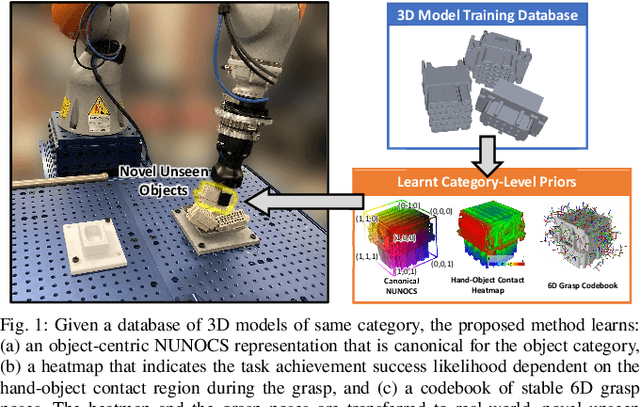
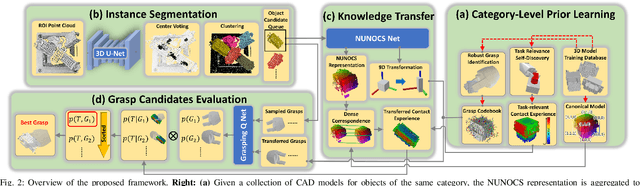
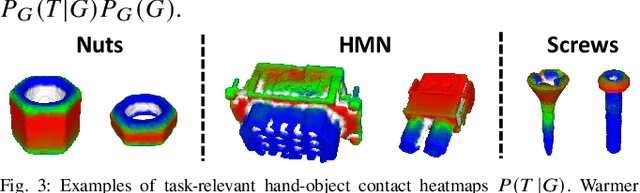
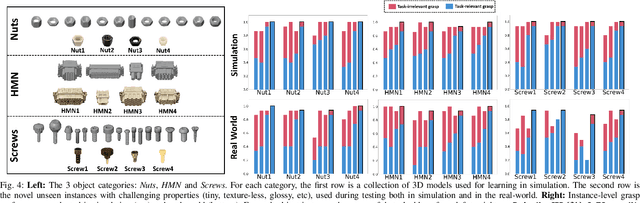
Task-relevant grasping is critical for industrial assembly, where downstream manipulation tasks constrain the set of valid grasps. Learning how to perform this task, however, is challenging, since task-relevant grasp labels are hard to define and annotate. There is also yet no consensus on proper representations for modeling or off-the-shelf tools for performing task-relevant grasps. This work proposes a framework to learn task-relevant grasping for industrial objects without the need of time-consuming real-world data collection or manual annotation. To achieve this, the entire framework is trained solely in simulation, including supervised training with synthetic label generation and self-supervised, hand-object interaction. In the context of this framework, this paper proposes a novel, object-centric canonical representation at the category level, which allows establishing dense correspondence across object instances and transferring task-relevant grasps to novel instances. Extensive experiments on task-relevant grasping of densely-cluttered industrial objects are conducted in both simulation and real-world setups, demonstrating the effectiveness of the proposed framework. Code and data will be released upon acceptance at https://sites.google.com/view/catgrasp.
Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study
Mar 23, 2021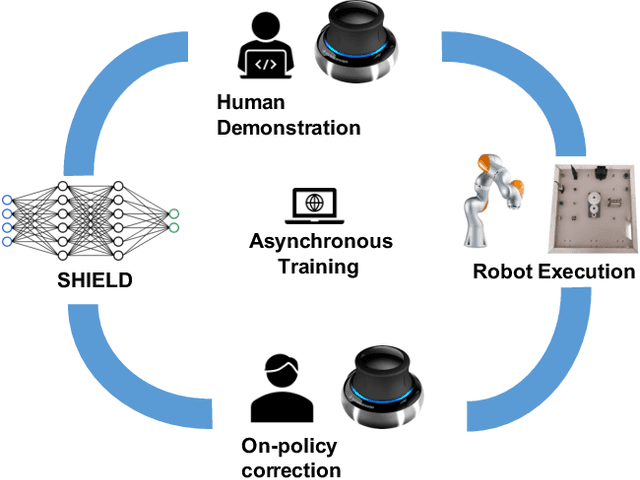


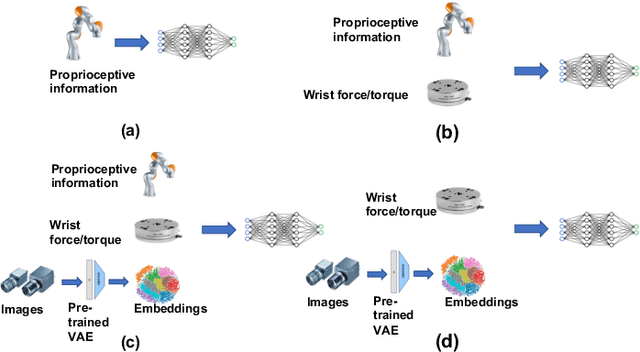
Over the past several years there has been a considerable research investment into learning-based approaches to industrial assembly, but despite significant progress these techniques have yet to be adopted by industry. We argue that it is the prohibitively large design space for Deep Reinforcement Learning (DRL), rather than algorithmic limitations per se, that are truly responsible for this lack of adoption. Pushing these techniques into the industrial mainstream requires an industry-oriented paradigm which differs significantly from the academic mindset. In this paper we define criteria for industry-oriented DRL, and perform a thorough comparison according to these criteria of one family of learning approaches, DRL from demonstration, against a professional industrial integrator on the recently established NIST assembly benchmark. We explain the design choices, representing several years of investigation, which enabled our DRL system to consistently outperform the integrator baseline in terms of both speed and reliability. Finally, we conclude with a competition between our DRL system and a human on a challenge task of insertion into a randomly moving target. This study suggests that DRL is capable of outperforming not only established engineered approaches, but the human motor system as well, and that there remains significant room for improvement. Videos can be found on our project website: https://sites.google.com/view/shield-nist.
Benchmarking Off-The-Shelf Solutions to Robotic Assembly Tasks
Mar 08, 2021

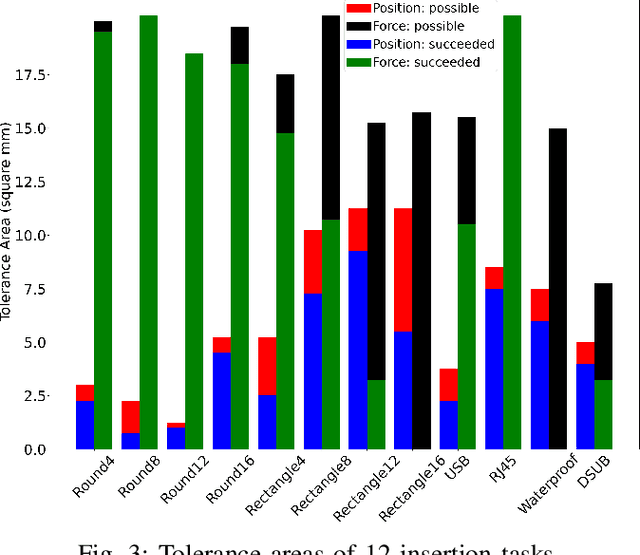

In recent years, many learning based approaches have been studied to realize robotic manipulation and assembly tasks, often including vision and force/tactile feedback. However, it remains frequently unclear what is the baseline state-of-the-art performance and what are the bottleneck problems. In this work, we evaluate some off-the-shelf (OTS) industrial solutions on a recently introduced benchmark, the National Institute of Standards and Technology (NIST) Assembly Task Boards. A set of assembly tasks are introduced and baseline methods are provided to understand their intrinsic difficulty. Multiple sensor-based robotic solutions are then evaluated, including hybrid force/motion control and 2D/3D pattern matching algorithms. An end-to-end integrated solution that accomplishes the tasks is also provided. The results and findings throughout the study reveal a few noticeable factors that impede the adoptions of the OTS solutions: expertise dependent, limited applicability, lack of interoperability, no scene awareness or error recovery mechanisms, and high cost. This paper also provides a first attempt of an objective benchmark performance on the NIST Assembly Task Boards as a reference comparison for future works on this problem.
Interpreting Contact Interactions to Overcome Failure in Robot Assembly Tasks
Jan 07, 2021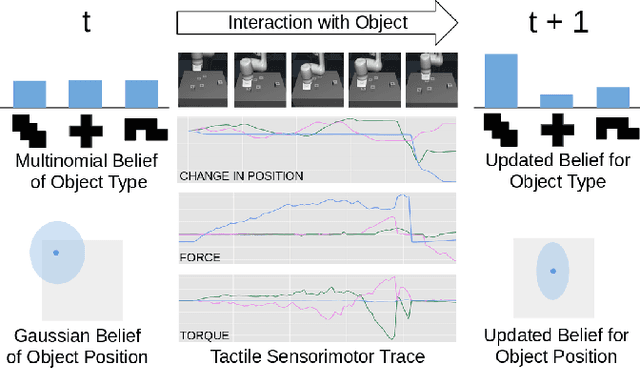
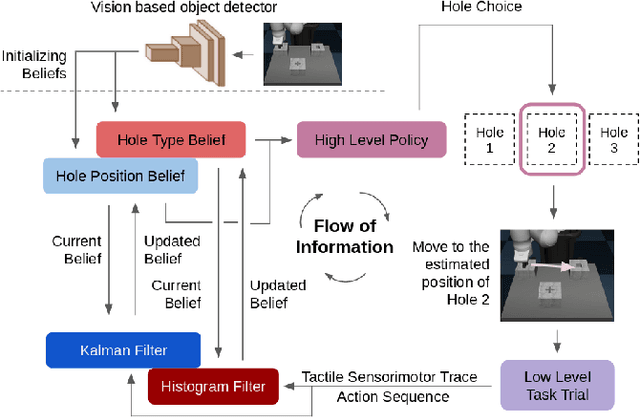
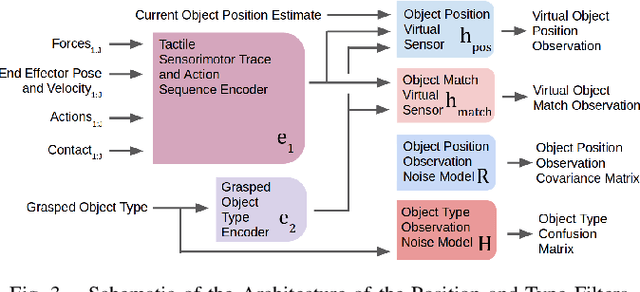
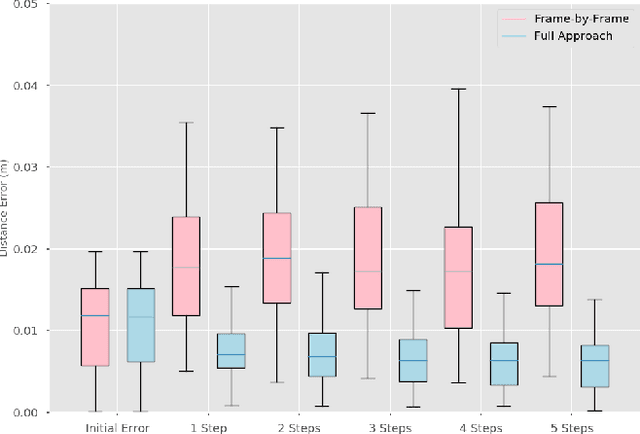
A key challenge towards the goal of multi-part assembly tasks is finding robust sensorimotor control methods in the presence of uncertainty. In contrast to previous works that rely on a priori knowledge on whether two parts match, we aim to learn this through physical interaction. We propose a hierachical approach that enables a robot to autonomously assemble parts while being uncertain about part types and positions. In particular, our probabilistic approach learns a set of differentiable filters that leverage the tactile sensorimotor trace from failed assembly attempts to update its belief about part position and type. This enables a robot to overcome assembly failure. We demonstrate the effectiveness of our approach on a set of object fitting tasks. The experimental results indicate that our proposed approach achieves higher precision in object position and type estimation, and accomplishes object fitting tasks faster than baselines.
Learning Dense Rewards for Contact-Rich Manipulation Tasks
Nov 17, 2020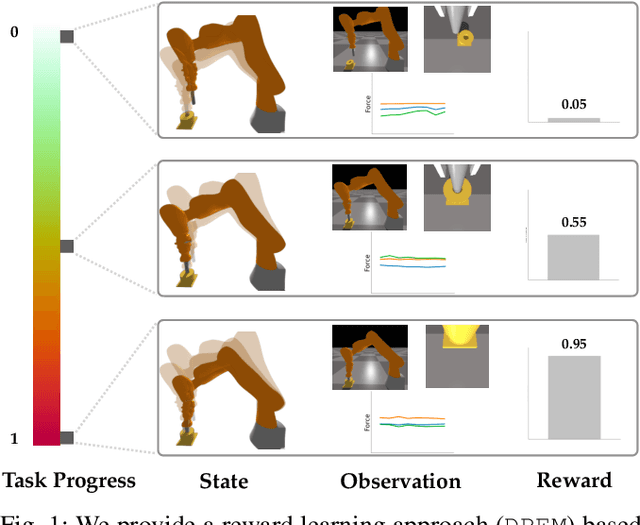
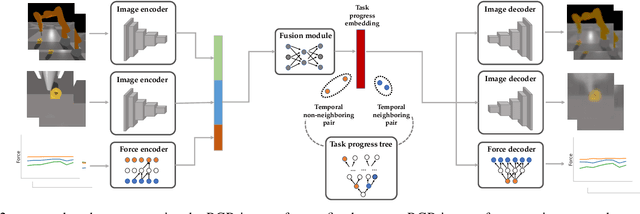
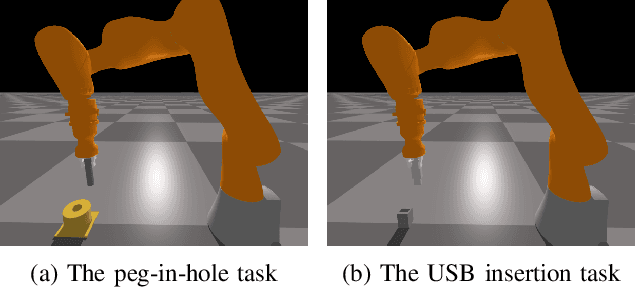
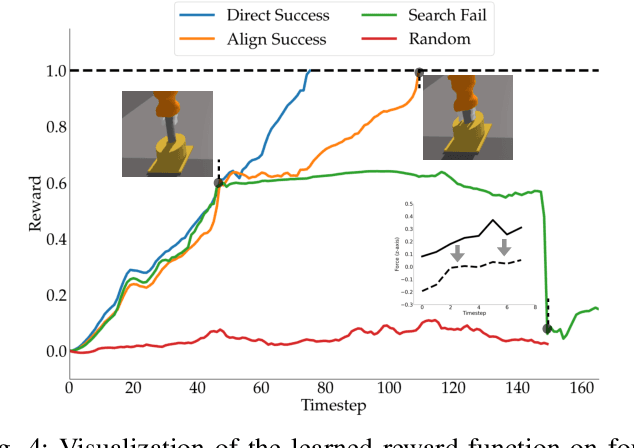
Rewards play a crucial role in reinforcement learning. To arrive at the desired policy, the design of a suitable reward function often requires significant domain expertise as well as trial-and-error. Here, we aim to minimize the effort involved in designing reward functions for contact-rich manipulation tasks. In particular, we provide an approach capable of extracting dense reward functions algorithmically from robots' high-dimensional observations, such as images and tactile feedback. In contrast to state-of-the-art high-dimensional reward learning methodologies, our approach does not leverage adversarial training, and is thus less prone to the associated training instabilities. Instead, our approach learns rewards by estimating task progress in a self-supervised manner. We demonstrate the effectiveness and efficiency of our approach on two contact-rich manipulation tasks, namely, peg-in-hole and USB insertion. The experimental results indicate that the policies trained with the learned reward function achieves better performance and faster convergence compared to the baselines.
Convex Factorization Machine for Regression
Aug 10, 2016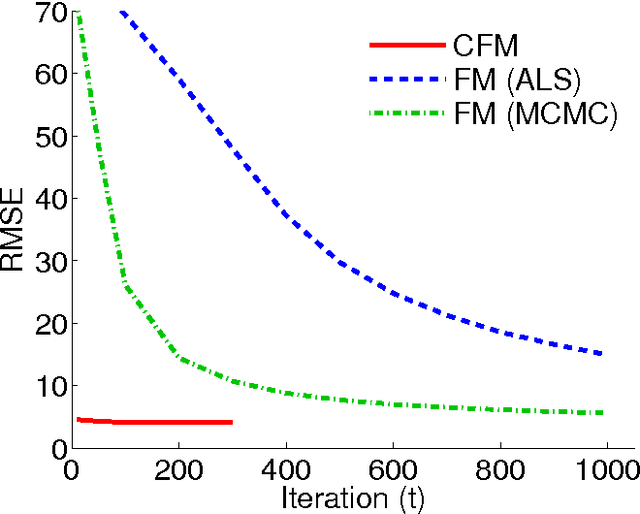
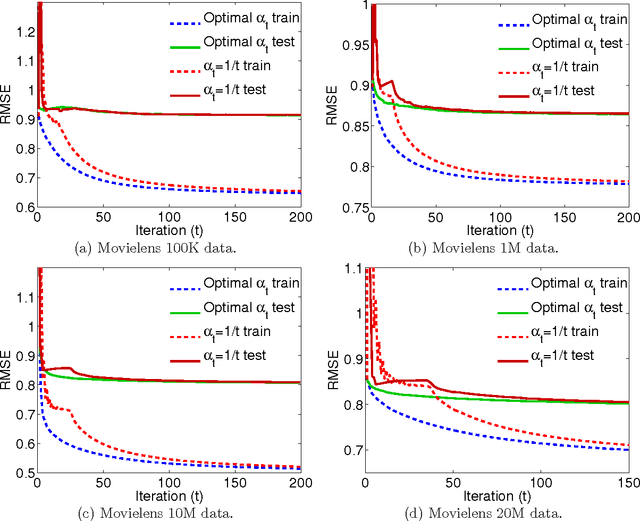
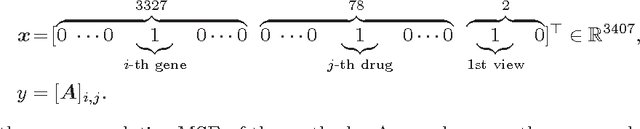
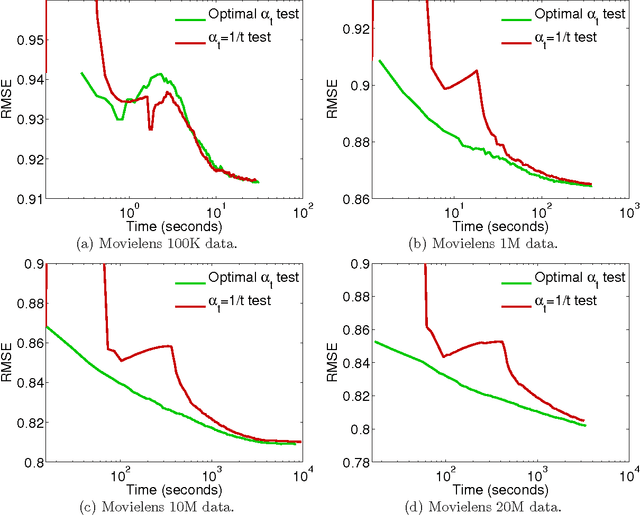
We propose the convex factorization machine (CFM), which is a convex variant of the widely used Factorization Machines (FMs). Specifically, we employ a linear+quadratic model and regularize the linear term with the $\ell_2$-regularizer and the quadratic term with the trace norm regularizer. Then, we formulate the CFM optimization as a semidefinite programming problem and propose an efficient optimization procedure with Hazan's algorithm. A key advantage of CFM over existing FMs is that it can find a globally optimal solution, while FMs may get a poor locally optimal solution since the objective function of FMs is non-convex. In addition, the proposed algorithm is simple yet effective and can be implemented easily. Finally, CFM is a general factorization method and can also be used for other factorization problems including including multi-view matrix factorization and tensor completion problems. Through synthetic and movielens datasets, we first show that the proposed CFM achieves results competitive to FMs. Furthermore, in a toxicogenomics prediction task, we show that CFM outperforms a state-of-the-art tensor factorization method.