 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Interpretable Internal States of Merging Tasks at Highway On-Ramps for Autonomous Driving Decision-Making
Feb 15, 2021
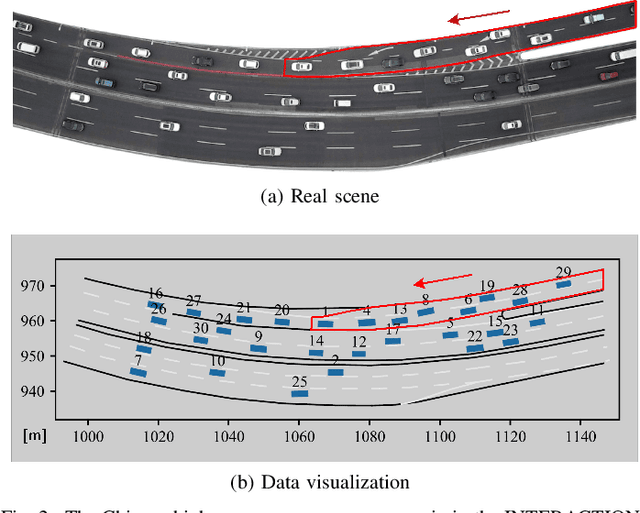
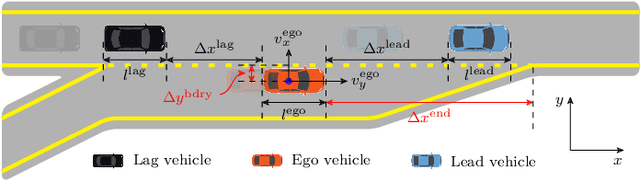
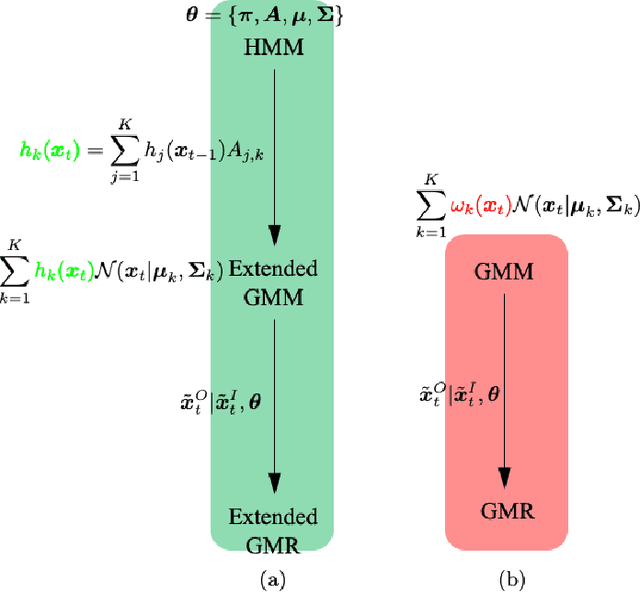
Humans make daily-routine decisions based on their internal states in intricate interaction scenarios. This paper presents a probabilistically reconstructive learning approach to identify the internal states of multi-vehicle sequential interactions when merging at highway on-ramps. We treated the merging task's sequential decision as a dynamic, stochastic process and then integrated the internal states into an HMM-GMR model, a probabilistic combination of an extended Gaussian mixture regression (GMR) and hidden Markov models (HMM). We also developed a variant expectation-maximum (EM) algorithm to estimate the model parameters and verified them based on a real-world data set. Experimental results reveal that the interactive merge procedure at highway on-ramps can be semantically described by three interpretable internal states. This finding provides a basis for autonomous vehicles to develop a model-based decision-making algorithm in a partially observable environment.
On Social Interactions of Merging Behaviors at Highway On-Ramps in Congested Traffic
Aug 14, 2020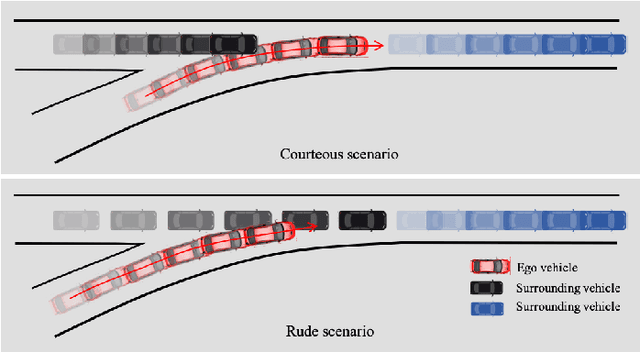
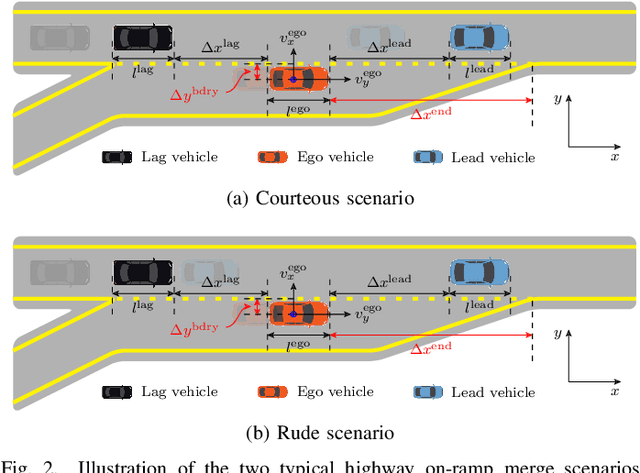
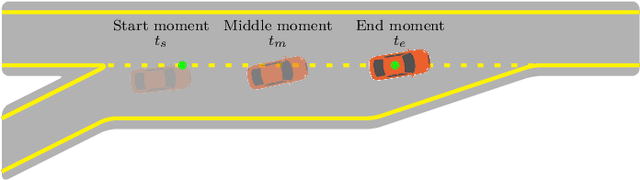
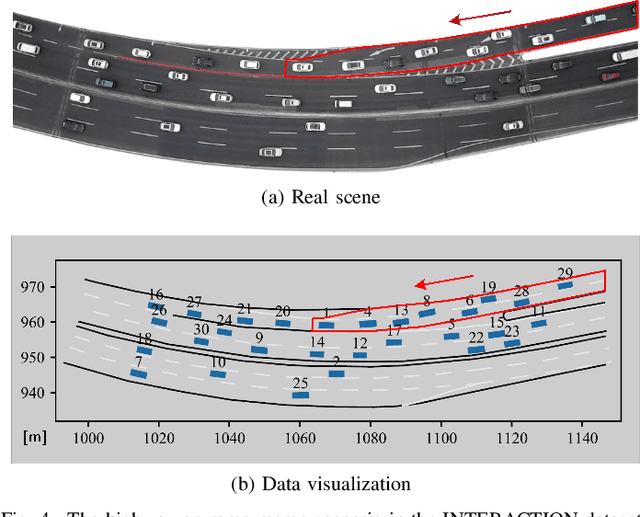
Merging at highway on-ramps while interacting with other human-driven vehicles is challenging for autonomous vehicles (AVs). An efficient route to this challenge requires exploring and then exploiting knowledge of the interaction process from demonstrations by humans. However, it is unclear what information (or the environment states) is utilized by the human driver to guide their behavior over the whole merging process. This paper provides quantitative analysis and evaluation of the merging behavior at highway on-ramps with congested traffic in a volume of time and space. Two types of social interaction scenarios are considered based on the social preferences of surrounding vehicles: courteous and rude. The significant levels of environment states for characterizing the interactive merging process are empirically analyzed based on the real-world INTERACTION dataset. Experimental results reveal two fundamental mechanisms in the merging process: 1) Human driver selects different states to make sequential decisions at different moments of task execution and 2) the social preference of surrounding vehicles has an impact on variable selection for making decisions. It implies that for autonomous driving, efficient decision-making design should filter out irrelevant information while considering the social preference of the surrounding vehicles, to reach a comparable human-level performance. These essential findings shed light on developing new decision-making approaches for AVs.
Spatiotemporal Learning of Multivehicle Interaction Patterns in Lane-Change Scenarios
Mar 02, 2020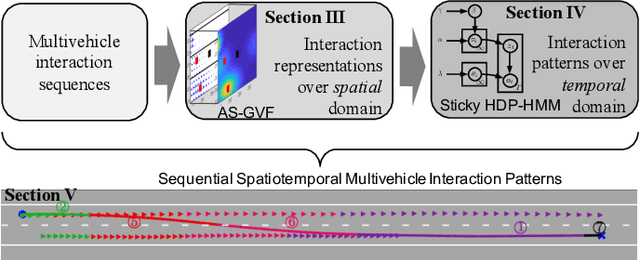
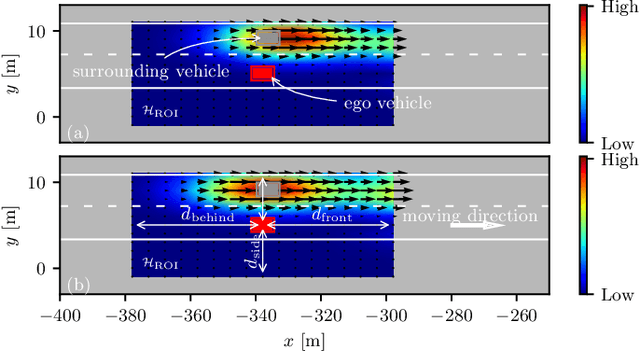
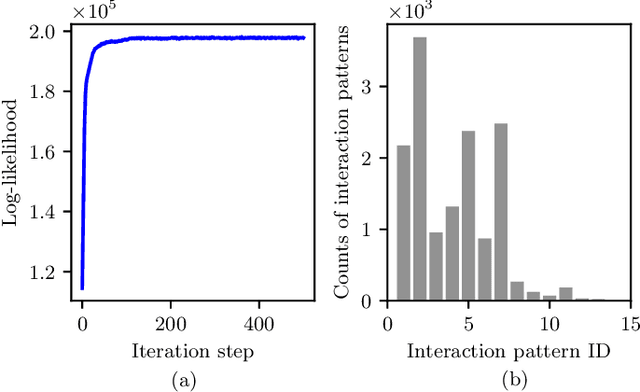
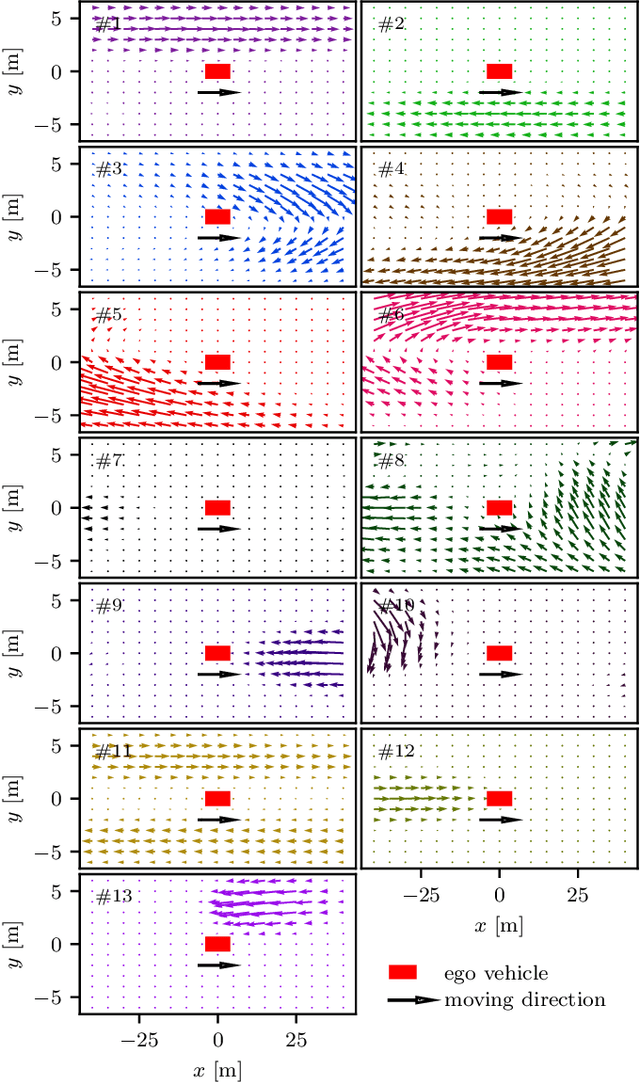
Interpretation of common-yet-challenging interaction scenarios can benefit well-founded decisions for autonomous vehicles. Previous research achieved this using their prior knowledge of specific scenarios with predefined models, which limits their adaptive capabilities. This paper describes a Bayesian nonparametric approach that leverages continuous (i.e., Gaussian processes) and discrete (i.e., Dirichlet processes) stochastic processes to reveal underlying interaction patterns of the ego vehicle with other nearby vehicles. Our model relaxes dependency on the number of surrounding vehicles by developing an acceleration-sensitive velocity field based on Gaussian processes. The experiment results demonstrate that the velocity field can represent the spatial interactions between the ego vehicle and its surroundings. Then, a discrete Bayesian nonparametric model, integrating Dirichlet processes and hidden Markov models, is developed to learn the interaction patterns over the temporal space by segmenting and clustering the sequential interaction data into interpretable granular patterns automatically. We then evaluate our approach in the highway lane-change scenarios using the highD dataset, which was collected from real-world settings. Results demonstrate that our proposed Bayesian nonparametric approach provides an insight into the complicated lane-change interactions of the ego vehicle with multiple surrounding traffic participants based on the interpretable interaction patterns and their transition properties in temporal relationships. Our proposed approach sheds light on efficiently analyzing other kinds of multi-agent interactions, such as vehicle-pedestrian interactions.
Measuring Similarity of Interactive Driving Behaviors Using Matrix Profile
Nov 03, 2019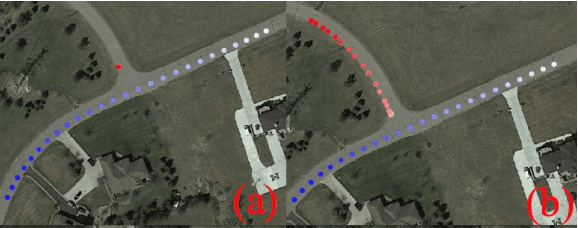
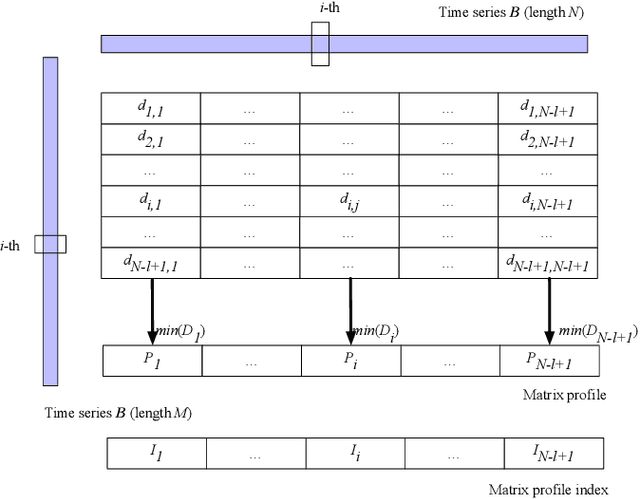
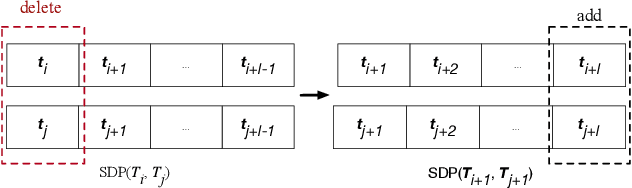
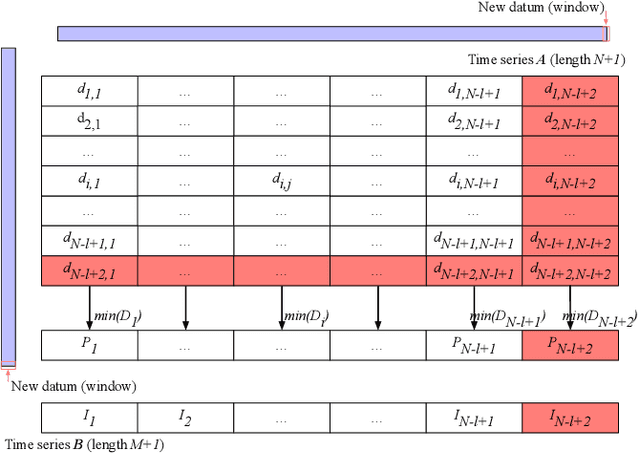
Understanding multi-vehicle interactive behaviors with temporal sequential observations is crucial for autonomous vehicles to make appropriate decisions in an uncertain traffic environment. On-demand similarity measures are significant for autonomous vehicles to deal with massive interactive driving behaviors by clustering and classifying diverse scenarios. This paper proposes a general approach for measuring spatiotemporal similarity of interactive behaviors using a multivariate matrix profile technique. The key attractive features of the approach are its superior space and time complexity, real-time online computing for streaming traffic data, and possible capability of leveraging hardware for parallel computation. The proposed approach is validated through automatically discovering similar interactive driving behaviors at intersections from sequential data.
Probabilistic Trajectory Prediction for Autonomous Vehicles with Attentive Recurrent Neural Process
Oct 17, 2019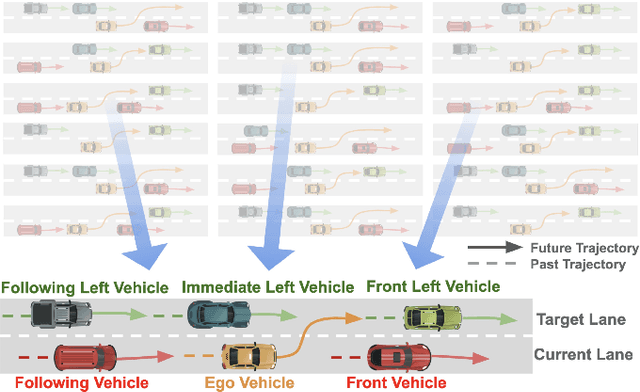
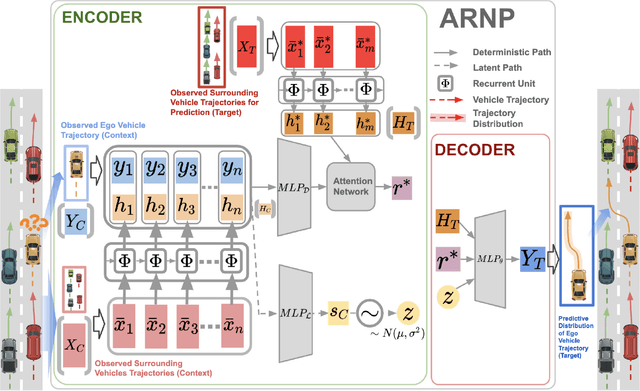

Predicting surrounding vehicle behaviors are critical to autonomous vehicles when negotiating in multi-vehicle interaction scenarios. Most existing approaches require tedious training process with large amounts of data and may fail to capture the propagating uncertainty in interaction behaviors. The multi-vehicle behaviors are assumed to be generated from a stochastic process. This paper proposes an attentive recurrent neural process (ARNP) approach to overcome the above limitations, which uses a neural process (NP) to learn a distribution of multi-vehicle interaction behavior. Our proposed model inherits the flexibility of neural networks while maintaining Bayesian probabilistic characteristics. Constructed by incorporating NPs with recurrent neural networks (RNNs), the ARNP model predicts the distribution of a target vehicle trajectory conditioned on the observed long-term sequential data of all surrounding vehicles. This approach is verified by learning and predicting lane-changing trajectories in complex traffic scenarios. Experimental results demonstrate that our proposed method outperforms previous counterparts in terms of accuracy and uncertainty expressiveness. Moreover, the meta-learning instinct of NPs enables our proposed ARNP model to capture global information of all observations, thereby being able to adapt to new targets efficiently.
Recurrent Attentive Neural Process for Sequential Data
Oct 17, 2019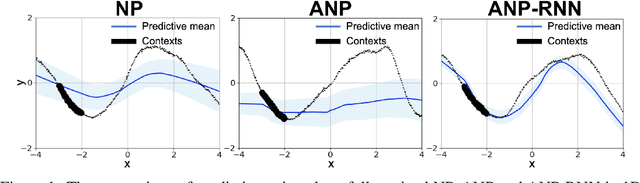
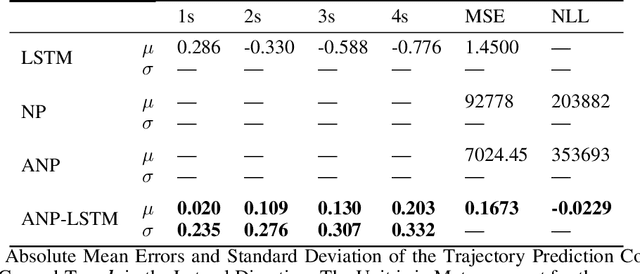
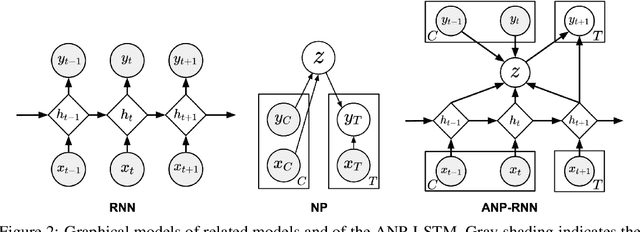
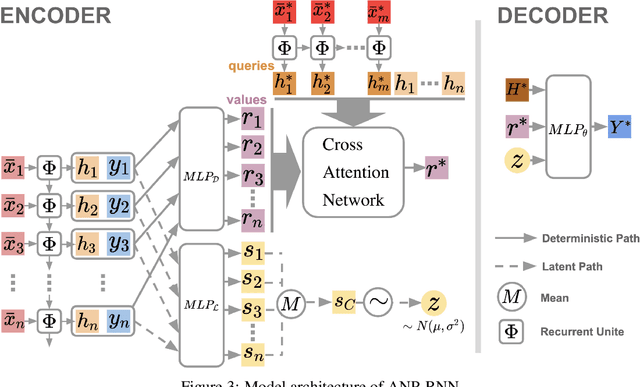
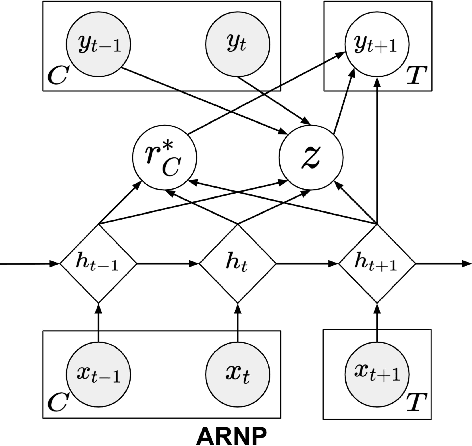
Neural processes (NPs) learn stochastic processes and predict the distribution of target output adaptively conditioned on a context set of observed input-output pairs. Furthermore, Attentive Neural Process (ANP) improved the prediction accuracy of NPs by incorporating attention mechanism among contexts and targets. In a number of real-world applications such as robotics, finance, speech, and biology, it is critical to learn the temporal order and recurrent structure from sequential data. However, the capability of NPs capturing these properties is limited due to its permutation invariance instinct. In this paper, we proposed the Recurrent Attentive Neural Process (RANP), or alternatively, Attentive Neural Process-RecurrentNeural Network(ANP-RNN), in which the ANP is incorporated into a recurrent neural network. The proposed model encapsulates both the inductive biases of recurrent neural networks and also the strength of NPs for modelling uncertainty. We demonstrate that RANP can effectively model sequential data and outperforms NPs and LSTMs remarkably in a 1D regression toy example as well as autonomous-driving applications.
Multi-Vehicle Interaction Scenarios Generation with Interpretable Traffic Primitives and Gaussian Process Regression
Oct 08, 2019



Generating multi-vehicle interaction scenarios can benefit motion planning and decision making of autonomous vehicles when on-road data is insufficient. This paper presents an efficient approach to generate varied multi-vehicle interaction scenarios that can both adapt to different road geometries and inherit the key interaction patterns in real-world driving. Towards this end, the available multi-vehicle interaction scenarios are temporally segmented into several interpretable fundamental building blocks, called traffic primitives, via the Bayesian nonparametric learning. Then, the changepoints of traffic primitives are transformed into the desired road to generate collision-free interaction trajectories through a sampling-based path planning algorithm. The Gaussian process regression is finally introduced to control the variance and smoothness of the generated multi-vehicle interaction trajectories. Experiments with simulation results of three typical multi-vehicle trajectories at different road conditions are carried out. The experimental results demonstrate that our proposed method can generate a bunch of human-like multi-vehicle interaction trajectories that can fit different road conditions remaining the key interaction patterns of agents in the provided scenarios, which is import to the development of autonomous vehicles.
Active Learning for Risk-Sensitive Inverse Reinforcement Learning
Sep 23, 2019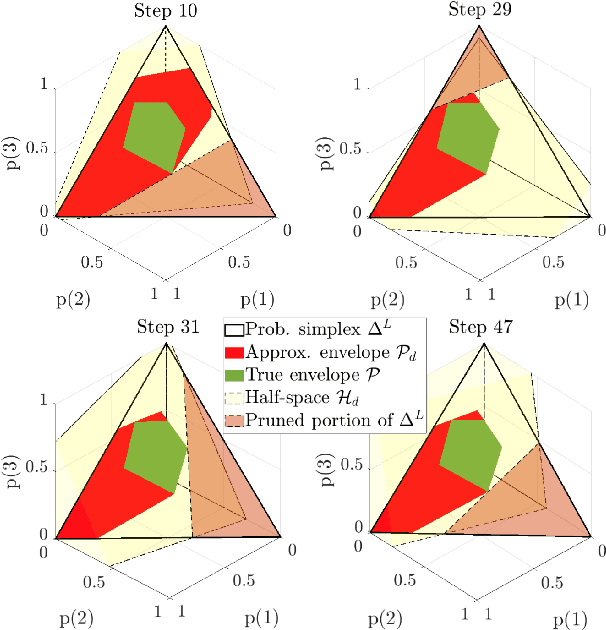
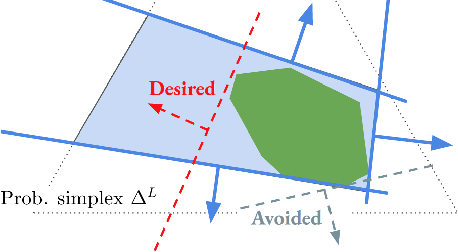
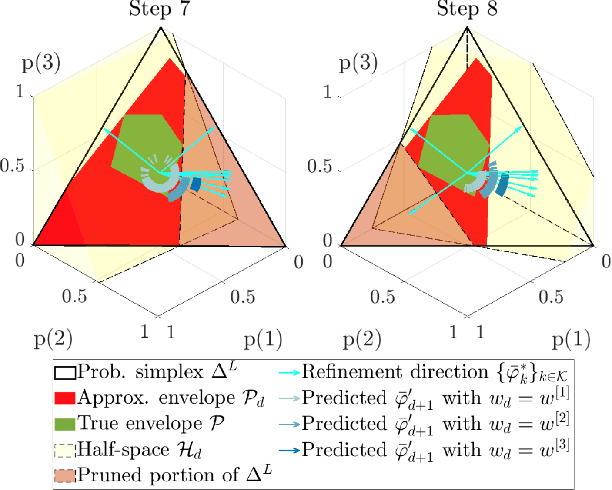
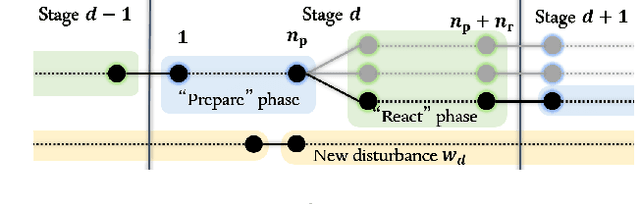
One typical assumption in inverse reinforcement learning (IRL) is that human experts act to optimize the expected utility of a stochastic cost with a fixed distribution. This assumption deviates from actual human behaviors under ambiguity. Risk-sensitive inverse reinforcement learning (RS-IRL) bridges such gap by assuming that humans act according to a random cost with respect to a set of subjectively distorted distributions instead of a fixed one. Such assumption provides the additional flexibility to model human's risk preferences, represented by a risk envelope, in safe-critical tasks. However, like other learning from demonstration techniques, RS-IRL could also suffer inefficient learning due to redundant demonstrations. Inspired by the concept of active learning, this research derives a probabilistic disturbance sampling scheme to enable an RS-IRL agent to query expert support that is likely to expose unrevealed boundaries of the expert's risk envelope. Experimental results confirm that our approach accelerates the convergence of RS-IRL algorithms with lower variance while still guaranteeing unbiased convergence.
A General Framework of Learning Multi-Vehicle Interaction Patterns from Videos
Jul 17, 2019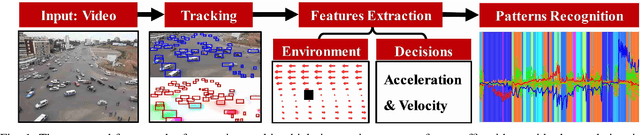
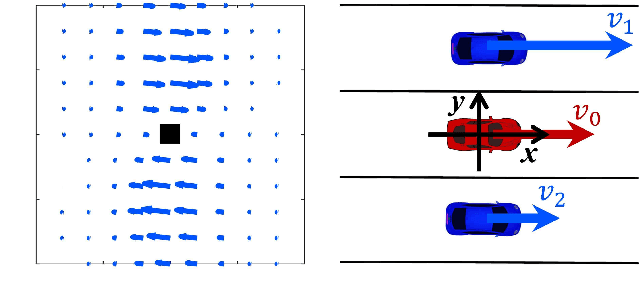
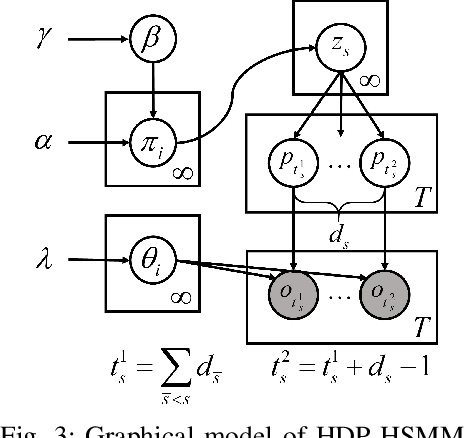
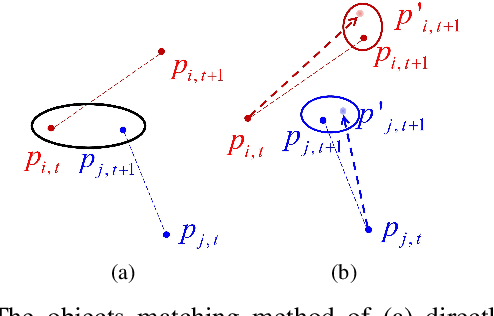
Semantic learning and understanding of multi-vehicle interaction patterns in a cluttered driving environment are essential but challenging for autonomous vehicles to make proper decisions. This paper presents a general framework to gain insights into intricate multi-vehicle interaction patterns from bird's-eye view traffic videos. We adopt a Gaussian velocity field to describe the time-varying multi-vehicle interaction behaviors and then use deep autoencoders to learn associated latent representations for each temporal frame. Then, we utilize a hidden semi-Markov model with a hierarchical Dirichlet process as a prior to segment these sequential representations into granular components, also called traffic primitives, corresponding to interaction patterns. Experimental results demonstrate that our proposed framework can extract traffic primitives from videos, thus providing a semantic way to analyze multi-vehicle interaction patterns, even for cluttered driving scenarios that are far messier than human beings can cope with.
Modeling Multi-Vehicle Interaction Scenarios Using Gaussian Random Field
Jun 25, 2019
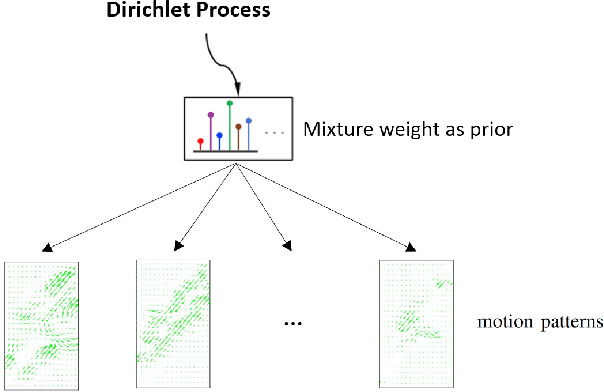
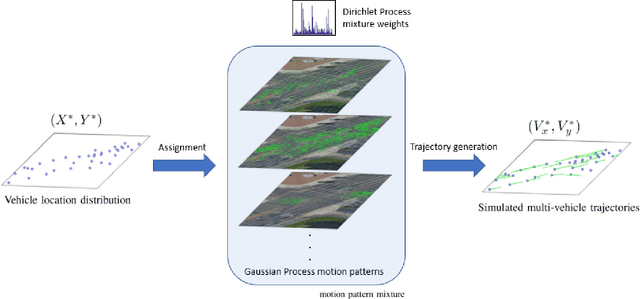
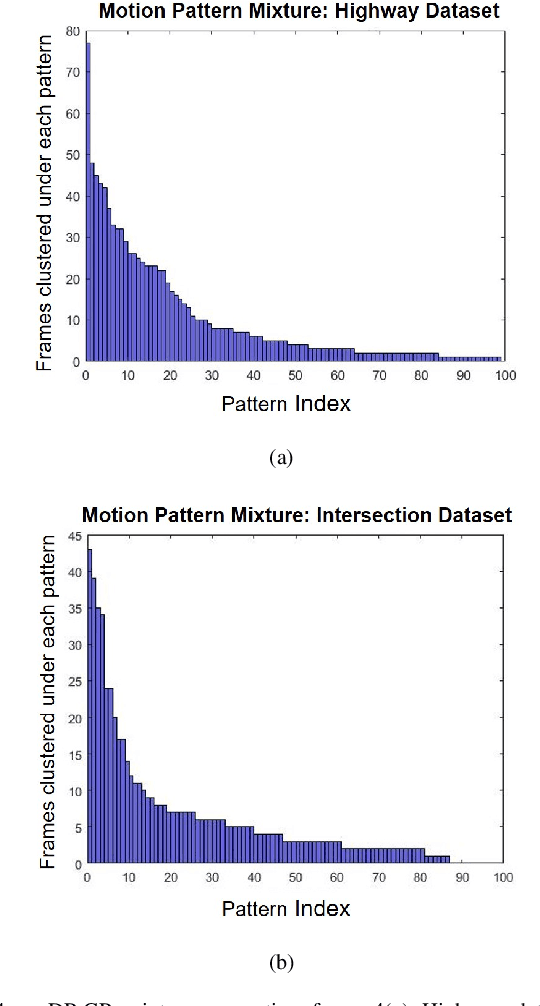
Autonomous vehicles (AV) are expected to navigate in complex traffic scenarios with multiple surrounding vehicles. The correlations between road users vary over time, the degree of which, in theory, could be infinitely large, and thus posing a great challenge in modeling and predicting the driving environment. In this research, we propose a method to reproduce such high-dimensional scenarios in a finitely tractable form by defining a stochastic vector field model in multi-vehicle interactions. We then apply non-parametric Bayesian learning to extract the underlying motion patterns from a large quantity of naturalistic traffic data. We use Gaussian process to model multi-vehicle motion, and Dirichlet process to assign each observation to a specific scenario. We implement the proposed method on NGSim highway and intersection data sets, in which complex multi-vehicle interactions are prevalent. The results show that the proposed method is capable of capturing motion patterns from both settings, without imposing heroic prior, hence can be applied for a wide array of traffic situations. The proposed modeling can enable simulation platforms and other testing methods designed for AV evaluation, to easily model and generate traffic scenarios emulating large scale driving data.