 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
I-Perceive: A Foundation Model for Active Perception with Language Instructions
Feb 28, 2026Active perception, the ability of a robot to proactively adjust its viewpoint to acquire task-relevant information, is essential for robust operation in unstructured real-world environments. While critical for downstream tasks such as manipulation, existing approaches have largely been confined to local settings (e.g., table-top scenes) with fixed perception objectives (e.g., occlusion reduction). Addressing active perception with open-ended intents in large-scale environments remains an open challenge. To bridge this gap, we propose I-Perceive, a foundation model for active perception conditioned on natural language instructions, designed for mobile manipulators and indoor environments. I-Perceive predicts camera views that follows open-ended language instructions, based on image-based scene contexts. By fusing a Vision-Language Model (VLM) backbone with a geometric foundation model, I-Perceive bridges semantic and geometric understanding, thus enabling effective reasoning for active perception. We train I-Perceive on a diverse dataset comprising real-world scene-scanning data and simulation data, both processed via an automated and scalable data generation pipeline. Experiments demonstrate that I-Perceive significantly outperforms state-of-the-art VLMs in both prediction accuracy and instruction following of generated camera views, and exhibits strong zero-shot generalization to novel scenes and tasks.
Mimic Intent, Not Just Trajectories
Feb 09, 2026While imitation learning (IL) has achieved impressive success in dexterous manipulation through generative modeling and pretraining, state-of-the-art approaches like Vision-Language-Action (VLA) models still struggle with adaptation to environmental changes and skill transfer. We argue this stems from mimicking raw trajectories without understanding the underlying intent. To address this, we propose explicitly disentangling behavior intent from execution details in end-2-end IL: \textit{``Mimic Intent, Not just Trajectories'' (MINT)}. We achieve this via \textit{multi-scale frequency-space tokenization}, which enforces a spectral decomposition of action chunk representation. We learn action tokens with a multi-scale coarse-to-fine structure, and force the coarsest token to capture low-frequency global structure and finer tokens to encode high-frequency details. This yields an abstract \textit{Intent token} that facilitates planning and transfer, and multi-scale \textit{Execution tokens} that enable precise adaptation to environmental dynamics. Building on this hierarchy, our policy generates trajectories through \textit{next-scale autoregression}, performing progressive \textit{intent-to-execution reasoning}, thus boosting learning efficiency and generalization. Crucially, this disentanglement enables \textit{one-shot transfer} of skills, by simply injecting the Intent token from a demonstration into the autoregressive generation process. Experiments on several manipulation benchmarks and on a real robot demonstrate state-of-the-art success rates, superior inference efficiency, robust generalization against disturbances, and effective one-shot transfer.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Efficient Discrete Supervised Hashing for Large-scale Cross-modal Retrieval
May 03, 2019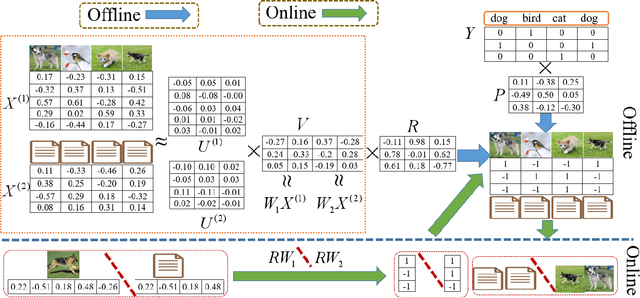
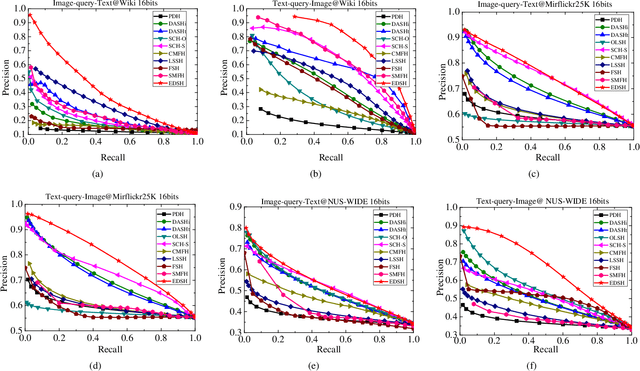
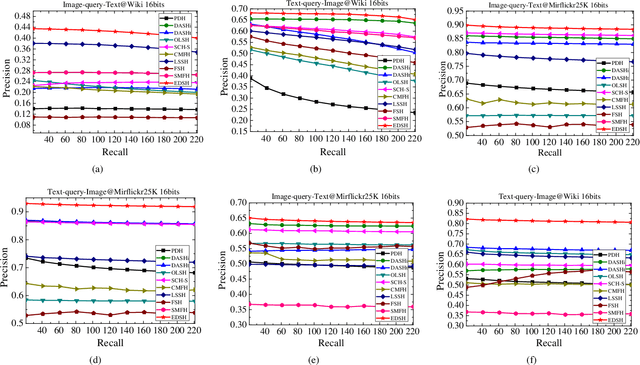
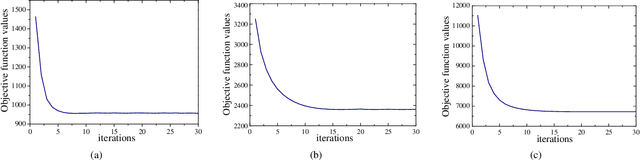
Supervised cross-modal hashing has gained increasing research interest on large-scale retrieval task owning to its satisfactory performance and efficiency. However, it still has some challenging issues to be further studied: 1) most of them fail to well preserve the semantic correlations in hash codes because of the large heterogenous gap; 2) most of them relax the discrete constraint on hash codes, leading to large quantization error and consequent low performance; 3) most of them suffer from relatively high memory cost and computational complexity during training procedure, which makes them unscalable. In this paper, to address above issues, we propose a supervised cross-modal hashing method based on matrix factorization dubbed Efficient Discrete Supervised Hashing (EDSH). Specifically, collective matrix factorization on heterogenous features and semantic embedding with class labels are seamlessly integrated to learn hash codes. Therefore, the feature based similarities and semantic correlations can be both preserved in hash codes, which makes the learned hash codes more discriminative. Then an efficient discrete optimal algorithm is proposed to handle the scalable issue. Instead of learning hash codes bit-by-bit, hash codes matrix can be obtained directly which is more efficient. Extensive experimental results on three public real-world datasets demonstrate that EDSH produces a superior performance in both accuracy and scalability over some existing cross-modal hashing methods.