 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDKG: A Descriptive Knowledge Graph for Explaining Relationships between Entities
May 21, 2022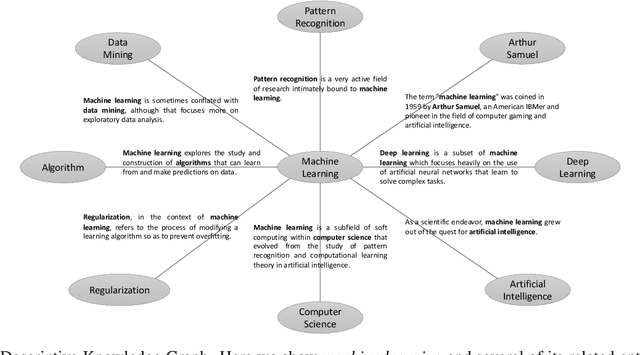
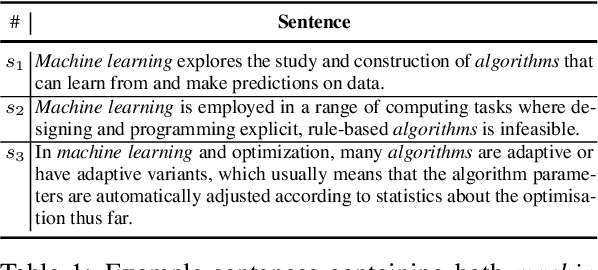
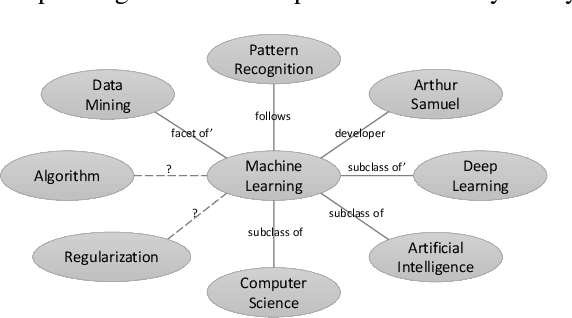
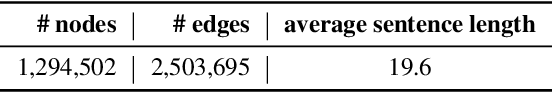
In this paper, we propose Descriptive Knowledge Graph (DKG) - an open and interpretable form of modeling relationships between entities. In DKGs, relationships between entities are represented by relation descriptions. For instance, the relationship between entities of machine learning and algorithm can be described as "Machine learning explores the study and construction of algorithms that can learn from and make predictions on data." To construct DKGs, we propose a self-supervised learning method to extract relation descriptions with the analysis of dependency patterns and a transformer-based relation description synthesizing model to generate relation descriptions. Experiments demonstrate that our system can extract and generate high-quality relation descriptions for explaining entity relationships.
Graph Neural Network Training with Data Tiering
Nov 10, 2021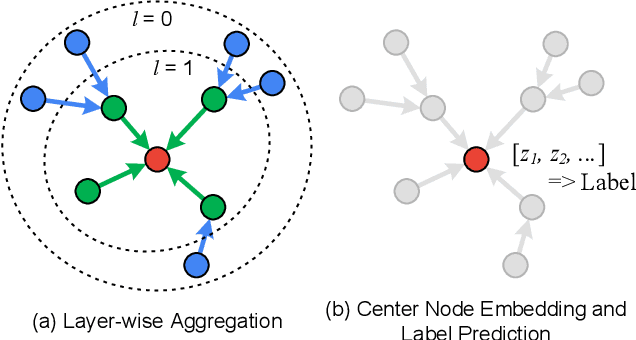
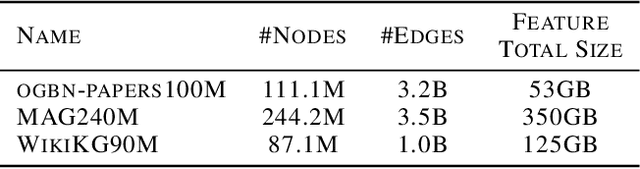
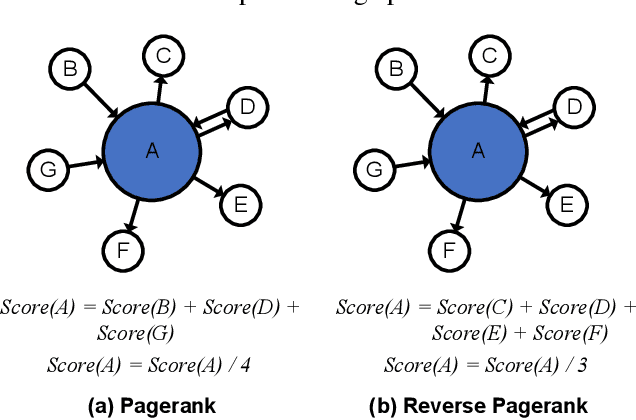
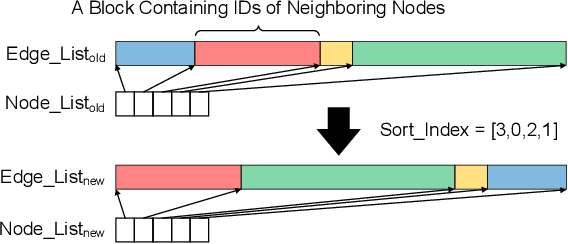
Graph Neural Networks (GNNs) have shown success in learning from graph-structured data, with applications to fraud detection, recommendation, and knowledge graph reasoning. However, training GNN efficiently is challenging because: 1) GPU memory capacity is limited and can be insufficient for large datasets, and 2) the graph-based data structure causes irregular data access patterns. In this work, we provide a method to statistical analyze and identify more frequently accessed data ahead of GNN training. Our data tiering method not only utilizes the structure of input graph, but also an insight gained from actual GNN training process to achieve a higher prediction result. With our data tiering method, we additionally provide a new data placement and access strategy to further minimize the CPU-GPU communication overhead. We also take into account of multi-GPU GNN training as well and we demonstrate the effectiveness of our strategy in a multi-GPU system. The evaluation results show that our work reduces CPU-GPU traffic by 87-95% and improves the training speed of GNN over the existing solutions by 1.6-2.1x on graphs with hundreds of millions of nodes and billions of edges.
MLHarness: A Scalable Benchmarking System for MLCommons
Nov 09, 2021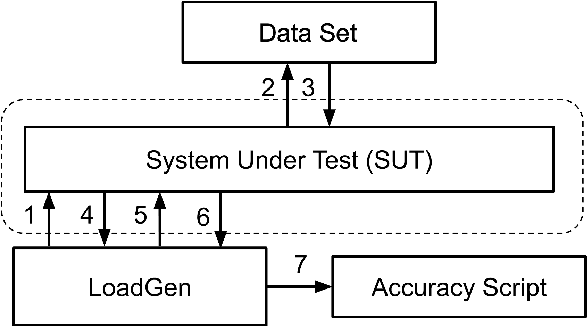
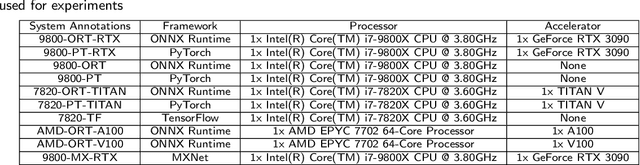

With the society's growing adoption of machine learning (ML) and deep learning (DL) for various intelligent solutions, it becomes increasingly imperative to standardize a common set of measures for ML/DL models with large scale open datasets under common development practices and resources so that people can benchmark and compare models quality and performance on a common ground. MLCommons has emerged recently as a driving force from both industry and academia to orchestrate such an effort. Despite its wide adoption as standardized benchmarks, MLCommons Inference has only included a limited number of ML/DL models (in fact seven models in total). This significantly limits the generality of MLCommons Inference's benchmarking results because there are many more novel ML/DL models from the research community, solving a wide range of problems with different inputs and outputs modalities. To address such a limitation, we propose MLHarness, a scalable benchmarking harness system for MLCommons Inference with three distinctive features: (1) it codifies the standard benchmark process as defined by MLCommons Inference including the models, datasets, DL frameworks, and software and hardware systems; (2) it provides an easy and declarative approach for model developers to contribute their models and datasets to MLCommons Inference; and (3) it includes the support of a wide range of models with varying inputs/outputs modalities so that we can scalably benchmark these models across different datasets, frameworks, and hardware systems. This harness system is developed on top of the MLModelScope system, and will be open sourced to the community. Our experimental results demonstrate the superior flexibility and scalability of this harness system for MLCommons Inference benchmarking.
Open Relation Modeling: Learning to Define Relations between Entities
Aug 20, 2021

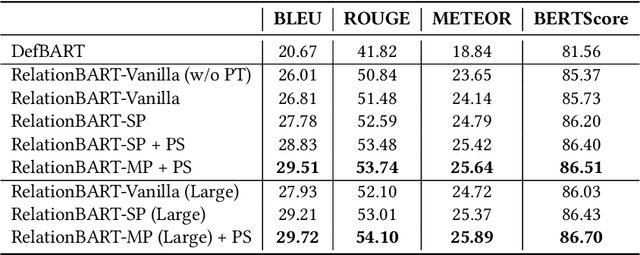
Relations between entities can be represented by different instances, e.g., a sentence containing both entities or a fact in a Knowledge Graph (KG). However, these instances may not well capture the general relations between entities, may be difficult to understand by humans, even may not be found due to the incompleteness of the knowledge source. In this paper, we introduce the Open Relation Modeling task - given two entities, generate a coherent sentence describing the relation between them. To solve this task, we propose to teach machines to generate definition-like relation descriptions by letting them learn from definitions of entities. Specifically, we fine-tune Pre-trained Language Models (PLMs) to produce definitions conditioned on extracted entity pairs. To help PLMs reason between entities and provide additional relational knowledge to PLMs for open relation modeling, we incorporate reasoning paths in KGs and include a reasoning path selection mechanism. We show that PLMs can select interpretable and informative reasoning paths by confidence estimation, and the selected path can guide PLMs to generate better relation descriptions. Experimental results show that our model can generate concise but informative relation descriptions that capture the representative characteristics of entities and relations.
Measuring Fine-Grained Domain Relevance of Terms: A Hierarchical Core-Fringe Approach
May 27, 2021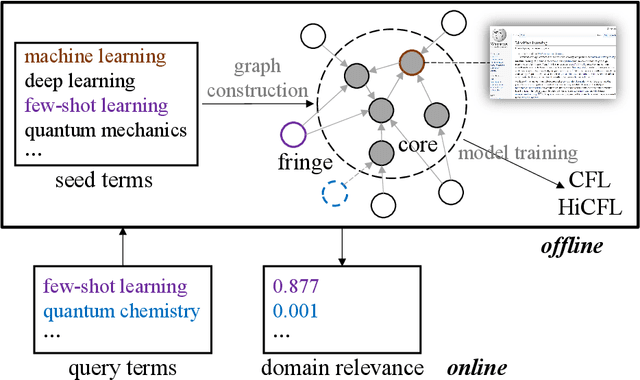
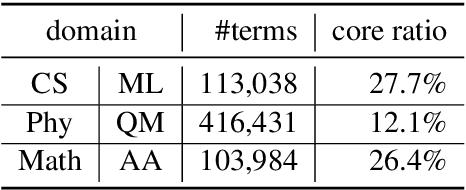
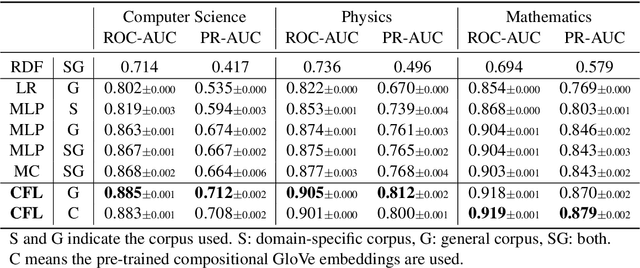
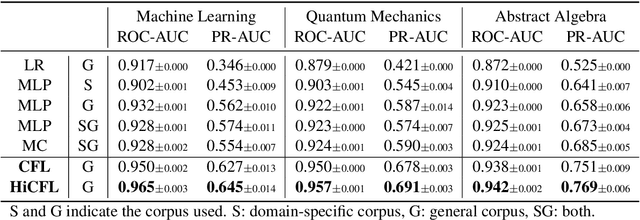
We propose to measure fine-grained domain relevance - the degree that a term is relevant to a broad (e.g., computer science) or narrow (e.g., deep learning) domain. Such measurement is crucial for many downstream tasks in natural language processing. To handle long-tail terms, we build a core-anchored semantic graph, which uses core terms with rich description information to bridge the vast remaining fringe terms semantically. To support a fine-grained domain without relying on a matching corpus for supervision, we develop hierarchical core-fringe learning, which learns core and fringe terms jointly in a semi-supervised manner contextualized in the hierarchy of the domain. To reduce expensive human efforts, we employ automatic annotation and hierarchical positive-unlabeled learning. Our approach applies to big or small domains, covers head or tail terms, and requires little human effort. Extensive experiments demonstrate that our methods outperform strong baselines and even surpass professional human performance.
Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture
Mar 04, 2021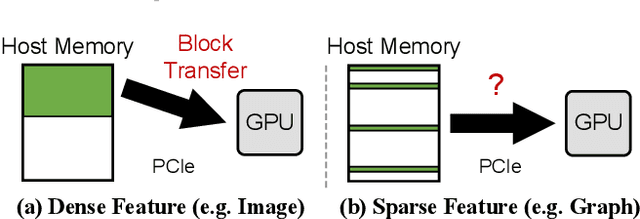

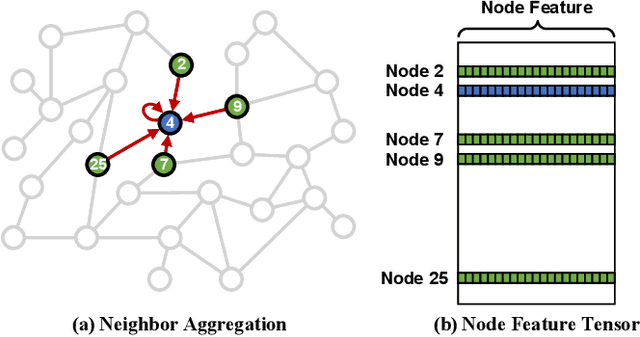

Graph Convolutional Networks (GCNs) are increasingly adopted in large-scale graph-based recommender systems. Training GCN requires the minibatch generator traversing graphs and sampling the sparsely located neighboring nodes to obtain their features. Since real-world graphs often exceed the capacity of GPU memory, current GCN training systems keep the feature table in host memory and rely on the CPU to collect sparse features before sending them to the GPUs. This approach, however, puts tremendous pressure on host memory bandwidth and the CPU. This is because the CPU needs to (1) read sparse features from memory, (2) write features into memory as a dense format, and (3) transfer the features from memory to the GPUs. In this work, we propose a novel GPU-oriented data communication approach for GCN training, where GPU threads directly access sparse features in host memory through zero-copy accesses without much CPU help. By removing the CPU gathering stage, our method significantly reduces the consumption of the host resources and data access latency. We further present two important techniques to achieve high host memory access efficiency by the GPU: (1) automatic data access address alignment to maximize PCIe packet efficiency, and (2) asynchronous zero-copy access and kernel execution to fully overlap data transfer with training. We incorporate our method into PyTorch and evaluate its effectiveness using several graphs with sizes up to 111 million nodes and 1.6 billion edges. In a multi-GPU training setup, our method is 65-92% faster than the conventional data transfer method, and can even match the performance of all-in-GPU-memory training for some graphs that fit in GPU memory.
PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
Jan 20, 2021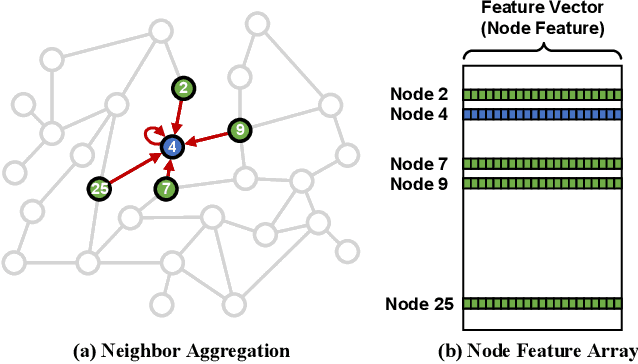

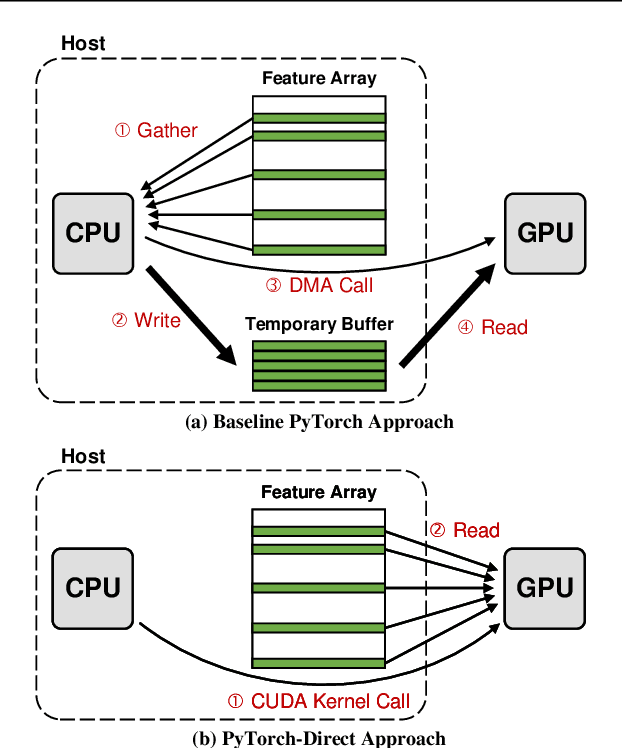

With the increasing adoption of graph neural networks (GNNs) in the machine learning community, GPUs have become an essential tool to accelerate GNN training. However, training GNNs on very large graphs that do not fit in GPU memory is still a challenging task. Unlike conventional neural networks, mini-batching input samples in GNNs requires complicated tasks such as traversing neighboring nodes and gathering their feature values. While this process accounts for a significant portion of the training time, we find existing GNN implementations using popular deep neural network (DNN) libraries such as PyTorch are limited to a CPU-centric approach for the entire data preparation step. This "all-in-CPU" approach has negative impact on the overall GNN training performance as it over-utilizes CPU resources and hinders GPU acceleration of GNN training. To overcome such limitations, we introduce PyTorch-Direct, which enables a GPU-centric data accessing paradigm for GNN training. In PyTorch-Direct, GPUs are capable of efficiently accessing complicated data structures in host memory directly without CPU intervention. Our microbenchmark and end-to-end GNN training results show that PyTorch-Direct reduces data transfer time by 47.1% on average and speeds up GNN training by up to 1.6x. Furthermore, by reducing CPU utilization, PyTorch-Direct also saves system power by 12.4% to 17.5% during training. To minimize programmer effort, we introduce a new "unified tensor" type along with necessary changes to the PyTorch memory allocator, dispatch logic, and placement rules. As a result, users need to change at most two lines of their PyTorch GNN training code for each tensor object to take advantage of PyTorch-Direct.
Interpretable Visual Reasoning via Induced Symbolic Space
Nov 23, 2020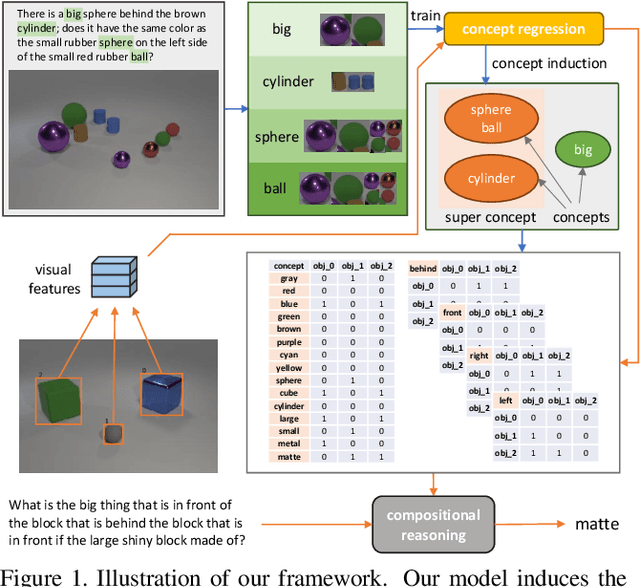
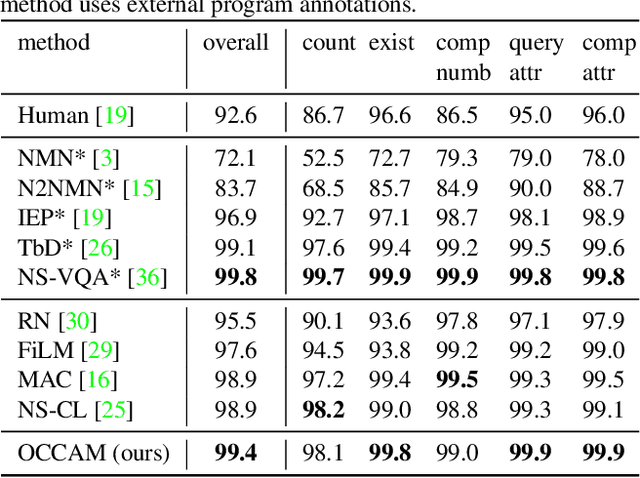
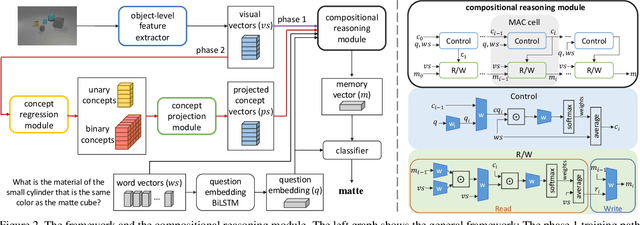

We study the problem of concept induction in visual reasoning, i.e., identifying concepts and their hierarchical relationships from question-answer pairs associated with images; and achieve an interpretable model via working on the induced symbolic concept space. To this end, we first design a new framework named object-centric compositional attention model (OCCAM) to perform the visual reasoning task with object-level visual features. Then, we come up with a method to induce concepts of objects and relations using clues from the attention patterns between objects' visual features and question words. Finally, we achieve a higher level of interpretability by imposing OCCAM on the objects represented in the induced symbolic concept space. Experiments on the CLEVR dataset demonstrate: 1) our OCCAM achieves a new state of the art without human-annotated functional programs; 2) our induced concepts are both accurate and sufficient as OCCAM achieves an on-par performance on objects represented either in visual features or in the induced symbolic concept space.
Effective Algorithm-Accelerator Co-design for AI Solutions on Edge Devices
Oct 15, 2020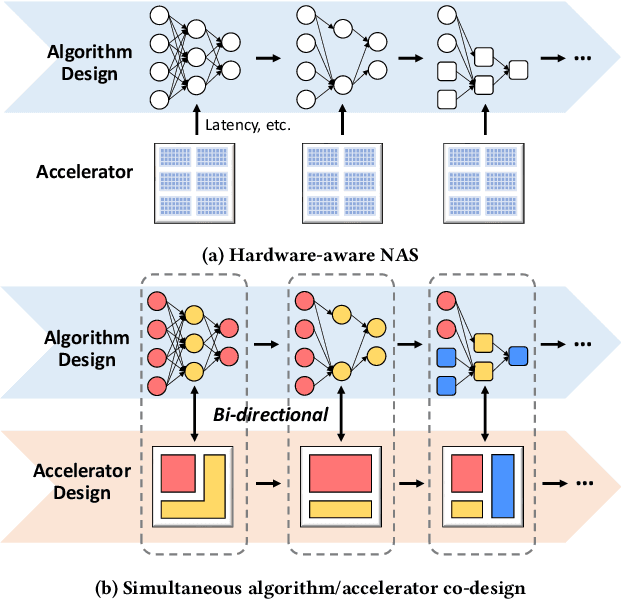
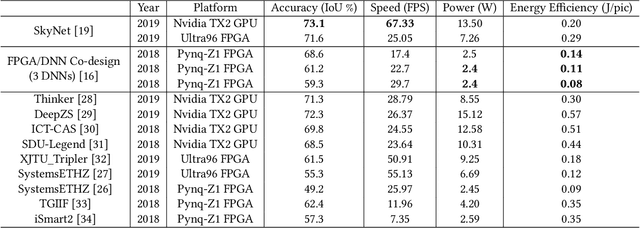
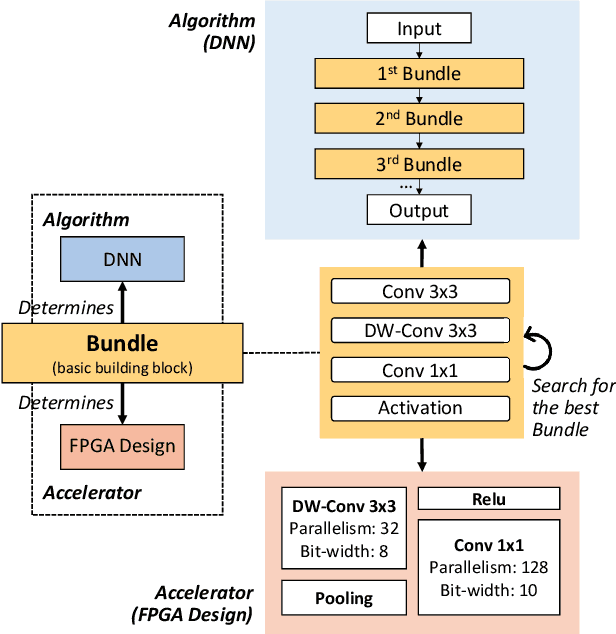
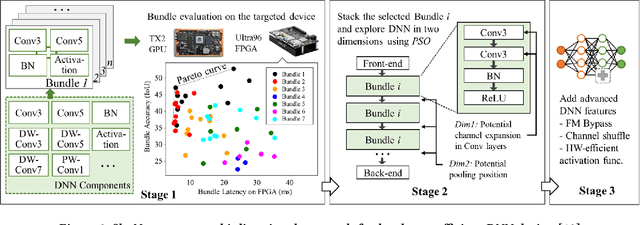
High quality AI solutions require joint optimization of AI algorithms, such as deep neural networks (DNNs), and their hardware accelerators. To improve the overall solution quality as well as to boost the design productivity, efficient algorithm and accelerator co-design methodologies are indispensable. In this paper, we first discuss the motivations and challenges for the Algorithm/Accelerator co-design problem and then provide several effective solutions. Especially, we highlight three leading works of effective co-design methodologies: 1) the first simultaneous DNN/FPGA co-design method; 2) a bi-directional lightweight DNN and accelerator co-design method; 3) a differentiable and efficient DNN and accelerator co-search method. We demonstrate the effectiveness of the proposed co-design approaches using extensive experiments on both FPGAs and GPUs, with comparisons to existing works. This paper emphasizes the importance and efficacy of algorithm-accelerator co-design and calls for more research breakthroughs in this interesting and demanding area.
Exploring Semantic Capacity of Terms
Oct 05, 2020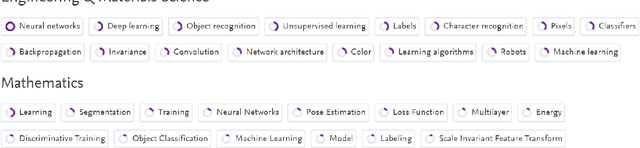
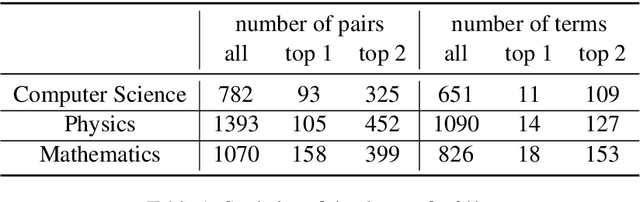
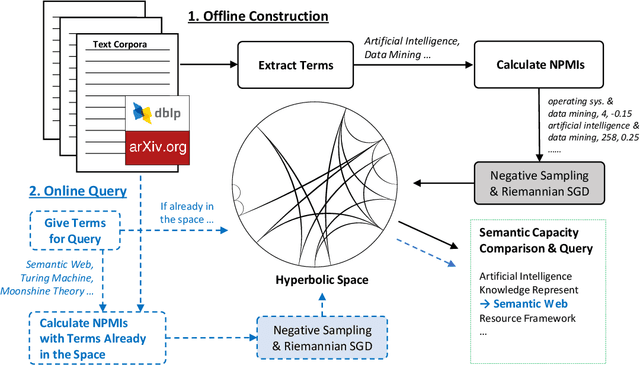
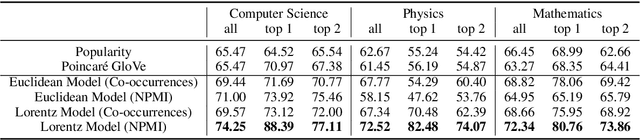
We introduce and study semantic capacity of terms. For example, the semantic capacity of artificial intelligence is higher than that of linear regression since artificial intelligence possesses a broader meaning scope. Understanding semantic capacity of terms will help many downstream tasks in natural language processing. For this purpose, we propose a two-step model to investigate semantic capacity of terms, which takes a large text corpus as input and can evaluate semantic capacity of terms if the text corpus can provide enough co-occurrence information of terms. Extensive experiments in three fields demonstrate the effectiveness and rationality of our model compared with well-designed baselines and human-level evaluations.