 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMNA-Net for Overall Survival Time Prediction of Brain Tumor Patients
Jun 13, 2022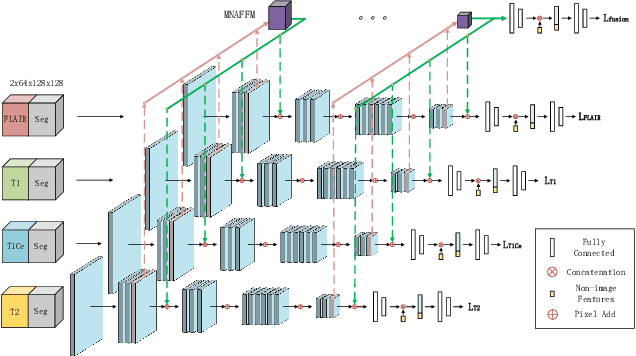
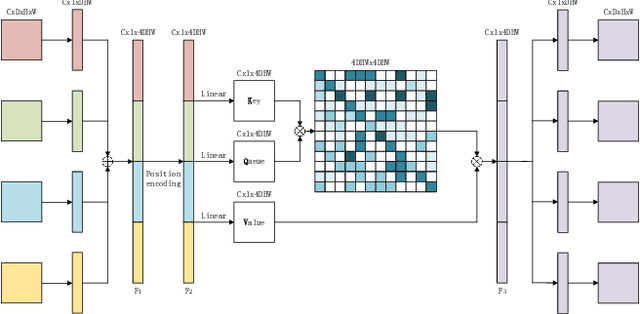
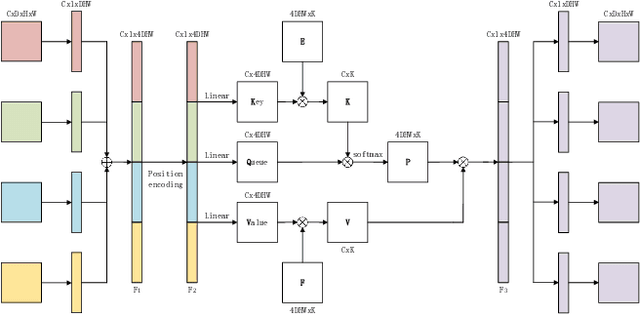
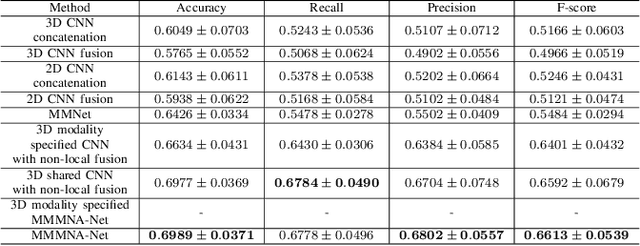
Overall survival (OS) time is one of the most important evaluation indices for gliomas situations. Multimodal Magnetic Resonance Imaging (MRI) scans play an important role in the study of glioma prognosis OS time. Several deep learning-based methods are proposed for the OS time prediction on multi-modal MRI problems. However, these methods usually fuse multi-modal information at the beginning or at the end of the deep learning networks and lack the fusion of features from different scales. In addition, the fusion at the end of networks always adapts global with global (eg. fully connected after concatenation of global average pooling output) or local with local (eg. bilinear pooling), which loses the information of local with global. In this paper, we propose a novel method for multi-modal OS time prediction of brain tumor patients, which contains an improved nonlocal features fusion module introduced on different scales. Our method obtains a relative 8.76% improvement over the current state-of-art method (0.6989 vs. 0.6426 on accuracy). Extensive testing demonstrates that our method could adapt to situations with missing modalities. The code is available at https://github.com/TangWen920812/mmmna-net.
RPLHR-CT Dataset and Transformer Baseline for Volumetric Super-Resolution from CT Scans
Jun 13, 2022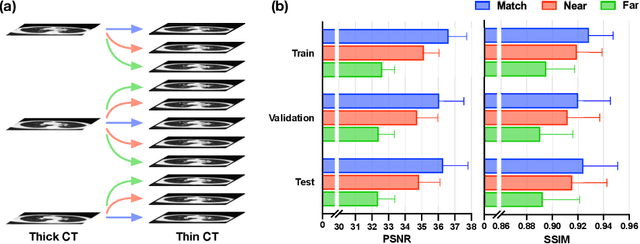
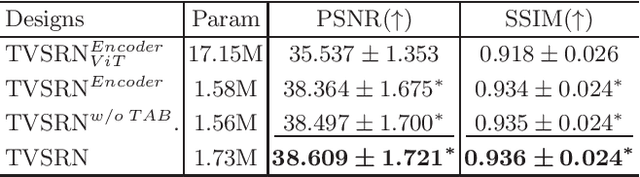
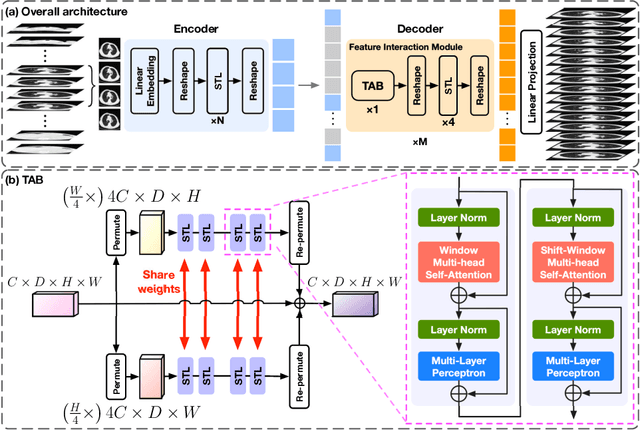
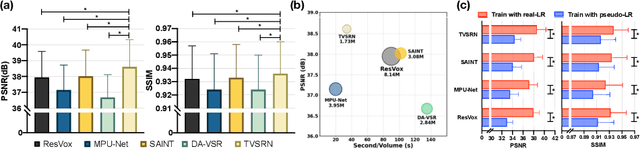
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used due to short acquisition time and lower storage cost. Nevertheless, the coarse resolution may lead to difficulties in medical diagnosis by either physicians or computer-aided diagnosis algorithms. Deep learning-based volumetric super-resolution (SR) methods are feasible ways to improve resolution, with convolutional neural networks (CNN) at their core. Despite recent progress, these methods are limited by inherent properties of convolution operators, which ignore content relevance and cannot effectively model long-range dependencies. In addition, most of the existing methods use pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a simple degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the poor performance of these methods in practice. In this paper, we build the first public real-paired dataset RPLHR-CT as a benchmark for volumetric SR, and provide baseline results by re-implementing four state-of-the-art CNN-based methods. Considering the inherent shortcoming of CNN, we also propose a transformer volumetric super-resolution network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. This is the first research to use a pure transformer for CT volumetric SR. The experimental results show that TVSRN significantly outperforms all baselines on both PSNR and SSIM. Moreover, the TVSRN method achieves a better trade-off between the image quality, the number of parameters, and the running time. Data and code are available at https://github.com/smilenaxx/RPLHR-CT.
Transformer Lesion Tracker
Jun 13, 2022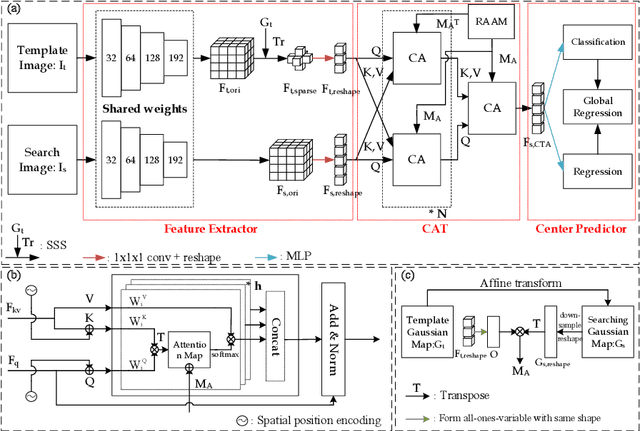
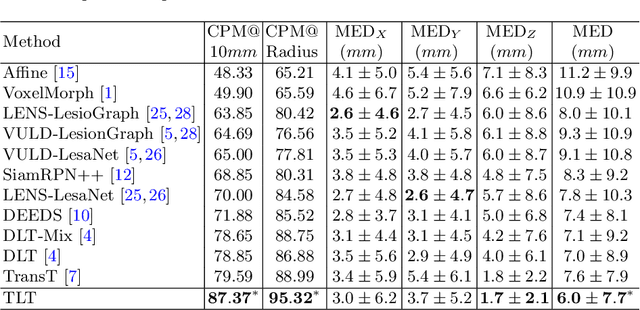
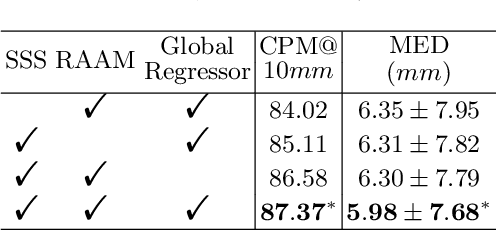

Evaluating lesion progression and treatment response via longitudinal lesion tracking plays a critical role in clinical practice. Automated approaches for this task are motivated by prohibitive labor costs and time consumption when lesion matching is done manually. Previous methods typically lack the integration of local and global information. In this work, we propose a transformer-based approach, termed Transformer Lesion Tracker (TLT). Specifically, we design a Cross Attention-based Transformer (CAT) to capture and combine both global and local information to enhance feature extraction. We also develop a Registration-based Anatomical Attention Module (RAAM) to introduce anatomical information to CAT so that it can focus on useful feature knowledge. A Sparse Selection Strategy (SSS) is presented for selecting features and reducing memory footprint in Transformer training. In addition, we use a global regression to further improve model performance. We conduct experiments on a public dataset to show the superiority of our method and find that our model performance has improved the average Euclidean center error by at least 14.3% (6mm vs. 7mm) compared with the state-of-the-art (SOTA). Code is available at https://github.com/TangWen920812/TLT.
MedFACT: Modeling Medical Feature Correlations in Patient Health Representation Learning via Feature Clustering
Apr 21, 2022
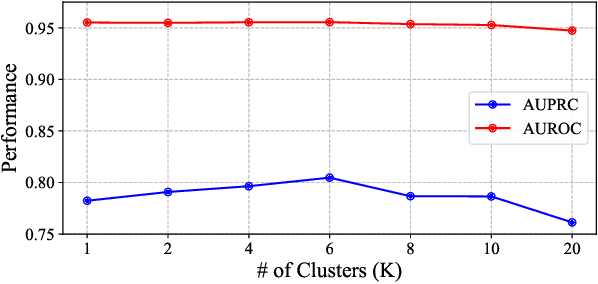
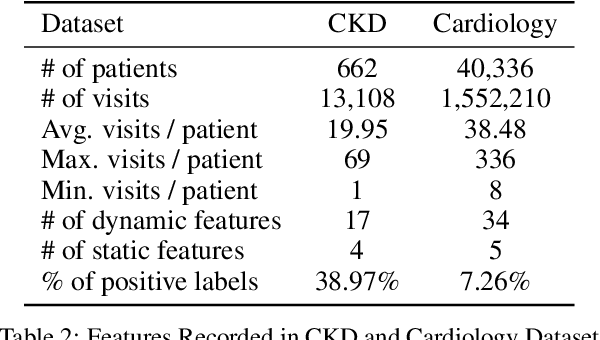
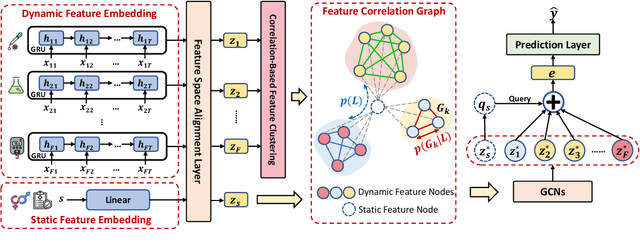
In healthcare prediction tasks, it is essential to exploit the correlations between medical features and learn better patient health representations. Existing methods try to estimate feature correlations only from data, or increase the quality of estimation by introducing task-specific medical knowledge. However, such methods either are difficult to estimate the feature correlations due to insufficient training samples, or cannot be generalized to other tasks due to reliance on specific knowledge. There are medical research revealing that not all the medical features are strongly correlated. Thus, to address the issues, we expect to group up strongly correlated features and learn feature correlations in a group-wise manner to reduce the learning complexity without losing generality. In this paper, we propose a general patient health representation learning framework MedFACT. We estimate correlations via measuring similarity between temporal patterns of medical features with kernel methods, and cluster features with strong correlations into groups. The feature group is further formulated as a correlation graph, and we employ graph convolutional networks to conduct group-wise feature interactions for better representation learning. Experiments on two real-world datasets demonstrate the superiority of MedFACT. The discovered medical findings are also confirmed by literature, providing valuable medical insights and explanations.
eProduct: A Million-Scale Visual Search Benchmark to Address Product Recognition Challenges
Jul 13, 2021
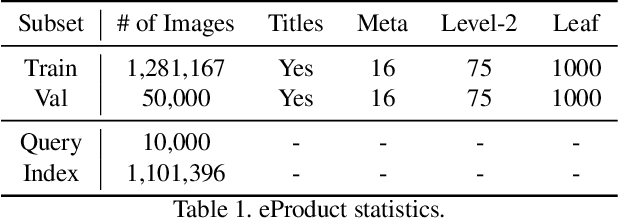
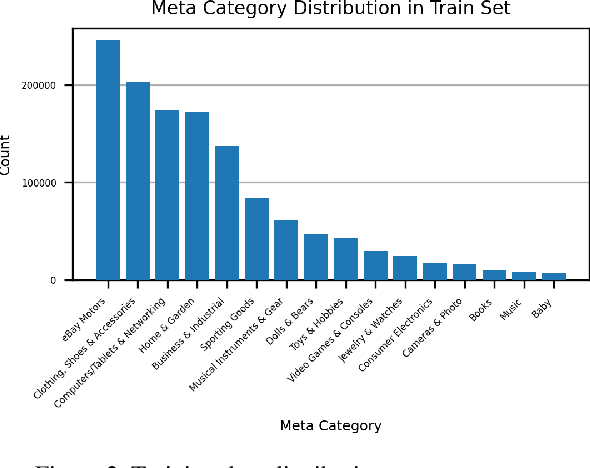
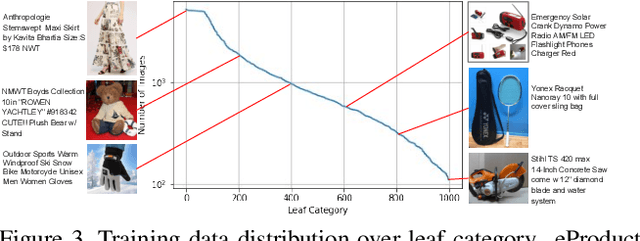
Large-scale product recognition is one of the major applications of computer vision and machine learning in the e-commerce domain. Since the number of products is typically much larger than the number of categories of products, image-based product recognition is often cast as a visual search rather than a classification problem. It is also one of the instances of super fine-grained recognition, where there are many products with slight or subtle visual differences. It has always been a challenge to create a benchmark dataset for training and evaluation on various visual search solutions in a real-world setting. This motivated creation of eProduct, a dataset consisting of 2.5 million product images towards accelerating development in the areas of self-supervised learning, weakly-supervised learning, and multimodal learning, for fine-grained recognition. We present eProduct as a training set and an evaluation set, where the training set contains 1.3M+ listing images with titles and hierarchical category labels, for model development, and the evaluation set includes 10,000 query and 1.1 million index images for visual search evaluation. We will present eProduct's construction steps, provide analysis about its diversity and cover the performance of baseline models trained on it.
De Re Updates
Jun 22, 2021In this paper, we propose a lightweight yet powerful dynamic epistemic logic that captures not only the distinction between de dicto and de re knowledge but also the distinction between de dicto and de re updates. The logic is based on the dynamified version of an epistemic language extended with the assignment operator borrowed from dynamic logic, following the work of Wang and Seligman (Proc. AiML 2018). We obtain complete axiomatizations for the counterparts of public announcement logic and event-model-based DEL based on new reduction axioms taking care of the interactions between dynamics and assignments.
* In Proceedings TARK 2021, arXiv:2106.10886
Deep Transform and Metric Learning Networks
Apr 21, 2021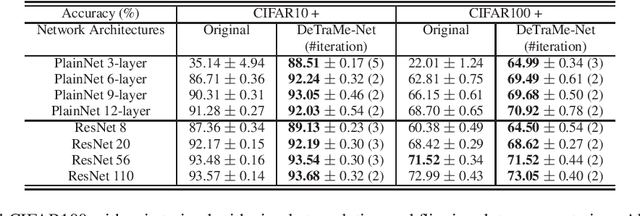
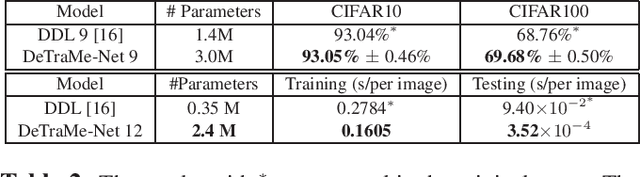
Based on its great successes in inference and denosing tasks, Dictionary Learning (DL) and its related sparse optimization formulations have garnered a lot of research interest. While most solutions have focused on single layer dictionaries, the recently improved Deep DL methods have also fallen short on a number of issues. We hence propose a novel Deep DL approach where each DL layer can be formulated and solved as a combination of one linear layer and a Recurrent Neural Network, where the RNN is flexibly regraded as a layer-associated learned metric. Our proposed work unveils new insights between the Neural Networks and Deep DL, and provides a novel, efficient and competitive approach to jointly learn the deep transforms and metrics. Extensive experiments are carried out to demonstrate that the proposed method can not only outperform existing Deep DL, but also state-of-the-art generic Convolutional Neural Networks.
CovidCare: Transferring Knowledge from Existing EMR to Emerging Epidemic for Interpretable Prognosis
Jul 17, 2020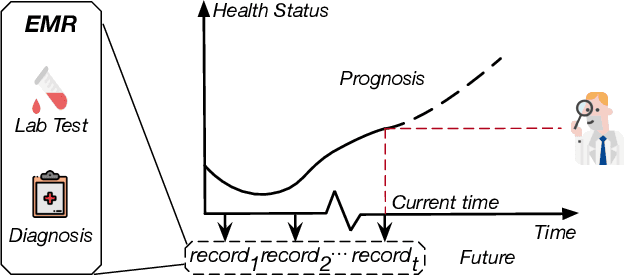

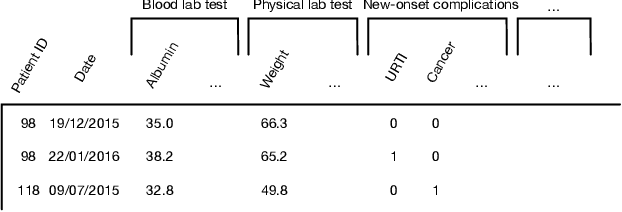
Due to the characteristics of COVID-19, the epidemic develops rapidly and overwhelms health service systems worldwide. Many patients suffer from systemic life-threatening problems and need to be carefully monitored in ICUs. Thus the intelligent prognosis is in an urgent need to assist physicians to take an early intervention, prevent the adverse outcome, and optimize the medical resource allocation. However, in the early stage of the epidemic outbreak, the data available for analysis is limited due to the lack of effective diagnostic mechanisms, rarity of the cases, and privacy concerns. In this paper, we propose a deep-learning-based approach, CovidCare, which leverages the existing electronic medical records to enhance the prognosis for inpatients with emerging infectious diseases. It learns to embed the COVID-19-related medical features based on massive existing EMR data via transfer learning. The transferred parameters are further trained to imitate the teacher model's representation behavior based on knowledge distillation, which embeds the health status more comprehensively in the source dataset. We conduct the length of stay prediction experiments for patients on a real-world COVID-19 dataset. The experiment results indicate that our proposed model consistently outperforms the comparative baseline methods. CovidCare also reveals that, 1) hs-cTnI, hs-CRP and Platelet Counts are the most fatal biomarkers, whose abnormal values usually indicate emergency adverse outcome. 2) Normal values of gamma-GT, AP and eGFR indicate the overall improvement of health. The medical findings extracted by CovidCare are empirically confirmed by human experts and medical literatures.
Deep Transform and Metric Learning Network: Wedding Deep Dictionary Learning and Neural Networks
Feb 18, 2020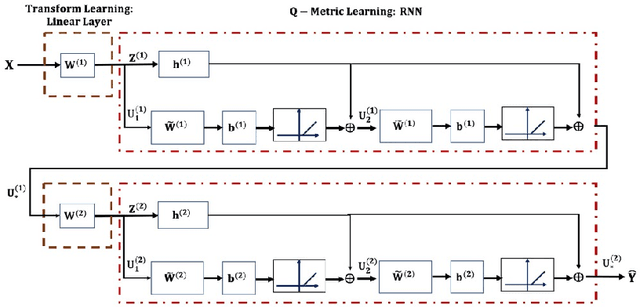
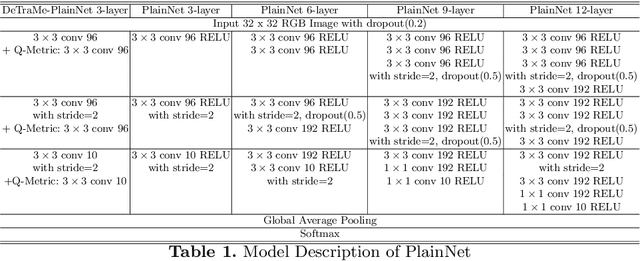
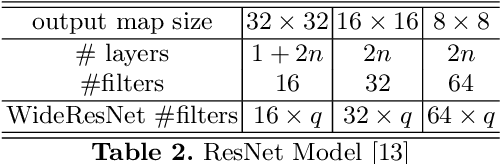
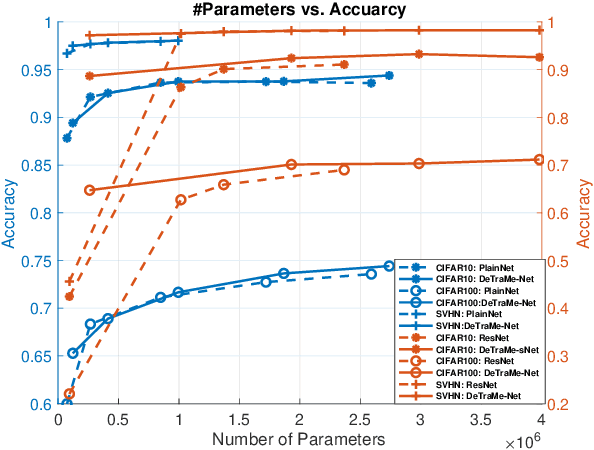
On account of its many successes in inference tasks and denoising applications, Dictionary Learning (DL) and its related sparse optimization problems have garnered a lot of research interest. While most solutions have focused on single layer dictionaries, the improved recently proposed Deep DL (DDL) methods have also fallen short on a number of issues. We propose herein, a novel DDL approach where each DL layer can be formulated as a combination of one linear layer and a Recurrent Neural Network (RNN). The RNN is shown to flexibly account for the layer-associated and learned metric. Our proposed work unveils new insights into Neural Networks and DDL and provides a new, efficient and competitive approach to jointly learn a deep transform and a metric for inference applications. Extensive experiments are carried out to demonstrate that the proposed method can not only outperform existing DDL but also state-of-the-art generic CNNs.
StageNet: Stage-Aware Neural Networks for Health Risk Prediction
Jan 24, 2020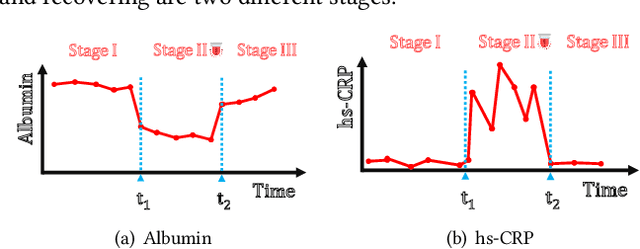
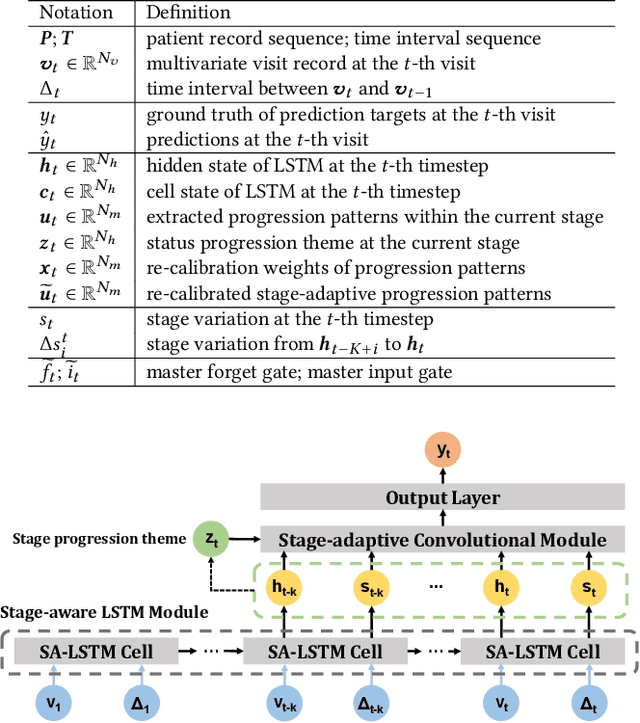
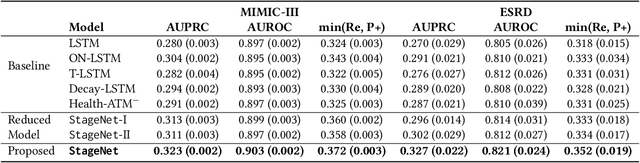
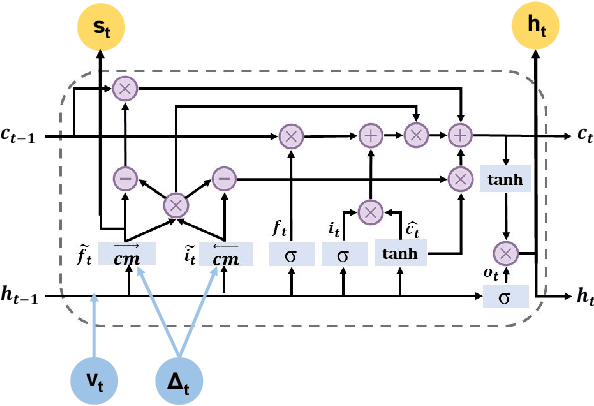
Deep learning has demonstrated success in health risk prediction especially for patients with chronic and progressing conditions. Most existing works focus on learning disease Network (StageNet) model to extract disease stage information from patient data and integrate it into risk prediction. StageNet is enabled by (1) a stage-aware long short-term memory (LSTM) module that extracts health stage variations unsupervisedly; (2) a stage-adaptive convolutional module that incorporates stage-related progression patterns into risk prediction. We evaluate StageNet on two real-world datasets and show that StageNet outperforms state-of-the-art models in risk prediction task and patient subtyping task. Compared to the best baseline model, StageNet achieves up to 12% higher AUPRC for risk prediction task on two real-world patient datasets. StageNet also achieves over 58% higher Calinski-Harabasz score (a cluster quality metric) for a patient subtyping task.