 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Mask: Query-driven Causal Masks for Text Anchoring in OCR-Oriented Vision-Language Models
Mar 31, 2026Optical Character Recognition (OCR) is increasingly regarded as a foundational capability for modern vision-language models (VLMs), enabling them not only to read text in images but also to support downstream reasoning in real-world visual question answering (VQA). However, practical applications further require reliable text anchors, i.e., accurately grounding queried text to its corresponding spatial region. To systematically evaluate this capability, we introduce TextAnchor-Bench (TABench), a benchmark for fine-grained text-region grounding, which reveals that both general-purpose and OCR-specific VLMs still struggle to establish accurate and stable text anchors. To address this limitation, we propose Q-Mask, a precise OCR framework built upon a causal query-driven mask decoder (CQMD). Inspired by chain-of-thought reasoning, Q-Mask performs causal visual decoding that sequentially generates query-conditioned visual masks before producing the final OCR output. This visual CoT paradigm disentangles where the text is from what the text is, enforcing grounded evidence acquisition prior to recognition and enabling explicit text anchor construction during inference. To train CQMD, we construct TextAnchor-26M, a large-scale dataset of image-text pairs annotated with fine-grained masks corresponding to specific textual elements, encouraging stable text-region correspondences and injecting strong spatial priors into VLM training. Extensive experiments demonstrate that Q-Mask substantially improves text anchoring and understanding across diverse visual scenes.
Enhancing Topic Interpretability for Neural Topic Modeling through Topic-wise Contrastive Learning
Dec 23, 2024Data mining and knowledge discovery are essential aspects of extracting valuable insights from vast datasets. Neural topic models (NTMs) have emerged as a valuable unsupervised tool in this field. However, the predominant objective in NTMs, which aims to discover topics maximizing data likelihood, often lacks alignment with the central goals of data mining and knowledge discovery which is to reveal interpretable insights from large data repositories. Overemphasizing likelihood maximization without incorporating topic regularization can lead to an overly expansive latent space for topic modeling. In this paper, we present an innovative approach to NTMs that addresses this misalignment by introducing contrastive learning measures to assess topic interpretability. We propose a novel NTM framework, named ContraTopic, that integrates a differentiable regularizer capable of evaluating multiple facets of topic interpretability throughout the training process. Our regularizer adopts a unique topic-wise contrastive methodology, fostering both internal coherence within topics and clear external distinctions among them. Comprehensive experiments conducted on three diverse datasets demonstrate that our approach consistently produces topics with superior interpretability compared to state-of-the-art NTMs.
MedFACT: Modeling Medical Feature Correlations in Patient Health Representation Learning via Feature Clustering
Apr 21, 2022
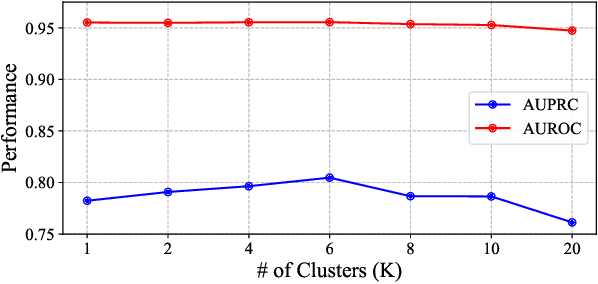
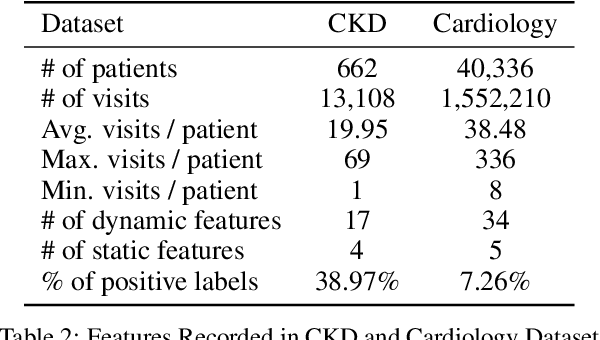
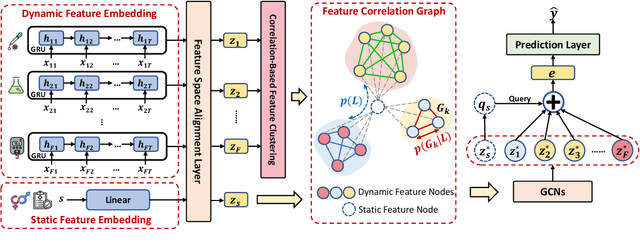
In healthcare prediction tasks, it is essential to exploit the correlations between medical features and learn better patient health representations. Existing methods try to estimate feature correlations only from data, or increase the quality of estimation by introducing task-specific medical knowledge. However, such methods either are difficult to estimate the feature correlations due to insufficient training samples, or cannot be generalized to other tasks due to reliance on specific knowledge. There are medical research revealing that not all the medical features are strongly correlated. Thus, to address the issues, we expect to group up strongly correlated features and learn feature correlations in a group-wise manner to reduce the learning complexity without losing generality. In this paper, we propose a general patient health representation learning framework MedFACT. We estimate correlations via measuring similarity between temporal patterns of medical features with kernel methods, and cluster features with strong correlations into groups. The feature group is further formulated as a correlation graph, and we employ graph convolutional networks to conduct group-wise feature interactions for better representation learning. Experiments on two real-world datasets demonstrate the superiority of MedFACT. The discovered medical findings are also confirmed by literature, providing valuable medical insights and explanations.