 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Value-Based Offline RL under Realizability and Partial Coverage
Feb 05, 2023In offline reinforcement learning (RL) we have no opportunity to explore so we must make assumptions that the data is sufficient to guide picking a good policy, taking the form of assuming some coverage, realizability, Bellman completeness, and/or hard margin (gap). In this work we propose value-based algorithms for offline RL with PAC guarantees under just partial coverage, specifically, coverage of just a single comparator policy, and realizability of soft (entropy-regularized) Q-function of the single policy and a related function defined as a saddle point of certain minimax optimization problem. This offers refined and generally more lax conditions for offline RL. We further show an analogous result for vanilla Q-functions under a soft margin condition. To attain these guarantees, we leverage novel minimax learning algorithms to accurately estimate soft or vanilla Q-functions with $L^2$-convergence guarantees. Our algorithms' loss functions arise from casting the estimation problems as nonlinear convex optimization problems and Lagrangifying.
Hybrid RL: Using Both Offline and Online Data Can Make RL Efficient
Oct 13, 2022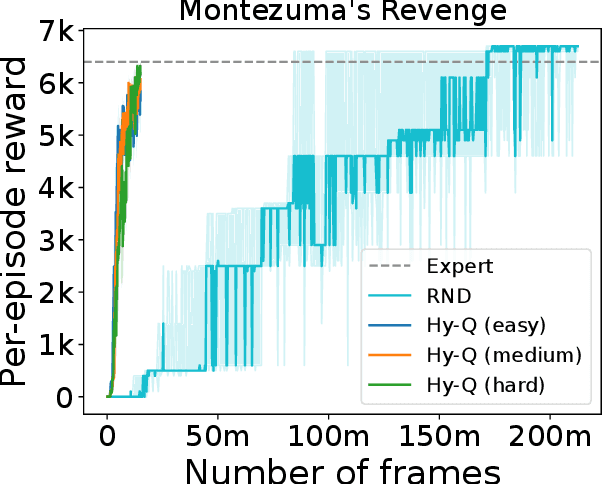
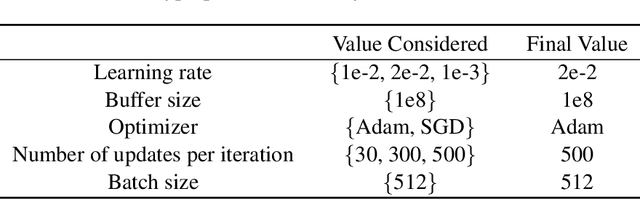
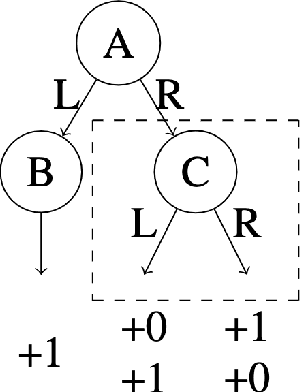
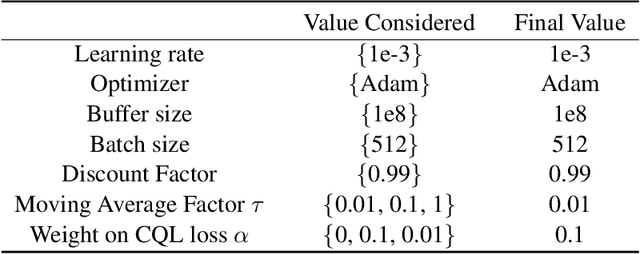
We consider a hybrid reinforcement learning setting (Hybrid RL), in which an agent has access to an offline dataset and the ability to collect experience via real-world online interaction. The framework mitigates the challenges that arise in both pure offline and online RL settings, allowing for the design of simple and highly effective algorithms, in both theory and practice. We demonstrate these advantages by adapting the classical Q learning/iteration algorithm to the hybrid setting, which we call Hybrid Q-Learning or Hy-Q. In our theoretical results, we prove that the algorithm is both computationally and statistically efficient whenever the offline dataset supports a high-quality policy and the environment has bounded bilinear rank. Notably, we require no assumptions on the coverage provided by the initial distribution, in contrast with guarantees for policy gradient/iteration methods. In our experimental results, we show that Hy-Q with neural network function approximation outperforms state-of-the-art online, offline, and hybrid RL baselines on challenging benchmarks, including Montezuma's Revenge.
Sample-efficient Safe Learning for Online Nonlinear Control with Control Barrier Functions
Jul 29, 2022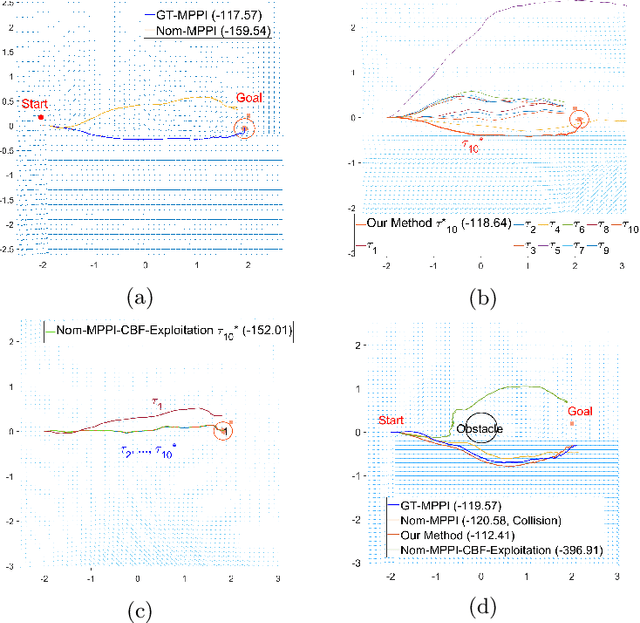
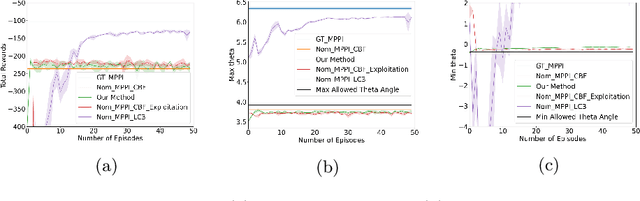
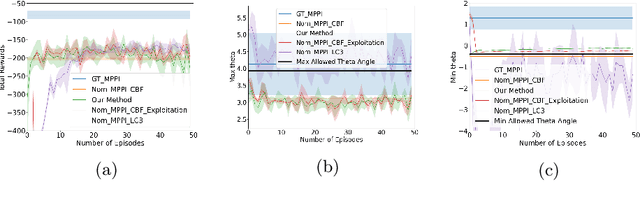
Reinforcement Learning (RL) and continuous nonlinear control have been successfully deployed in multiple domains of complicated sequential decision-making tasks. However, given the exploration nature of the learning process and the presence of model uncertainty, it is challenging to apply them to safety-critical control tasks due to the lack of safety guarantee. On the other hand, while combining control-theoretical approaches with learning algorithms has shown promise in safe RL applications, the sample efficiency of safe data collection process for control is not well addressed. In this paper, we propose a \emph{provably} sample efficient episodic safe learning framework for online control tasks that leverages safe exploration and exploitation in an unknown, nonlinear dynamical system. In particular, the framework 1) extends control barrier functions (CBFs) in a stochastic setting to achieve provable high-probability safety under uncertainty during model learning and 2) integrates an optimism-based exploration strategy to efficiently guide the safe exploration process with learned dynamics for \emph{near optimal} control performance. We provide formal analysis on the episodic regret bound against the optimal controller and probabilistic safety with theoretical guarantees. Simulation results are provided to demonstrate the effectiveness and efficiency of the proposed algorithm.
Future-Dependent Value-Based Off-Policy Evaluation in POMDPs
Jul 26, 2022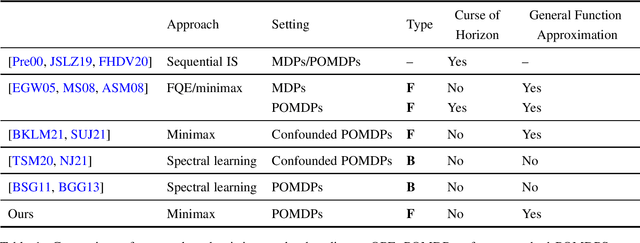
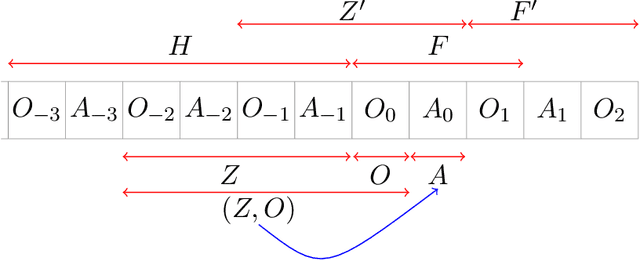
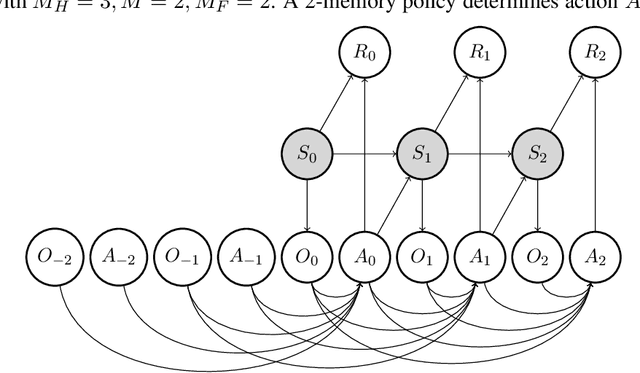
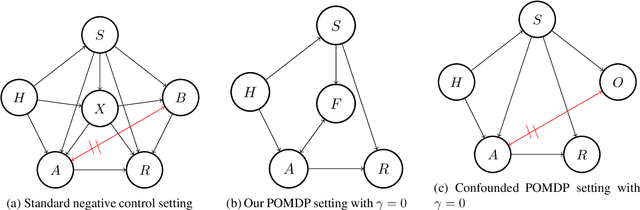
We study off-policy evaluation (OPE) for partially observable MDPs (POMDPs) with general function approximation. Existing methods such as sequential importance sampling estimators and fitted-Q evaluation suffer from the curse of horizon in POMDPs. To circumvent this problem, we develop a novel model-free OPE method by introducing future-dependent value functions that take future proxies as inputs. Future-dependent value functions play similar roles as classical value functions in fully-observable MDPs. We derive a new Bellman equation for future-dependent value functions as conditional moment equations that use history proxies as instrumental variables. We further propose a minimax learning method to learn future-dependent value functions using the new Bellman equation. We obtain the PAC result, which implies our OPE estimator is consistent as long as futures and histories contain sufficient information about latent states, and the Bellman completeness. Finally, we extend our methods to learning of dynamics and establish the connection between our approach and the well-known spectral learning methods in POMDPs.
PAC Reinforcement Learning for Predictive State Representations
Jul 15, 2022
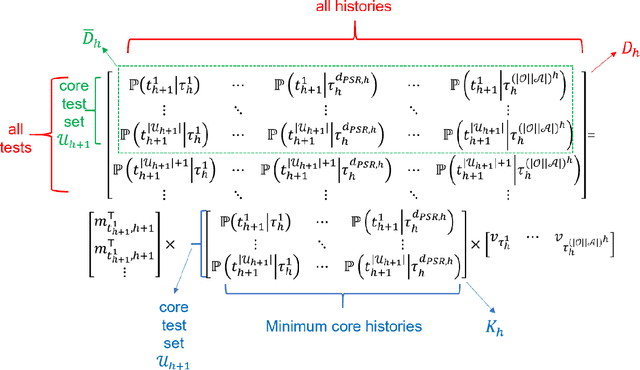


In this paper we study online Reinforcement Learning (RL) in partially observable dynamical systems. We focus on the Predictive State Representations (PSRs) model, which is an expressive model that captures other well-known models such as Partially Observable Markov Decision Processes (POMDP). PSR represents the states using a set of predictions of future observations and is defined entirely using observable quantities. We develop a novel model-based algorithm for PSRs that can learn a near optimal policy in sample complexity scaling polynomially with respect to all the relevant parameters of the systems. Our algorithm naturally works with function approximation to extend to systems with potentially large state and observation spaces. We show that given a realizable model class, the sample complexity of learning the near optimal policy only scales polynomially with respect to the statistical complexity of the model class, without any explicit polynomial dependence on the size of the state and observation spaces. Notably, our work is the first work that shows polynomial sample complexities to compete with the globally optimal policy in PSRs. Finally, we demonstrate how our general theorem can be directly used to derive sample complexity bounds for special models including $m$-step weakly revealing and $m$-step decodable tabular POMDPs, POMDPs with low-rank latent transition, and POMDPs with linear emission and latent transition.
Learning Bellman Complete Representations for Offline Policy Evaluation
Jul 12, 2022
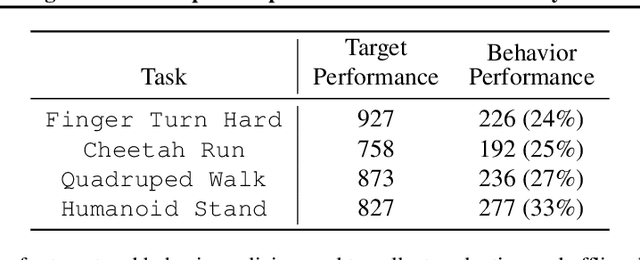

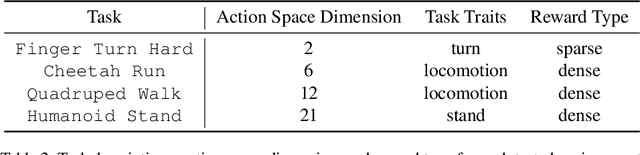
We study representation learning for Offline Reinforcement Learning (RL), focusing on the important task of Offline Policy Evaluation (OPE). Recent work shows that, in contrast to supervised learning, realizability of the Q-function is not enough for learning it. Two sufficient conditions for sample-efficient OPE are Bellman completeness and coverage. Prior work often assumes that representations satisfying these conditions are given, with results being mostly theoretical in nature. In this work, we propose BCRL, which directly learns from data an approximately linear Bellman complete representation with good coverage. With this learned representation, we perform OPE using Least Square Policy Evaluation (LSPE) with linear functions in our learned representation. We present an end-to-end theoretical analysis, showing that our two-stage algorithm enjoys polynomial sample complexity provided some representation in the rich class considered is linear Bellman complete. Empirically, we extensively evaluate our algorithm on challenging, image-based continuous control tasks from the Deepmind Control Suite. We show our representation enables better OPE compared to previous representation learning methods developed for off-policy RL (e.g., CURL, SPR). BCRL achieve competitive OPE error with the state-of-the-art method Fitted Q-Evaluation (FQE), and beats FQE when evaluating beyond the initial state distribution. Our ablations show that both linear Bellman complete and coverage components of our method are crucial.
* Accepted for Long Talk at ICML 2022
Computationally Efficient PAC RL in POMDPs with Latent Determinism and Conditional Embeddings
Jun 24, 2022
We study reinforcement learning with function approximation for large-scale Partially Observable Markov Decision Processes (POMDPs) where the state space and observation space are large or even continuous. Particularly, we consider Hilbert space embeddings of POMDP where the feature of latent states and the feature of observations admit a conditional Hilbert space embedding of the observation emission process, and the latent state transition is deterministic. Under the function approximation setup where the optimal latent state-action $Q$-function is linear in the state feature, and the optimal $Q$-function has a gap in actions, we provide a \emph{computationally and statistically efficient} algorithm for finding the \emph{exact optimal} policy. We show our algorithm's computational and statistical complexities scale polynomially with respect to the horizon and the intrinsic dimension of the feature on the observation space. Furthermore, we show both the deterministic latent transitions and gap assumptions are necessary to avoid statistical complexity exponential in horizon or dimension. Since our guarantee does not have an explicit dependence on the size of the state and observation spaces, our algorithm provably scales to large-scale POMDPs.
Provably Efficient Reinforcement Learning in Partially Observable Dynamical Systems
Jun 24, 2022
We study Reinforcement Learning for partially observable dynamical systems using function approximation. We propose a new \textit{Partially Observable Bilinear Actor-Critic framework}, that is general enough to include models such as observable tabular Partially Observable Markov Decision Processes (POMDPs), observable Linear-Quadratic-Gaussian (LQG), Predictive State Representations (PSRs), as well as a newly introduced model Hilbert Space Embeddings of POMDPs and observable POMDPs with latent low-rank transition. Under this framework, we propose an actor-critic style algorithm that is capable of performing agnostic policy learning. Given a policy class that consists of memory based policies (that look at a fixed-length window of recent observations), and a value function class that consists of functions taking both memory and future observations as inputs, our algorithm learns to compete against the best memory-based policy in the given policy class. For certain examples such as undercomplete observable tabular POMDPs, observable LQGs and observable POMDPs with latent low-rank transition, by implicitly leveraging their special properties, our algorithm is even capable of competing against the globally optimal policy without paying an exponential dependence on the horizon in its sample complexity.
Minimum Noticeable Difference based Adversarial Privacy Preserving Image Generation
Jun 17, 2022
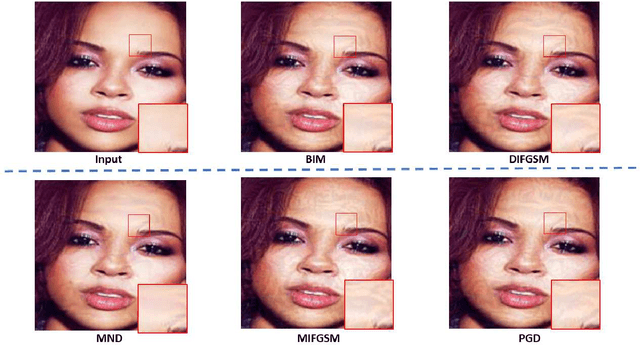
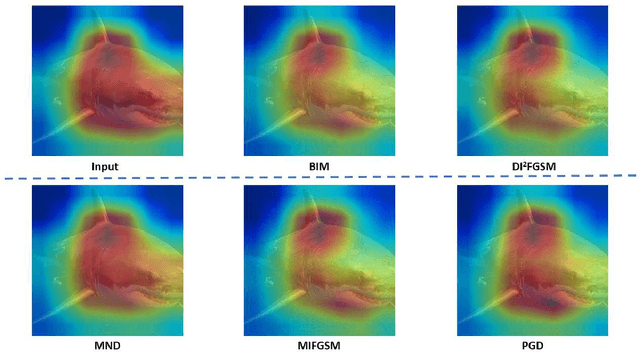

Deep learning models are found to be vulnerable to adversarial examples, as wrong predictions can be caused by small perturbation in input for deep learning models. Most of the existing works of adversarial image generation try to achieve attacks for most models, while few of them make efforts on guaranteeing the perceptual quality of the adversarial examples. High quality adversarial examples matter for many applications, especially for the privacy preserving. In this work, we develop a framework based on the Minimum Noticeable Difference (MND) concept to generate adversarial privacy preserving images that have minimum perceptual difference from the clean ones but are able to attack deep learning models. To achieve this, an adversarial loss is firstly proposed to make the deep learning models attacked by the adversarial images successfully. Then, a perceptual quality-preserving loss is developed by taking the magnitude of perturbation and perturbation-caused structural and gradient changes into account, which aims to preserve high perceptual quality for adversarial image generation. To the best of our knowledge, this is the first work on exploring quality-preserving adversarial image generation based on the MND concept for privacy preserving. To evaluate its performance in terms of perceptual quality, the deep models on image classification and face recognition are tested with the proposed method and several anchor methods in this work. Extensive experimental results demonstrate that the proposed MND framework is capable of generating adversarial images with remarkably improved performance metrics (e.g., PSNR, SSIM, and MOS) than that generated with the anchor methods.
Provable Benefits of Representational Transfer in Reinforcement Learning
May 29, 2022

We study the problem of representational transfer in RL, where an agent first pretrains in a number of source tasks to discover a shared representation, which is subsequently used to learn a good policy in a target task. We propose a new notion of task relatedness between source and target tasks, and develop a novel approach for representational transfer under this assumption. Concretely, we show that given generative access to source tasks, we can discover a representation, using which subsequent linear RL techniques quickly converge to a near-optimal policy, with only online access to the target task. The sample complexity is close to knowing the ground truth features in the target task, and comparable to prior representation learning results in the source tasks. We complement our positive results with lower bounds without generative access, and validate our findings with empirical evaluation on rich observation MDPs that require deep exploration.