 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shots to Stories: LLM-Assisted Video Editing with Unified Language Representations
May 18, 2025Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated remarkable reasoning and generalization capabilities in video understanding; however, their application in video editing remains largely underexplored. This paper presents the first systematic study of LLMs in the context of video editing. To bridge the gap between visual information and language-based reasoning, we introduce L-Storyboard, an intermediate representation that transforms discrete video shots into structured language descriptions suitable for LLM processing. We categorize video editing tasks into Convergent Tasks and Divergent Tasks, focusing on three core tasks: Shot Attributes Classification, Next Shot Selection, and Shot Sequence Ordering. To address the inherent instability of divergent task outputs, we propose the StoryFlow strategy, which converts the divergent multi-path reasoning process into a convergent selection mechanism, effectively enhancing task accuracy and logical coherence. Experimental results demonstrate that L-Storyboard facilitates a more robust mapping between visual information and language descriptions, significantly improving the interpretability and privacy protection of video editing tasks. Furthermore, StoryFlow enhances the logical consistency and output stability in Shot Sequence Ordering, underscoring the substantial potential of LLMs in intelligent video editing.
Mitigating Hallucinations on Object Attributes using Multiview Images and Negative Instructions
Jan 17, 2025
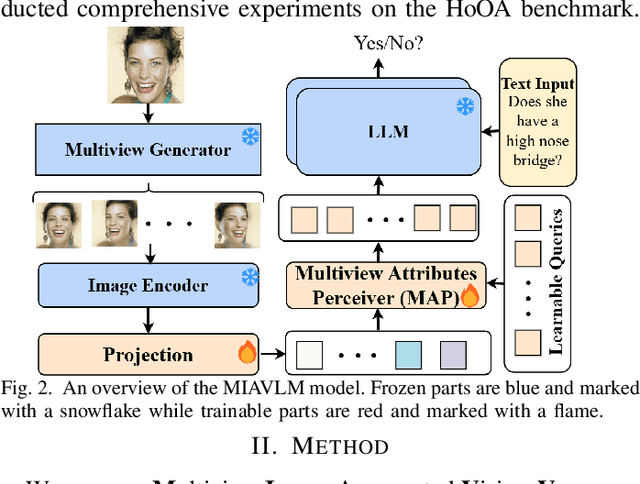


Current popular Large Vision-Language Models (LVLMs) are suffering from Hallucinations on Object Attributes (HoOA), leading to incorrect determination of fine-grained attributes in the input images. Leveraging significant advancements in 3D generation from a single image, this paper proposes a novel method to mitigate HoOA in LVLMs. This method utilizes multiview images sampled from generated 3D representations as visual prompts for LVLMs, thereby providing more visual information from other viewpoints. Furthermore, we observe the input order of multiple multiview images significantly affects the performance of LVLMs. Consequently, we have devised Multiview Image Augmented VLM (MIAVLM), incorporating a Multiview Attributes Perceiver (MAP) submodule capable of simultaneously eliminating the influence of input image order and aligning visual information from multiview images with Large Language Models (LLMs). Besides, we designed and employed negative instructions to mitigate LVLMs' bias towards ``Yes" responses. Comprehensive experiments demonstrate the effectiveness of our method.