 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGIGEN: Logic-Driven Generation of Verifiable Agentic Tasks
Feb 28, 2026The evolution of Large Language Models (LLMs) from static instruction-followers to autonomous agents necessitates operating within complex, stateful environments to achieve precise state-transition objectives. However, this paradigm is bottlenecked by data scarcity, as existing tool-centric reverse-synthesis pipelines fail to capture the rigorous logic of real-world applications. We introduce \textbf{LOGIGEN}, a logic-driven framework that synthesizes verifiable training data based on three core pillars: \textbf{Hard-Compiled Policy Grounding}, \textbf{Logic-Driven Forward Synthesis}, and \textbf{Deterministic State Verification}. Specifically, a Triple-Agent Orchestration is employed: the \textbf{Architect} compiles natural-language policy into database constraints to enforce hard rules; the \textbf{Set Designer} initializes boundary-adjacent states to trigger critical policy conflicts; and the \textbf{Explorer} searches this environment to discover causal solution paths. This framework yields a dataset of 20,000 complex tasks across 8 domains, where validity is strictly guaranteed by checking exact state equivalence. Furthermore, we propose a verification-based training protocol where Supervised Fine-Tuning (SFT) on verifiable trajectories establishes compliance with hard-compiled policy, while Reinforcement Learning (RL) guided by dense state-rewards refines long-horizon goal achievement. On $τ^2$-Bench, LOGIGEN-32B(RL) achieves a \textbf{79.5\% success rate}, substantially outperforming the base model (40.7\%). These results demonstrate that logic-driven synthesis combined with verification-based training effectively constructs the causally valid trajectories needed for next-generation agents.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
Safe Medicine Recommendation via Medical Knowledge Graph Embedding
Oct 26, 2017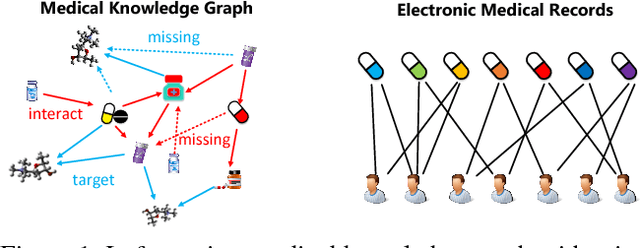
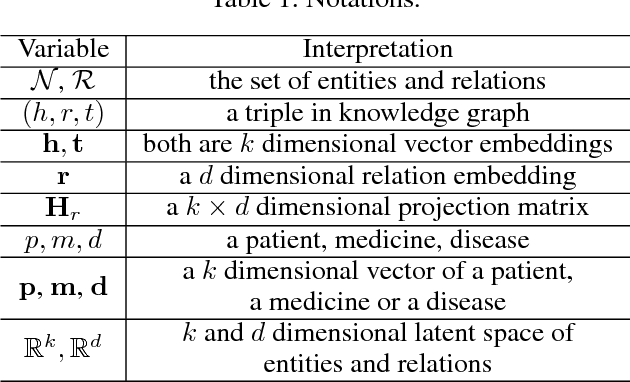
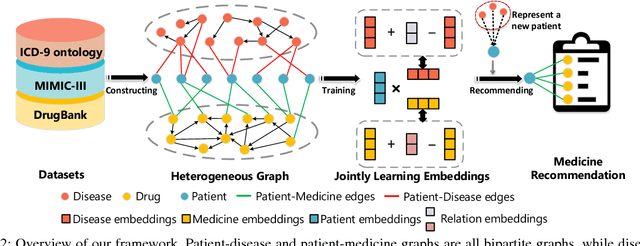
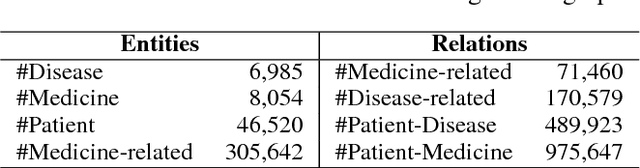
Most of the existing medicine recommendation systems that are mainly based on electronic medical records (EMRs) are significantly assisting doctors to make better clinical decisions benefiting both patients and caregivers. Even though the growth of EMRs is at a lighting fast speed in the era of big data, content limitations in EMRs restrain the existed recommendation systems to reflect relevant medical facts, such as drug-drug interactions. Many medical knowledge graphs that contain drug-related information, such as DrugBank, may give hope for the recommendation systems. However, the direct use of these knowledge graphs in the systems suffers from robustness caused by the incompleteness of the graphs. To address these challenges, we stand on recent advances in graph embedding learning techniques and propose a novel framework, called Safe Medicine Recommendation (SMR), in this paper. Specifically, SMR first constructs a high-quality heterogeneous graph by bridging EMRs (MIMIC-III) and medical knowledge graphs (ICD-9 ontology and DrugBank). Then, SMR jointly embeds diseases, medicines, patients, and their corresponding relations into a shared lower dimensional space. Finally, SMR uses the embeddings to decompose the medicine recommendation into a link prediction process while considering the patient's diagnoses and adverse drug reactions. To our best knowledge, SMR is the first to learn embeddings of a patient-disease-medicine graph for medicine recommendation in the world. Extensive experiments on real datasets are conducted to evaluate the effectiveness of proposed framework.