 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Detecting Hallucinations in Neural Machine Translation via Model Introspection
Jan 18, 2023Neural sequence generation models are known to "hallucinate", by producing outputs that are unrelated to the source text. These hallucinations are potentially harmful, yet it remains unclear in what conditions they arise and how to mitigate their impact. In this work, we first identify internal model symptoms of hallucinations by analyzing the relative token contributions to the generation in contrastive hallucinated vs. non-hallucinated outputs generated via source perturbations. We then show that these symptoms are reliable indicators of natural hallucinations, by using them to design a lightweight hallucination detector which outperforms both model-free baselines and strong classifiers based on quality estimation or large pre-trained models on manually annotated English-Chinese and German-English translation test beds.
Recognition and Co-Analysis of Pedestrian Activities in Different Parts of Road using Traffic Camera Video
Nov 27, 2021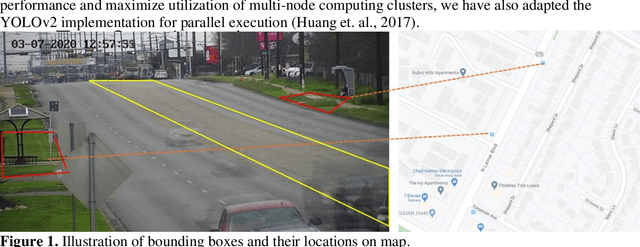


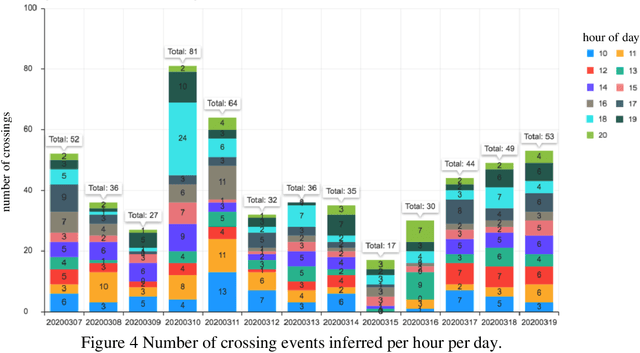
Pedestrian safety is a priority for transportation system managers and operators, and a main focus of the Vision Zero strategy employed by the City of Austin, Texas. While there are a number of treatments and technologies to effectively improve pedestrian safety, identifying the location where these treatments are most needed remains a challenge. Current practice requires manual observation of candidate locations for limited time periods, leading to an identification process that is time consuming, lags behind traffic pattern changes over time, and lacks scalability. Mid-block locations, where safety countermeasures are often needed the most, are especially hard to identify and monitor. The goal for this research is to understand the correlation between bus stop locations and mid-block crossings, so as to assist traffic engineers in implementing Vision Zero strategies to improve pedestrian safety. In a prior work, we have developed a tool to detect pedestrian crossing events with traffic camera video using a deep neural network model to identify crossing events. In this paper, we extend the methods to identify bus stop usage with traffic camera video from off-the-shelf CCTV pan-tilt-zoom (PTZ) traffic monitoring cameras installed at nearby intersections. We correlate the video detection results for mid-block crossings near a bus stop, with pedestrian activity at the bus stops in each side of the mid-block crossing. We also implement a web portal to facilitate manual review of pedestrian activity detections by automating creation of video clips that show only crossing events, thereby vastly improving the efficiency of the human review process.
Rule-based Morphological Inflection Improves Neural Terminology Translation
Sep 10, 2021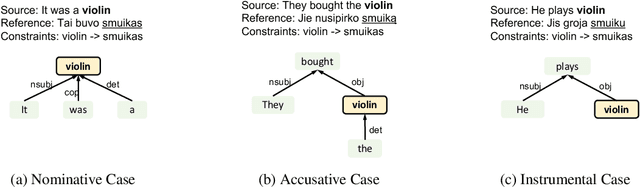
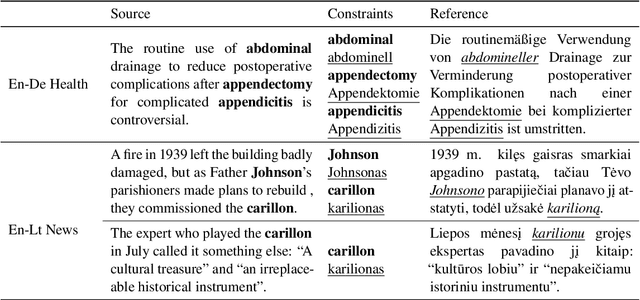
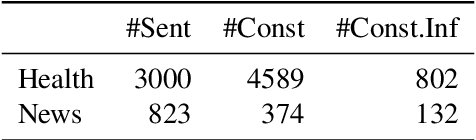
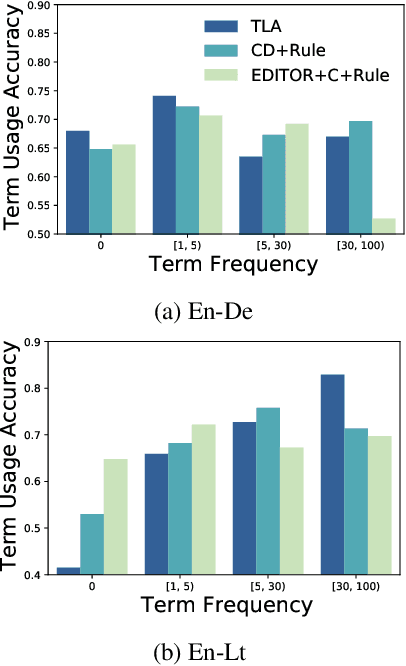
Current approaches to incorporating terminology constraints in machine translation (MT) typically assume that the constraint terms are provided in their correct morphological forms. This limits their application to real-world scenarios where constraint terms are provided as lemmas. In this paper, we introduce a modular framework for incorporating lemma constraints in neural MT (NMT) in which linguistic knowledge and diverse types of NMT models can be flexibly applied. It is based on a novel cross-lingual inflection module that inflects the target lemma constraints based on the source context. We explore linguistically motivated rule-based and data-driven neural-based inflection modules and design English-German health and English-Lithuanian news test suites to evaluate them in domain adaptation and low-resource MT settings. Results show that our rule-based inflection module helps NMT models incorporate lemma constraints more accurately than a neural module and outperforms the existing end-to-end approach with lower training costs.
Soft Layer Selection with Meta-Learning for Zero-Shot Cross-Lingual Transfer
Jul 21, 2021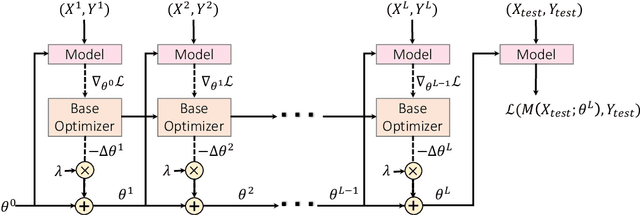
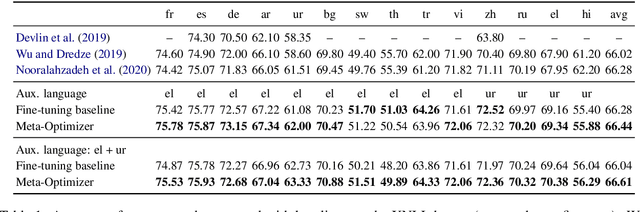

Multilingual pre-trained contextual embedding models (Devlin et al., 2019) have achieved impressive performance on zero-shot cross-lingual transfer tasks. Finding the most effective fine-tuning strategy to fine-tune these models on high-resource languages so that it transfers well to the zero-shot languages is a non-trivial task. In this paper, we propose a novel meta-optimizer to soft-select which layers of the pre-trained model to freeze during fine-tuning. We train the meta-optimizer by simulating the zero-shot transfer scenario. Results on cross-lingual natural language inference show that our approach improves over the simple fine-tuning baseline and X-MAML (Nooralahzadeh et al., 2020).
How Does Distilled Data Complexity Impact the Quality and Confidence of Non-Autoregressive Machine Translation?
May 27, 2021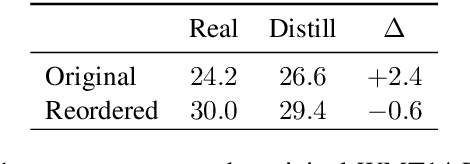
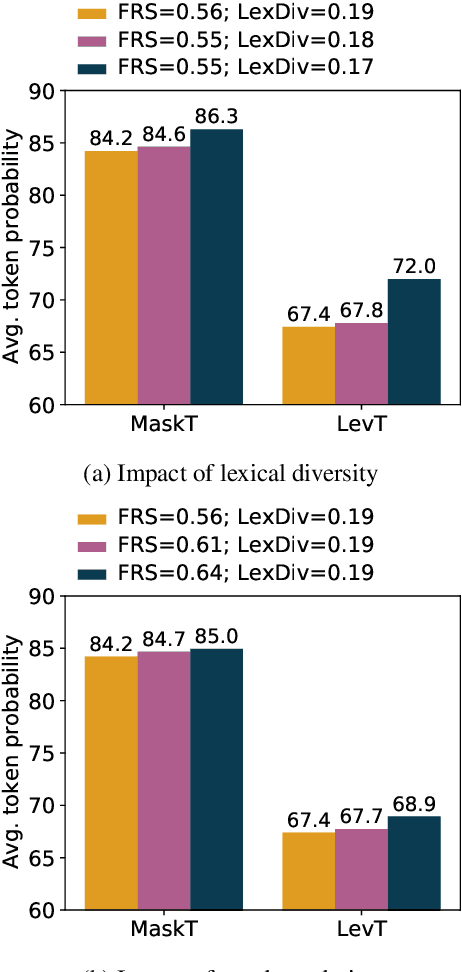
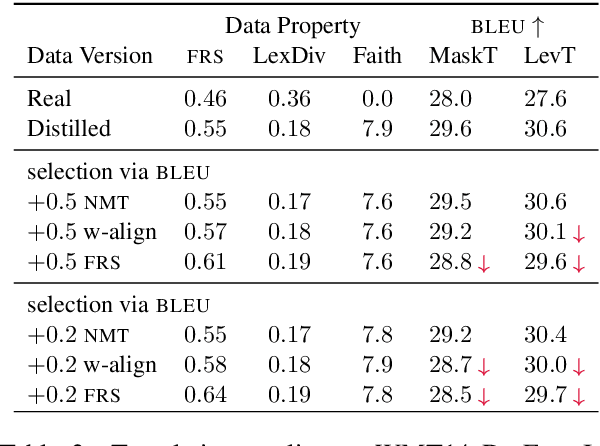
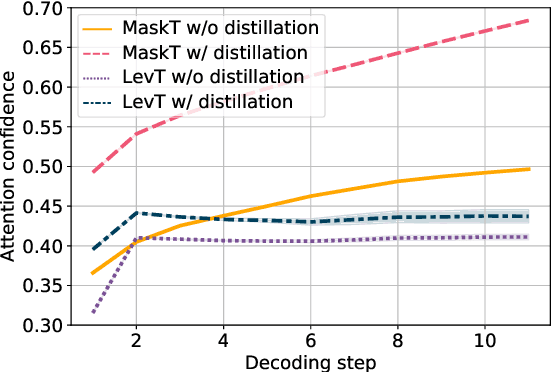
While non-autoregressive (NAR) models are showing great promise for machine translation, their use is limited by their dependence on knowledge distillation from autoregressive models. To address this issue, we seek to understand why distillation is so effective. Prior work suggests that distilled training data is less complex than manual translations. Based on experiments with the Levenshtein Transformer and the Mask-Predict NAR models on the WMT14 German-English task, this paper shows that different types of complexity have different impacts: while reducing lexical diversity and decreasing reordering complexity both help NAR learn better alignment between source and target, and thus improve translation quality, lexical diversity is the main reason why distillation increases model confidence, which affects the calibration of different NAR models differently.
EDITOR: an Edit-Based Transformer with Repositioning for Neural Machine Translation with Soft Lexical Constraints
Nov 13, 2020
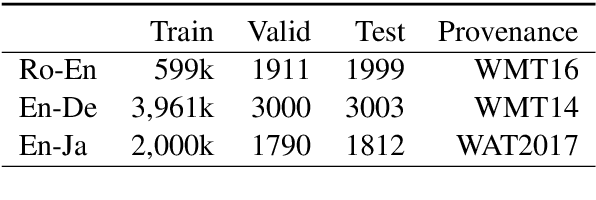
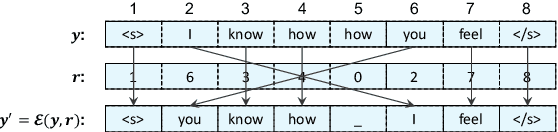
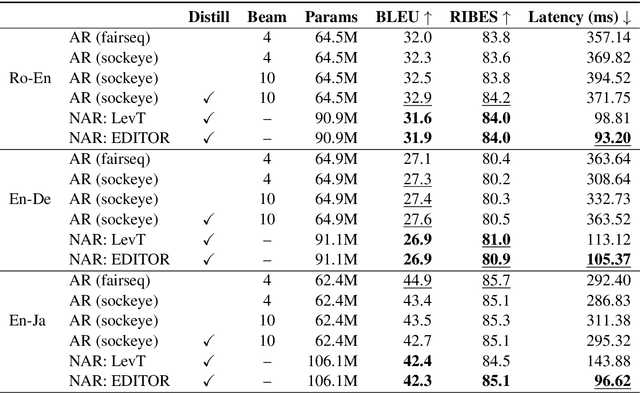
We introduce an Edit-Based Transformer with Repositioning (EDITOR), which makes sequence generation flexible by seamlessly allowing users to specify preferences in output lexical choice. Building on recent models for non-autoregressive sequence generation (Gu et al., 2019), EDITOR generates new sequences by iteratively editing hypotheses. It relies on a novel reposition operation designed to disentangle lexical choice from word positioning decisions, while enabling efficient oracles for imitation learning and parallel edits at decoding time. Empirically, EDITOR uses soft lexical constraints more effectively than the Levenshtein Transformer (Gu et al., 2019) while speeding up decoding dramatically compared to constrained beam search (Post and Vilar, 2018). EDITOR also achieves comparable or better translation quality with faster decoding speed than the Levenshtein Transformer on standard Romanian-English, English-German, and English-Japanese machine translation tasks.
Dual Reconstruction: a Unifying Objective for Semi-Supervised Neural Machine Translation
Oct 07, 2020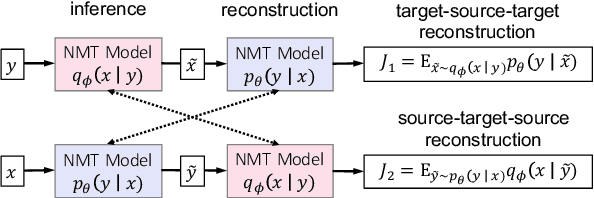

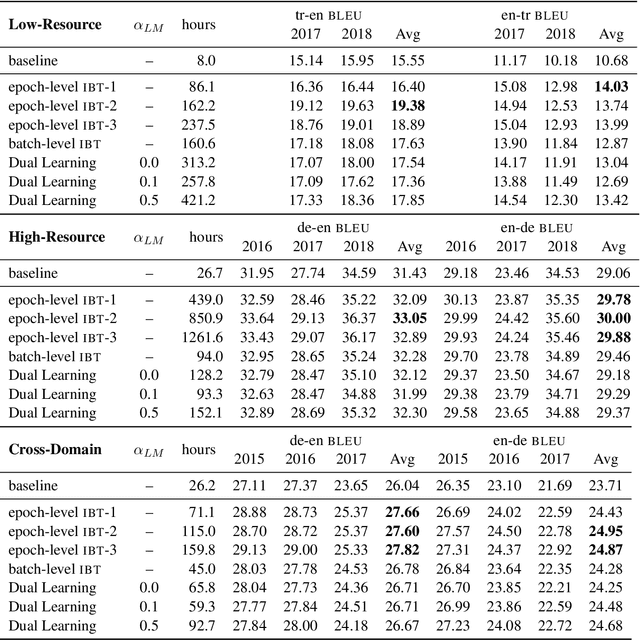
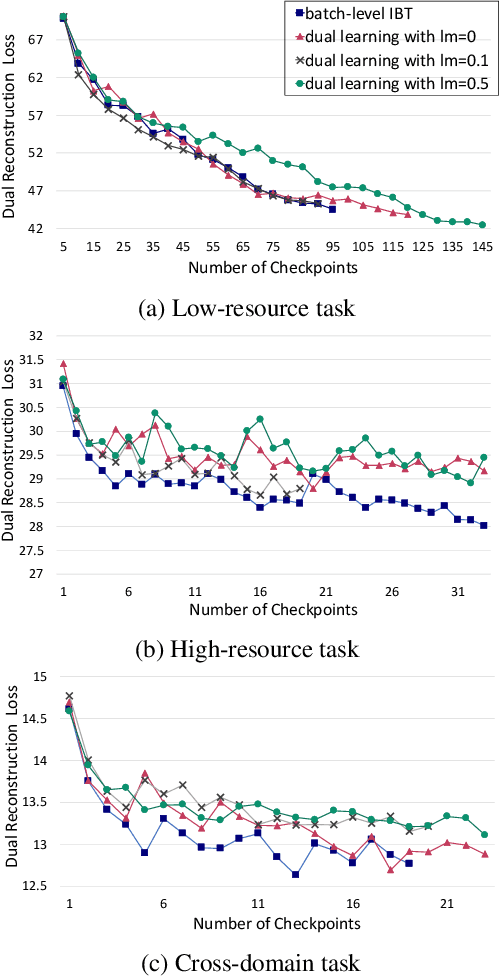
While Iterative Back-Translation and Dual Learning effectively incorporate monolingual training data in neural machine translation, they use different objectives and heuristic gradient approximation strategies, and have not been extensively compared. We introduce a novel dual reconstruction objective that provides a unified view of Iterative Back-Translation and Dual Learning. It motivates a theoretical analysis and controlled empirical study on German-English and Turkish-English tasks, which both suggest that Iterative Back-Translation is more effective than Dual Learning despite its relative simplicity.
Convolutional Neural Network Training with Distributed K-FAC
Jul 01, 2020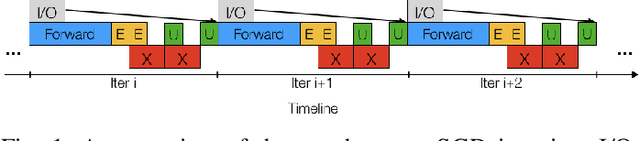
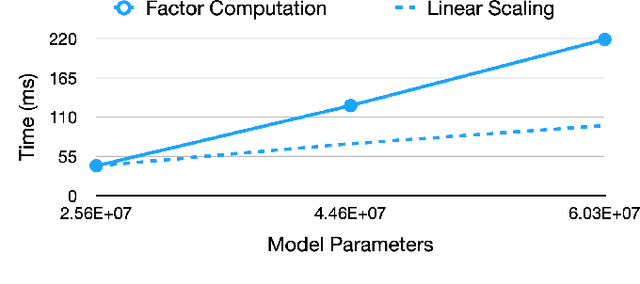
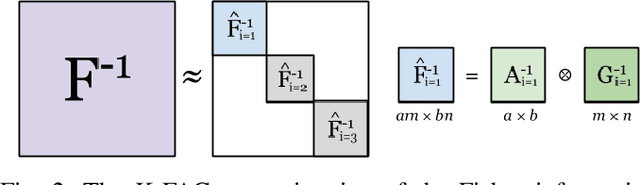
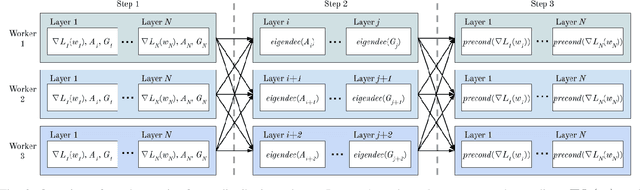
Training neural networks with many processors can reduce time-to-solution; however, it is challenging to maintain convergence and efficiency at large scales. The Kronecker-factored Approximate Curvature (K-FAC) was recently proposed as an approximation of the Fisher Information Matrix that can be used in natural gradient optimizers. We investigate here a scalable K-FAC design and its applicability in convolutional neural network (CNN) training at scale. We study optimization techniques such as layer-wise distribution strategies, inverse-free second-order gradient evaluation, and dynamic K-FAC update decoupling to reduce training time while preserving convergence. We use residual neural networks (ResNet) applied to the CIFAR-10 and ImageNet-1k datasets to evaluate the correctness and scalability of our K-FAC gradient preconditioner. With ResNet-50 on the ImageNet-1k dataset, our distributed K-FAC implementation converges to the 75.9% MLPerf baseline in 18-25% less time than does the classic stochastic gradient descent (SGD) optimizer across scales on a GPU cluster.
End-to-End Slot Alignment and Recognition for Cross-Lingual NLU
Apr 29, 2020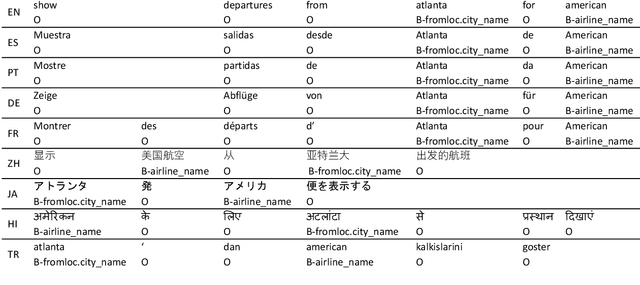
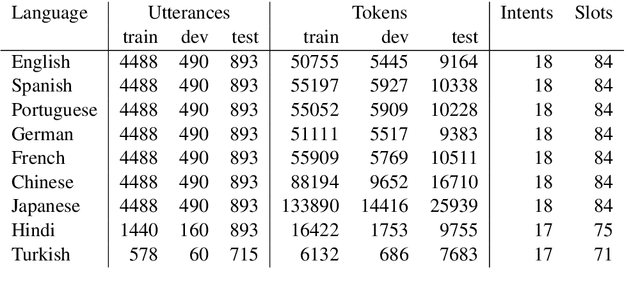
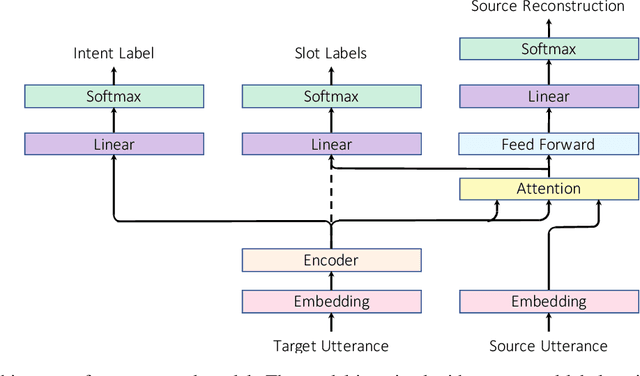
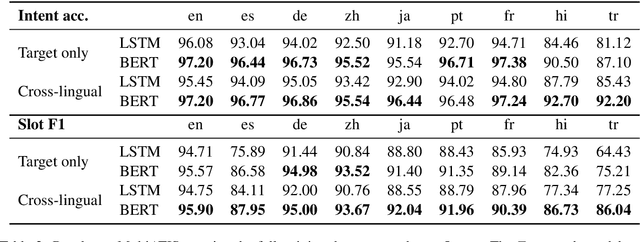
Natural language understanding in the context of goal oriented dialog systems typically includes intent classification and slot labeling tasks. An effective method to expand an NLU system to new languages is using machine translation (MT) with annotation projection to the target language. Previous work focused on using word alignment tools or complex heuristics for slot annotation projection. In this work, we propose a novel end-to-end model that learns to align and predict slots. Existing multilingual NLU data sets only support up to three languages which limits the study on cross-lingual transfer. To this end, we construct a multilingual NLU corpus, MultiATIS++, by extending the Multilingual ATIS corpus to nine languages across various language families. We use the corpus to explore various cross-lingual transfer methods focusing on the zero-shot setting and leveraging MT for language expansion. Results show that our soft-alignment method significantly improves slot F1 over strong baselines on most languages. In addition, our experiments show the strength of using multilingual BERT for both cross-lingual training and zero-shot transfer.
HPC AI500: A Benchmark Suite for HPC AI Systems
Aug 13, 2019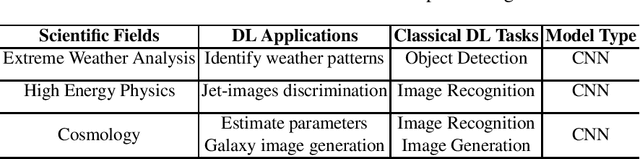
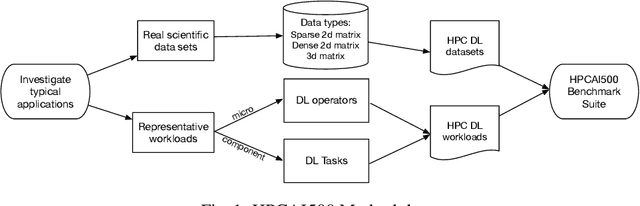

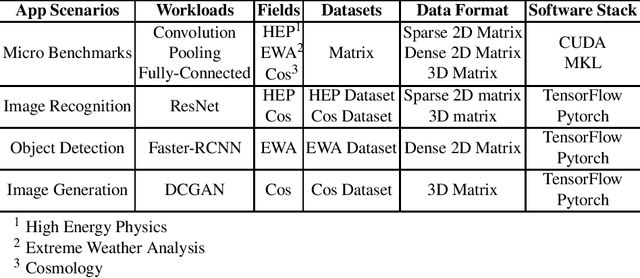
In recent years, with the trend of applying deep learning (DL) in high performance scientific computing, the unique characteristics of emerging DL workloads in HPC raise great challenges in designing, implementing HPC AI systems. The community needs a new yard stick for evaluating the future HPC systems. In this paper, we propose HPC AI500 --- a benchmark suite for evaluating HPC systems that running scientific DL workloads. Covering the most representative scientific fields, each workload from HPC AI500 is based on real-world scientific DL applications. Currently, we choose 14 scientific DL benchmarks from perspectives of application scenarios, data sets, and software stack. We propose a set of metrics for comprehensively evaluating the HPC AI systems, considering both accuracy, performance as well as power and cost. We provide a scalable reference implementation of HPC AI500. HPC AI500 is a part of the open-source AIBench project, the specification and source code are publicly available from \url{http://www.benchcouncil.org/AIBench/index.html}.