 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022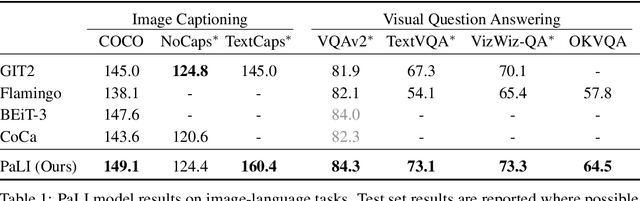

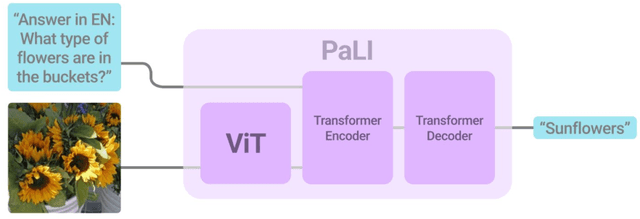

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
Pre-training image-language transformers for open-vocabulary tasks
Sep 09, 2022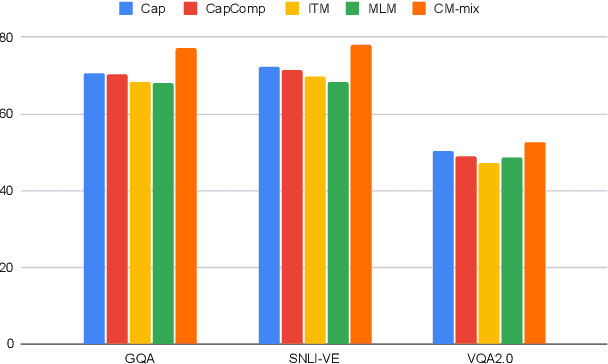
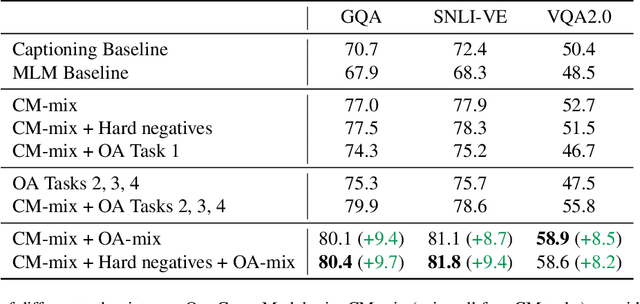
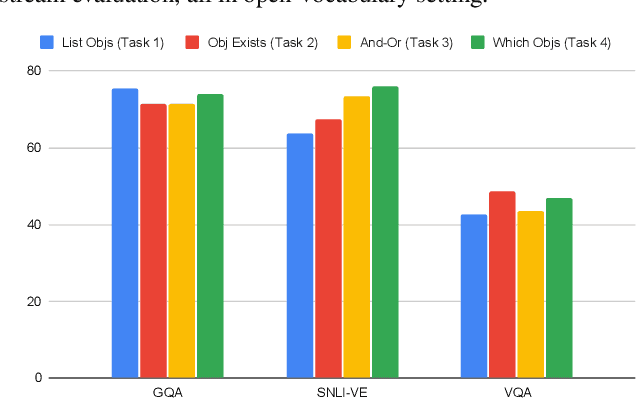

We present a pre-training approach for vision and language transformer models, which is based on a mixture of diverse tasks. We explore both the use of image-text captioning data in pre-training, which does not need additional supervision, as well as object-aware strategies to pre-train the model. We evaluate the method on a number of textgenerative vision+language tasks, such as Visual Question Answering, visual entailment and captioning, and demonstrate large gains over standard pre-training methods.
Video Question Answering with Iterative Video-Text Co-Tokenization
Aug 01, 2022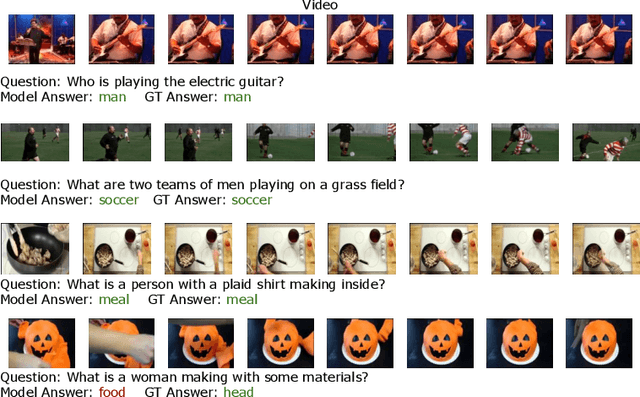
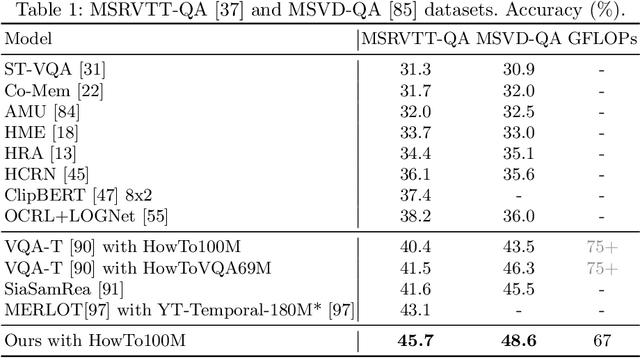
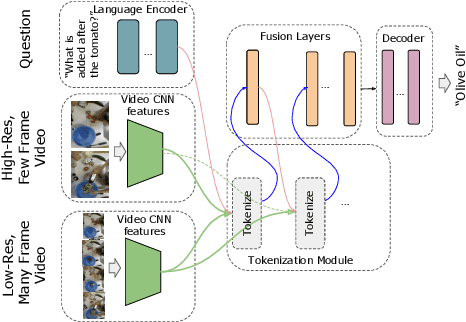

Video question answering is a challenging task that requires understanding jointly the language input, the visual information in individual video frames, as well as the temporal information about the events occurring in the video. In this paper, we propose a novel multi-stream video encoder for video question answering that uses multiple video inputs and a new video-text iterative co-tokenization approach to answer a variety of questions related to videos. We experimentally evaluate the model on several datasets, such as MSRVTT-QA, MSVD-QA, IVQA, outperforming the previous state-of-the-art by large margins. Simultaneously, our model reduces the required GFLOPs from 150-360 to only 67, producing a highly efficient video question answering model.
Answer-Me: Multi-Task Open-Vocabulary Visual Question Answering
May 02, 2022
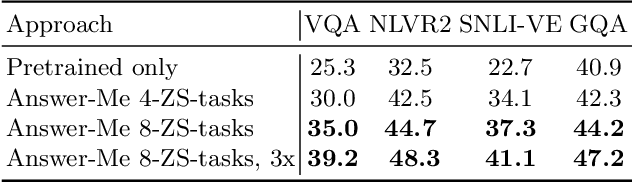
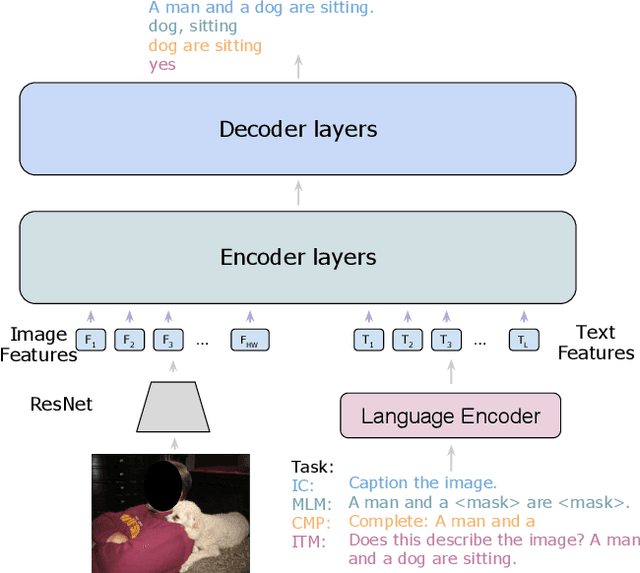
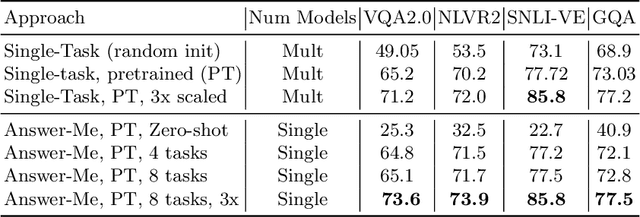
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.
FindIt: Generalized Localization with Natural Language Queries
Mar 31, 2022

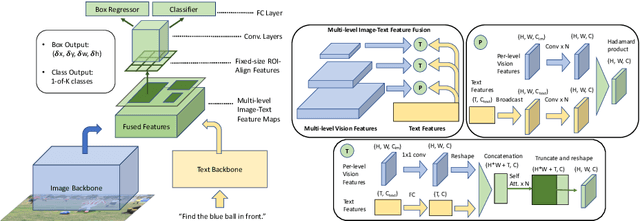
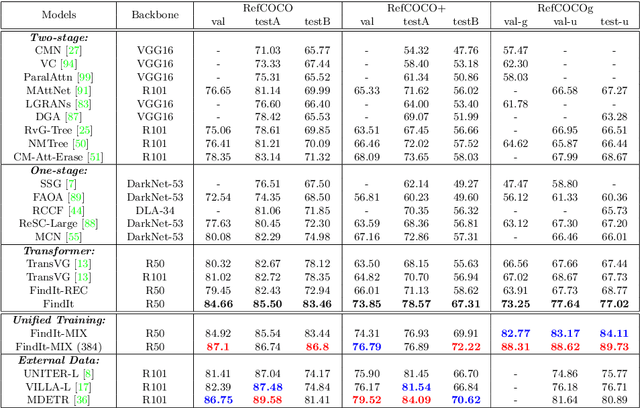
We propose FindIt, a simple and versatile framework that unifies a variety of visual grounding and localization tasks including referring expression comprehension, text-based localization, and object detection. Key to our architecture is an efficient multi-scale fusion module that unifies the disparate localization requirements across the tasks. In addition, we discover that a standard object detector is surprisingly effective in unifying these tasks without a need for task-specific design, losses, or pre-computed detections. Our end-to-end trainable framework responds flexibly and accurately to a wide range of referring expression, localization or detection queries for zero, one, or multiple objects. Jointly trained on these tasks, FindIt outperforms the state of the art on both referring expression and text-based localization, and shows competitive performance on object detection. Finally, FindIt generalizes better to out-of-distribution data and novel categories compared to strong single-task baselines. All of these are accomplished by a single, unified and efficient model. The code will be released.
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Aug 20, 2021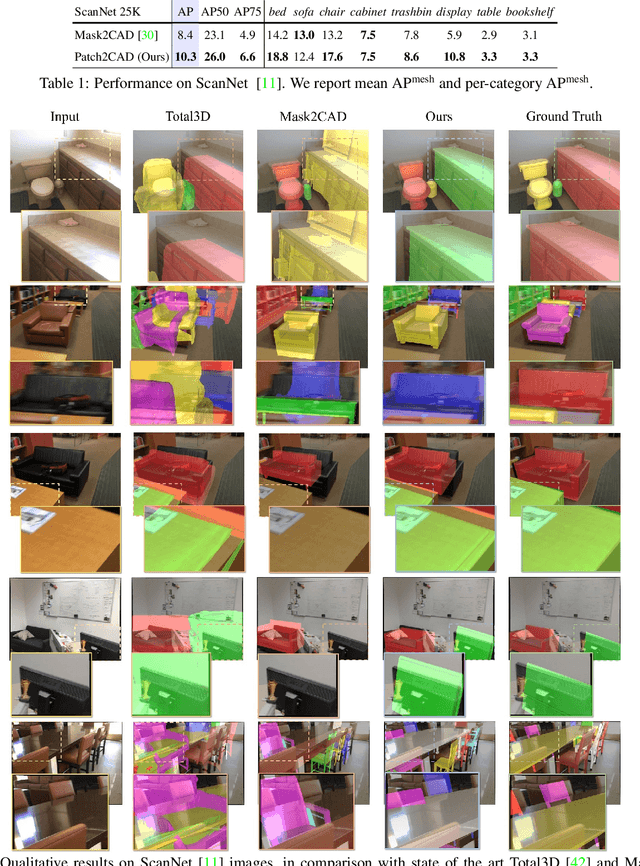
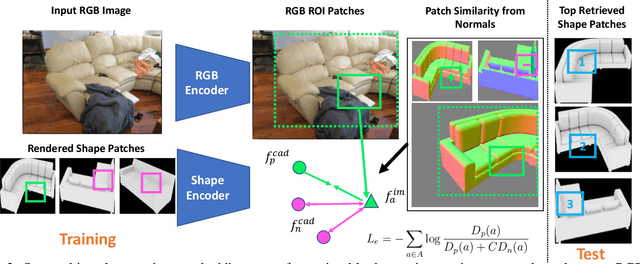
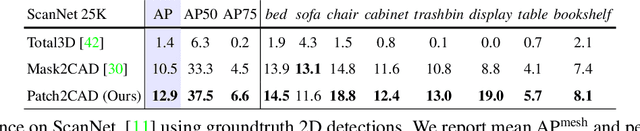
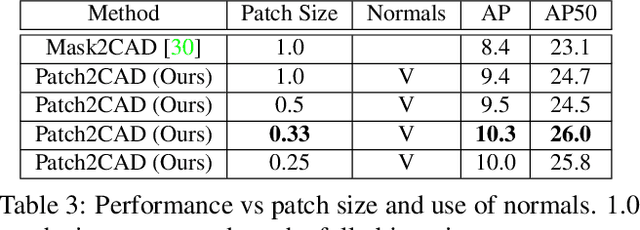
3D perception of object shapes from RGB image input is fundamental towards semantic scene understanding, grounding image-based perception in our spatially 3-dimensional real-world environments. To achieve a mapping between image views of objects and 3D shapes, we leverage CAD model priors from existing large-scale databases, and propose a novel approach towards constructing a joint embedding space between 2D images and 3D CAD models in a patch-wise fashion -- establishing correspondences between patches of an image view of an object and patches of CAD geometry. This enables part similarity reasoning for retrieving similar CADs to a new image view without exact matches in the database. Our patch embedding provides more robust CAD retrieval for shape estimation in our end-to-end estimation of CAD model shape and pose for detected objects in a single input image. Experiments on in-the-wild, complex imagery from ScanNet show that our approach is more robust than state of the art in real-world scenarios without any exact CAD matches.
Learning Open-World Object Proposals without Learning to Classify
Aug 15, 2021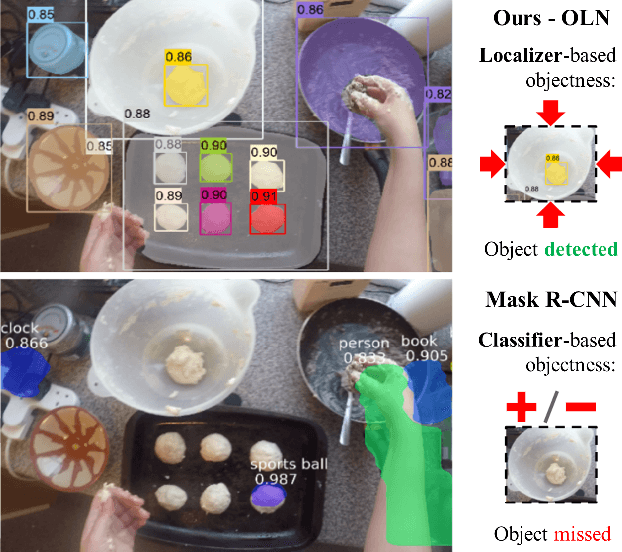
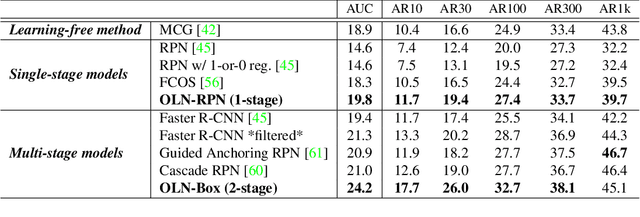
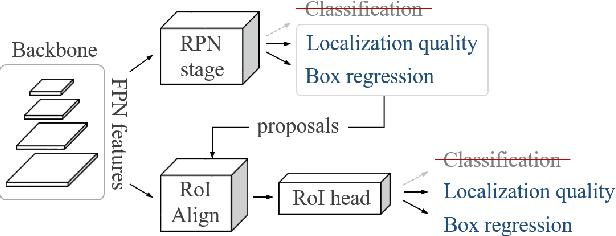
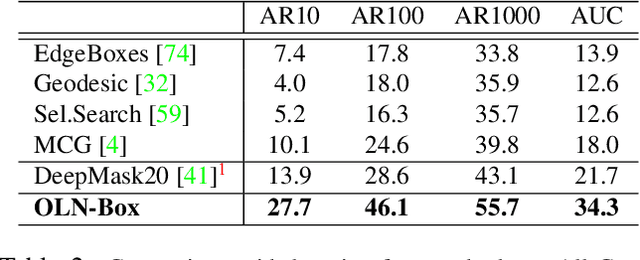
Object proposals have become an integral preprocessing steps of many vision pipelines including object detection, weakly supervised detection, object discovery, tracking, etc. Compared to the learning-free methods, learning-based proposals have become popular recently due to the growing interest in object detection. The common paradigm is to learn object proposals from data labeled with a set of object regions and their corresponding categories. However, this approach often struggles with novel objects in the open world that are absent in the training set. In this paper, we identify that the problem is that the binary classifiers in existing proposal methods tend to overfit to the training categories. Therefore, we propose a classification-free Object Localization Network (OLN) which estimates the objectness of each region purely by how well the location and shape of a region overlap with any ground-truth object (e.g., centerness and IoU). This simple strategy learns generalizable objectness and outperforms existing proposals on cross-category generalization on COCO, as well as cross-dataset evaluation on RoboNet, Object365, and EpicKitchens. Finally, we demonstrate the merit of OLN for long-tail object detection on large vocabulary dataset, LVIS, where we notice clear improvement in rare and common categories.
Noisy Student learning for cross-institution brain hemorrhage detection
May 03, 2021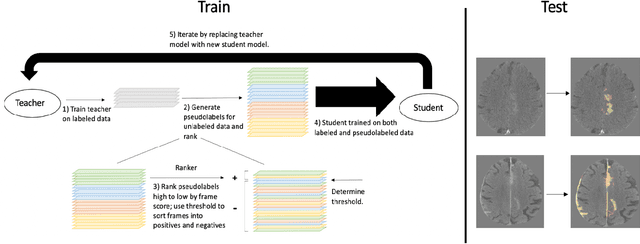
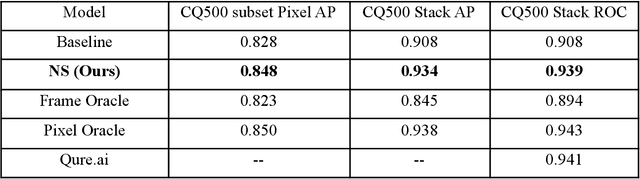
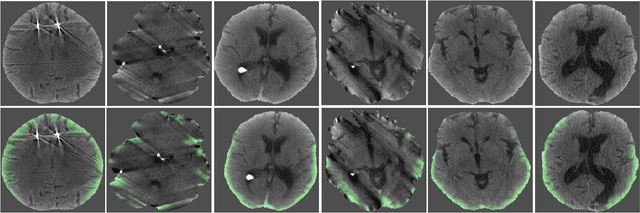
Computed tomography (CT) is the imaging modality used in the diagnosis of neurological emergencies, including acute stroke and traumatic brain injury. Advances in deep learning have led to models that can detect and segment hemorrhage on head CT. PatchFCN, one such supervised fully convolutional network (FCN), recently demonstrated expert-level detection of intracranial hemorrhage on in-sample data. However, its potential for similar accuracy outside the training domain is hindered by its need for pixel-labeled data from outside institutions. Also recently, a semi-supervised technique, Noisy Student (NS) learning, demonstrated state-of-the-art performance on ImageNet by moving from a fully-supervised to a semi-supervised learning paradigm. We combine the PatchFCN and Noisy Student approaches, extending semi-supervised learning to an intracranial hemorrhage segmentation task. Surprisingly, the NS model performance surpasses that of a fully-supervised oracle model trained with image-level labels on the same data. It also performs comparably to another recently reported supervised model trained on a labeled dataset 600x larger than that used to train the NS model. To our knowledge, we are the first to demonstrate the effectiveness of semi-supervised learning on a head CT detection and segmentation task.
Zero-Shot Detection via Vision and Language Knowledge Distillation
Apr 28, 2021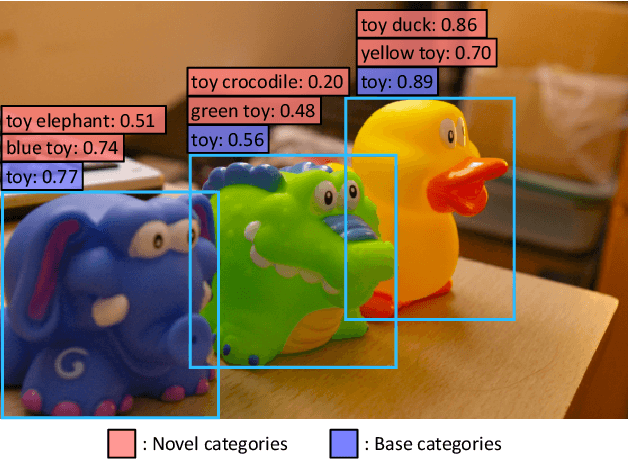

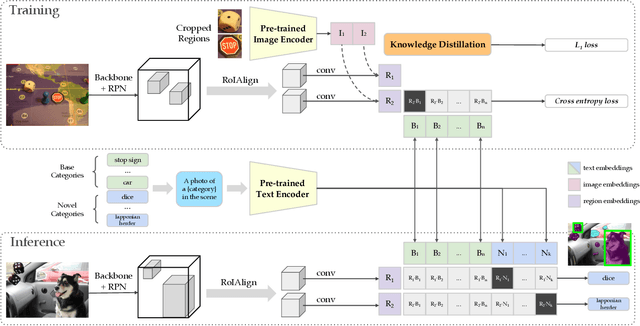
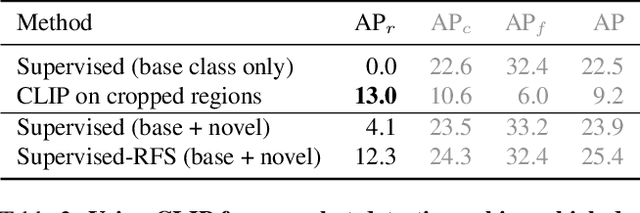
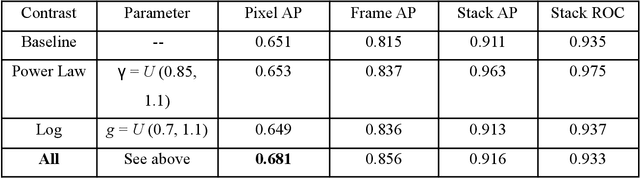
Zero-shot image classification has made promising progress by training the aligned image and text encoders. The goal of this work is to advance zero-shot object detection, which aims to detect novel objects without bounding box nor mask annotations. We propose ViLD, a training method via Vision and Language knowledge Distillation. We distill the knowledge from a pre-trained zero-shot image classification model (e.g., CLIP) into a two-stage detector (e.g., Mask R-CNN). Our method aligns the region embeddings in the detector to the text and image embeddings inferred by the pre-trained model. We use the text embeddings as the detection classifier, obtained by feeding category names into the pre-trained text encoder. We then minimize the distance between the region embeddings and image embeddings, obtained by feeding region proposals into the pre-trained image encoder. During inference, we include text embeddings of novel categories into the detection classifier for zero-shot detection. We benchmark the performance on LVIS dataset by holding out all rare categories as novel categories. ViLD obtains 16.1 mask AP$_r$ with a Mask R-CNN (ResNet-50 FPN) for zero-shot detection, outperforming the supervised counterpart by 3.8. The model can directly transfer to other datasets, achieving 72.2 AP$_{50}$, 36.6 AP and 11.8 AP on PASCAL VOC, COCO and Objects365, respectively.
Mask2CAD: 3D Shape Prediction by Learning to Segment and Retrieve
Jul 26, 2020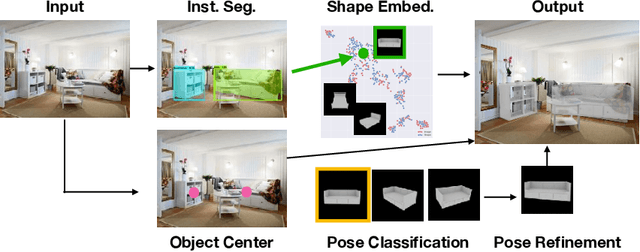
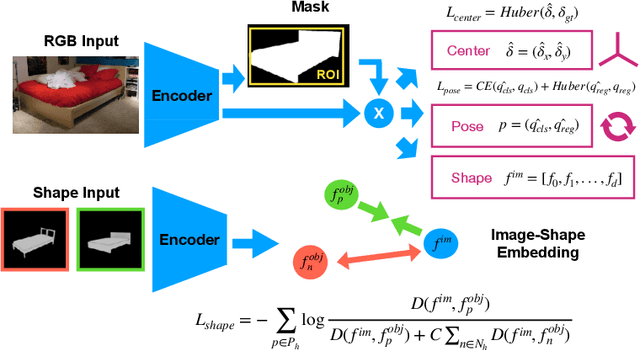
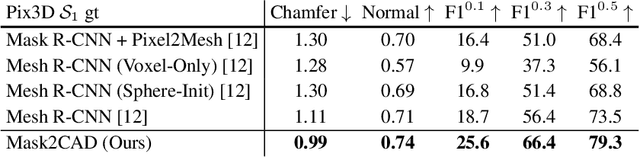
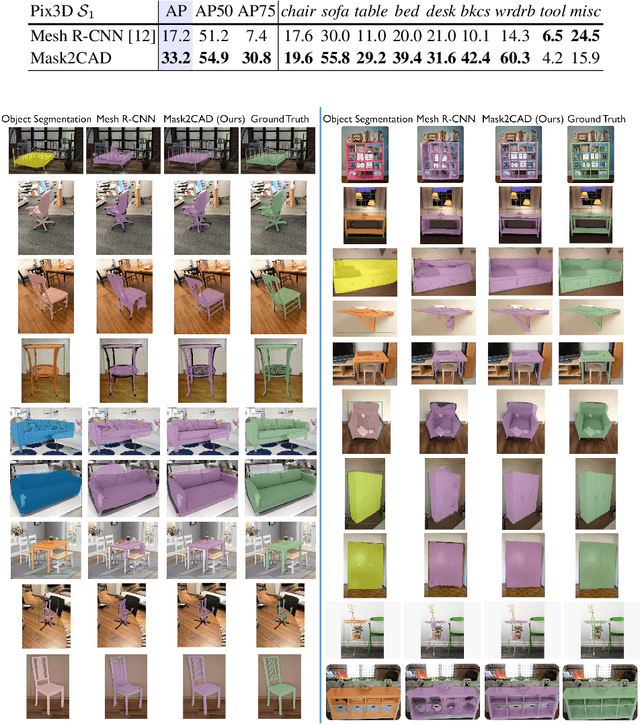
Object recognition has seen significant progress in the image domain, with focus primarily on 2D perception. We propose to leverage existing large-scale datasets of 3D models to understand the underlying 3D structure of objects seen in an image by constructing a CAD-based representation of the objects and their poses. We present Mask2CAD, which jointly detects objects in real-world images and for each detected object, optimizes for the most similar CAD model and its pose. We construct a joint embedding space between the detected regions of an image corresponding to an object and 3D CAD models, enabling retrieval of CAD models for an input RGB image. This produces a clean, lightweight representation of the objects in an image; this CAD-based representation ensures a valid, efficient shape representation for applications such as content creation or interactive scenarios, and makes a step towards understanding the transformation of real-world imagery to a synthetic domain. Experiments on real-world images from Pix3D demonstrate the advantage of our approach in comparison to state of the art. To facilitate future research, we additionally propose a new image-to-3D baseline on ScanNet which features larger shape diversity, real-world occlusions, and challenging image views.