 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Spoken Dialogue Language Modeling
Mar 30, 2022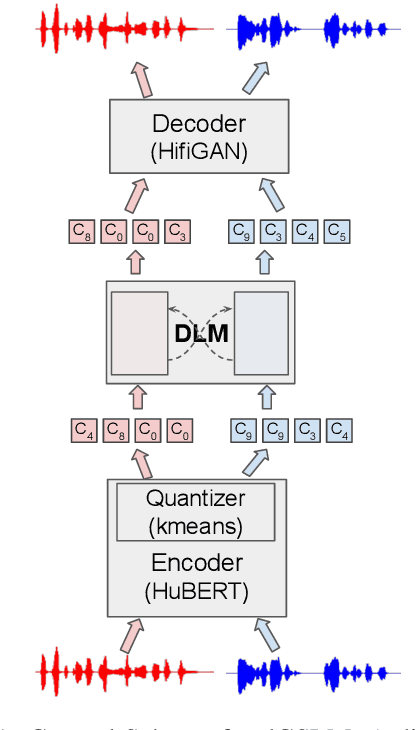
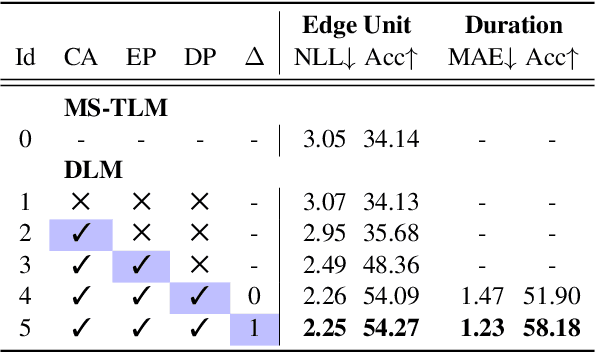
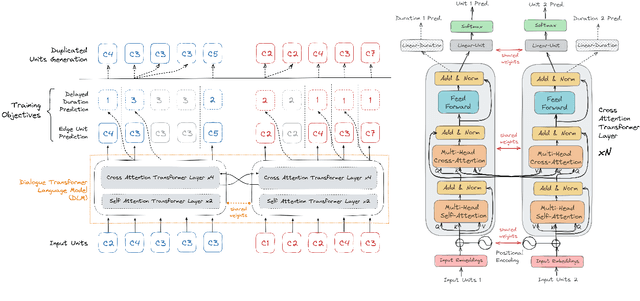
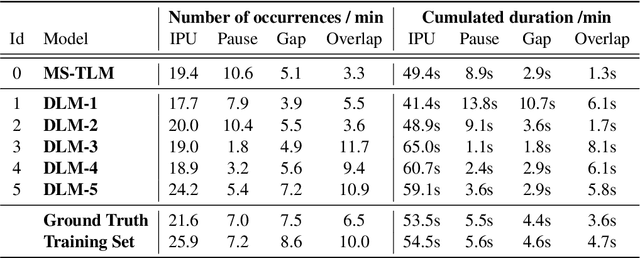
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues. It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or labels. It is able to generate speech, laughter and other paralinguistic signals in the two channels simultaneously and reproduces naturalistic turn taking. Generation samples can be found at: https://speechbot.github.io/dgslm.
Measuring the Impact of Individual Domain Factors in Self-Supervised Pre-Training
Mar 02, 2022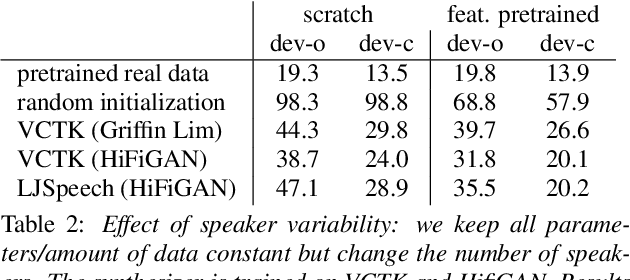
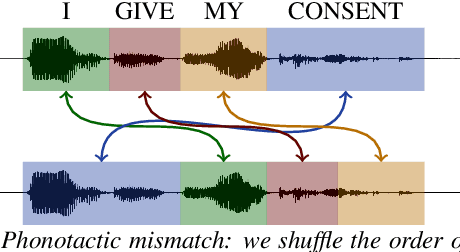
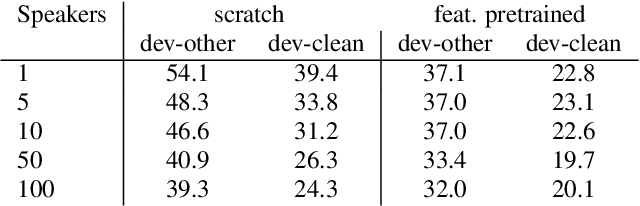

Human speech data comprises a rich set of domain factors such as accent, syntactic and semantic variety, or acoustic environment. Previous work explores the effect of domain mismatch in automatic speech recognition between pre-training and fine-tuning as a whole but does not dissect the contribution of individual factors. In this paper, we present a controlled study to better understand the effect of such factors on the performance of pre-trained representations. To do so, we pre-train models either on modified natural speech or synthesized audio, with a single domain factor modified, and then measure performance on automatic speech recognition after fine tuning. Results show that phonetic domain factors play an important role during pre-training while grammatical and syntactic factors are far less important. To our knowledge, this is the first study to better understand the domain characteristics in self-supervised pre-training for speech.
textless-lib: a Library for Textless Spoken Language Processing
Feb 15, 2022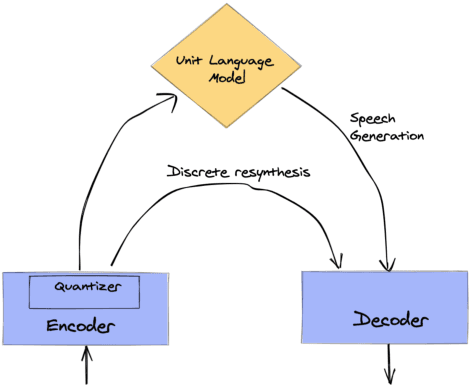
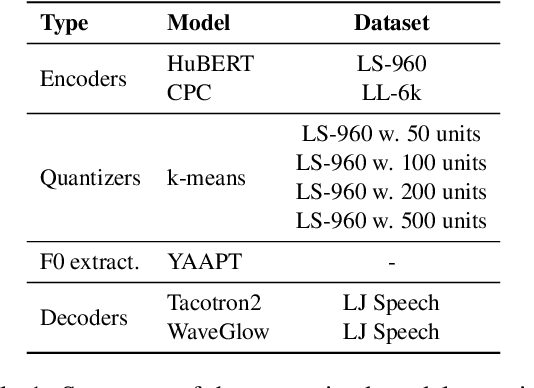
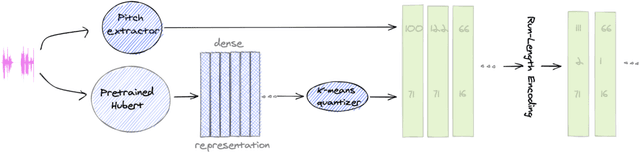
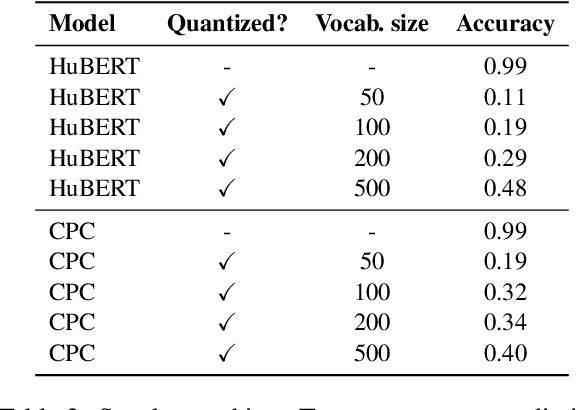
Textless spoken language processing research aims to extend the applicability of standard NLP toolset onto spoken language and languages with few or no textual resources. In this paper, we introduce textless-lib, a PyTorch-based library aimed to facilitate research in this research area. We describe the building blocks that the library provides and demonstrate its usability by discuss three different use-case examples: (i) speaker probing, (ii) speech resynthesis and compression, and (iii) speech continuation. We believe that textless-lib substantially simplifies research the textless setting and will be handful not only for speech researchers but also for the NLP community at large. The code, documentation, and pre-trained models are available at https://github.com/facebookresearch/textlesslib/ .
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Feb 07, 2022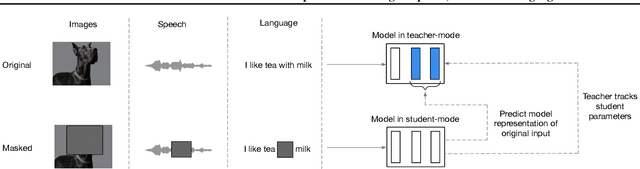
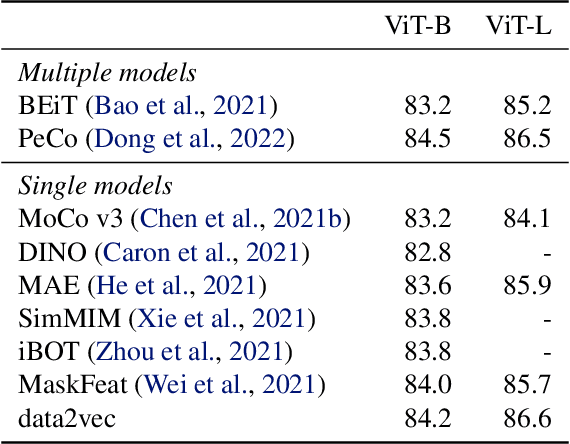
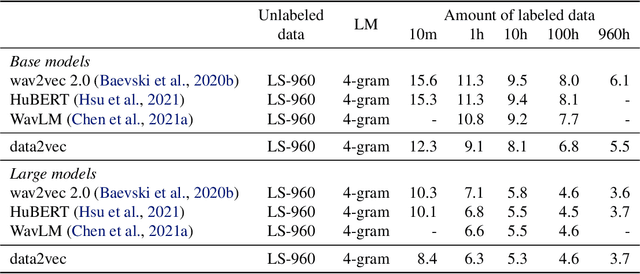
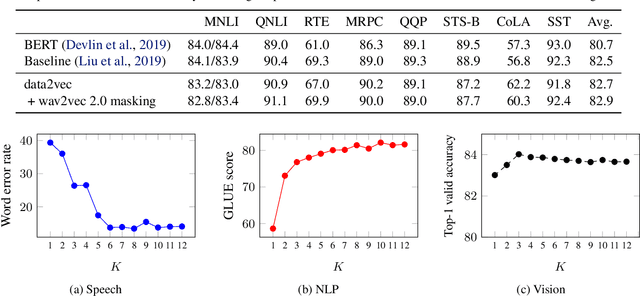
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Robust Self-Supervised Audio-Visual Speech Recognition
Jan 05, 2022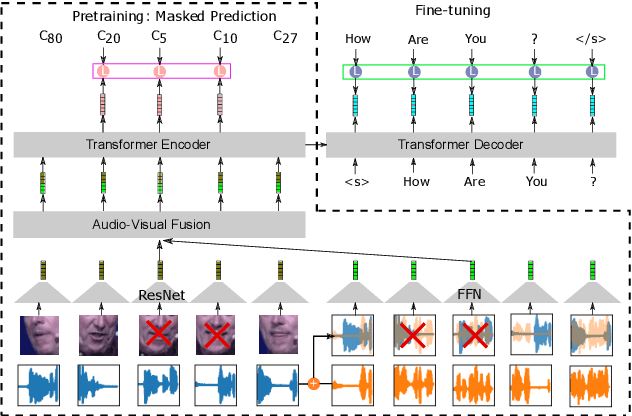

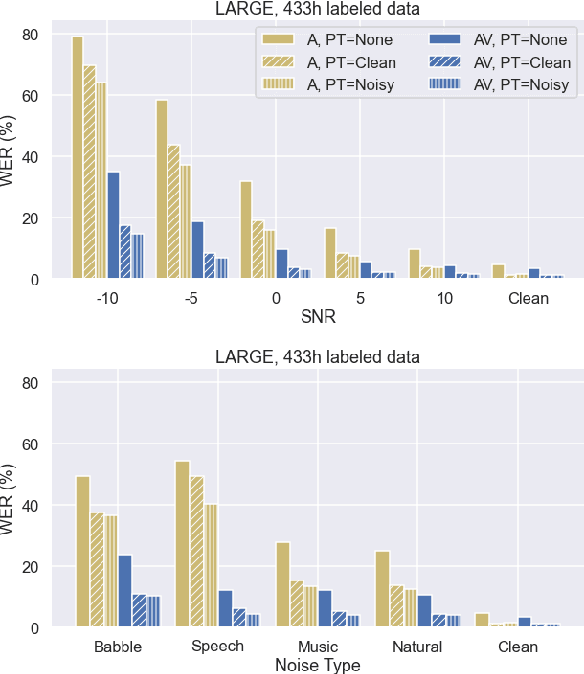
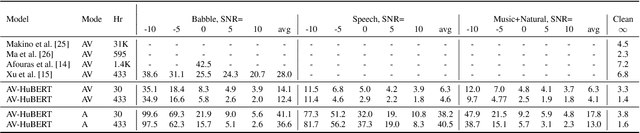
Audio-based automatic speech recognition (ASR) degrades significantly in noisy environments and is particularly vulnerable to interfering speech, as the model cannot determine which speaker to transcribe. Audio-visual speech recognition (AVSR) systems improve robustness by complementing the audio stream with the visual information that is invariant to noise and helps the model focus on the desired speaker. However, previous AVSR work focused solely on the supervised learning setup; hence the progress was hindered by the amount of labeled data available. In this work, we present a self-supervised AVSR framework built upon Audio-Visual HuBERT (AV-HuBERT), a state-of-the-art audio-visual speech representation learning model. On the largest available AVSR benchmark dataset LRS3, our approach outperforms prior state-of-the-art by ~50% (28.0% vs. 14.1%) using less than 10% of labeled data (433hr vs. 30hr) in the presence of babble noise, while reducing the WER of an audio-based model by over 75% (25.8% vs. 5.8%) on average.
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
Jan 05, 2022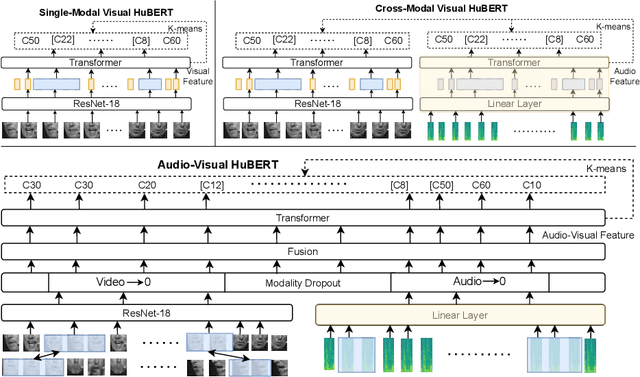
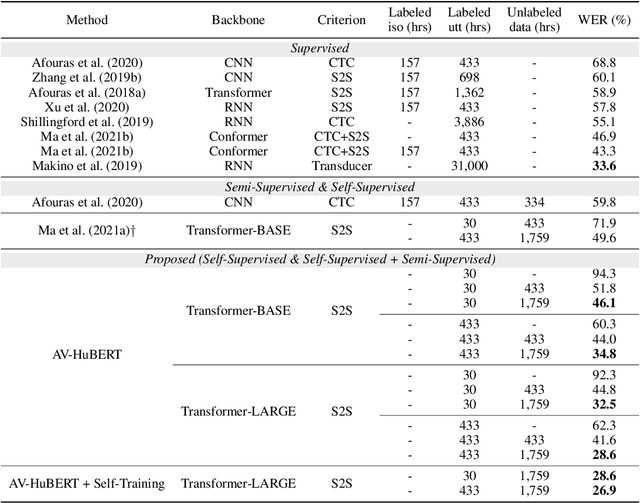


Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker's lip movements and the produced sound. We introduce Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition. On the largest public lip-reading benchmark LRS3 (433 hours), AV-HuBERT achieves 32.5% WER with only 30 hours of labeled data, outperforming the former state-of-the-art approach (33.6%) trained with a thousand times more transcribed video data (31K hours). The lip-reading WER is further reduced to 26.9% when using all 433 hours of labeled data from LRS3 and combined with self-training. Using our audio-visual representation on the same benchmark for audio-only speech recognition leads to a 40% relative WER reduction over the state-of-the-art performance (1.3% vs 2.3%). Our code and models are available at https://github.com/facebookresearch/av_hubert
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
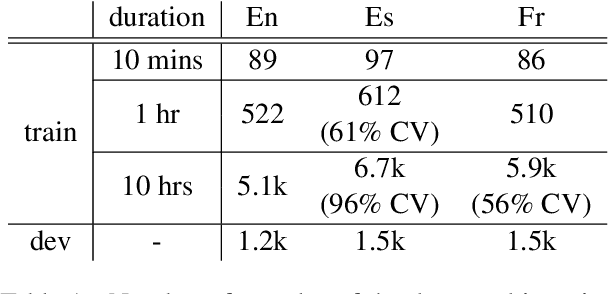
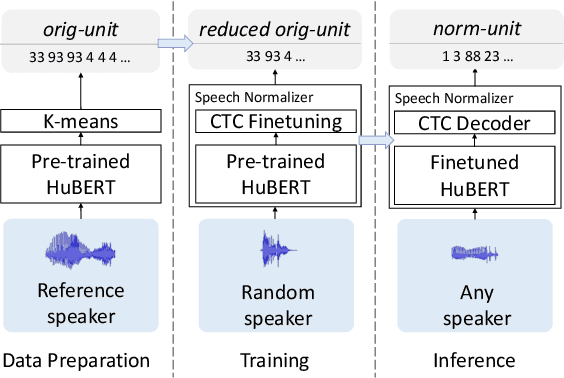
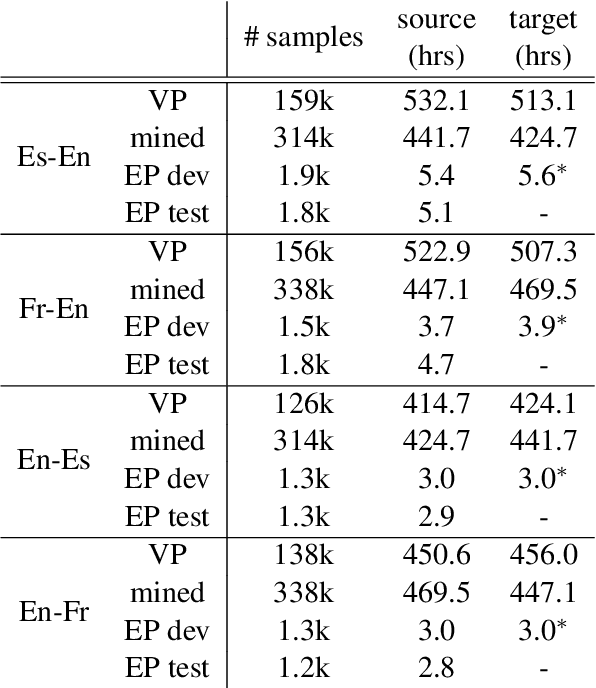
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.
Textless Speech Emotion Conversion using Decomposed and Discrete Representations
Nov 14, 2021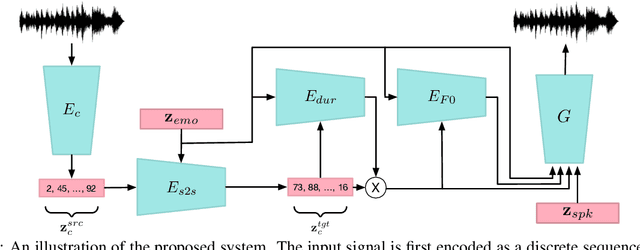
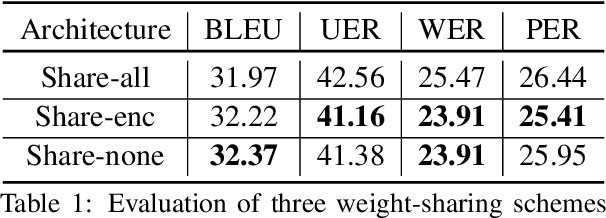
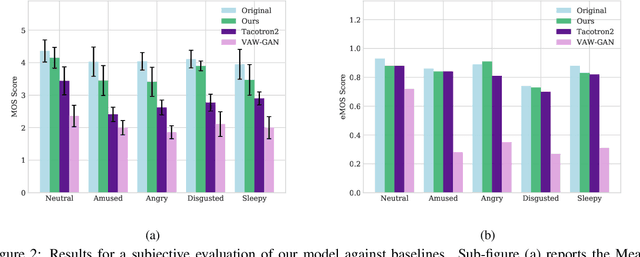
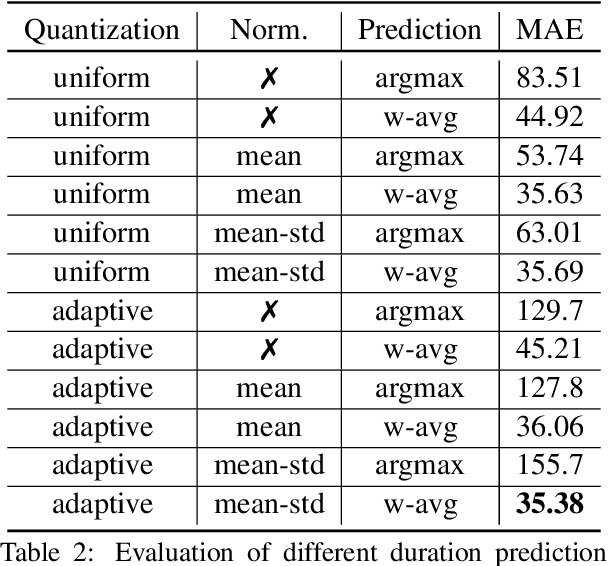
Speech emotion conversion is the task of modifying the perceived emotion of a speech utterance while preserving the lexical content and speaker identity. In this study, we cast the problem of emotion conversion as a spoken language translation task. We decompose speech into discrete and disentangled learned representations, consisting of content units, F0, speaker, and emotion. First, we modify the speech content by translating the content units to a target emotion, and then predict the prosodic features based on these units. Finally, the speech waveform is generated by feeding the predicted representations into a neural vocoder. Such a paradigm allows us to go beyond spectral and parametric changes of the signal, and model non-verbal vocalizations, such as laughter insertion, yawning removal, etc. We demonstrate objectively and subjectively that the proposed method is superior to the baselines in terms of perceived emotion and audio quality. We rigorously evaluate all components of such a complex system and conclude with an extensive model analysis and ablation study to better emphasize the architectural choices, strengths and weaknesses of the proposed method. Samples and code will be publicly available under the following link: https://speechbot.github.io/emotion.
Direct simultaneous speech to speech translation
Oct 15, 2021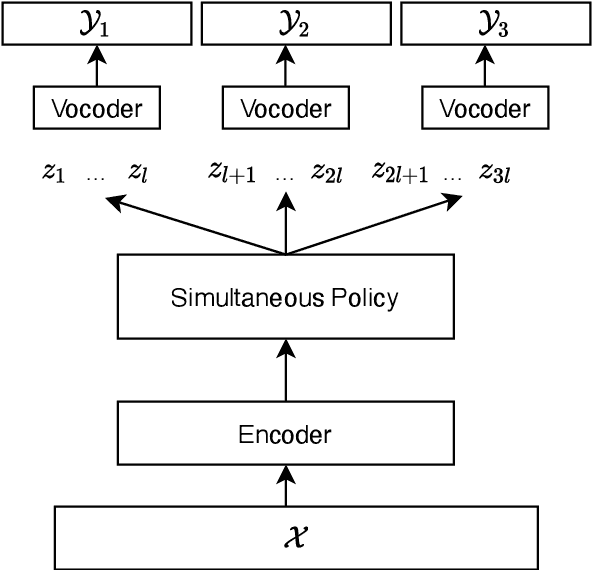
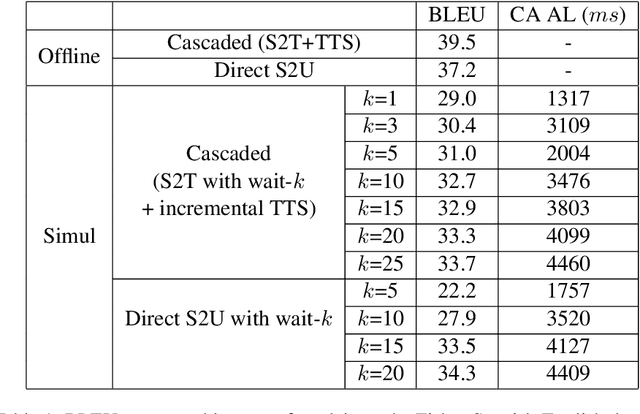
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021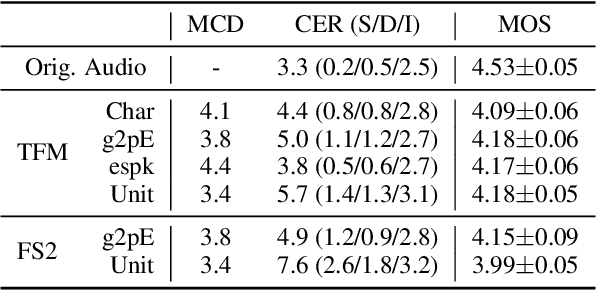
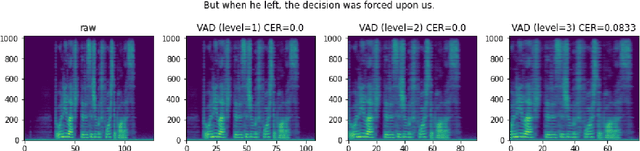

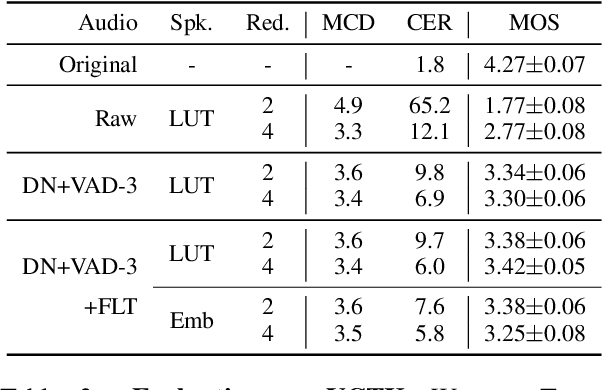
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.