 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
Jun 13, 2024



Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals -- resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Jun 10, 2024



As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Apr 16, 2024



Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
Mar 21, 2024



Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023



Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023


In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Generative Pre-training for Speech with Flow Matching
Oct 25, 2023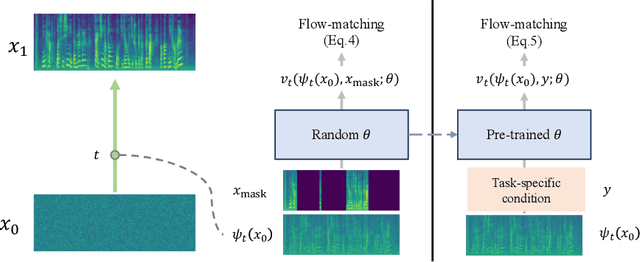
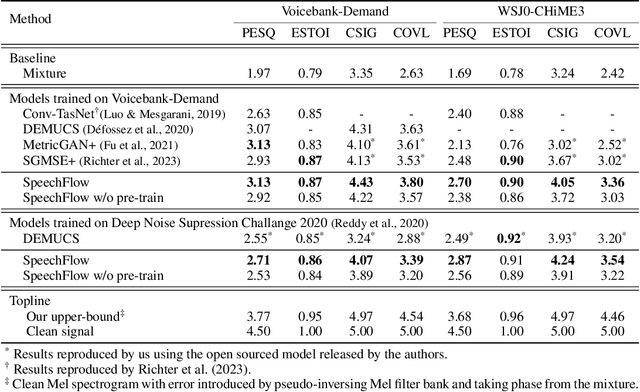
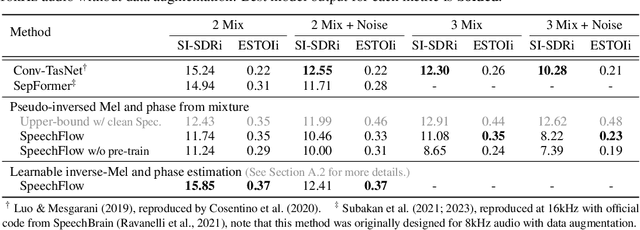
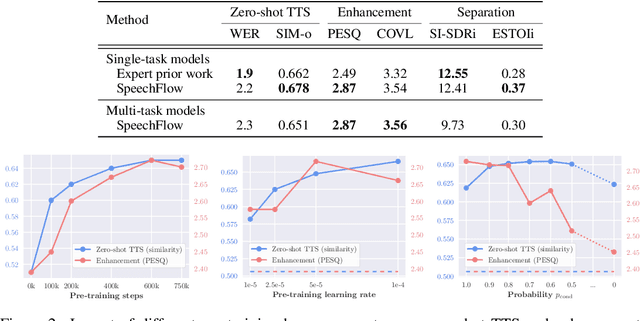
Generative models have gained more and more attention in recent years for their remarkable success in tasks that required estimating and sampling data distribution to generate high-fidelity synthetic data. In speech, text-to-speech synthesis and neural vocoder are good examples where generative models have shined. While generative models have been applied to different applications in speech, there exists no general-purpose generative model that models speech directly. In this work, we take a step toward this direction by showing a single pre-trained generative model can be adapted to different downstream tasks with strong performance. Specifically, we pre-trained a generative model, named SpeechFlow, on 60k hours of untranscribed speech with Flow Matching and masked conditions. Experiment results show the pre-trained generative model can be fine-tuned with task-specific data to match or surpass existing expert models on speech enhancement, separation, and synthesis. Our work suggested a foundational model for generation tasks in speech can be built with generative pre-training.
Toward Joint Language Modeling for Speech Units and Text
Oct 12, 2023



Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model's learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Sep 29, 2023



Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90\% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
EXPRESSO: A Benchmark and Analysis of Discrete Expressive Speech Resynthesis
Aug 10, 2023



Recent work has shown that it is possible to resynthesize high-quality speech based, not on text, but on low bitrate discrete units that have been learned in a self-supervised fashion and can therefore capture expressive aspects of speech that are hard to transcribe (prosody, voice styles, non-verbal vocalization). The adoption of these methods is still limited by the fact that most speech synthesis datasets are read, severely limiting spontaneity and expressivity. Here, we introduce Expresso, a high-quality expressive speech dataset for textless speech synthesis that includes both read speech and improvised dialogues rendered in 26 spontaneous expressive styles. We illustrate the challenges and potentials of this dataset with an expressive resynthesis benchmark where the task is to encode the input in low-bitrate units and resynthesize it in a target voice while preserving content and style. We evaluate resynthesis quality with automatic metrics for different self-supervised discrete encoders, and explore tradeoffs between quality, bitrate and invariance to speaker and style. All the dataset, evaluation metrics and baseline models are open source