 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Tasks for Embedding-based Large-scale Retrieval
Feb 10, 2020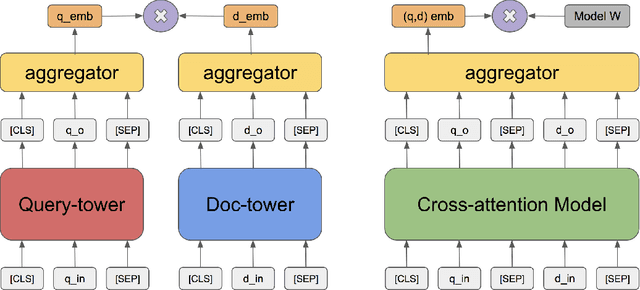
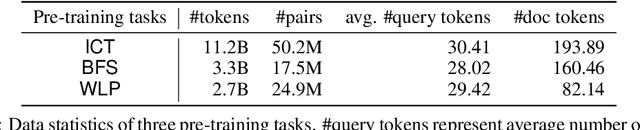

We consider the large-scale query-document retrieval problem: given a query (e.g., a question), return the set of relevant documents (e.g., paragraphs containing the answer) from a large document corpus. This problem is often solved in two steps. The retrieval phase first reduces the solution space, returning a subset of candidate documents. The scoring phase then re-ranks the documents. Critically, the retrieval algorithm not only desires high recall but also requires to be highly efficient, returning candidates in time sublinear to the number of documents. Unlike the scoring phase witnessing significant advances recently due to the BERT-style pre-training tasks on cross-attention models, the retrieval phase remains less well studied. Most previous works rely on classic Information Retrieval (IR) methods such as BM-25 (token matching + TF-IDF weights). These models only accept sparse handcrafted features and can not be optimized for different downstream tasks of interest. In this paper, we conduct a comprehensive study on the embedding-based retrieval models. We show that the key ingredient of learning a strong embedding-based Transformer model is the set of pre-training tasks. With adequately designed paragraph-level pre-training tasks, the Transformer models can remarkably improve over the widely-used BM-25 as well as embedding models without Transformers. The paragraph-level pre-training tasks we studied are Inverse Cloze Task (ICT), Body First Selection (BFS), Wiki Link Prediction (WLP), and the combination of all three.
XL-Editor: Post-editing Sentences with XLNet
Oct 19, 2019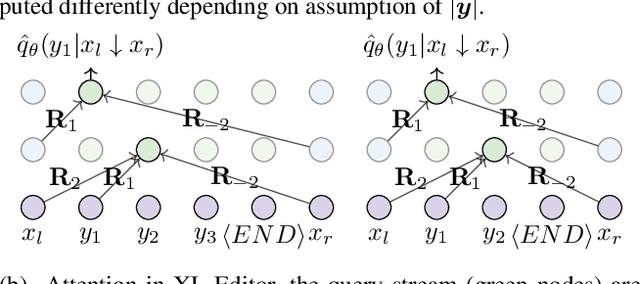
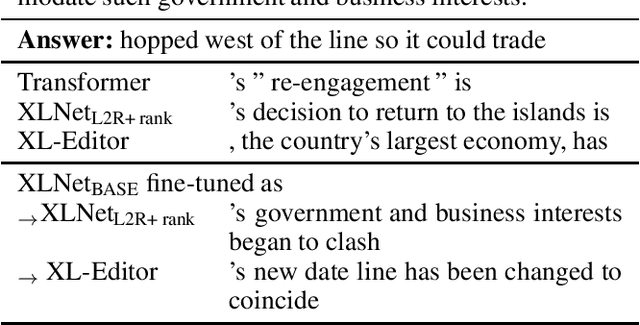
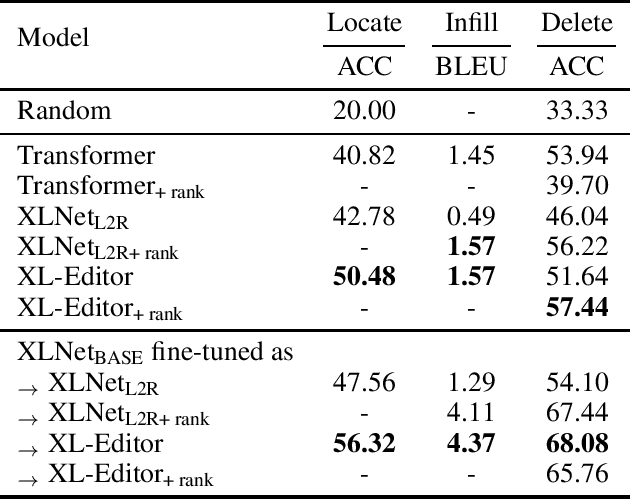

While neural sequence generation models achieve initial success for many NLP applications, the canonical decoding procedure with left-to-right generation order (i.e., autoregressive) in one-pass can not reflect the true nature of human revising a sentence to obtain a refined result. In this work, we propose XL-Editor, a novel training framework that enables state-of-the-art generalized autoregressive pretraining methods, XLNet specifically, to revise a given sentence by the variable-length insertion probability. Concretely, XL-Editor can (1) estimate the probability of inserting a variable-length sequence into a specific position of a given sentence; (2) execute post-editing operations such as insertion, deletion, and replacement based on the estimated variable-length insertion probability; (3) complement existing sequence-to-sequence models to refine the generated sequences. Empirically, we first demonstrate better post-editing capabilities of XL-Editor over XLNet on the text insertion and deletion tasks, which validates the effectiveness of our proposed framework. Furthermore, we extend XL-Editor to the unpaired text style transfer task, where transferring the target style onto a given sentence can be naturally viewed as post-editing the sentence into the target style. XL-Editor achieves significant improvement in style transfer accuracy and also maintains coherent semantic of the original sentence, showing the broad applicability of our method.
A Modular Deep Learning Approach for Extreme Multi-label Text Classification
May 07, 2019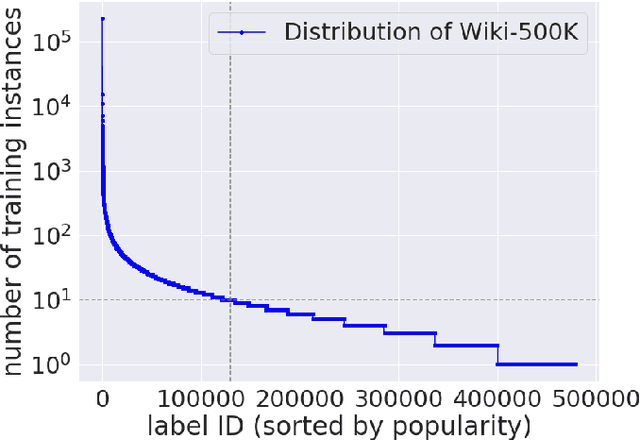

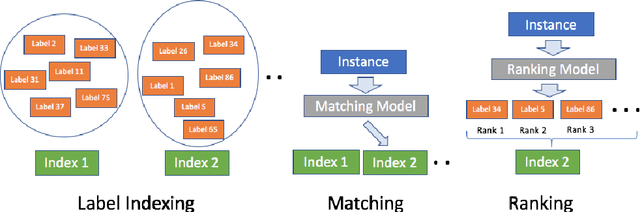
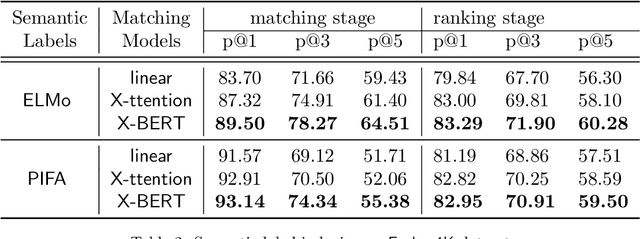
Extreme multi-label classification (XMC) aims to assign to an instance the most relevant subset of labels from a colossal label set. Due to modern applications that lead to massive label sets, the scalability of XMC has attracted much recent attention from both academia and industry. In this paper, we establish a three-stage framework to solve XMC efficiently, which includes 1) indexing the labels, 2) matching the instance to the relevant indices, and 3) ranking the labels from the relevant indices. This framework unifies many existing XMC approaches. Based on this framework, we propose a modular deep learning approach SLINMER: Semantic Label Indexing, Neural Matching, and Efficient Ranking. The label indexing stage of SLINMER can adopt different semantic label representations leading to different configurations of SLINMER. Empirically, we demonstrate that several individual configurations of SLINMER achieve superior performance than the state-of-the-art XMC approaches on several benchmark datasets. Moreover, by ensembling those configurations, SLINMER can achieve even better results. In particular, on a Wiki dataset with around 0.5 millions of labels, the precision@1 is increased from 61% to 67%.
Implicit Kernel Learning
Feb 26, 2019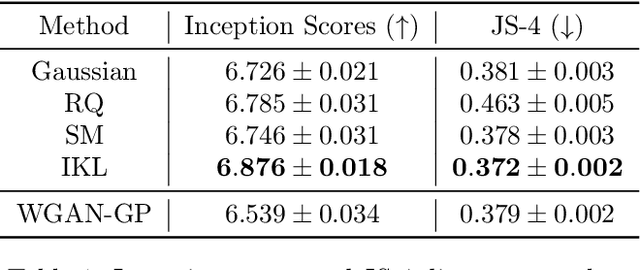

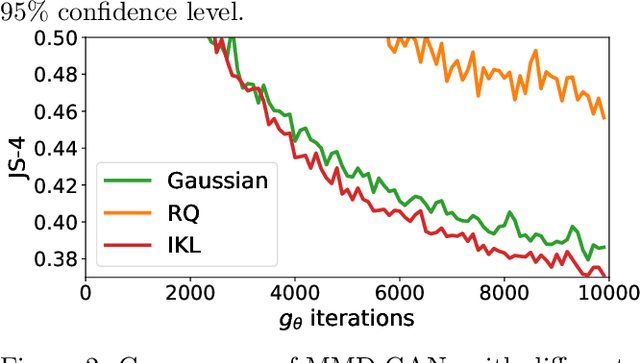
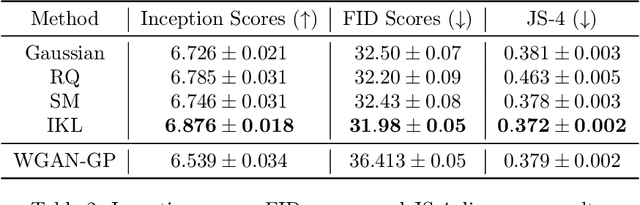
Kernels are powerful and versatile tools in machine learning and statistics. Although the notion of universal kernels and characteristic kernels has been studied, kernel selection still greatly influences the empirical performance. While learning the kernel in a data driven way has been investigated, in this paper we explore learning the spectral distribution of kernel via implicit generative models parametrized by deep neural networks. We called our method Implicit Kernel Learning (IKL). The proposed framework is simple to train and inference is performed via sampling random Fourier features. We investigate two applications of the proposed IKL as examples, including generative adversarial networks with MMD (MMD GAN) and standard supervised learning. Empirically, MMD GAN with IKL outperforms vanilla predefined kernels on both image and text generation benchmarks; using IKL with Random Kitchen Sinks also leads to substantial improvement over existing state-of-the-art kernel learning algorithms on popular supervised learning benchmarks. Theory and conditions for using IKL in both applications are also studied as well as connections to previous state-of-the-art methods.
Kernel Change-point Detection with Auxiliary Deep Generative Models
Jan 18, 2019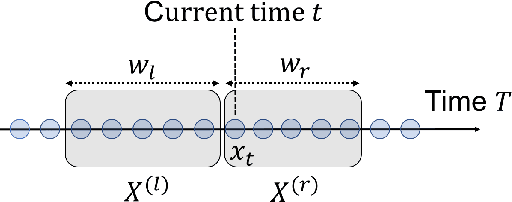
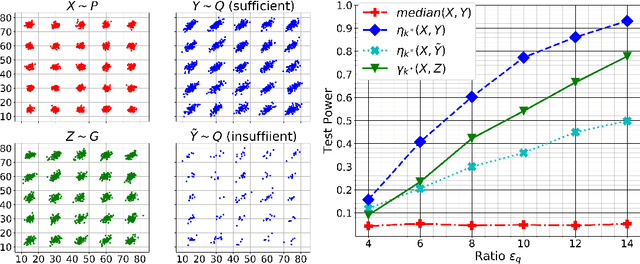
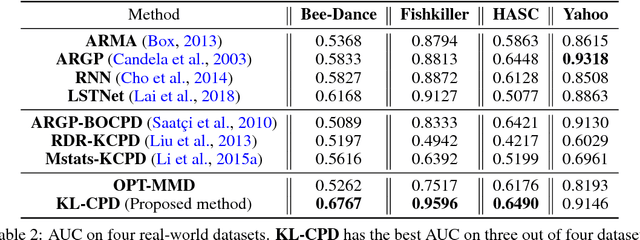
Detecting the emergence of abrupt property changes in time series is a challenging problem. Kernel two-sample test has been studied for this task which makes fewer assumptions on the distributions than traditional parametric approaches. However, selecting kernels is non-trivial in practice. Although kernel selection for two-sample test has been studied, the insufficient samples in change point detection problem hinder the success of those developed kernel selection algorithms. In this paper, we propose KL-CPD, a novel kernel learning framework for time series CPD that optimizes a lower bound of test power via an auxiliary generative model. With deep kernel parameterization, KL-CPD endows kernel two-sample test with the data-driven kernel to detect different types of change-points in real-world applications. The proposed approach significantly outperformed other state-of-the-art methods in our comparative evaluation of benchmark datasets and simulation studies.
Contextual Encoding for Translation Quality Estimation
Sep 01, 2018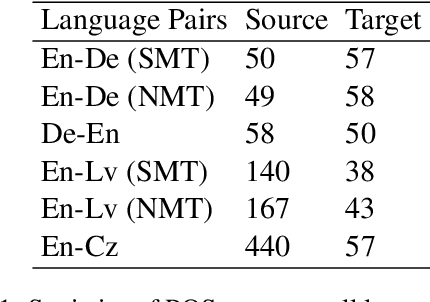
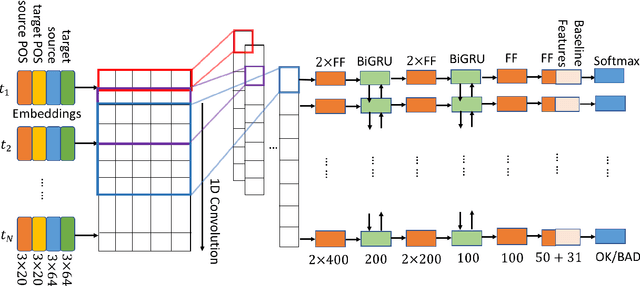

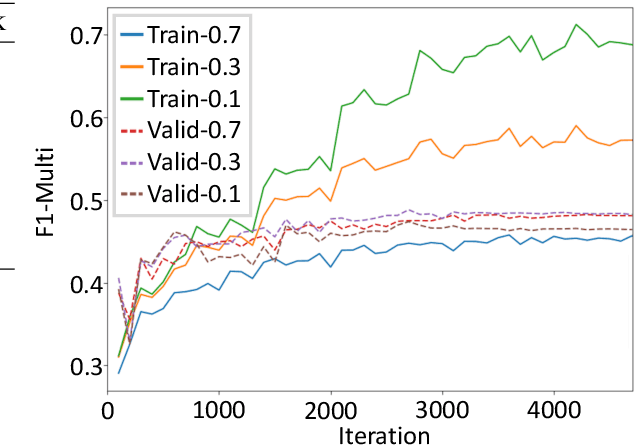
The task of word-level quality estimation (QE) consists of taking a source sentence and machine-generated translation, and predicting which words in the output are correct and which are wrong. In this paper, propose a method to effectively encode the local and global contextual information for each target word using a three-part neural network approach. The first part uses an embedding layer to represent words and their part-of-speech tags in both languages. The second part leverages a one-dimensional convolution layer to integrate local context information for each target word. The third part applies a stack of feed-forward and recurrent neural networks to further encode the global context in the sentence before making the predictions. This model was submitted as the CMU entry to the WMT2018 shared task on QE, and achieves strong results, ranking first in three of the six tracks.
The Mixing method: low-rank coordinate descent for semidefinite programming with diagonal constraints
Jul 04, 2018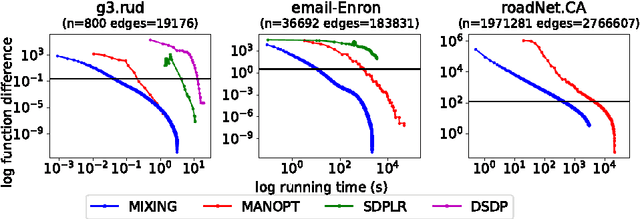
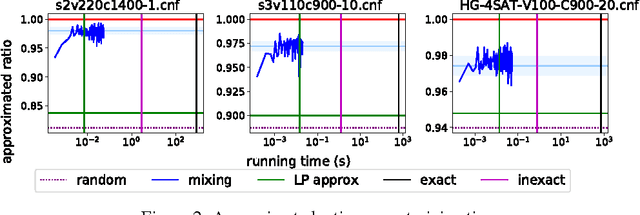
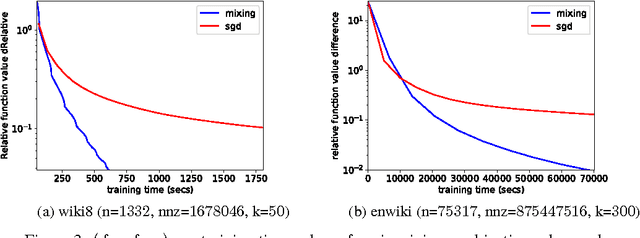
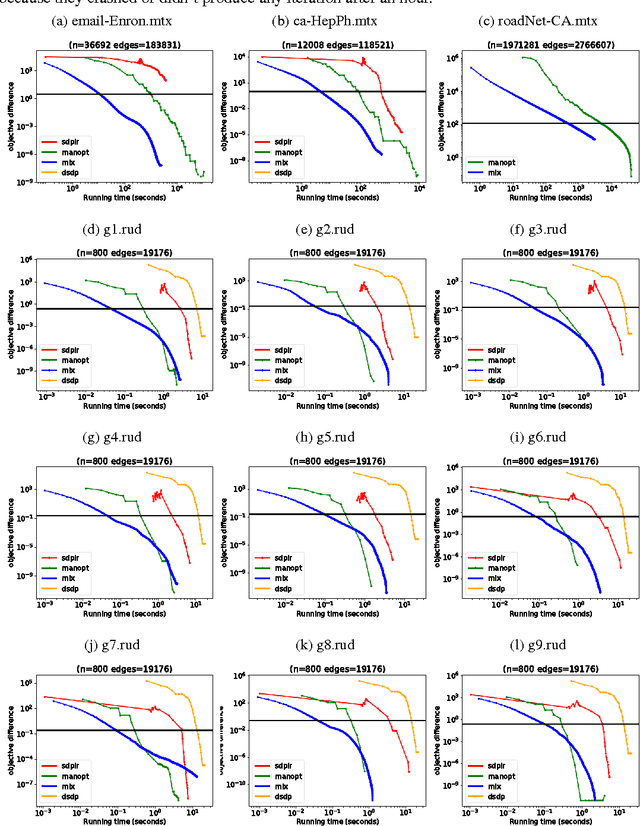
In this paper, we propose a low-rank coordinate descent approach to structured semidefinite programming with diagonal constraints. The approach, which we call the Mixing method, is extremely simple to implement, has no free parameters, and typically attains an order of magnitude or better improvement in optimization performance over the current state of the art. We show that the method is strictly decreasing, converges to a critical point, and further that for sufficient rank all non-optimal critical points are unstable. Moreover, we prove that with a step size, the Mixing method converges to the global optimum of the semidefinite program almost surely in a locally linear rate under random initialization. This is the first low-rank semidefinite programming method that has been shown to achieve a global optimum on the spherical manifold without assumption. We apply our algorithm to two related domains: solving the maximum cut semidefinite relaxation, and solving a maximum satisfiability relaxation (we also briefly consider additional applications such as learning word embeddings). In all settings, we demonstrate substantial improvement over the existing state of the art along various dimensions, and in total, this work expands the scope and scale of problems that can be solved using semidefinite programming methods.
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
Apr 18, 2018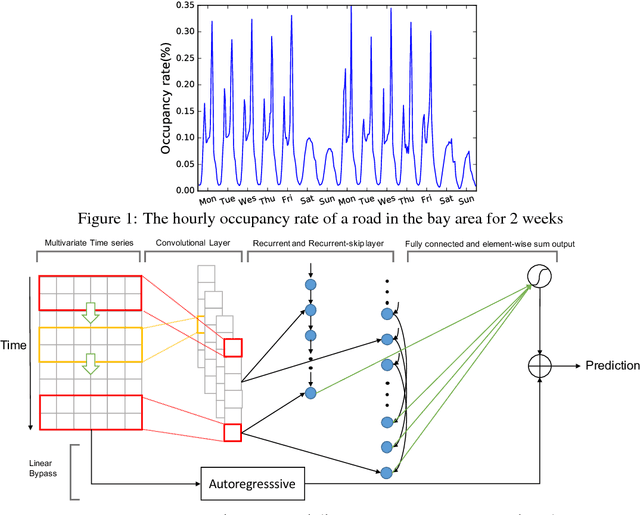
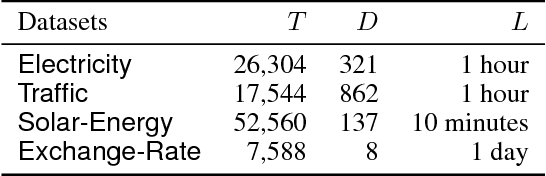
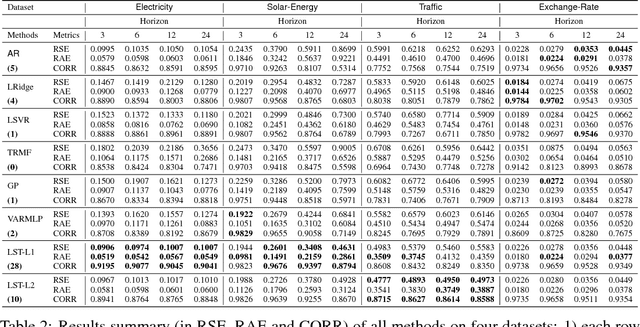
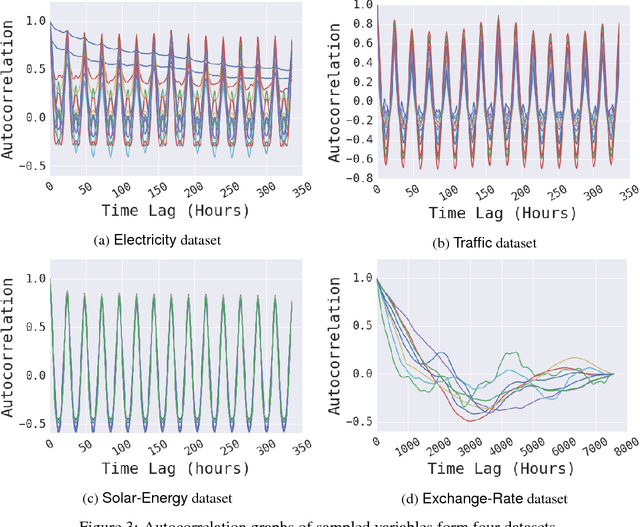
Multivariate time series forecasting is an important machine learning problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. Temporal data arise in these real-world applications often involves a mixture of long-term and short-term patterns, for which traditional approaches such as Autoregressive models and Gaussian Process may fail. In this paper, we proposed a novel deep learning framework, namely Long- and Short-term Time-series network (LSTNet), to address this open challenge. LSTNet uses the Convolution Neural Network (CNN) and the Recurrent Neural Network (RNN) to extract short-term local dependency patterns among variables and to discover long-term patterns for time series trends. Furthermore, we leverage traditional autoregressive model to tackle the scale insensitive problem of the neural network model. In our evaluation on real-world data with complex mixtures of repetitive patterns, LSTNet achieved significant performance improvements over that of several state-of-the-art baseline methods. All the data and experiment codes are available online.
MMD GAN: Towards Deeper Understanding of Moment Matching Network
Nov 27, 2017
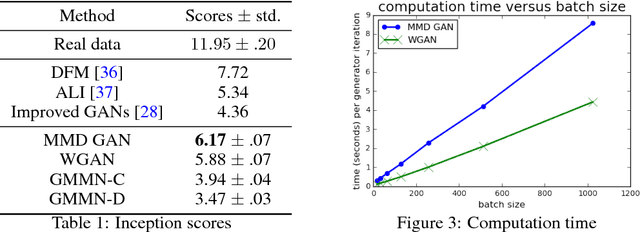

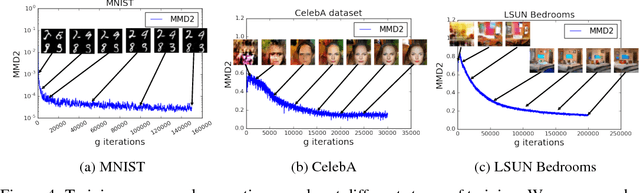
Generative moment matching network (GMMN) is a deep generative model that differs from Generative Adversarial Network (GAN) by replacing the discriminator in GAN with a two-sample test based on kernel maximum mean discrepancy (MMD). Although some theoretical guarantees of MMD have been studied, the empirical performance of GMMN is still not as competitive as that of GAN on challenging and large benchmark datasets. The computational efficiency of GMMN is also less desirable in comparison with GAN, partially due to its requirement for a rather large batch size during the training. In this paper, we propose to improve both the model expressiveness of GMMN and its computational efficiency by introducing adversarial kernel learning techniques, as the replacement of a fixed Gaussian kernel in the original GMMN. The new approach combines the key ideas in both GMMN and GAN, hence we name it MMD GAN. The new distance measure in MMD GAN is a meaningful loss that enjoys the advantage of weak topology and can be optimized via gradient descent with relatively small batch sizes. In our evaluation on multiple benchmark datasets, including MNIST, CIFAR- 10, CelebA and LSUN, the performance of MMD-GAN significantly outperforms GMMN, and is competitive with other representative GAN works.
Data-driven Random Fourier Features using Stein Effect
May 23, 2017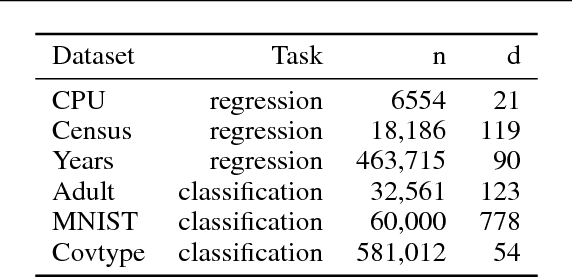
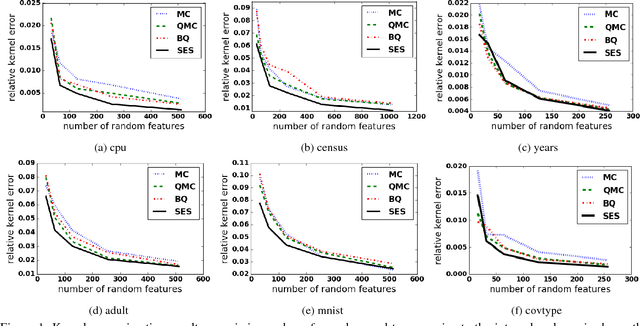
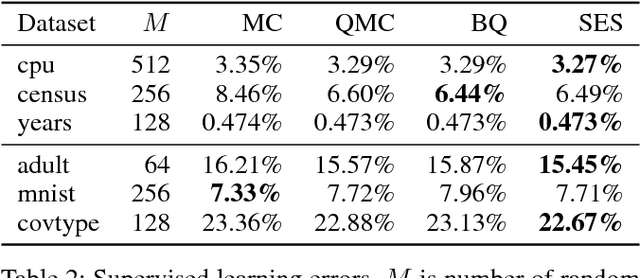
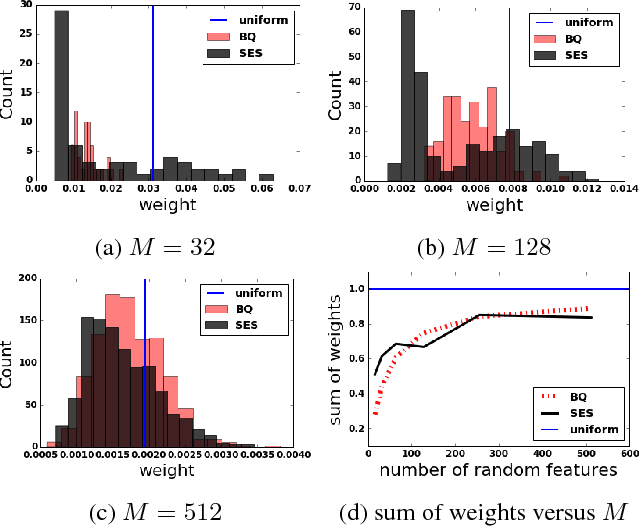
Large-scale kernel approximation is an important problem in machine learning research. Approaches using random Fourier features have become increasingly popular [Rahimi and Recht, 2007], where kernel approximation is treated as empirical mean estimation via Monte Carlo (MC) or Quasi-Monte Carlo (QMC) integration [Yang et al., 2014]. A limitation of the current approaches is that all the features receive an equal weight summing to 1. In this paper, we propose a novel shrinkage estimator from "Stein effect", which provides a data-driven weighting strategy for random features and enjoys theoretical justifications in terms of lowering the empirical risk. We further present an efficient randomized algorithm for large-scale applications of the proposed method. Our empirical results on six benchmark data sets demonstrate the advantageous performance of this approach over representative baselines in both kernel approximation and supervised learning tasks.