 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted Gaze Detection for Proctoring Online Exams
Sep 25, 2024For high-stakes online exams, it is important to detect potential rule violations to ensure the security of the test. In this study, we investigate the task of detecting whether test takers are looking away from the screen, as such behavior could be an indication that the test taker is consulting external resources. For asynchronous proctoring, the exam videos are recorded and reviewed by the proctors. However, when the length of the exam is long, it could be tedious for proctors to watch entire exam videos to determine the exact moments when test takers look away. We present an AI-assisted gaze detection system, which allows proctors to navigate between different video frames and discover video frames where the test taker is looking in similar directions. The system enables proctors to work more effectively to identify suspicious moments in videos. An evaluation framework is proposed to evaluate the system against human-only and ML-only proctoring, and a user study is conducted to gather feedback from proctors, aiming to demonstrate the effectiveness of the system.
Human-in-the-Loop AI for Cheating Ring Detection
Mar 18, 2024


Online exams have become popular in recent years due to their accessibility. However, some concerns have been raised about the security of the online exams, particularly in the context of professional cheating services aiding malicious test takers in passing exams, forming so-called "cheating rings". In this paper, we introduce a human-in-the-loop AI cheating ring detection system designed to detect and deter these cheating rings. We outline the underlying logic of this human-in-the-loop AI system, exploring its design principles tailored to achieve its objectives of detecting cheaters. Moreover, we illustrate the methodologies used to evaluate its performance and fairness, aiming to mitigate the unintended risks associated with the AI system. The design and development of the system adhere to Responsible AI (RAI) standards, ensuring that ethical considerations are integrated throughout the entire development process.
Augmenters at SemEval-2023 Task 1: Enhancing CLIP in Handling Compositionality and Ambiguity for Zero-Shot Visual WSD through Prompt Augmentation and Text-To-Image Diffusion
Jul 09, 2023



This paper describes our zero-shot approaches for the Visual Word Sense Disambiguation (VWSD) Task in English. Our preliminary study shows that the simple approach of matching candidate images with the phrase using CLIP suffers from the many-to-many nature of image-text pairs. We find that the CLIP text encoder may have limited abilities in capturing the compositionality in natural language. Conversely, the descriptive focus of the phrase varies from instance to instance. We address these issues in our two systems, Augment-CLIP and Stable Diffusion Sampling (SD Sampling). Augment-CLIP augments the text prompt by generating sentences that contain the context phrase with the help of large language models (LLMs). We further explore CLIP models in other languages, as the an ambiguous word may be translated into an unambiguous one in the other language. SD Sampling uses text-to-image Stable Diffusion to generate multiple images from the given phrase, increasing the likelihood that a subset of images match the one that paired with the text.
XL-Editor: Post-editing Sentences with XLNet
Oct 19, 2019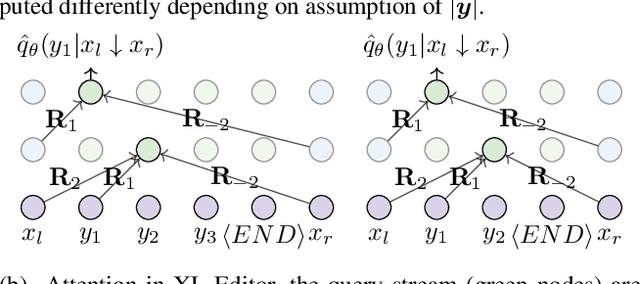
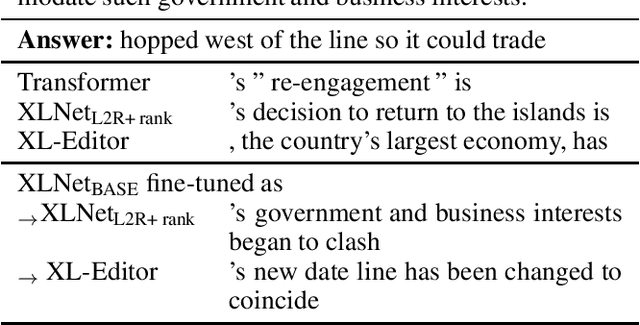
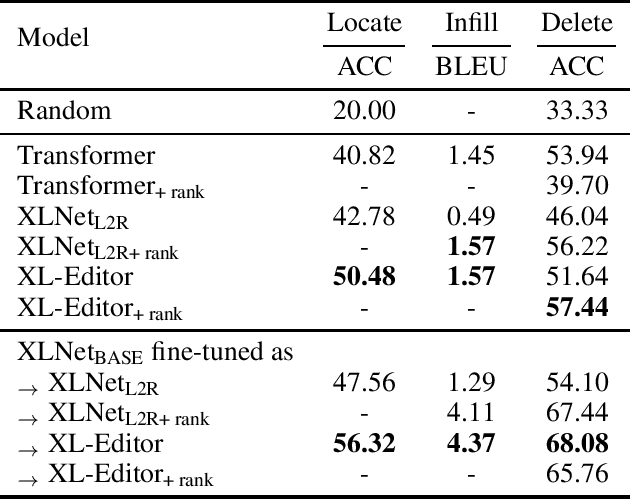

While neural sequence generation models achieve initial success for many NLP applications, the canonical decoding procedure with left-to-right generation order (i.e., autoregressive) in one-pass can not reflect the true nature of human revising a sentence to obtain a refined result. In this work, we propose XL-Editor, a novel training framework that enables state-of-the-art generalized autoregressive pretraining methods, XLNet specifically, to revise a given sentence by the variable-length insertion probability. Concretely, XL-Editor can (1) estimate the probability of inserting a variable-length sequence into a specific position of a given sentence; (2) execute post-editing operations such as insertion, deletion, and replacement based on the estimated variable-length insertion probability; (3) complement existing sequence-to-sequence models to refine the generated sequences. Empirically, we first demonstrate better post-editing capabilities of XL-Editor over XLNet on the text insertion and deletion tasks, which validates the effectiveness of our proposed framework. Furthermore, we extend XL-Editor to the unpaired text style transfer task, where transferring the target style onto a given sentence can be naturally viewed as post-editing the sentence into the target style. XL-Editor achieves significant improvement in style transfer accuracy and also maintains coherent semantic of the original sentence, showing the broad applicability of our method.
Compatibility Family Learning for Item Recommendation and Generation
Dec 02, 2017

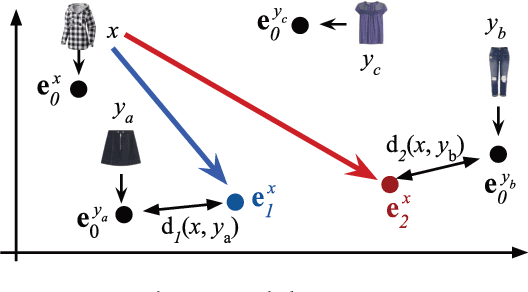
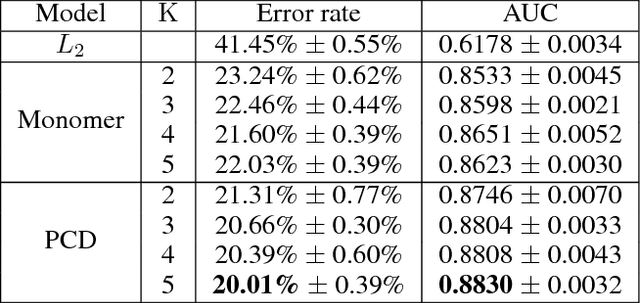
Compatibility between items, such as clothes and shoes, is a major factor among customer's purchasing decisions. However, learning "compatibility" is challenging due to (1) broader notions of compatibility than those of similarity, (2) the asymmetric nature of compatibility, and (3) only a small set of compatible and incompatible items are observed. We propose an end-to-end trainable system to embed each item into a latent vector and project a query item into K compatible prototypes in the same space. These prototypes reflect the broad notions of compatibility. We refer to both the embedding and prototypes as "Compatibility Family". In our learned space, we introduce a novel Projected Compatibility Distance (PCD) function which is differentiable and ensures diversity by aiming for at least one prototype to be close to a compatible item, whereas none of the prototypes are close to an incompatible item. We evaluate our system on a toy dataset, two Amazon product datasets, and Polyvore outfit dataset. Our method consistently achieves state-of-the-art performance. Finally, we show that we can visualize the candidate compatible prototypes using a Metric-regularized Conditional Generative Adversarial Network (MrCGAN), where the input is a projected prototype and the output is a generated image of a compatible item. We ask human evaluators to judge the relative compatibility between our generated images and images generated by CGANs conditioned directly on query items. Our generated images are significantly preferred, with roughly twice the number of votes as others.