 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Real-World Reinforcement Learning for Mobile Agent Obstacle Avoidance
Sep 23, 2022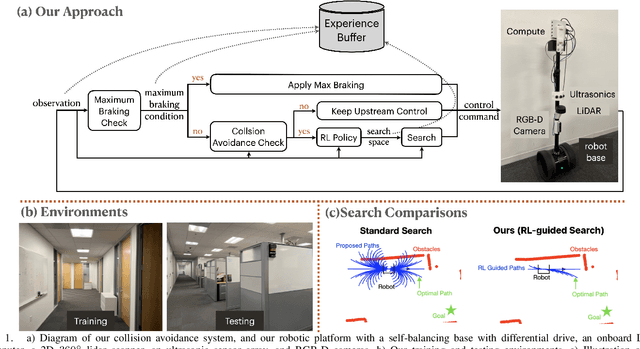
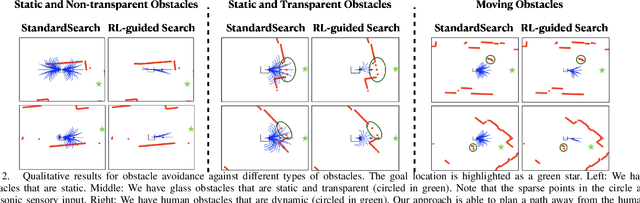


Collision avoidance is key for mobile robots and agents to operate safely in the real world. In this work, we present an efficient and effective collision avoidance system that combines real-world reinforcement learning (RL), search-based online trajectory planning, and automatic emergency intervention, e.g. automatic emergency braking (AEB). The goal of the RL is to learn effective search heuristics that speed up the search for collision-free trajectory and reduce the frequency of triggering automatic emergency interventions. This novel setup enables RL to learn safely and directly on mobile robots in a real-world indoor environment, minimizing actual crashes even during training. Our real-world experiments show that, when compared with several baselines, our approach enjoys a higher average speed, lower crash rate, higher goals reached rate, smaller computation overhead, and smoother overall control.
PGADA: Perturbation-Guided Adversarial Alignment for Few-shot Learning Under the Support-Query Shift
May 08, 2022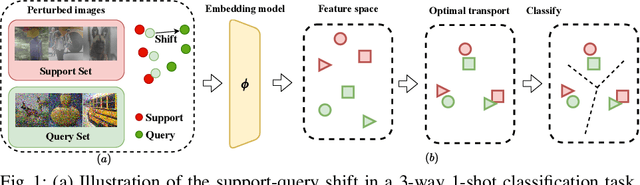
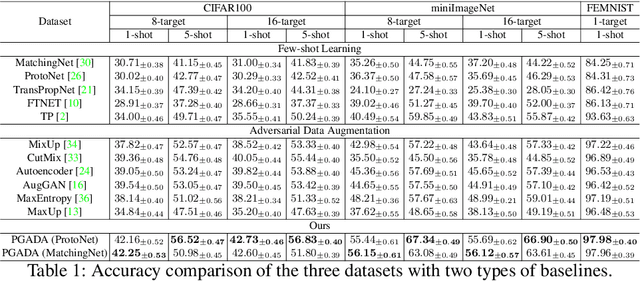
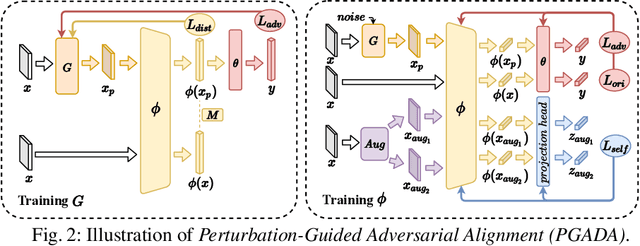
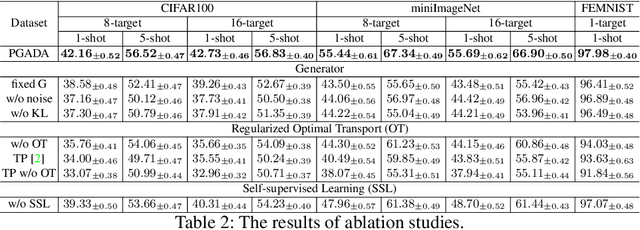
Few-shot learning methods aim to embed the data to a low-dimensional embedding space and then classify the unseen query data to the seen support set. While these works assume that the support set and the query set lie in the same embedding space, a distribution shift usually occurs between the support set and the query set, i.e., the Support-Query Shift, in the real world. Though optimal transportation has shown convincing results in aligning different distributions, we find that the small perturbations in the images would significantly misguide the optimal transportation and thus degrade the model performance. To relieve the misalignment, we first propose a novel adversarial data augmentation method, namely Perturbation-Guided Adversarial Alignment (PGADA), which generates the hard examples in a self-supervised manner. In addition, we introduce Regularized Optimal Transportation to derive a smooth optimal transportation plan. Extensive experiments on three benchmark datasets manifest that our framework significantly outperforms the eleven state-of-the-art methods on three datasets.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021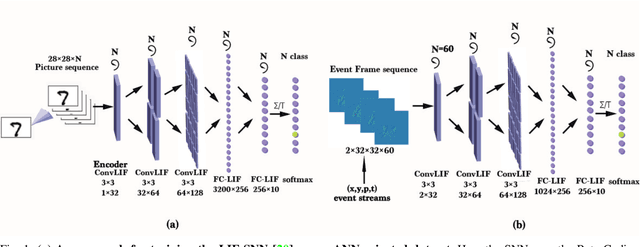
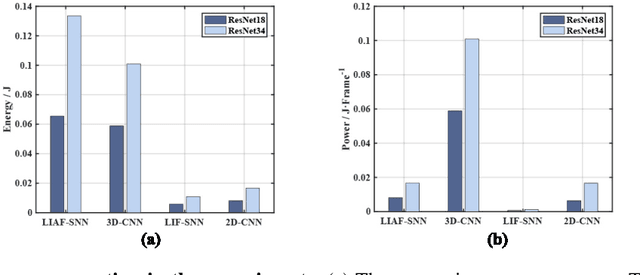
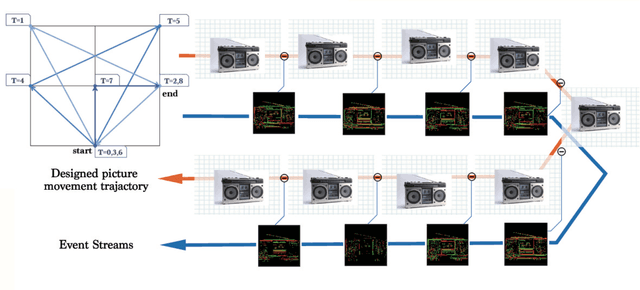
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
CodeTrans: Towards Cracking the Language of Silicone's Code Through Self-Supervised Deep Learning and High Performance Computing
Apr 06, 2021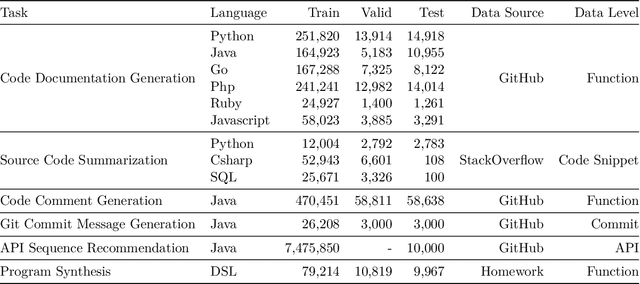
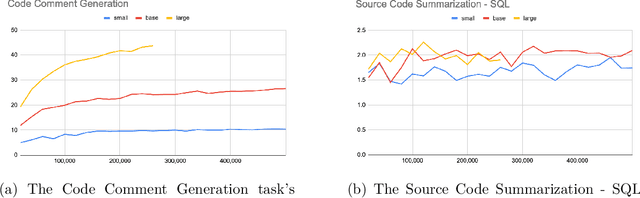
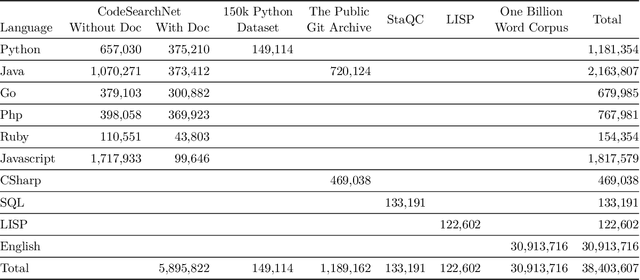
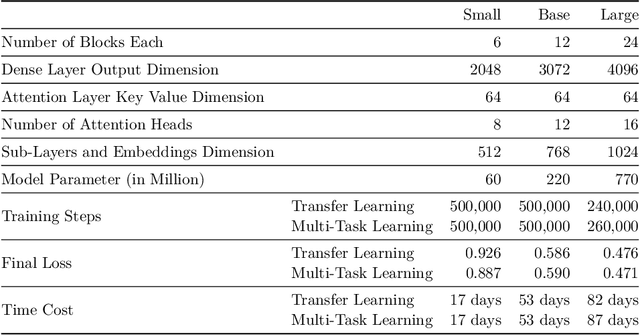
Currently, a growing number of mature natural language processing applications make people's life more convenient. Such applications are built by source code - the language in software engineering. However, the applications for understanding source code language to ease the software engineering process are under-researched. Simultaneously, the transformer model, especially its combination with transfer learning, has been proven to be a powerful technique for natural language processing tasks. These breakthroughs point out a promising direction for process source code and crack software engineering tasks. This paper describes CodeTrans - an encoder-decoder transformer model for tasks in the software engineering domain, that explores the effectiveness of encoder-decoder transformer models for six software engineering tasks, including thirteen sub-tasks. Moreover, we have investigated the effect of different training strategies, including single-task learning, transfer learning, multi-task learning, and multi-task learning with fine-tuning. CodeTrans outperforms the state-of-the-art models on all the tasks. To expedite future works in the software engineering domain, we have published our pre-trained models of CodeTrans. https://github.com/agemagician/CodeTrans
Learning a Proposal Classifier for Multiple Object Tracking
Mar 26, 2021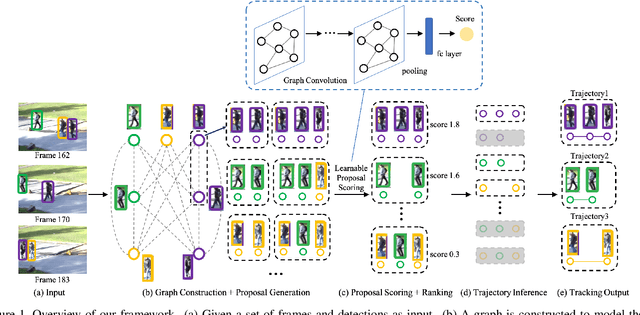
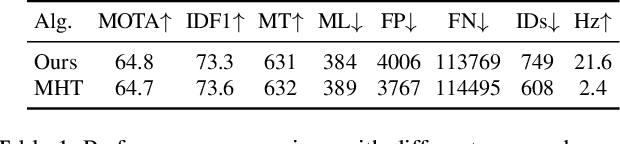
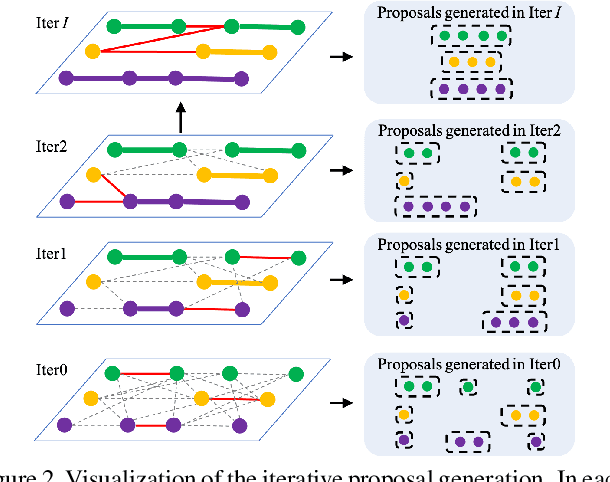
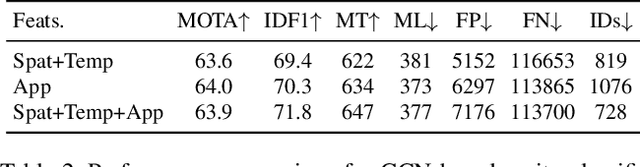
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. However, it is not trivial to solve the data-association problem in an end-to-end fashion. In this paper, we propose a novel proposal-based learnable framework, which models MOT as a proposal generation, proposal scoring and trajectory inference paradigm on an affinity graph. This framework is similar to the two-stage object detector Faster RCNN, and can solve the MOT problem in a data-driven way. For proposal generation, we propose an iterative graph clustering method to reduce the computational cost while maintaining the quality of the generated proposals. For proposal scoring, we deploy a trainable graph-convolutional-network (GCN) to learn the structural patterns of the generated proposals and rank them according to the estimated quality scores. For trajectory inference, a simple deoverlapping strategy is adopted to generate tracking output while complying with the constraints that no detection can be assigned to more than one track. We experimentally demonstrate that the proposed method achieves a clear performance improvement in both MOTA and IDF1 with respect to previous state-of-the-art on two public benchmarks. Our code is available at https://github.com/daip13/LPC_MOT.git.
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Aug 13, 2020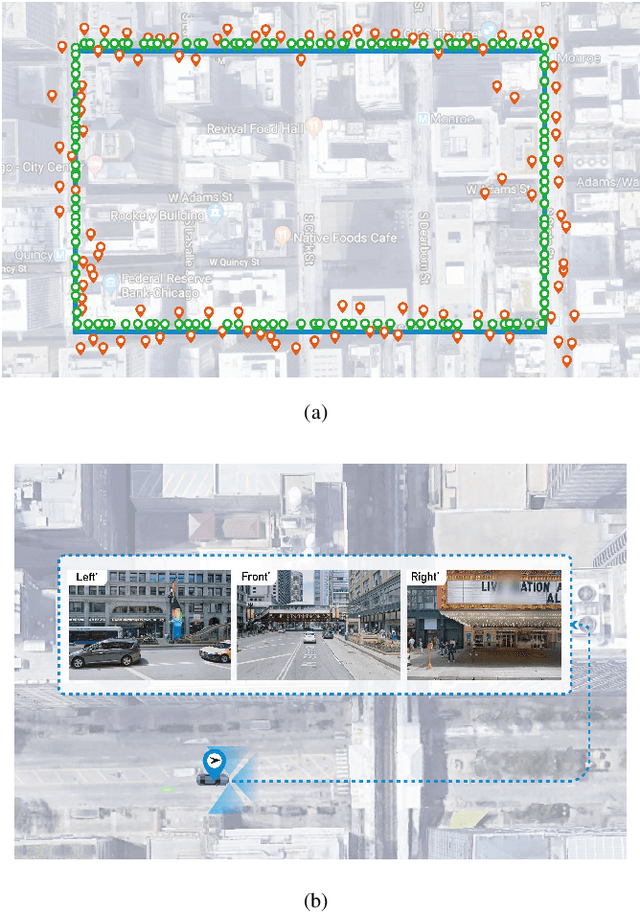
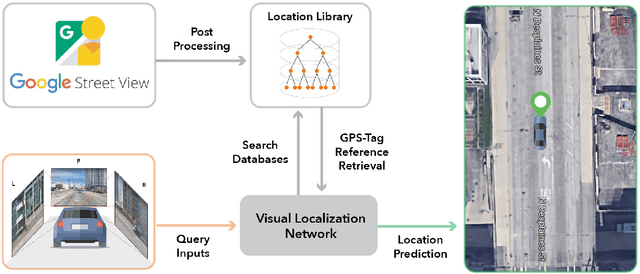
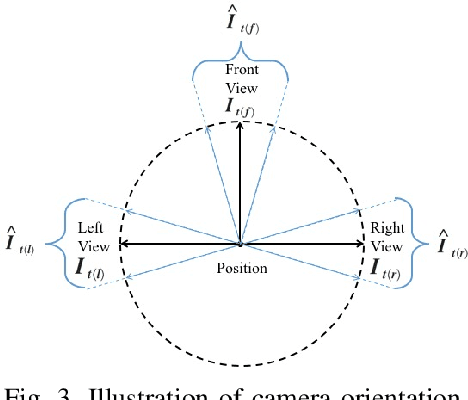
Accurate localization is a foundational capacity, required for autonomous vehicles to accomplish other tasks such as navigation or path planning. It is a common practice for vehicles to use GPS to acquire location information. However, the application of GPS can result in severe challenges when vehicles run within the inner city where different kinds of structures may shadow the GPS signal and lead to inaccurate location results. To address the localization challenges of urban settings, we propose a novel feature voting technique for visual localization. Different from the conventional front-view-based method, our approach employs views from three directions (front, left, and right) and thus significantly improves the robustness of location prediction. In our work, we craft the proposed feature voting method into three state-of-the-art visual localization networks and modify their architectures properly so that they can be applied for vehicular operation. Extensive field test results indicate that our approach can predict location robustly even in challenging inner-city settings. Our research sheds light on using the visual localization approach to help autonomous vehicles to find accurate location information in a city maze, within a desirable time constraint.
Comparing SNNs and RNNs on Neuromorphic Vision Datasets: Similarities and Differences
May 02, 2020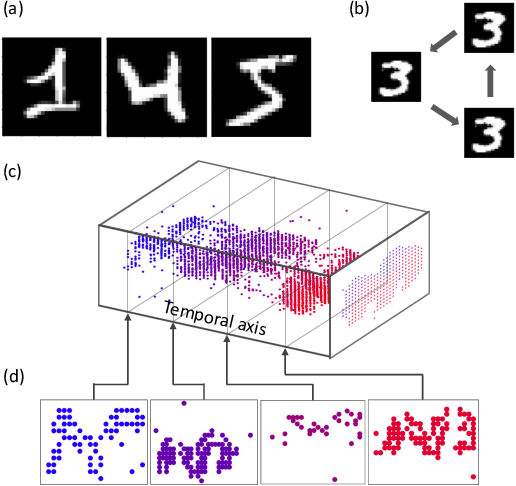
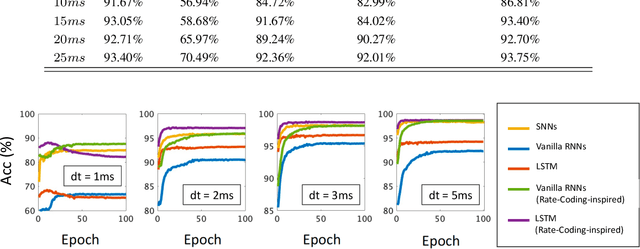
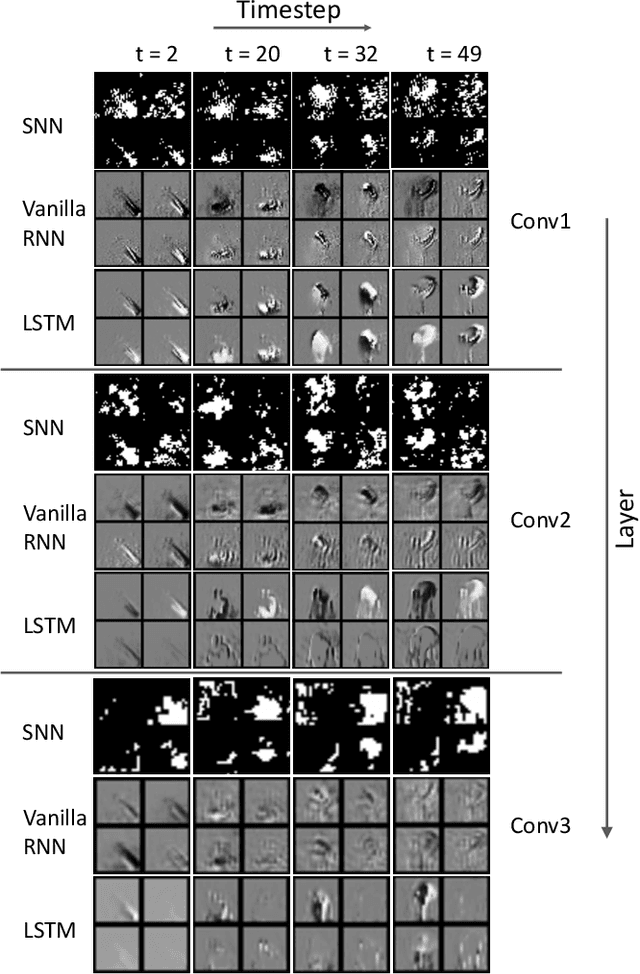
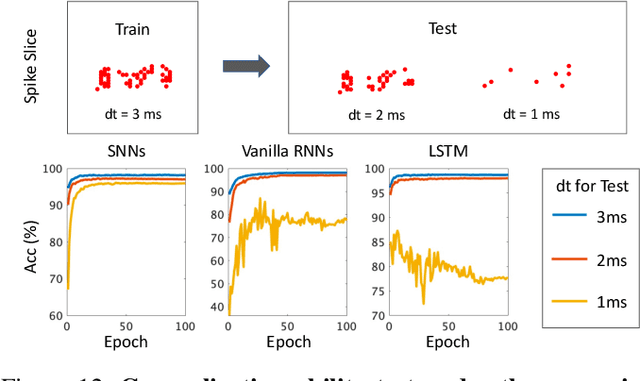
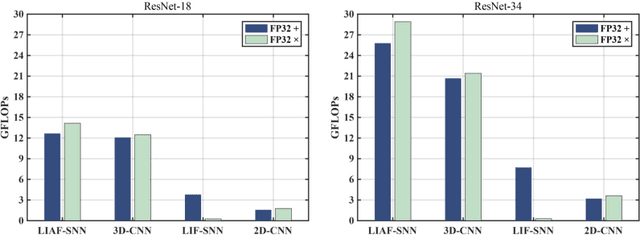
Neuromorphic data, recording frameless spike events, have attracted considerable attention for the spatiotemporal information components and the event-driven processing fashion. Spiking neural networks (SNNs) represent a family of event-driven models with spatiotemporal dynamics for neuromorphic computing, which are widely benchmarked on neuromorphic data. Interestingly, researchers in the machine learning community can argue that recurrent (artificial) neural networks (RNNs) also have the capability to extract spatiotemporal features although they are not event-driven. Thus, the question of "what will happen if we benchmark these two kinds of models together on neuromorphic data" comes out but remains unclear. In this work, we make a systematic study to compare SNNs and RNNs on neuromorphic data, taking the vision datasets as a case study. First, we identify the similarities and differences between SNNs and RNNs (including the vanilla RNNs and LSTM) from the modeling and learning perspectives. To improve comparability and fairness, we unify the supervised learning algorithm based on backpropagation through time (BPTT), the loss function exploiting the outputs at all timesteps, the network structure with stacked fully-connected or convolutional layers, and the hyper-parameters during training. Especially, given the mainstream loss function used in RNNs, we modify it inspired by the rate coding scheme to approach that of SNNs. Furthermore, we tune the temporal resolution of datasets to test model robustness and generalization. At last, a series of contrast experiments are conducted on two types of neuromorphic datasets: DVS-converted (N-MNIST) and DVS-captured (DVS Gesture).
Mitigating Class Boundary Label Uncertainty to Reduce Both Model Bias and Variance
Feb 23, 2020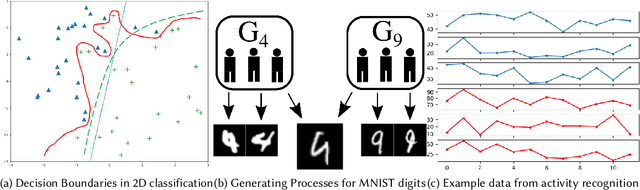
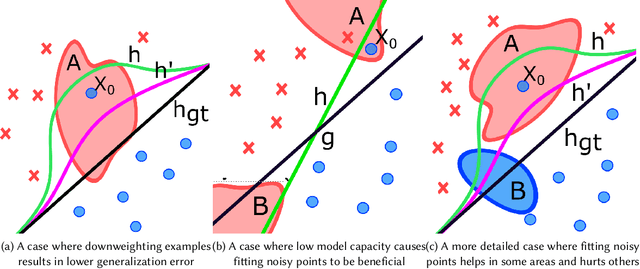
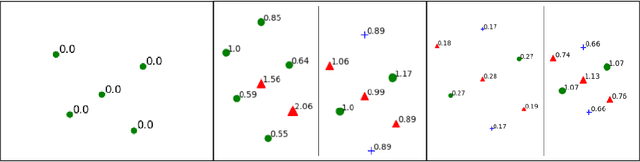
The study of model bias and variance with respect to decision boundaries is critically important in supervised classification. There is generally a tradeoff between the two, as fine-tuning of the decision boundary of a classification model to accommodate more boundary training samples (i.e., higher model complexity) may improve training accuracy (i.e., lower bias) but hurt generalization against unseen data (i.e., higher variance). By focusing on just classification boundary fine-tuning and model complexity, it is difficult to reduce both bias and variance. To overcome this dilemma, we take a different perspective and investigate a new approach to handle inaccuracy and uncertainty in the training data labels, which are inevitable in many applications where labels are conceptual and labeling is performed by human annotators. The process of classification can be undermined by uncertainty in the labels of the training data; extending a boundary to accommodate an inaccurately labeled point will increase both bias and variance. Our novel method can reduce both bias and variance by estimating the pointwise label uncertainty of the training set and accordingly adjusting the training sample weights such that those samples with high uncertainty are weighted down and those with low uncertainty are weighted up. In this way, uncertain samples have a smaller contribution to the objective function of the model's learning algorithm and exert less pull on the decision boundary. In a real-world physical activity recognition case study, the data presents many labeling challenges, and we show that this new approach improves model performance and reduces model variance.
SummerTime: Variable-length Time SeriesSummarization with Applications to PhysicalActivity Analysis
Feb 20, 2020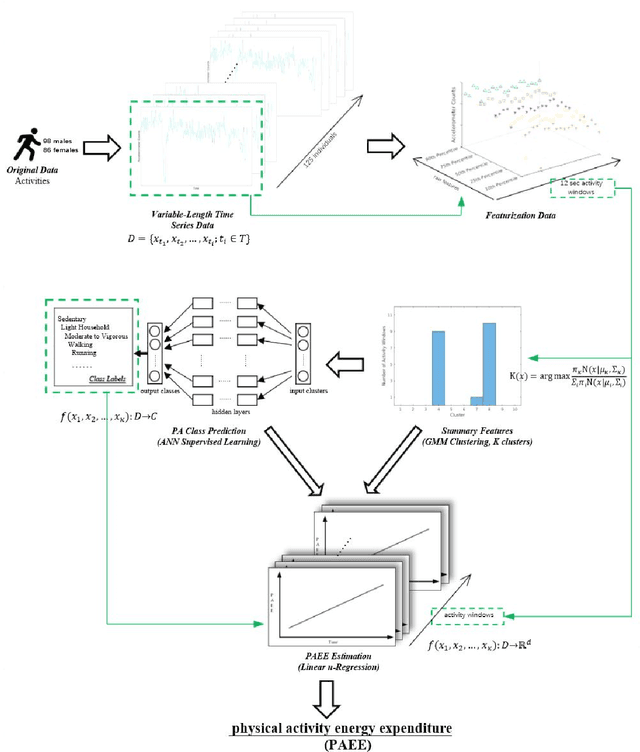
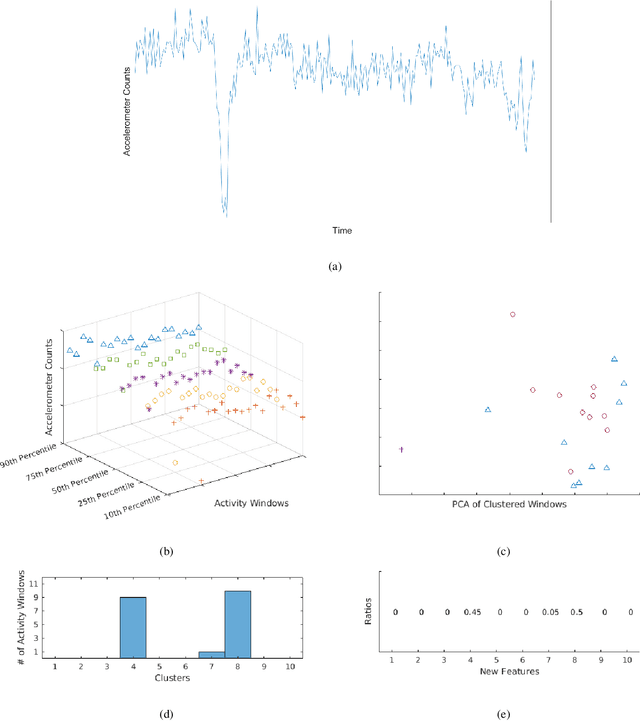
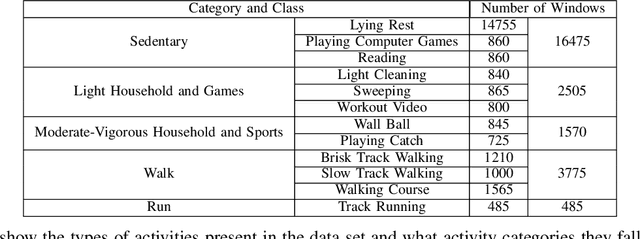
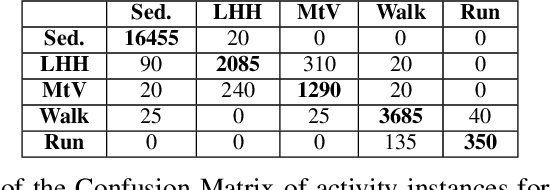
\textit{SummerTime} seeks to summarize globally time series signals and provides a fixed-length, robust summarization of the variable-length time series. Many classical machine learning methods for classification and regression depend on data instances with a fixed number of features. As a result, those methods cannot be directly applied to variable-length time series data. One common approach is to perform classification over a sliding window on the data and aggregate the decisions made at local sections of the time series in some way, through majority voting for classification or averaging for regression. The downside to this approach is that minority local information is lost in the voting process and averaging assumes that each time series measurement is equal in significance. Also, since time series can be of varying length, the quality of votes and averages could vary greatly in cases where there is a close voting tie or bimodal distribution of regression domain. Summarization conducted by the \textit{SummerTime} method will be a fixed-length feature vector which can be used in-place of the time series dataset for use with classical machine learning methods. We use Gaussian Mixture models (GMM) over small same-length disjoint windows in the time series to group local data into clusters. The time series' rate of membership for each cluster will be a feature in the summarization. The model is naturally capable of converging to an appropriate cluster count. We compare our results to state-of-the-art studies in physical activity classification and show high-quality improvement by classifying with only the summarization. Finally, we show that regression using the summarization can augment energy expenditure estimation, producing more robust and precise results.
Measuring similarity between geo-tagged videos using largest common view
Apr 28, 2019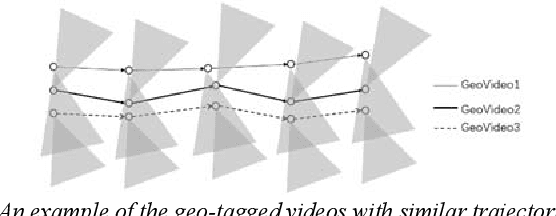
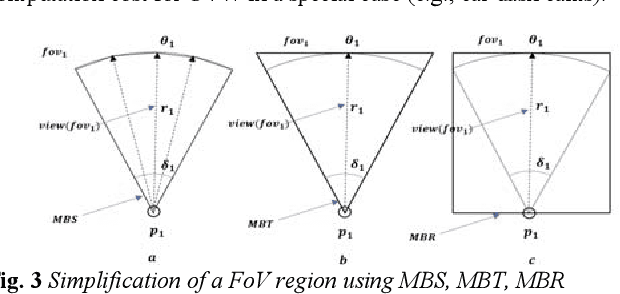
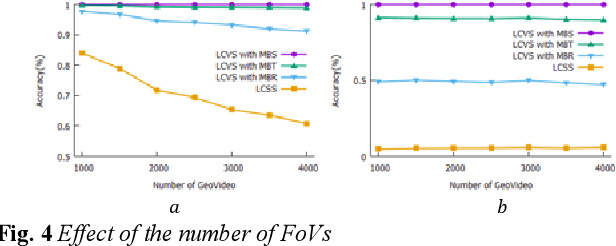
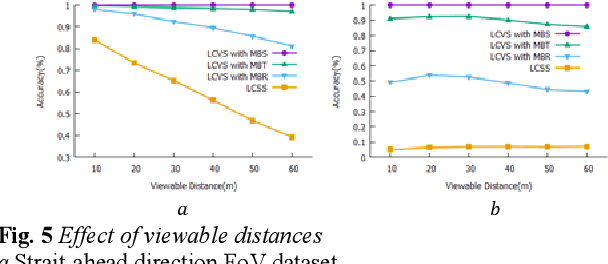
This paper presents a novel problem for discovering the similar trajectories based on the field of view (FoV) of the video data. The problem is important for many societal applications such as grouping moving objects, classifying geo-images, and identifying the interesting trajectory patterns. Prior work consider only either spatial locations or spatial relationship between two line-segments. However, these approaches show a limitation to find the similar moving objects with common views. In this paper, we propose new algorithm that can group both spatial locations and points of view to identify similar trajectories. We also propose novel methods that reduce the computational cost for the proposed work. Experimental results using real-world datasets demonstrates that the proposed approach outperforms prior work and reduces the computational cost.
* 2 pages