 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseRide: A Robotic Wheelchair for Personalized Exertion Control with Human-in-the-Loop Reinforcement Learning
Jun 05, 2025Maintaining an active lifestyle is vital for quality of life, yet challenging for wheelchair users. For instance, powered wheelchairs face increasing risks of obesity and deconditioning due to inactivity. Conversely, manual wheelchair users, who propel the wheelchair by pushing the wheelchair's handrims, often face upper extremity injuries from repetitive motions. These challenges underscore the need for a mobility system that promotes activity while minimizing injury risk. Maintaining optimal exertion during wheelchair use enhances health benefits and engagement, yet the variations in individual physiological responses complicate exertion optimization. To address this, we introduce PulseRide, a novel wheelchair system that provides personalized assistance based on each user's physiological responses, helping them maintain their physical exertion goals. Unlike conventional assistive systems focused on obstacle avoidance and navigation, PulseRide integrates real-time physiological data-such as heart rate and ECG-with wheelchair speed to deliver adaptive assistance. Using a human-in-the-loop reinforcement learning approach with Deep Q-Network algorithm (DQN), the system adjusts push assistance to keep users within a moderate activity range without under- or over-exertion. We conducted preliminary tests with 10 users on various terrains, including carpet and slate, to assess PulseRide's effectiveness. Our findings show that, for individual users, PulseRide maintains heart rates within the moderate activity zone as much as 71.7 percent longer than manual wheelchairs. Among all users, we observed an average reduction in muscle contractions of 41.86 percent, delaying fatigue onset and enhancing overall comfort and engagement. These results indicate that PulseRide offers a healthier, adaptive mobility solution, bridging the gap between passive and physically taxing mobility options.
Mitigating Class Boundary Label Uncertainty to Reduce Both Model Bias and Variance
Feb 23, 2020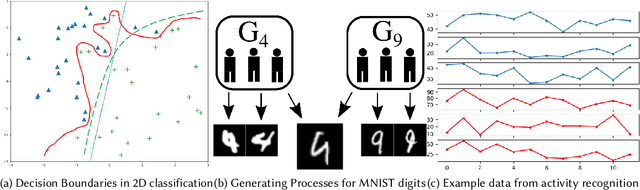
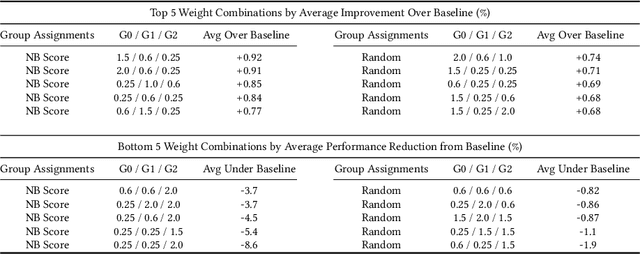
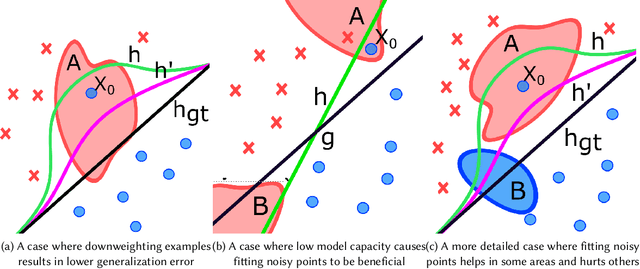
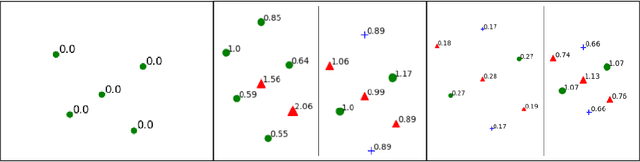
The study of model bias and variance with respect to decision boundaries is critically important in supervised classification. There is generally a tradeoff between the two, as fine-tuning of the decision boundary of a classification model to accommodate more boundary training samples (i.e., higher model complexity) may improve training accuracy (i.e., lower bias) but hurt generalization against unseen data (i.e., higher variance). By focusing on just classification boundary fine-tuning and model complexity, it is difficult to reduce both bias and variance. To overcome this dilemma, we take a different perspective and investigate a new approach to handle inaccuracy and uncertainty in the training data labels, which are inevitable in many applications where labels are conceptual and labeling is performed by human annotators. The process of classification can be undermined by uncertainty in the labels of the training data; extending a boundary to accommodate an inaccurately labeled point will increase both bias and variance. Our novel method can reduce both bias and variance by estimating the pointwise label uncertainty of the training set and accordingly adjusting the training sample weights such that those samples with high uncertainty are weighted down and those with low uncertainty are weighted up. In this way, uncertain samples have a smaller contribution to the objective function of the model's learning algorithm and exert less pull on the decision boundary. In a real-world physical activity recognition case study, the data presents many labeling challenges, and we show that this new approach improves model performance and reduces model variance.
SummerTime: Variable-length Time SeriesSummarization with Applications to PhysicalActivity Analysis
Feb 20, 2020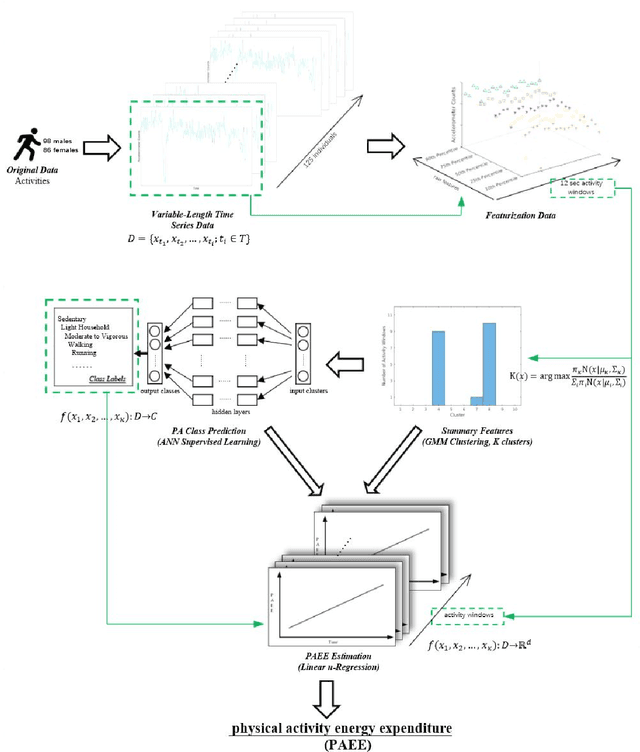
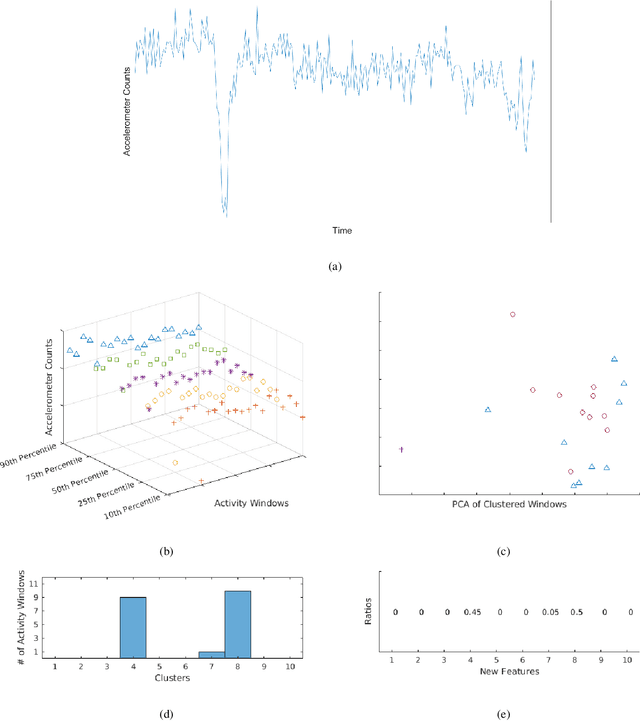
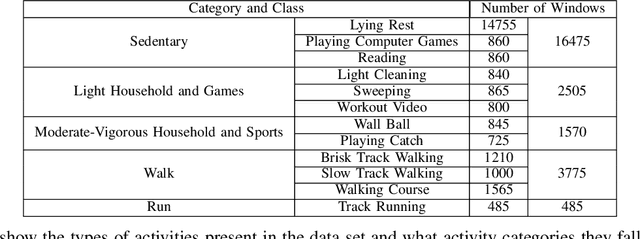
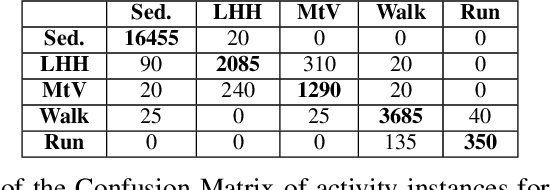
\textit{SummerTime} seeks to summarize globally time series signals and provides a fixed-length, robust summarization of the variable-length time series. Many classical machine learning methods for classification and regression depend on data instances with a fixed number of features. As a result, those methods cannot be directly applied to variable-length time series data. One common approach is to perform classification over a sliding window on the data and aggregate the decisions made at local sections of the time series in some way, through majority voting for classification or averaging for regression. The downside to this approach is that minority local information is lost in the voting process and averaging assumes that each time series measurement is equal in significance. Also, since time series can be of varying length, the quality of votes and averages could vary greatly in cases where there is a close voting tie or bimodal distribution of regression domain. Summarization conducted by the \textit{SummerTime} method will be a fixed-length feature vector which can be used in-place of the time series dataset for use with classical machine learning methods. We use Gaussian Mixture models (GMM) over small same-length disjoint windows in the time series to group local data into clusters. The time series' rate of membership for each cluster will be a feature in the summarization. The model is naturally capable of converging to an appropriate cluster count. We compare our results to state-of-the-art studies in physical activity classification and show high-quality improvement by classifying with only the summarization. Finally, we show that regression using the summarization can augment energy expenditure estimation, producing more robust and precise results.
Bag-of-Words Method Applied to Accelerometer Measurements for the Purpose of Classification and Energy Estimation
Apr 12, 2017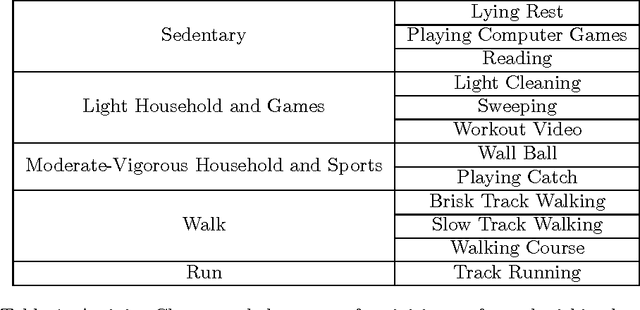
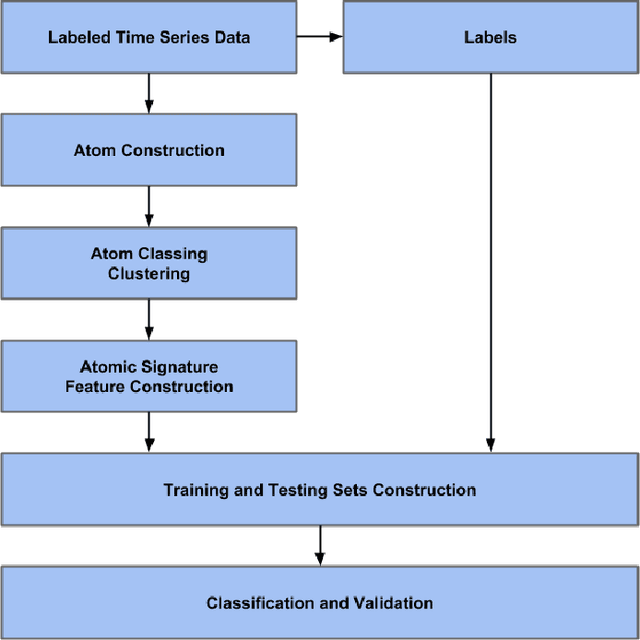
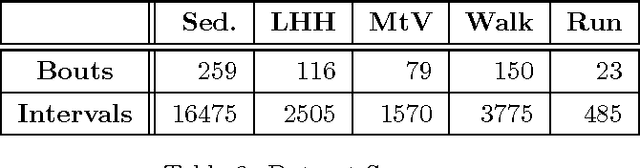
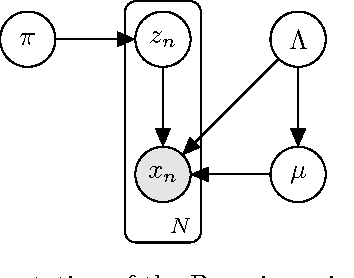
Accelerometer measurements are the prime type of sensor information most think of when seeking to measure physical activity. On the market, there are many fitness measuring devices which aim to track calories burned and steps counted through the use of accelerometers. These measurements, though good enough for the average consumer, are noisy and unreliable in terms of the precision of measurement needed in a scientific setting. The contribution of this paper is an innovative and highly accurate regression method which uses an intermediary two-stage classification step to better direct the regression of energy expenditure values from accelerometer counts. We show that through an additional unsupervised layer of intermediate feature construction, we can leverage latent patterns within accelerometer counts to provide better grounds for activity classification than expert-constructed timeseries features. For this, our approach utilizes a mathematical model originating in natural language processing, the bag-of-words model, that has in the past years been appearing in diverse disciplines outside of the natural language processing field such as image processing. Further emphasizing the natural language connection to stochastics, we use a gaussian mixture model to learn the dictionary upon which the bag-of-words model is built. Moreover, we show that with the addition of these features, we're able to improve regression root mean-squared error of energy expenditure by approximately 1.4 units over existing state-of-the-art methods.