 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualizing Variation in Text Style Transfer Datasets
Aug 17, 2021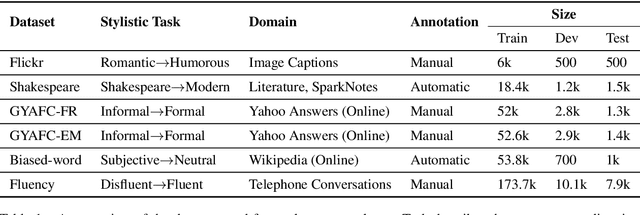

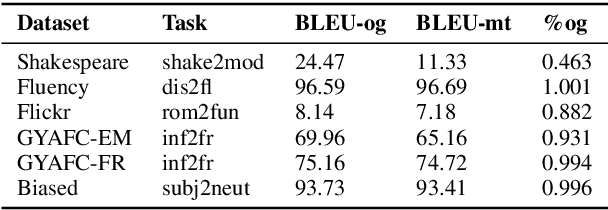
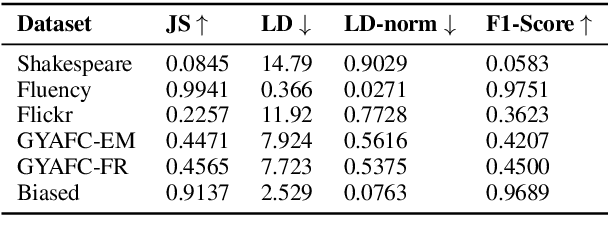
Text style transfer involves rewriting the content of a source sentence in a target style. Despite there being a number of style tasks with available data, there has been limited systematic discussion of how text style datasets relate to each other. This understanding, however, is likely to have implications for selecting multiple data sources for model training. While it is prudent to consider inherent stylistic properties when determining these relationships, we also must consider how a style is realized in a particular dataset. In this paper, we conduct several empirical analyses of existing text style datasets. Based on our results, we propose a categorization of stylistic and dataset properties to consider when utilizing or comparing text style datasets.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
An Empirical Comparison on Imitation Learning and Reinforcement Learning for Paraphrase Generation
Aug 28, 2019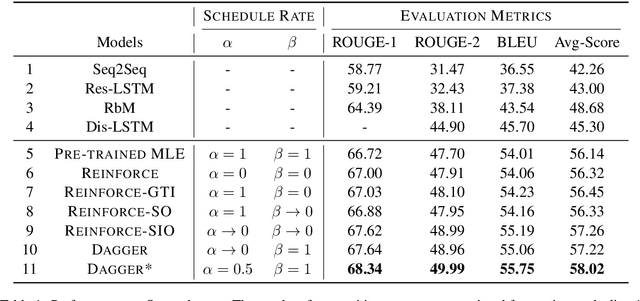
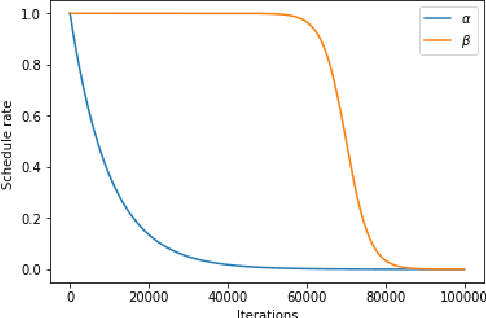
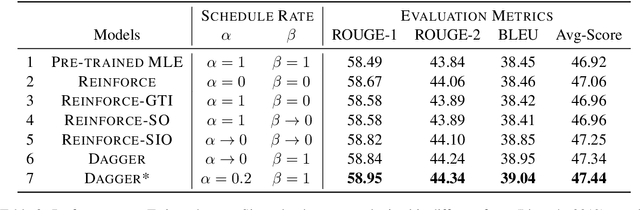
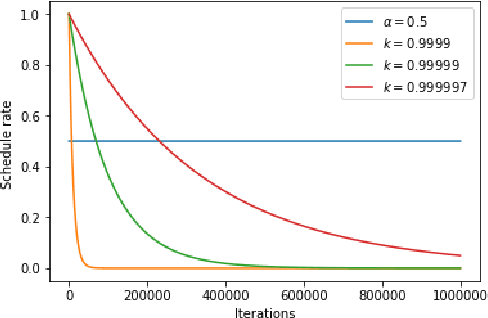
Generating paraphrases from given sentences involves decoding words step by step from a large vocabulary. To learn a decoder, supervised learning which maximizes the likelihood of tokens always suffers from the exposure bias. Although both reinforcement learning (RL) and imitation learning (IL) have been widely used to alleviate the bias, the lack of direct comparison leads to only a partial image on their benefits. In this work, we present an empirical study on how RL and IL can help boost the performance of generating paraphrases, with the pointer-generator as a base model. Experiments on the benchmark datasets show that (1) imitation learning is constantly better than reinforcement learning; and (2) the pointer-generator models with imitation learning outperform the state-of-the-art methods with a large margin.