 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensic Analysis of Synthetically Generated Scientific Images
Dec 16, 2021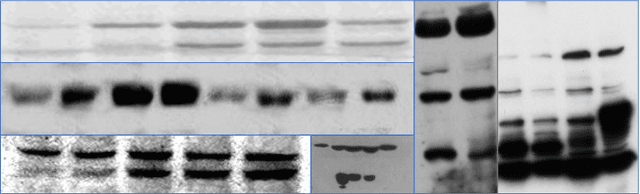

The widespread diffusion of synthetically generated content is a serious threat that needs urgent countermeasures. The generation of synthetic content is not restricted to multimedia data like videos, photographs, or audio sequences, but covers a significantly vast area that can include biological images as well, such as western-blot and microscopic images. In this paper, we focus on the detection of synthetically generated western-blot images. Western-blot images are largely explored in the biomedical literature and it has been already shown how these images can be easily counterfeited with few hope to spot manipulations by visual inspection or by standard forensics detectors. To overcome the absence of a publicly available dataset, we create a new dataset comprising more than 14K original western-blot images and 18K synthetic western-blot images, generated by three different state-of-the-art generation methods. Then, we investigate different strategies to detect synthetic western blots, exploring binary classification methods as well as one-class detectors. In both scenarios, we never exploit synthetic western-blot images at training stage. The achieved results show that synthetically generated western-blot images can be spot with good accuracy, even though the exploited detectors are not optimized over synthetic versions of these scientific images.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021
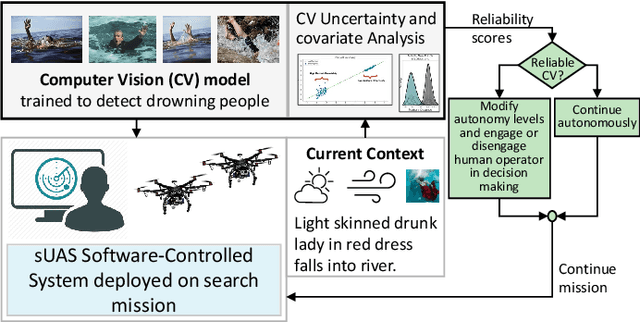

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
The Criminality From Face Illusion
Jun 06, 2020
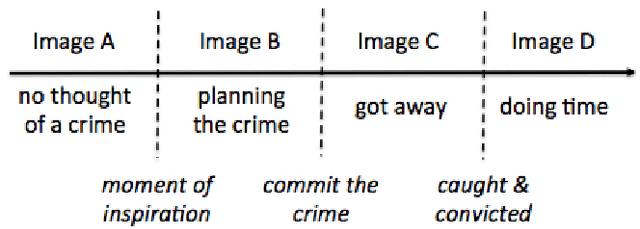

The automatic analysis of face images can generate predictions about a person's gender, age, race, facial expression, body mass index, and various other indices and conditions. A few recent publications have claimed success in analyzing an image of a person's face in order to predict the person's status as Criminal / Non-Criminal. Predicting criminality from face may initially seem similar to other facial analytics, but we argue that attempts to create a criminality-from-face algorithm are necessarily doomed to fail, that apparently promising experimental results in recent publications are an illusion resulting from inadequate experimental design, and that there is potentially a large social cost to belief in the criminality from face illusion.
Automatic Discovery of Political Meme Genres with Diverse Appearances
Jan 17, 2020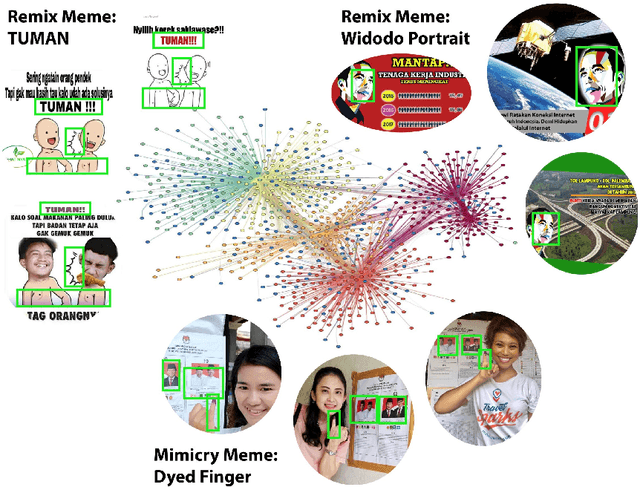
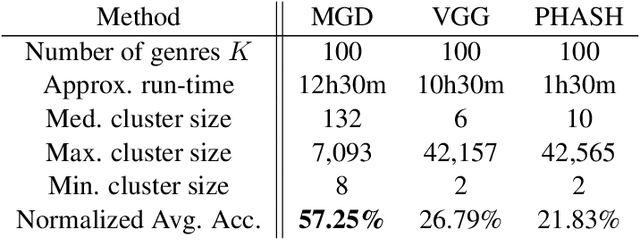
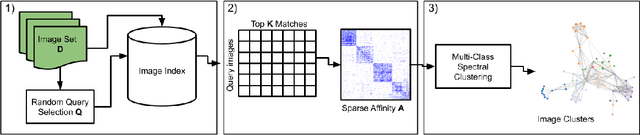

Forms of human communication are not static --- we expect some evolution in the way information is conveyed over time because of advances in technology. One example of this phenomenon is the image-based meme, which has emerged as a dominant form of political messaging in the past decade. While originally used to spread jokes on social media, memes are now having an outsized impact on public perception of world events. A significant challenge in automatic meme analysis has been the development of a strategy to match memes from within a single genre when the appearances of the images vary. Such variation is especially common in memes exhibiting mimicry. For example, when voters perform a common hand gesture to signal their support for a candidate. In this paper we introduce a scalable automated visual recognition pipeline for discovering political meme genres of diverse appearance. This pipeline can ingest meme images from a social network, apply computer vision-based techniques to extract local features and index new images into a database, and then organize the memes into related genres. To validate this approach, we perform a large case study on the 2019 Indonesian Presidential Election using a new dataset of over two million images collected from Twitter and Instagram. Results show that this approach can discover new meme genres with visually diverse images that share common stylistic elements, paving the way forward for further work in semantic analysis and content attribution.
Learning Transformation-Aware Embeddings for Image Forensics
Jan 13, 2020
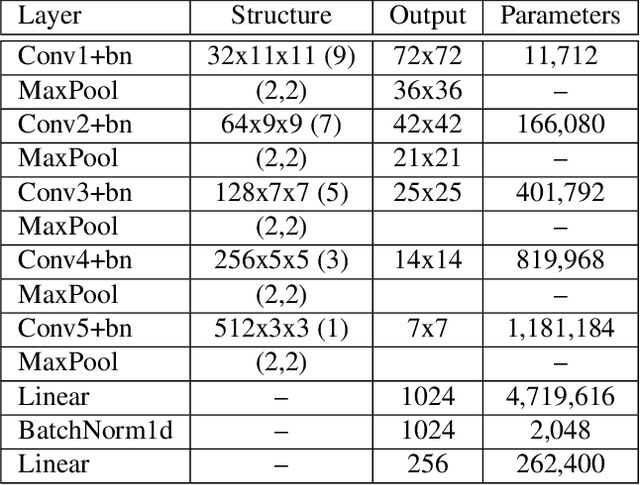

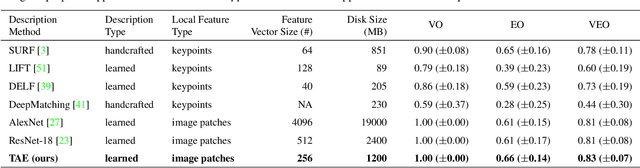
A dramatic rise in the flow of manipulated image content on the Internet has led to an aggressive response from the media forensics research community. New efforts have incorporated increased usage of techniques from computer vision and machine learning to detect and profile the space of image manipulations. This paper addresses Image Provenance Analysis, which aims at discovering relationships among different manipulated image versions that share content. One of the main sub-problems for provenance analysis that has not yet been addressed directly is the edit ordering of images that share full content or are near-duplicates. The existing large networks that generate image descriptors for tasks such as object recognition may not encode the subtle differences between these image covariates. This paper introduces a novel deep learning-based approach to provide a plausible ordering to images that have been generated from a single image through transformations. Our approach learns transformation-aware descriptors using weak supervision via composited transformations and a rank-based quadruplet loss. To establish the efficacy of the proposed approach, comparisons with state-of-the-art handcrafted and deep learning-based descriptors, and image matching approaches are made. Further experimentation validates the proposed approach in the context of image provenance analysis.
Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance for Low-Resource Machine Translation
Oct 01, 2019
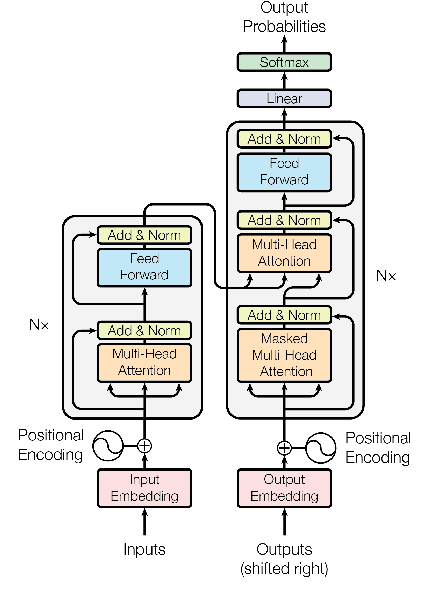
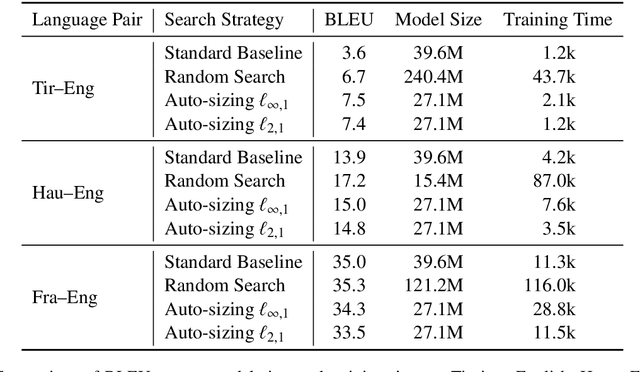
Neural sequence-to-sequence models, particularly the Transformer, are the state of the art in machine translation. Yet these neural networks are very sensitive to architecture and hyperparameter settings. Optimizing these settings by grid or random search is computationally expensive because it requires many training runs. In this paper, we incorporate architecture search into a single training run through auto-sizing, which uses regularization to delete neurons in a network over the course of training. On very low-resource language pairs, we show that auto-sizing can improve BLEU scores by up to 3.9 points while removing one-third of the parameters from the model.
Needle in a Haystack: A Framework for Seeking Small Objects in Big Datasets
Apr 10, 2019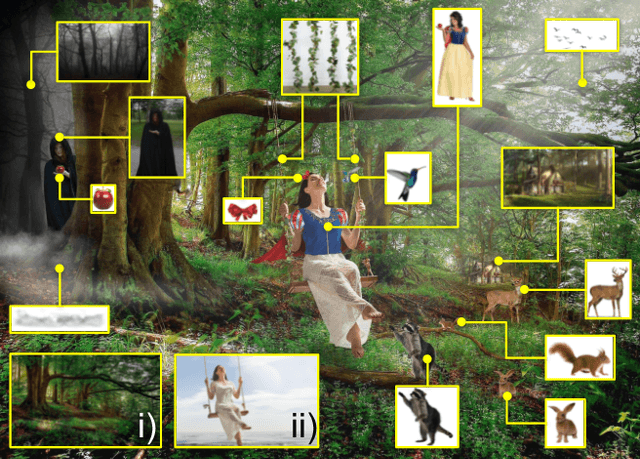
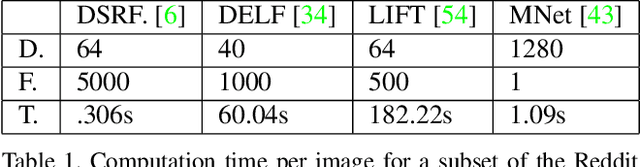
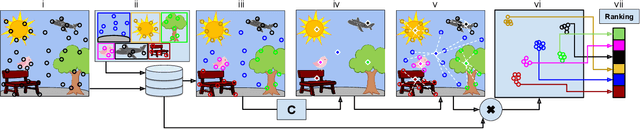
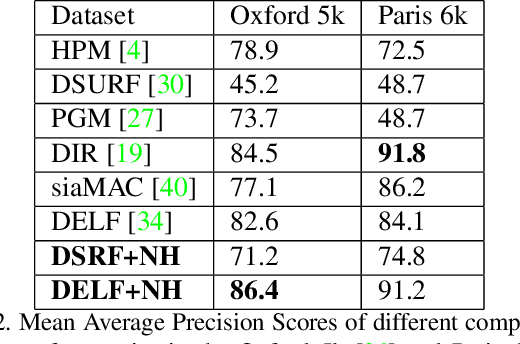
Images from social media can reflect diverse viewpoints, heated arguments, and expressions of creativity --- adding new complexity to search tasks. Researchers working on Content-Based Image Retrieval (CBIR) have traditionally tuned their search algorithms to match filtered results with user search intent. However, we are now bombarded with composite images of unknown origin, authenticity, and even meaning. With such uncertainty, users may not have an initial idea of what the results of a search query should look like. For instance, hidden people, spliced objects, and subtly altered scenes can be difficult for a user to detect initially in a meme image, but may contribute significantly to its composition. We propose a new framework for image retrieval that models object-level regions using image keypoints retrieved from an image index, which are then used to accurately weight small contributing objects within the results, without the need for costly object detection steps. We call this method Needle-Haystack (NH) scoring, and it is optimized for fast matrix operations on CPUs. We show that this method not only performs comparably to state-of-the-art methods in classic CBIR problems, but also outperforms them in fine-grained object- and instance-level retrieval on the Oxford 5K, Paris 6K, Google-Landmarks, and NIST MFC2018 datasets, as well as meme-style imagery from Reddit.
Measuring Human Perception to Improve Handwritten Document Transcription
Apr 10, 2019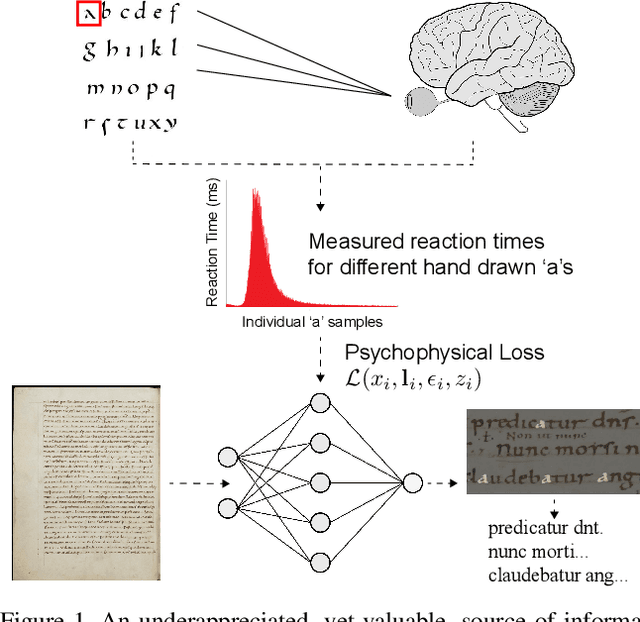

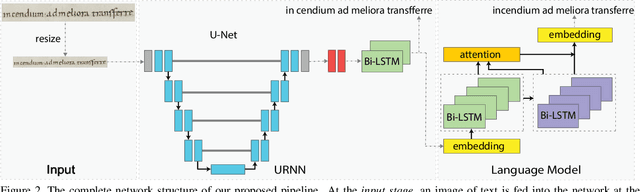

The subtleties of human perception, as measured by vision scientists through the use of psychophysics, are important clues to the internal workings of visual recognition. For instance, measured reaction time can indicate whether a visual stimulus is easy for a subject to recognize, or whether it is hard. In this paper, we consider how to incorporate psychophysical measurements of visual perception into the loss function of a deep neural network being trained for a recognition task, under the assumption that such information can enforce consistency with human behavior. As a case study to assess the viability of this approach, we look at the problem of handwritten document transcription. While good progress has been made towards automatically transcribing modern handwriting, significant challenges remain in transcribing historical documents. Here we work towards a comprehensive transcription solution for Medieval manuscripts that combines networks trained using our novel loss formulation with natural language processing elements. In a baseline assessment, reliable performance is demonstrated for the standard IAM and RIMES datasets. Further, we go on to show feasibility for our approach on a previously published dataset and a new dataset of digitized Latin manuscripts, originally produced by scribes in the Cloister of St. Gall around the middle of the 9th century.
Learning-Free Iris Segmentation Revisited: A First Step Toward Fast Volumetric Operation Over Video Samples
Jan 06, 2019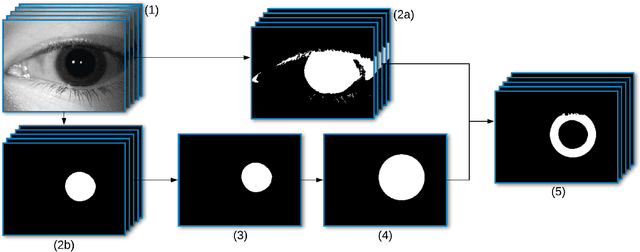
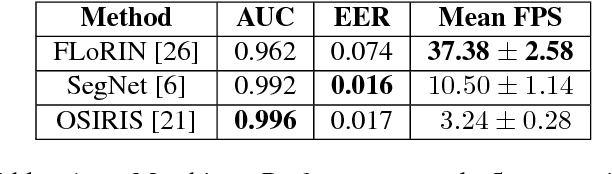
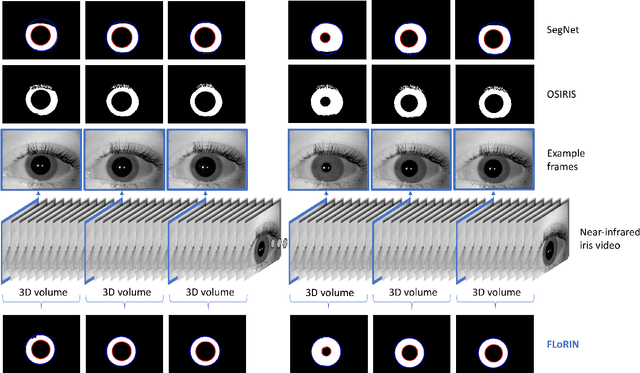
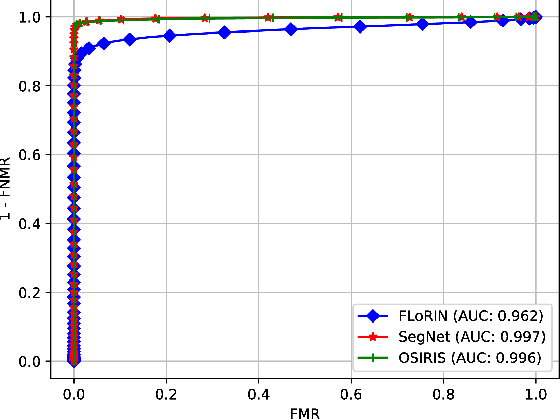
Subject matching performance in iris biometrics is contingent upon fast, high-quality iris segmentation. In many cases, iris biometrics acquisition equipment takes a number of images in sequence and combines the segmentation and matching results for each image to strengthen the result. To date, segmentation has occurred in 2D, operating on each image individually. But such methodologies, while powerful, do not take advantage of potential gains in performance afforded by treating sequential images as volumetric data. As a first step in this direction, we apply the Flexible Learning-Free Reconstructoin of Neural Volumes (FLoRIN) framework, an open source segmentation and reconstruction framework originally designed for neural microscopy volumes, to volumetric segmentation of iris videos. Further, we introduce a novel dataset of near-infrared iris videos, in which each subject's pupil rapidly changes size due to visible-light stimuli, as a test bed for FLoRIN. We compare the matching performance for iris masks generated by FLoRIN, deep-learning-based (SegNet), and Daugman's (OSIRIS) iris segmentation approaches. We show that by incorporating volumetric information, FLoRIN achieves a factor of 3.6 to an order of magnitude increase in throughput with only a minor drop in subject matching performance. We also demonstrate that FLoRIN-based iris segmentation maintains this speedup on low-resource hardware, making it suitable for embedded biometrics systems.
Face Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018
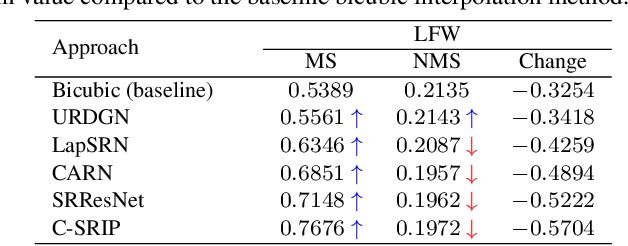
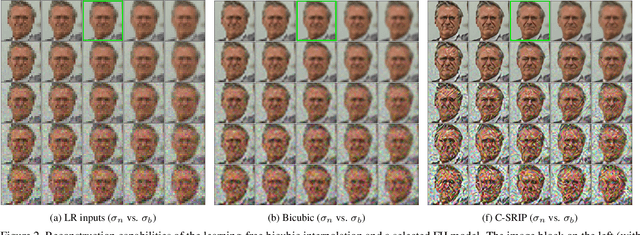
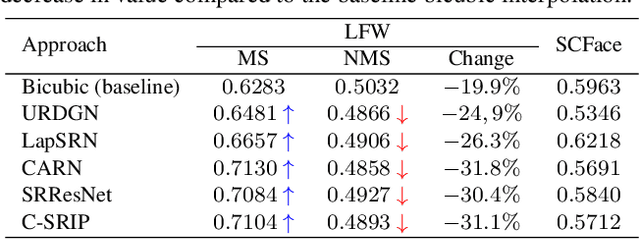
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.