 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREN: Anatomically-Informed Mixture-of-Experts for Interstitial Lung Disease Diagnosis
Oct 06, 2025Mixture-of-Experts (MoE) architectures have significantly contributed to scalable machine learning by enabling specialized subnetworks to tackle complex tasks efficiently. However, traditional MoE systems lack domain-specific constraints essential for medical imaging, where anatomical structure and regional disease heterogeneity strongly influence pathological patterns. Here, we introduce Regional Expert Networks (REN), the first anatomically-informed MoE framework tailored specifically for medical image classification. REN leverages anatomical priors to train seven specialized experts, each dedicated to distinct lung lobes and bilateral lung combinations, enabling precise modeling of region-specific pathological variations. Multi-modal gating mechanisms dynamically integrate radiomics biomarkers and deep learning (DL) features (CNN, ViT, Mamba) to weight expert contributions optimally. Applied to interstitial lung disease (ILD) classification, REN achieves consistently superior performance: the radiomics-guided ensemble reached an average AUC of 0.8646 +/- 0.0467, a +12.5 percent improvement over the SwinUNETR baseline (AUC 0.7685, p = 0.031). Region-specific experts further revealed that lower-lobe models achieved AUCs of 0.88-0.90, surpassing DL counterparts (CNN: 0.76-0.79) and aligning with known disease progression patterns. Through rigorous patient-level cross-validation, REN demonstrates strong generalizability and clinical interpretability, presenting a scalable, anatomically-guided approach readily extensible to other structured medical imaging applications.
Towards Space Group Determination from EBSD Patterns: The Role of Deep Learning and High-throughput Dynamical Simulations
Apr 30, 2025



The design of novel materials hinges on the understanding of structure-property relationships. However, our capability to synthesize a large number of materials has outpaced the ability and speed needed to characterize them. While the overall chemical constituents can be readily known during synthesis, the structural evolution and characterization of newly synthesized samples remains a bottleneck for the ultimate goal of high throughput nanomaterials discovery. Thus, scalable methods for crystal symmetry determination that can analyze a large volume of material samples within a short time-frame are especially needed. Kikuchi diffraction in the SEM is a promising technique for this due to its sensitivity to dynamical scattering, which may provide information beyond just the seven crystal systems and fourteen Bravais lattices. After diffraction patterns are collected from material samples, deep learning methods may be able to classify the space group symmetries using the patterns as input, which paired with the elemental composition, would help enable the determination of the crystal structure. To investigate the feasibility of this solution, neural networks were trained to predict the space group type of background corrected EBSD patterns. Our networks were first trained and tested on an artificial dataset of EBSD patterns of 5,148 different cubic phases, created through physics-based dynamical simulations. Next, Maximum Classifier Discrepancy, an unsupervised deep learning-based domain adaptation method, was utilized to train neural networks to make predictions for experimental EBSD patterns. We introduce a relabeling scheme, which enables our models to achieve accuracy scores higher than 90% on simulated and experimental data, suggesting that neural networks are capable of making predictions of crystal symmetry from an EBSD pattern.
Leveraging Augmented Reality for Improved Situational Awareness During UAV-Driven Search and Rescue Missions
Oct 16, 2024



In the high-stakes domain of search-and-rescue missions, the deployment of Unmanned Aerial Vehicles (UAVs) has become increasingly pivotal. These missions require seamless, real-time communication among diverse roles within response teams, particularly between Remote Operators (ROs) and On-Site Operators (OSOs). Traditionally, ROs and OSOs have relied on radio communication to exchange critical information, such as the geolocation of victims, hazardous areas, and points of interest. However, radio communication lacks information visualization, suffers from noise, and requires mental effort to interpret information, leading to miscommunications and misunderstandings. To address these challenges, this paper presents VizCom-AR, an Augmented Reality system designed to facilitate visual communication between ROs and OSOs and their situational awareness during UAV-driven search-and-rescue missions. Our experiments, focus group sessions with police officers, and field study showed that VizCom-AR enhances spatial awareness of both ROs and OSOs, facilitate geolocation information exchange, and effectively complement existing communication tools in UAV-driven emergency response missions. Overall, VizCom-AR offers a fundamental framework for designing Augmented Reality systems for large scale UAV-driven rescue missions.
* 8 pages
DroneWiS: Automated Simulation Testing of small Unmanned Aerial Systems in Realistic Windy Conditions
Aug 29, 2024The continuous evolution of small Unmanned Aerial Systems (sUAS) demands advanced testing methodologies to ensure their safe and reliable operations in the real-world. To push the boundaries of sUAS simulation testing in realistic environments, we previously developed the DroneReqValidator (DRV) platform, allowing developers to automatically conduct simulation testing in digital twin of earth. In this paper, we present DRV 2.0, which introduces a novel component called DroneWiS (Drone Wind Simulation). DroneWiS allows sUAS developers to automatically simulate realistic windy conditions and test the resilience of sUAS against wind. Unlike current state-of-the-art simulation tools such as Gazebo and AirSim that only simulate basic wind conditions, DroneWiS leverages Computational Fluid Dynamics (CFD) to compute the unique wind flows caused by the interaction of wind with the objects in the environment such as buildings and uneven terrains. This simulation capability provides deeper insights to developers about the navigation capability of sUAS in challenging and realistic windy conditions. DroneWiS equips sUAS developers with a powerful tool to test, debug, and improve the reliability and safety of sUAS in real-world. A working demonstration is available at https://youtu.be/khBHEBST8Wc
An Incremental Phase Mapping Approach for X-ray Diffraction Patterns using Binary Peak Representations
Nov 08, 2022



Despite the huge advancement in knowledge discovery and data mining techniques, the X-ray diffraction (XRD) analysis process has mostly remained untouched and still involves manual investigation, comparison, and verification. Due to the large volume of XRD samples from high-throughput XRD experiments, it has become impossible for domain scientists to process them manually. Recently, they have started leveraging standard clustering techniques, to reduce the XRD pattern representations requiring manual efforts for labeling and verification. Nevertheless, these standard clustering techniques do not handle problem-specific aspects such as peak shifting, adjacent peaks, background noise, and mixed phases; hence, resulting in incorrect composition-phase diagrams that complicate further steps. Here, we leverage data mining techniques along with domain expertise to handle these issues. In this paper, we introduce an incremental phase mapping approach based on binary peak representations using a new threshold based fuzzy dissimilarity measure. The proposed approach first applies an incremental phase computation algorithm on discrete binary peak representation of XRD samples, followed by hierarchical clustering or manual merging of similar pure phases to obtain the final composition-phase diagram. We evaluate our method on the composition space of two ternary alloy systems- Co-Ni-Ta and Co-Ti-Ta. Our results are verified by domain scientists and closely resembles the manually computed ground-truth composition-phase diagrams. The proposed approach takes us closer towards achieving the goal of complete end-to-end automated XRD analysis.
Extending MAPE-K to support Human-Machine Teaming
Mar 24, 2022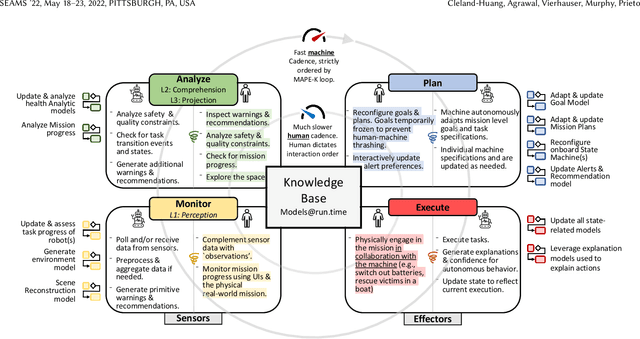
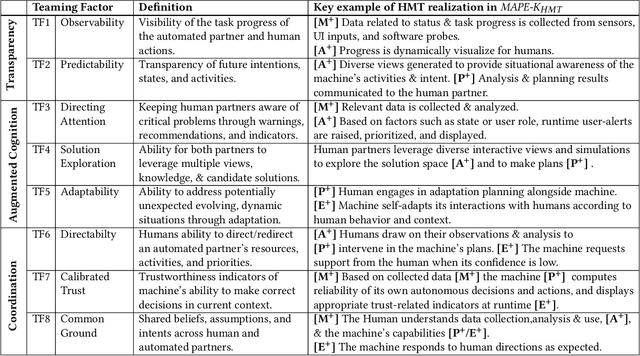
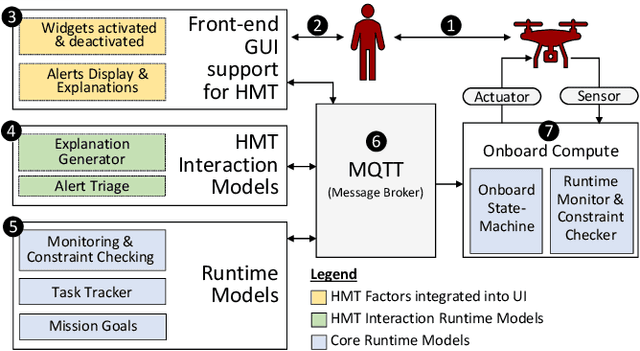

The MAPE-K feedback loop has been established as the primary reference model for self-adaptive and autonomous systems in domains such as autonomous driving, robotics, and Cyber-Physical Systems. At the same time, the Human Machine Teaming (HMT) paradigm is designed to promote partnerships between humans and autonomous machines. It goes far beyond the degree of collaboration expected in human-on-the-loop and human-in-the-loop systems and emphasizes interactions, partnership, and teamwork between humans and machines. However, while MAPE-K enables fully autonomous behavior, it does not explicitly address the interactions between humans and machines as intended by HMT. In this paper, we present the MAPE-K-HMT framework which augments the traditional MAPE-K loop with support for HMT. We identify critical human-machine teaming factors and describe the infrastructure needed across the various phases of the MAPE-K loop in order to effectively support HMT. This includes runtime models that are constructed and populated dynamically across monitoring, analysis, planning, and execution phases to support human-machine partnerships. We illustrate MAPE-K-HMT using examples from an autonomous multi-UAV emergency response system, and present guidelines for integrating HMT into MAPE-K.
Explaining Autonomous Decisions in Swarms of Human-on-the-Loop Small Unmanned Aerial Systems
Sep 05, 2021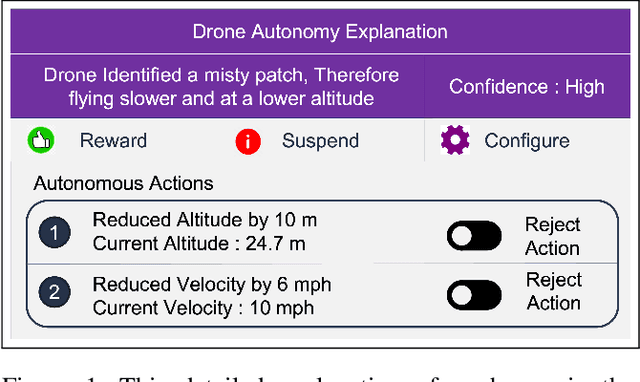

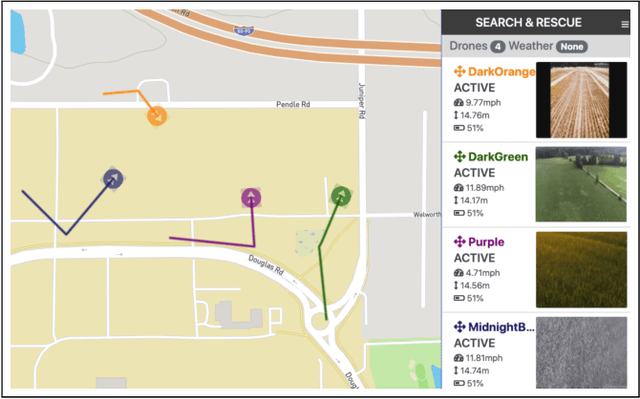
Rapid advancements in Artificial Intelligence have shifted the focus from traditional human-directed robots to fully autonomous ones that do not require explicit human control. These are commonly referred to as Human-on-the-Loop (HotL) systems. Transparency of HotL systems necessitates clear explanations of autonomous behavior so that humans are aware of what is happening in the environment and can understand why robots behave in a certain way. However, in complex multi-robot environments, especially those in which the robots are autonomous, mobile, and require intermittent interventions, humans may struggle to maintain situational awareness. Presenting humans with rich explanations of autonomous behavior tends to overload them with too much information and negatively affect their understanding of the situation. Therefore, explaining the autonomous behavior or autonomy of multiple robots creates a design tension that demands careful investigation. This paper examines the User Interface (UI) design trade-offs associated with providing timely and detailed explanations of autonomous behavior for swarms of small Unmanned Aerial Systems (sUAS) or drones. We analyze the impact of UI design choices on human awareness of the situation. We conducted multiple user studies with both inexperienced and expert sUAS operators to present our design solution and provide initial guidelines for designing the HotL multi-sUAS interface.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021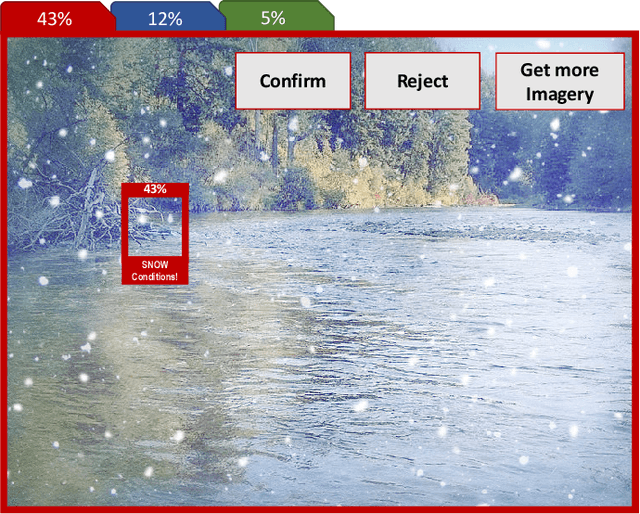
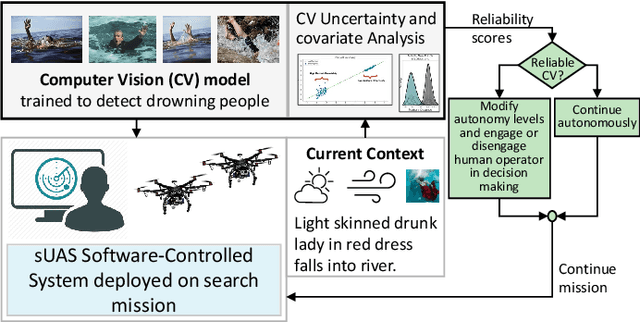

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
A General Framework Combining Generative Adversarial Networks and Mixture Density Networks for Inverse Modeling in Microstructural Materials Design
Jan 26, 2021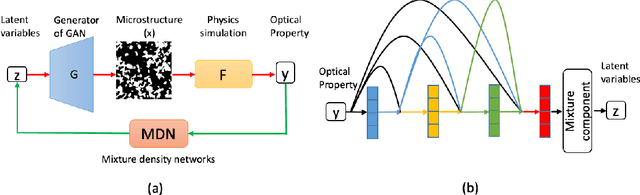
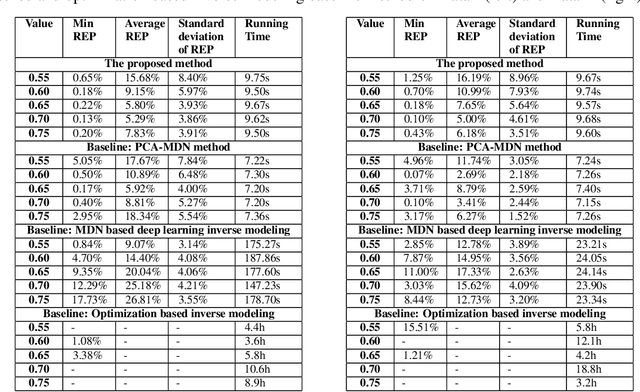

Microstructural materials design is one of the most important applications of inverse modeling in materials science. Generally speaking, there are two broad modeling paradigms in scientific applications: forward and inverse. While the forward modeling estimates the observations based on known parameters, the inverse modeling attempts to infer the parameters given the observations. Inverse problems are usually more critical as well as difficult in scientific applications as they seek to explore the parameters that cannot be directly observed. Inverse problems are used extensively in various scientific fields, such as geophysics, healthcare and materials science. However, it is challenging to solve inverse problems, because they usually need to learn a one-to-many non-linear mapping, and also require significant computing time, especially for high-dimensional parameter space. Further, inverse problems become even more difficult to solve when the dimension of input (i.e. observation) is much lower than that of output (i.e. parameters). In this work, we propose a framework consisting of generative adversarial networks and mixture density networks for inverse modeling, and it is evaluated on a materials science dataset for microstructural materials design. Compared with baseline methods, the results demonstrate that the proposed framework can overcome the above-mentioned challenges and produce multiple promising solutions in an efficient manner.
Art Style Classification with Self-Trained Ensemble of AutoEncoding Transformations
Dec 06, 2020
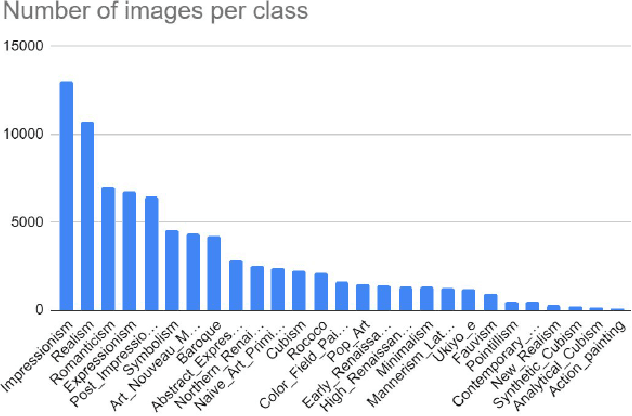

The artistic style of a painting is a rich descriptor that reveals both visual and deep intrinsic knowledge about how an artist uniquely portrays and expresses their creative vision. Accurate categorization of paintings across different artistic movements and styles is critical for large-scale indexing of art databases. However, the automatic extraction and recognition of these highly dense artistic features has received little to no attention in the field of computer vision research. In this paper, we investigate the use of deep self-supervised learning methods to solve the problem of recognizing complex artistic styles with high intra-class and low inter-class variation. Further, we outperform existing approaches by almost 20% on a highly class imbalanced WikiArt dataset with 27 art categories. To achieve this, we train the EnAET semi-supervised learning model (Wang et al., 2019) with limited annotated data samples and supplement it with self-supervised representations learned from an ensemble of spatial and non-spatial transformations.