 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESAM: Requirements Elicitation and Specification for Deep-Learning Anomaly Models with Applications to UAV Flight Controllers
Jul 18, 2022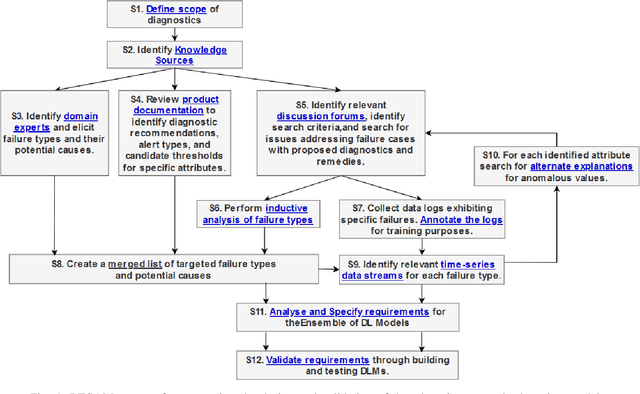
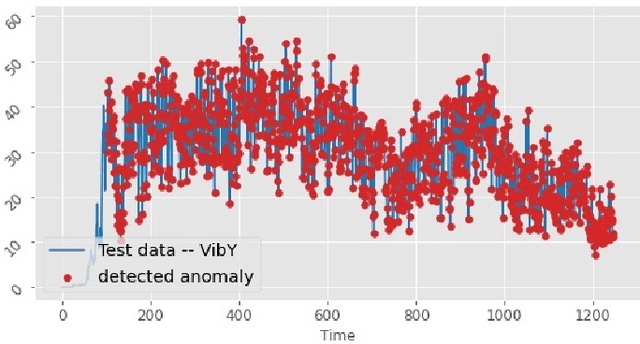
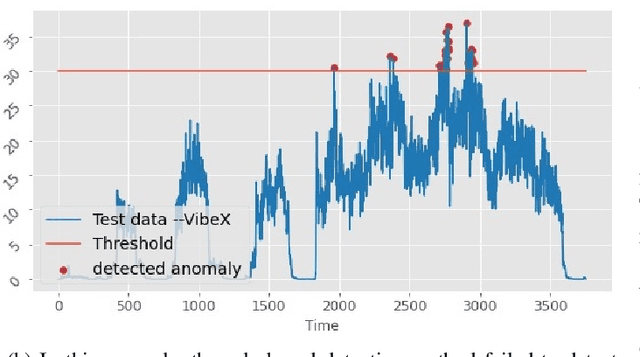
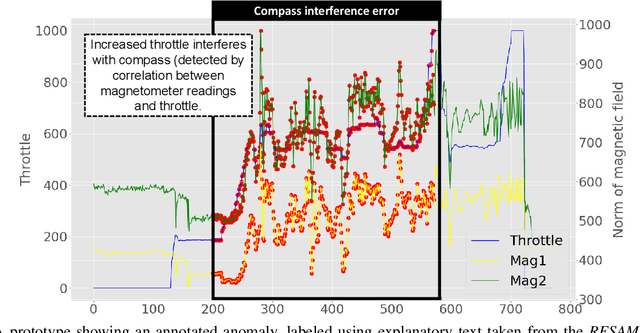
CyberPhysical systems (CPS) must be closely monitored to identify and potentially mitigate emergent problems that arise during their routine operations. However, the multivariate time-series data which they typically produce can be complex to understand and analyze. While formal product documentation often provides example data plots with diagnostic suggestions, the sheer diversity of attributes, critical thresholds, and data interactions can be overwhelming to non-experts who subsequently seek help from discussion forums to interpret their data logs. Deep learning models, such as Long Short-term memory (LSTM) networks can be used to automate these tasks and to provide clear explanations of diverse anomalies detected in real-time multivariate data-streams. In this paper we present RESAM, a requirements process that integrates knowledge from domain experts, discussion forums, and formal product documentation, to discover and specify requirements and design definitions in the form of time-series attributes that contribute to the construction of effective deep learning anomaly detectors. We present a case-study based on a flight control system for small Uncrewed Aerial Systems and demonstrate that its use guides the construction of effective anomaly detection models whilst also providing underlying support for explainability. RESAM is relevant to domains in which open or closed online forums provide discussion support for log analysis.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021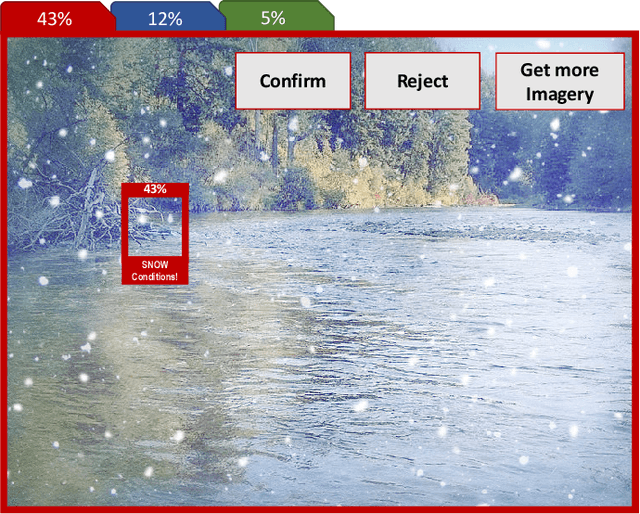
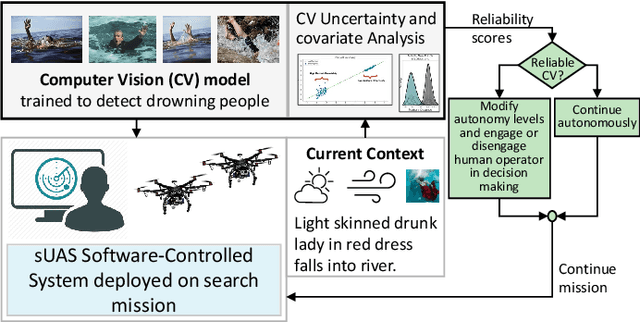
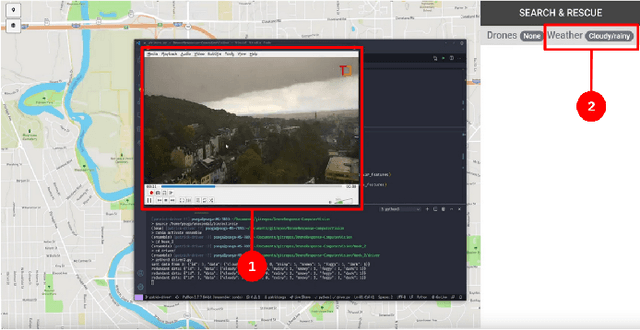

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
A CNN-based approach to classify cricket bowlers based on their bowling actions
Sep 03, 2019
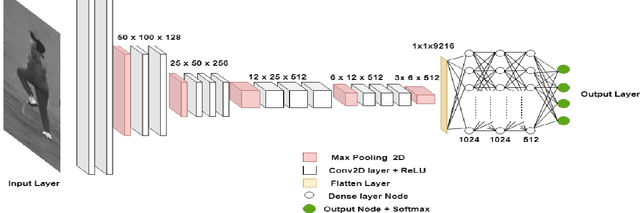


With the advances in hardware technologies and deep learning techniques, it has become feasible to apply these techniques in diverse fields. Convolutional Neural Network (CNN), an architecture from the field of deep learning, has revolutionized Computer Vision. Sports is one of the avenues in which the use of computer vision is thriving. Cricket is a complex game consisting of different types of shots, bowling actions and many other activities. Every bowler, in a game of cricket, bowls with a different bowling action. We leverage this point to identify different bowlers. In this paper, we have proposed a CNN model to identify eighteen different cricket bowlers based on their bowling actions using transfer learning. Additionally, we have created a completely new dataset containing 8100 images of these eighteen bowlers to train the proposed framework and evaluate its performance. We have used the VGG16 model pre-trained with the ImageNet dataset and added a few layers on top of it to build our model. After trying out different strategies, we found that freezing the weights for the first 14 layers of the network and training the rest of the layers works best. Our approach achieves an overall average accuracy of 93.3% on the test set and converges to a very low cross-entropy loss.
HishabNet: Detection, Localization and Calculation of Handwritten Bengali Mathematical Expressions
Sep 02, 2019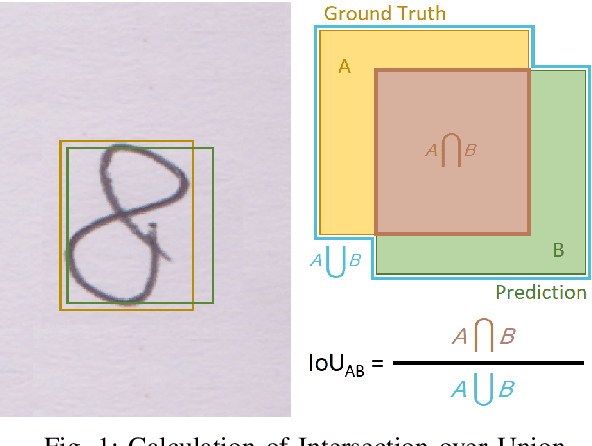
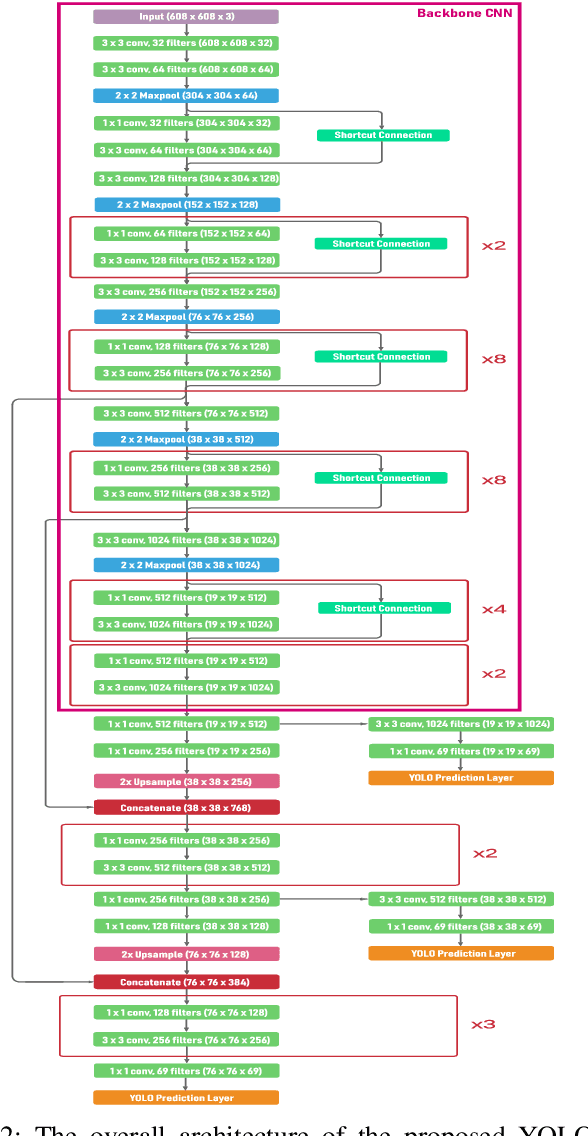

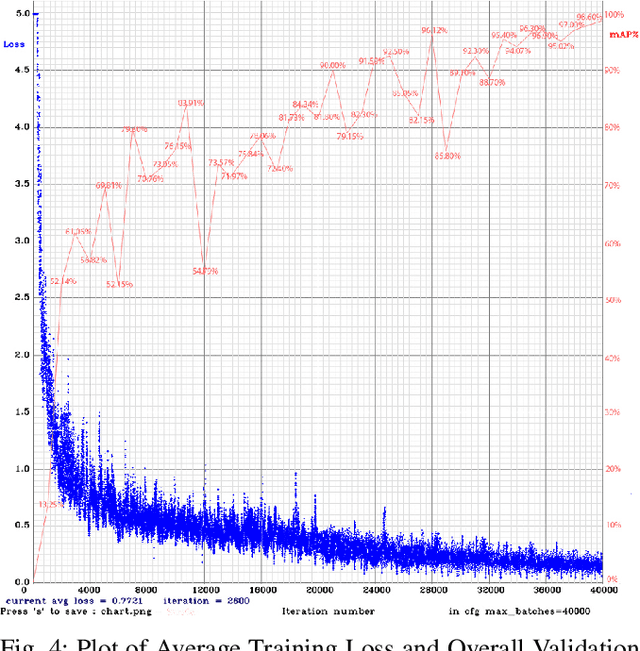
Recently, recognition of handwritten Bengali letters and digits have captured a lot of attention among the researchers of the AI community. In this work, we propose a Convolutional Neural Network (CNN) based object detection model which can recognize and evaluate handwritten Bengali mathematical expressions. This method is able to detect multiple Bengali digits and operators and locate their positions in the image. With that information, it is able to construct numbers from series of digits and perform mathematical operations on them. For the object detection task, the state-of-the-art YOLOv3 algorithm was utilized. For training and evaluating the model, we have engineered a new dataset 'Hishab' which is the first Bengali handwritten digits dataset intended for object detection. The model achieved an overall validation mean average precision (mAP) of 98.6%. Also, the classification accuracy of the feature extractor backbone CNN used in our model was tested on two publicly available Bengali handwritten digits datasets: NumtaDB and CMATERdb. The backbone CNN achieved a test set accuracy of 99.6252% on NumtaDB and 99.0833% on CMATERdb.