 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Probably Looks Exactly Like That: An Invertible Prototypical Network
Jul 16, 2024



We combine concept-based neural networks with generative, flow-based classifiers into a novel, intrinsically explainable, exactly invertible approach to supervised learning. Prototypical neural networks, a type of concept-based neural network, represent an exciting way forward in realizing human-comprehensible machine learning without concept annotations, but a human-machine semantic gap continues to haunt current approaches. We find that reliance on indirect interpretation functions for prototypical explanations imposes a severe limit on prototypes' informative power. From this, we posit that invertibly learning prototypes as distributions over the latent space provides more robust, expressive, and interpretable modeling. We propose one such model, called ProtoFlow, by composing a normalizing flow with Gaussian mixture models. ProtoFlow (1) sets a new state-of-the-art in joint generative and predictive modeling and (2) achieves predictive performance comparable to existing prototypical neural networks while enabling richer interpretation.
Benchmark Generation Framework with Customizable Distortions for Image Classifier Robustness
Nov 08, 2023



We present a novel framework for generating adversarial benchmarks to evaluate the robustness of image classification models. Our framework allows users to customize the types of distortions to be optimally applied to images, which helps address the specific distortions relevant to their deployment. The benchmark can generate datasets at various distortion levels to assess the robustness of different image classifiers. Our results show that the adversarial samples generated by our framework with any of the image classification models, like ResNet-50, Inception-V3, and VGG-16, are effective and transferable to other models causing them to fail. These failures happen even when these models are adversarially retrained using state-of-the-art techniques, demonstrating the generalizability of our adversarial samples. We achieve competitive performance in terms of net $L_2$ distortion compared to state-of-the-art benchmark techniques on CIFAR-10 and ImageNet; however, we demonstrate our framework achieves such results with simple distortions like Gaussian noise without introducing unnatural artifacts or color bleeds. This is made possible by a model-based reinforcement learning (RL) agent and a technique that reduces a deep tree search of the image for model sensitivity to perturbations, to a one-level analysis and action. The flexibility of choosing distortions and setting classification probability thresholds for multiple classes makes our framework suitable for algorithmic audits.
How Well Do Feature-Additive Explainers Explain Feature-Additive Predictors?
Oct 27, 2023



Surging interest in deep learning from high-stakes domains has precipitated concern over the inscrutable nature of black box neural networks. Explainable AI (XAI) research has led to an abundance of explanation algorithms for these black boxes. Such post hoc explainers produce human-comprehensible explanations, however, their fidelity with respect to the model is not well understood - explanation evaluation remains one of the most challenging issues in XAI. In this paper, we ask a targeted but important question: can popular feature-additive explainers (e.g., LIME, SHAP, SHAPR, MAPLE, and PDP) explain feature-additive predictors? Herein, we evaluate such explainers on ground truth that is analytically derived from the additive structure of a model. We demonstrate the efficacy of our approach in understanding these explainers applied to symbolic expressions, neural networks, and generalized additive models on thousands of synthetic and several real-world tasks. Our results suggest that all explainers eventually fail to correctly attribute the importance of features, especially when a decision-making process involves feature interactions.
Pixel-Grounded Prototypical Part Networks
Sep 25, 2023



Prototypical part neural networks (ProtoPartNNs), namely PROTOPNET and its derivatives, are an intrinsically interpretable approach to machine learning. Their prototype learning scheme enables intuitive explanations of the form, this (prototype) looks like that (testing image patch). But, does this actually look like that? In this work, we delve into why object part localization and associated heat maps in past work are misleading. Rather than localizing to object parts, existing ProtoPartNNs localize to the entire image, contrary to generated explanatory visualizations. We argue that detraction from these underlying issues is due to the alluring nature of visualizations and an over-reliance on intuition. To alleviate these issues, we devise new receptive field-based architectural constraints for meaningful localization and a principled pixel space mapping for ProtoPartNNs. To improve interpretability, we propose additional architectural improvements, including a simplified classification head. We also make additional corrections to PROTOPNET and its derivatives, such as the use of a validation set, rather than a test set, to evaluate generalization during training. Our approach, PIXPNET (Pixel-grounded Prototypical part Network), is the only ProtoPartNN that truly learns and localizes to prototypical object parts. We demonstrate that PIXPNET achieves quantifiably improved interpretability without sacrificing accuracy.
HomOpt: A Homotopy-Based Hyperparameter Optimization Method
Aug 07, 2023



Machine learning has achieved remarkable success over the past couple of decades, often attributed to a combination of algorithmic innovations and the availability of high-quality data available at scale. However, a third critical component is the fine-tuning of hyperparameters, which plays a pivotal role in achieving optimal model performance. Despite its significance, hyperparameter optimization (HPO) remains a challenging task for several reasons. Many HPO techniques rely on naive search methods or assume that the loss function is smooth and continuous, which may not always be the case. Traditional methods, like grid search and Bayesian optimization, often struggle to quickly adapt and efficiently search the loss landscape. Grid search is computationally expensive, while Bayesian optimization can be slow to prime. Since the search space for HPO is frequently high-dimensional and non-convex, it is often challenging to efficiently find a global minimum. Moreover, optimal hyperparameters can be sensitive to the specific dataset or task, further complicating the search process. To address these issues, we propose a new hyperparameter optimization method, HomOpt, using a data-driven approach based on a generalized additive model (GAM) surrogate combined with homotopy optimization. This strategy augments established optimization methodologies to boost the performance and effectiveness of any given method with faster convergence to the optimum on continuous, discrete, and categorical domain spaces. We compare the effectiveness of HomOpt applied to multiple optimization techniques (e.g., Random Search, TPE, Bayes, and SMAC) showing improved objective performance on many standardized machine learning benchmarks and challenging open-set recognition tasks.
Unfooling Perturbation-Based Post Hoc Explainers
May 29, 2022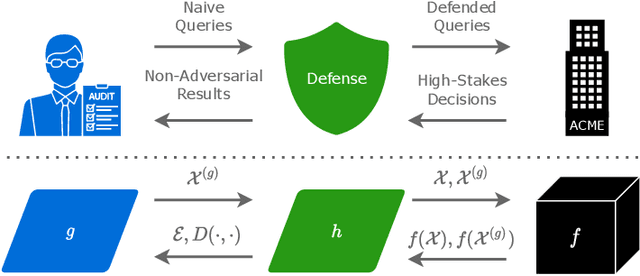

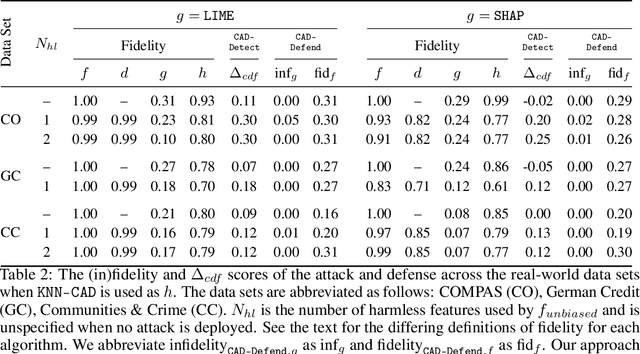
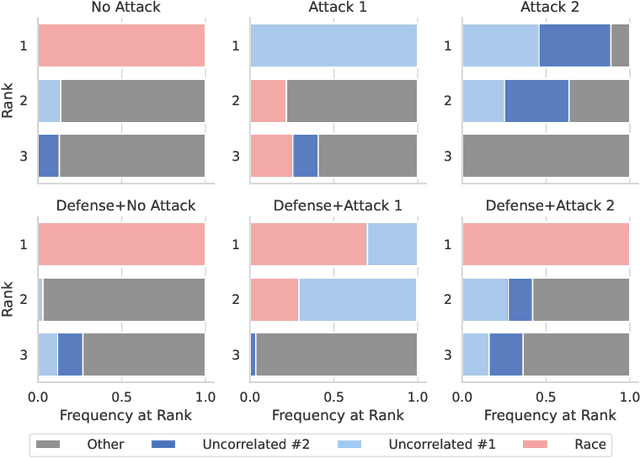
Monumental advancements in artificial intelligence (AI) have lured the interest of doctors, lenders, judges, and other professionals. While these high-stakes decision-makers are optimistic about the technology, those familiar with AI systems are wary about the lack of transparency of its decision-making processes. Perturbation-based post hoc explainers offer a model agnostic means of interpreting these systems while only requiring query-level access. However, recent work demonstrates that these explainers can be fooled adversarially. This discovery has adverse implications for auditors, regulators, and other sentinels. With this in mind, several natural questions arise - how can we audit these black box systems? And how can we ascertain that the auditee is complying with the audit in good faith? In this work, we rigorously formalize this problem and devise a defense against adversarial attacks on perturbation-based explainers. We propose algorithms for the detection (CAD-Detect) and defense (CAD-Defend) of these attacks, which are aided by our novel conditional anomaly detection approach, KNN-CAD. We demonstrate that our approach successfully detects whether a black box system adversarially conceals its decision-making process and mitigates the adversarial attack on real-world data for the prevalent explainers, LIME and SHAP.
Motif Mining: Finding and Summarizing Remixed Image Content
Mar 17, 2022
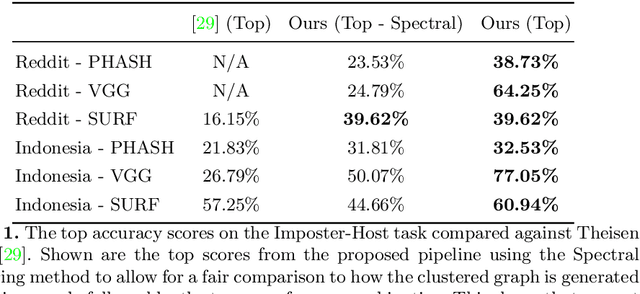
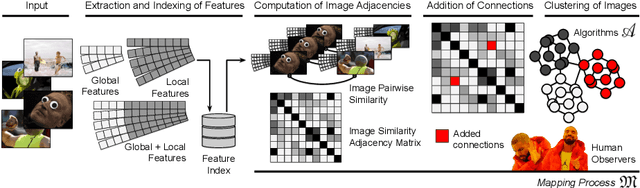
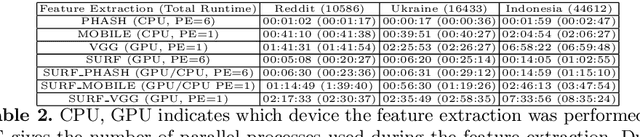
On the internet, images are no longer static; they have become dynamic content. Thanks to the availability of smartphones with cameras and easy-to-use editing software, images can be remixed (i.e., redacted, edited, and recombined with other content) on-the-fly and with a world-wide audience that can repeat the process. From digital art to memes, the evolution of images through time is now an important topic of study for digital humanists, social scientists, and media forensics specialists. However, because typical data sets in computer vision are composed of static content, the development of automated algorithms to analyze remixed content has been limited. In this paper, we introduce the idea of Motif Mining - the process of finding and summarizing remixed image content in large collections of unlabeled and unsorted data. In this paper, this idea is formalized and a reference implementation is introduced. Experiments are conducted on three meme-style data sets, including a newly collected set associated with the information war in the Russo-Ukrainian conflict. The proposed motif mining approach is able to identify related remixed content that, when compared to similar approaches, more closely aligns with the preferences and expectations of human observers.
Learning Interpretable Models Through Multi-Objective Neural Architecture Search
Dec 16, 2021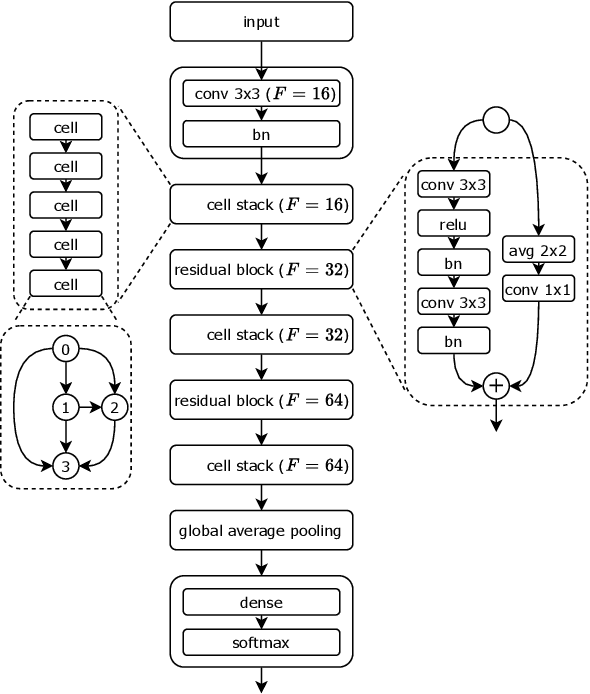
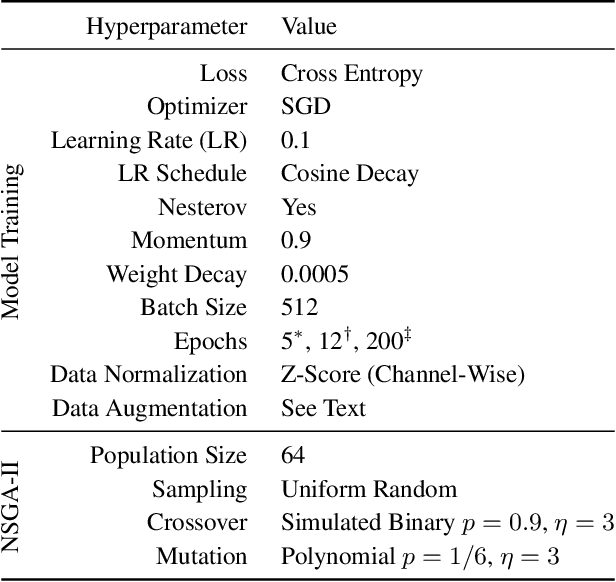
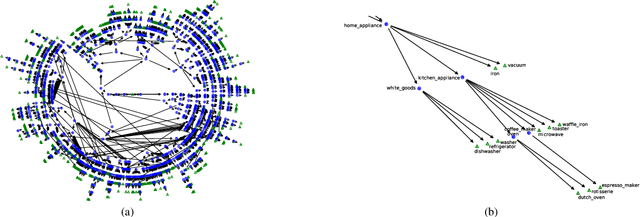
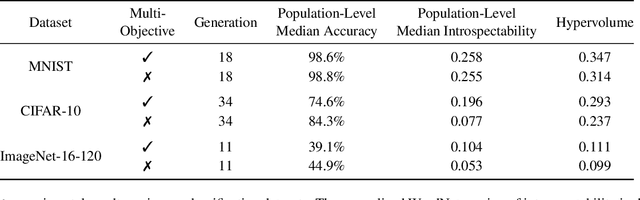
Monumental advances in deep learning have led to unprecedented achievements across a multitude of domains. While the performance of deep neural networks is indubitable, the architectural design and interpretability of such models are nontrivial. Research has been introduced to automate the design of neural network architectures through neural architecture search (NAS). Recent progress has made these methods more pragmatic by exploiting distributed computation and novel optimization algorithms. However, there is little work in optimizing architectures for interpretability. To this end, we propose a multi-objective distributed NAS framework that optimizes for both task performance and introspection. We leverage the non-dominated sorting genetic algorithm (NSGA-II) and explainable AI (XAI) techniques to reward architectures that can be better comprehended by humans. The framework is evaluated on several image classification datasets. We demonstrate that jointly optimizing for introspection ability and task error leads to more disentangled architectures that perform within tolerable error.
On the Objective Evaluation of Post Hoc Explainers
Jun 15, 2021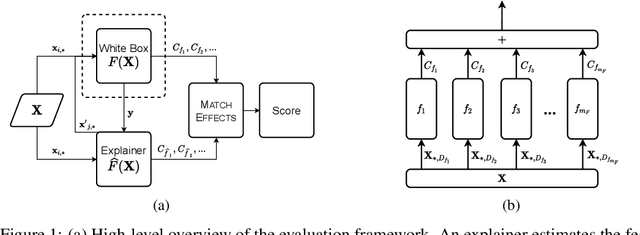
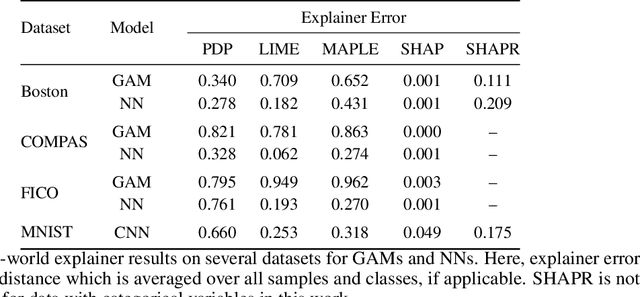
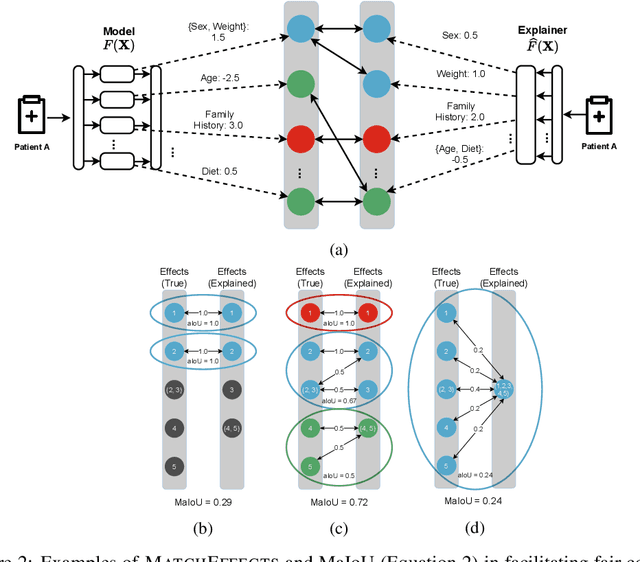
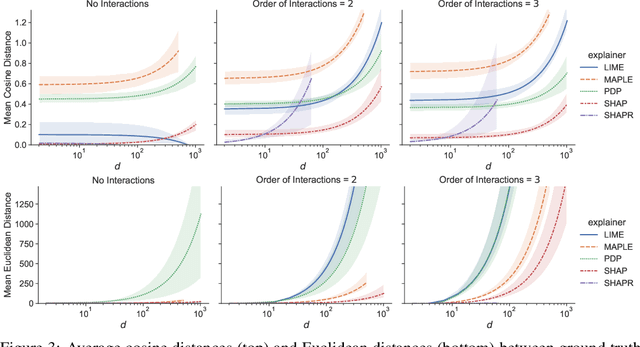
Many applications of data-driven models demand transparency of decisions, especially in health care, criminal justice, and other high-stakes environments. Modern trends in machine learning research have led to algorithms that are increasingly intricate to the degree that they are considered to be black boxes. In an effort to reduce the opacity of decisions, methods have been proposed to construe the inner workings of such models in a human-comprehensible manner. These post hoc techniques are described as being universal explainers - capable of faithfully augmenting decisions with algorithmic insight. Unfortunately, there is little agreement about what constitutes a "good" explanation. Moreover, current methods of explanation evaluation are derived from either subjective or proxy means. In this work, we propose a framework for the evaluation of post hoc explainers on ground truth that is directly derived from the additive structure of a model. We demonstrate the efficacy of the framework in understanding explainers by evaluating popular explainers on thousands of synthetic and several real-world tasks. The framework unveils that explanations may be accurate but misattribute the importance of individual features.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021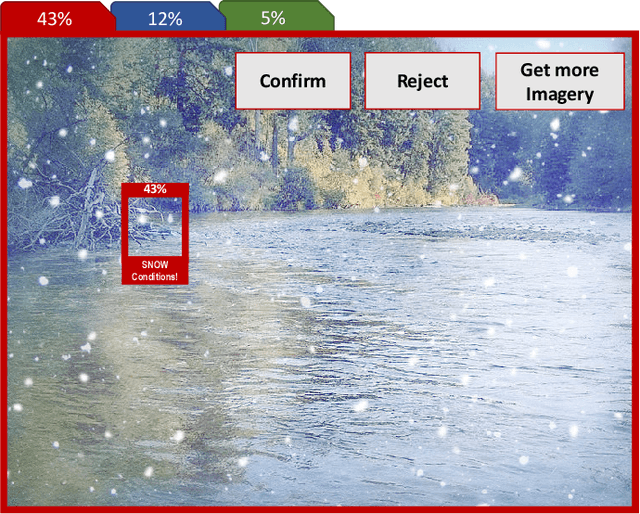
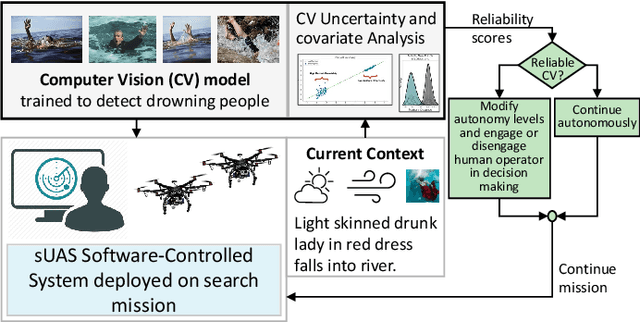

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.