 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognition Envelopes for Bounded AI Reasoning in Autonomous UAS Operations
Oct 30, 2025Cyber-physical systems increasingly rely on Foundational Models such as Large Language Models (LLMs) and Vision-Language Models (VLMs) to increase autonomy through enhanced perception, inference, and planning. However, these models also introduce new types of errors, such as hallucinations, overgeneralizations, and context misalignments, resulting in incorrect and flawed decisions. To address this, we introduce the concept of Cognition Envelopes, designed to establish reasoning boundaries that constrain AI-generated decisions while complementing the use of meta-cognition and traditional safety envelopes. As with safety envelopes, Cognition Envelopes require practical guidelines and systematic processes for their definition, validation, and assurance.
Cognitive Guardrails for Open-World Decision Making in Autonomous Drone Swarms
May 29, 2025
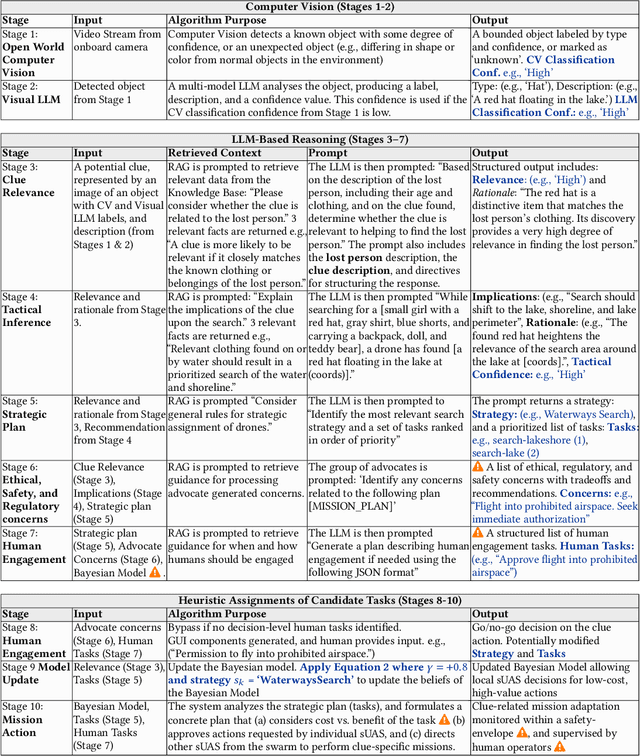

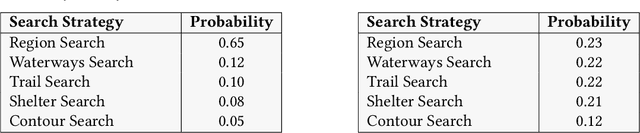
Small Uncrewed Aerial Systems (sUAS) are increasingly deployed as autonomous swarms in search-and-rescue and other disaster-response scenarios. In these settings, they use computer vision (CV) to detect objects of interest and autonomously adapt their missions. However, traditional CV systems often struggle to recognize unfamiliar objects in open-world environments or to infer their relevance for mission planning. To address this, we incorporate large language models (LLMs) to reason about detected objects and their implications. While LLMs can offer valuable insights, they are also prone to hallucinations and may produce incorrect, misleading, or unsafe recommendations. To ensure safe and sensible decision-making under uncertainty, high-level decisions must be governed by cognitive guardrails. This article presents the design, simulation, and real-world integration of these guardrails for sUAS swarms in search-and-rescue missions.
Land-Coverage Aware Path-Planning for Multi-UAV Swarms in Search and Rescue Scenarios
May 12, 2025Unmanned Aerial Vehicles (UAVs) have become vital in search-and-rescue (SAR) missions, with autonomous mission planning improving response times and coverage efficiency. Early approaches primarily used path planning techniques such as A*, potential-fields, or Dijkstra's algorithm, while recent approaches have incorporated meta-heuristic frameworks like genetic algorithms and particle swarm optimization to balance competing objectives such as network connectivity, energy efficiency, and strategic placement of charging stations. However, terrain-aware path planning remains under-explored, despite its critical role in optimizing UAV SAR deployments. To address this gap, we present a computer-vision based terrain-aware mission planner that autonomously extracts and analyzes terrain topology to enhance SAR pre-flight planning. Our framework uses a deep segmentation network fine-tuned on our own collection of landcover datasets to transform satellite imagery into a structured, grid-based representation of the operational area. This classification enables terrain-specific UAV-task allocation, improving deployment strategies in complex environments. We address the challenge of irregular terrain partitions, by introducing a two-stage partitioning scheme that first evaluates terrain monotonicity along coordinate axes before applying a cost-based recursive partitioning process, minimizing unnecessary splits and optimizing path efficiency. Empirical validation in a high-fidelity simulation environment demonstrates that our approach improves search and dispatch time over multiple meta-heuristic techniques and against a competing state-of-the-art method. These results highlight its potential for large-scale SAR operations, where rapid response and efficient UAV coordination are critical.
Multi-source Plume Tracing via Multi-Agent Reinforcement Learning
May 12, 2025



Industrial catastrophes like the Bhopal disaster (1984) and the Aliso Canyon gas leak (2015) demonstrate the urgent need for rapid and reliable plume tracing algorithms to protect public health and the environment. Traditional methods, such as gradient-based or biologically inspired approaches, often fail in realistic, turbulent conditions. To address these challenges, we present a Multi-Agent Reinforcement Learning (MARL) algorithm designed for localizing multiple airborne pollution sources using a swarm of small uncrewed aerial systems (sUAS). Our method models the problem as a Partially Observable Markov Game (POMG), employing a Long Short-Term Memory (LSTM)-based Action-specific Double Deep Recurrent Q-Network (ADDRQN) that uses full sequences of historical action-observation pairs, effectively approximating latent states. Unlike prior work, we use a general-purpose simulation environment based on the Gaussian Plume Model (GPM), incorporating realistic elements such as a three-dimensional environment, sensor noise, multiple interacting agents, and multiple plume sources. The incorporation of action histories as part of the inputs further enhances the adaptability of our model in complex, partially observable environments. Extensive simulations show that our algorithm significantly outperforms conventional approaches. Specifically, our model allows agents to explore only 1.29\% of the environment to successfully locate pollution sources.
Evaluating Reinforcement Learning Safety and Trustworthiness in Cyber-Physical Systems
Mar 12, 2025
Cyber-Physical Systems (CPS) often leverage Reinforcement Learning (RL) techniques to adapt dynamically to changing environments and optimize performance. However, it is challenging to construct safety cases for RL components. We therefore propose the SAFE-RL (Safety and Accountability Framework for Evaluating Reinforcement Learning) for supporting the development, validation, and safe deployment of RL-based CPS. We adopt a design science approach to construct the framework and demonstrate its use in three RL applications in small Uncrewed Aerial systems (sUAS)
Psych-Occlusion: Using Visual Psychophysics for Aerial Detection of Occluded Persons during Search and Rescue
Dec 07, 2024



The success of Emergency Response (ER) scenarios, such as search and rescue, is often dependent upon the prompt location of a lost or injured person. With the increasing use of small Unmanned Aerial Systems (sUAS) as "eyes in the sky" during ER scenarios, efficient detection of persons from aerial views plays a crucial role in achieving a successful mission outcome. Fatigue of human operators during prolonged ER missions, coupled with limited human resources, highlights the need for sUAS equipped with Computer Vision (CV) capabilities to aid in finding the person from aerial views. However, the performance of CV models onboard sUAS substantially degrades under real-life rigorous conditions of a typical ER scenario, where person search is hampered by occlusion and low target resolution. To address these challenges, we extracted images from the NOMAD dataset and performed a crowdsource experiment to collect behavioural measurements when humans were asked to "find the person in the picture". We exemplify the use of our behavioral dataset, Psych-ER, by using its human accuracy data to adapt the loss function of a detection model. We tested our loss adaptation on a RetinaNet model evaluated on NOMAD against increasing distance and occlusion, with our psychophysical loss adaptation showing improvements over the baseline at higher distances across different levels of occlusion, without degrading performance at closer distances. To the best of our knowledge, our work is the first human-guided approach to address the location task of a detection model, while addressing real-world challenges of aerial search and rescue. All datasets and code can be found at: https://github.com/ArtRuss/NOMAD.
Towards Engineering Fair and Equitable Software Systems for Managing Low-Altitude Airspace Authorizations
Feb 03, 2024



Small Unmanned Aircraft Systems (sUAS) have gained widespread adoption across a diverse range of applications. This has introduced operational complexities within shared airspaces and an increase in reported incidents, raising safety concerns. In response, the U.S. Federal Aviation Administration (FAA) is developing a UAS Traffic Management (UTM) system to control access to airspace based on an sUAS's predicted ability to safely complete its mission. However, a fully automated system capable of swiftly approving or denying flight requests can be prone to bias and must consider safety, transparency, and fairness to diverse stakeholders. In this paper, we present an initial study that explores stakeholders' perspectives on factors that should be considered in an automated system. Results indicate flight characteristics and environmental conditions were perceived as most important but pilot and drone capabilities should also be considered. Further, several respondents indicated an aversion to any AI-supported automation, highlighting the need for full transparency in automated decision-making. Results provide a societal perspective on the challenges of automating UTM flight authorization decisions and help frame the ongoing design of a solution acceptable to the broader sUAS community.
NOMAD: A Natural, Occluded, Multi-scale Aerial Dataset, for Emergency Response Scenarios
Sep 18, 2023



With the increasing reliance on small Unmanned Aerial Systems (sUAS) for Emergency Response Scenarios, such as Search and Rescue, the integration of computer vision capabilities has become a key factor in mission success. Nevertheless, computer vision performance for detecting humans severely degrades when shifting from ground to aerial views. Several aerial datasets have been created to mitigate this problem, however, none of them has specifically addressed the issue of occlusion, a critical component in Emergency Response Scenarios. Natural Occluded Multi-scale Aerial Dataset (NOMAD) presents a benchmark for human detection under occluded aerial views, with five different aerial distances and rich imagery variance. NOMAD is composed of 100 different Actors, all performing sequences of walking, laying and hiding. It includes 42,825 frames, extracted from 5.4k resolution videos, and manually annotated with a bounding box and a label describing 10 different visibility levels, categorized according to the percentage of the human body visible inside the bounding box. This allows computer vision models to be evaluated on their detection performance across different ranges of occlusion. NOMAD is designed to improve the effectiveness of aerial search and rescue and to enhance collaboration between sUAS and humans, by providing a new benchmark dataset for human detection under occluded aerial views.
RESAM: Requirements Elicitation and Specification for Deep-Learning Anomaly Models with Applications to UAV Flight Controllers
Jul 18, 2022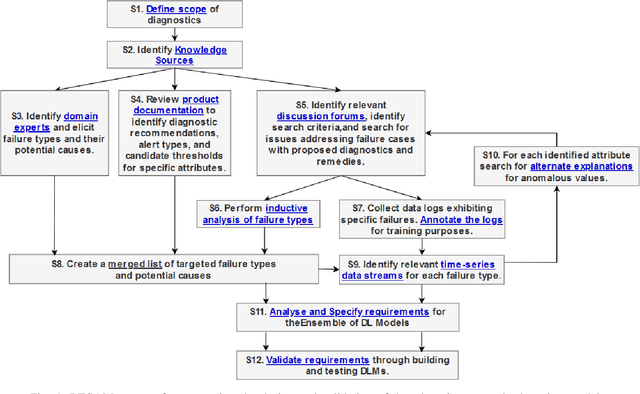
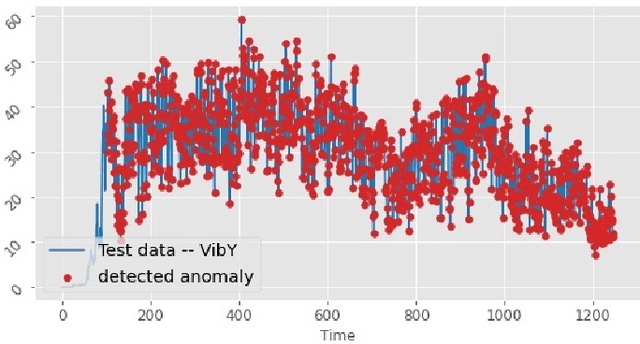
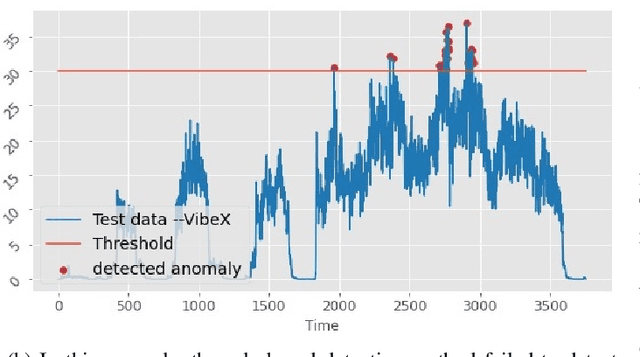
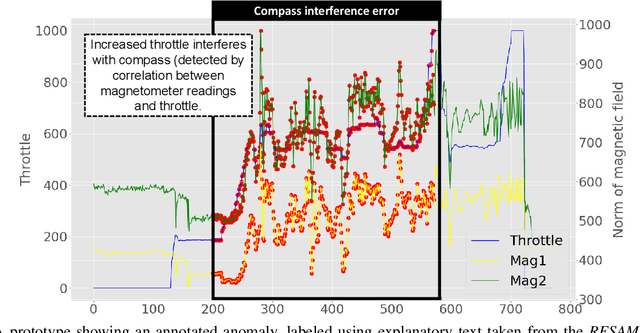
CyberPhysical systems (CPS) must be closely monitored to identify and potentially mitigate emergent problems that arise during their routine operations. However, the multivariate time-series data which they typically produce can be complex to understand and analyze. While formal product documentation often provides example data plots with diagnostic suggestions, the sheer diversity of attributes, critical thresholds, and data interactions can be overwhelming to non-experts who subsequently seek help from discussion forums to interpret their data logs. Deep learning models, such as Long Short-term memory (LSTM) networks can be used to automate these tasks and to provide clear explanations of diverse anomalies detected in real-time multivariate data-streams. In this paper we present RESAM, a requirements process that integrates knowledge from domain experts, discussion forums, and formal product documentation, to discover and specify requirements and design definitions in the form of time-series attributes that contribute to the construction of effective deep learning anomaly detectors. We present a case-study based on a flight control system for small Uncrewed Aerial Systems and demonstrate that its use guides the construction of effective anomaly detection models whilst also providing underlying support for explainability. RESAM is relevant to domains in which open or closed online forums provide discussion support for log analysis.
Extending MAPE-K to support Human-Machine Teaming
Mar 24, 2022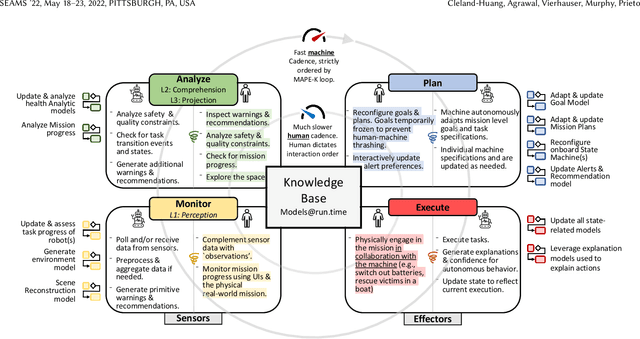
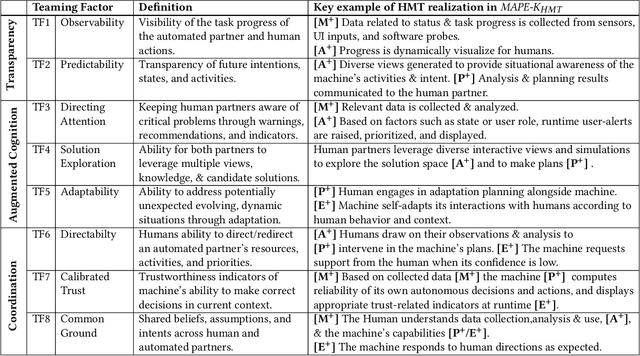
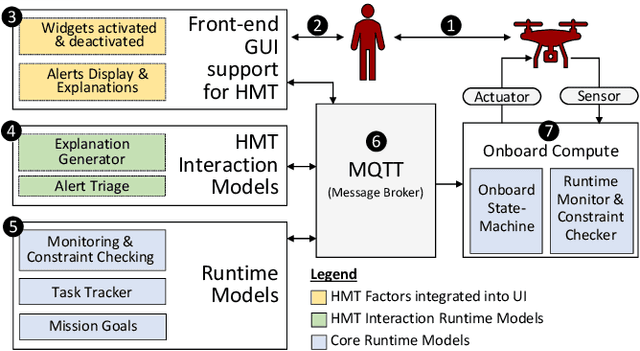

The MAPE-K feedback loop has been established as the primary reference model for self-adaptive and autonomous systems in domains such as autonomous driving, robotics, and Cyber-Physical Systems. At the same time, the Human Machine Teaming (HMT) paradigm is designed to promote partnerships between humans and autonomous machines. It goes far beyond the degree of collaboration expected in human-on-the-loop and human-in-the-loop systems and emphasizes interactions, partnership, and teamwork between humans and machines. However, while MAPE-K enables fully autonomous behavior, it does not explicitly address the interactions between humans and machines as intended by HMT. In this paper, we present the MAPE-K-HMT framework which augments the traditional MAPE-K loop with support for HMT. We identify critical human-machine teaming factors and describe the infrastructure needed across the various phases of the MAPE-K loop in order to effectively support HMT. This includes runtime models that are constructed and populated dynamically across monitoring, analysis, planning, and execution phases to support human-machine partnerships. We illustrate MAPE-K-HMT using examples from an autonomous multi-UAV emergency response system, and present guidelines for integrating HMT into MAPE-K.