 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFW, DamnGina, Juvie, and Hotsie-Totsie: On the Linguistic and Social Aspects of Internet Slang
Dec 22, 2017
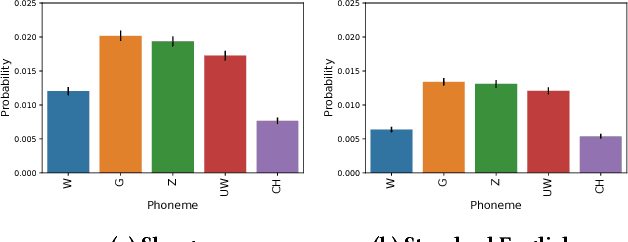
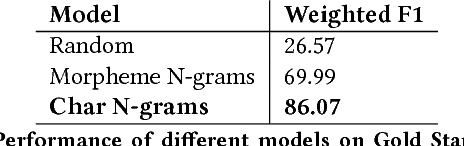
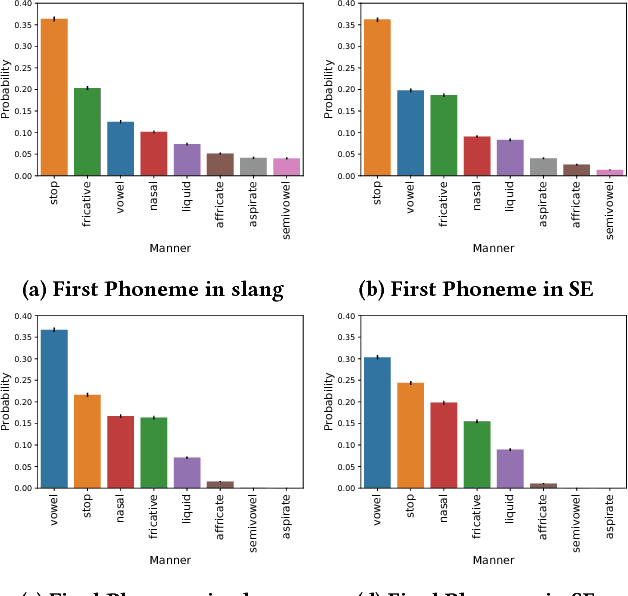
Slang is ubiquitous on the Internet. The emergence of new social contexts like micro-blogs, question-answering forums, and social networks has enabled slang and non-standard expressions to abound on the web. Despite this, slang has been traditionally viewed as a form of non-standard language -- a form of language that is not the focus of linguistic analysis and has largely been neglected. In this work, we use UrbanDictionary to conduct the first large-scale linguistic analysis of slang and its social aspects on the Internet to yield insights into this variety of language that is increasingly used all over the world online. We begin by computationally analyzing the phonological, morphological and syntactic properties of slang. We then study linguistic patterns in four specific categories of slang namely alphabetisms, blends, clippings, and reduplicatives. Our analysis reveals that slang demonstrates extra-grammatical rules of phonological and morphological formation that markedly distinguish it from the standard form shedding insight into its generative patterns. Next, we analyze the social aspects of slang by studying subject restriction and stereotyping in slang usage. Analyzing tens of thousands of such slang words reveals that the majority of slang on the Internet belongs to two major categories: sex and drugs. We also noted that not only is slang usage not immune to prevalent social biases and prejudices but also reflects such biases and stereotypes more intensely than the standard variety.
Latent Human Traits in the Language of Social Media: An Open-Vocabulary Approach
May 22, 2017
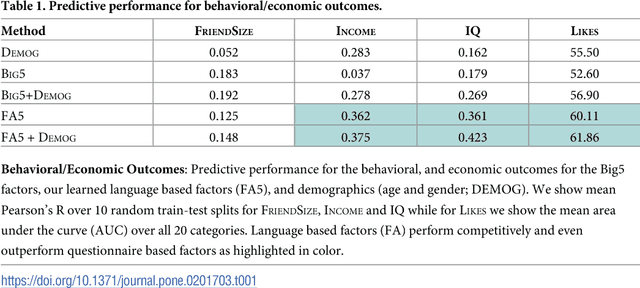
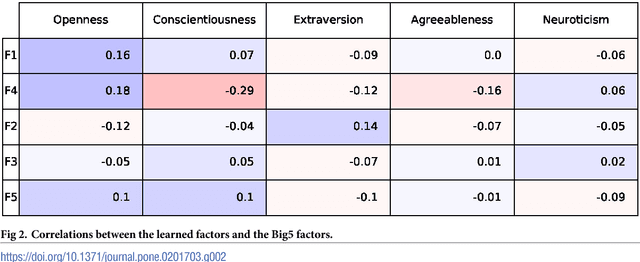

Over the past century, personality theory and research has successfully identified core sets of characteristics that consistently describe and explain fundamental differences in the way people think, feel and behave. Such characteristics were derived through theory, dictionary analyses, and survey research using explicit self-reports. The availability of social media data spanning millions of users now makes it possible to automatically derive characteristics from language use -- at large scale. Taking advantage of linguistic information available through Facebook, we study the process of inferring a new set of potential human traits based on unprompted language use. We subject these new traits to a comprehensive set of evaluations and compare them with a popular five factor model of personality. We find that our language-based trait construct is often more generalizable in that it often predicts non-questionnaire-based outcomes better than questionnaire-based traits (e.g. entities someone likes, income and intelligence quotient), while the factors remain nearly as stable as traditional factors. Our approach suggests a value in new constructs of personality derived from everyday human language use.
Data Centroid Based Multi-Level Fuzzy Min-Max Neural Network
Dec 20, 2016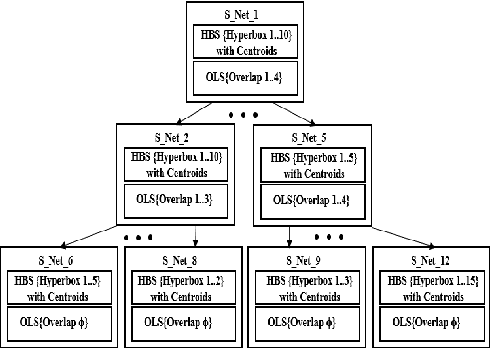
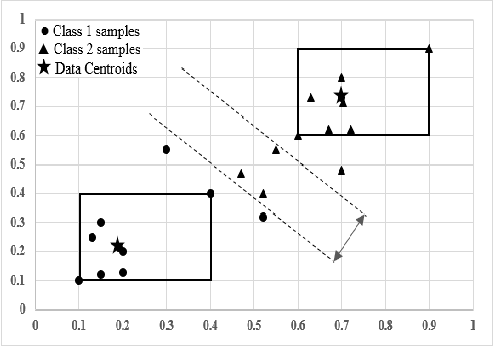
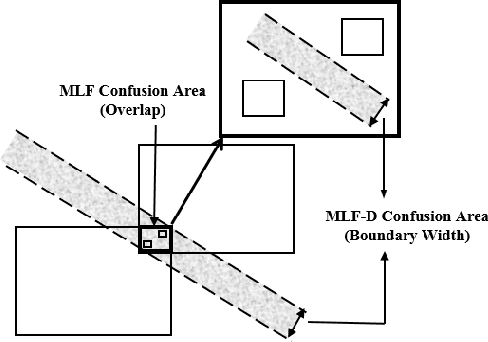
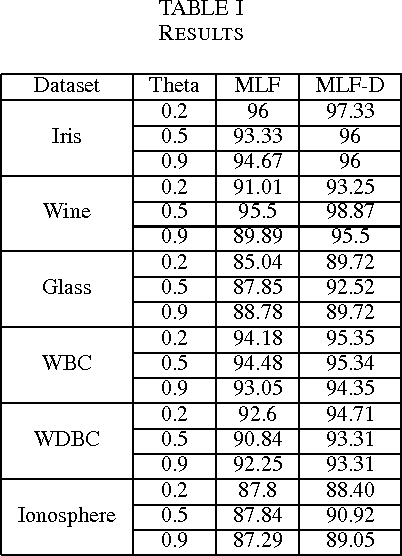
Recently, a multi-level fuzzy min max neural network (MLF) was proposed, which improves the classification accuracy by handling an overlapped region (area of confusion) with the help of a tree structure. In this brief, an extension of MLF is proposed which defines a new boundary region, where the previously proposed methods mark decisions with less confidence and hence misclassification is more frequent. A methodology to classify patterns more accurately is presented. Our work enhances the testing procedure by means of data centroids. We exhibit an illustrative example, clearly highlighting the advantage of our approach. Results on standard datasets are also presented to evidentially prove a consistent improvement in the classification rate.
Domain Adaptation for Named Entity Recognition in Online Media with Word Embeddings
Dec 01, 2016
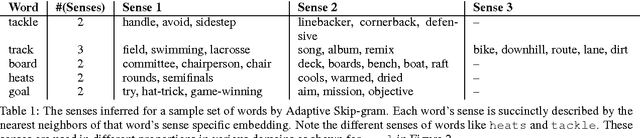
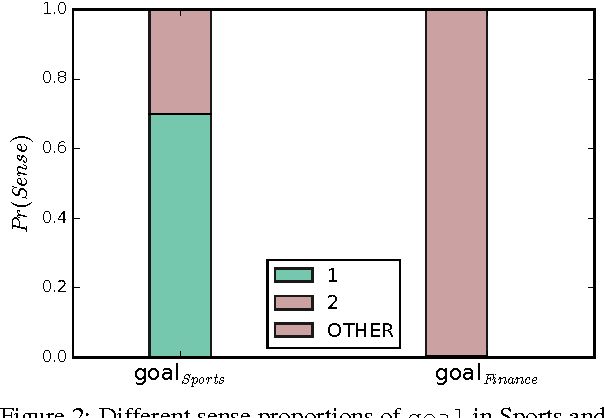

Content on the Internet is heterogeneous and arises from various domains like News, Entertainment, Finance and Technology. Understanding such content requires identifying named entities (persons, places and organizations) as one of the key steps. Traditionally Named Entity Recognition (NER) systems have been built using available annotated datasets (like CoNLL, MUC) and demonstrate excellent performance. However, these models fail to generalize onto other domains like Sports and Finance where conventions and language use can differ significantly. Furthermore, several domains do not have large amounts of annotated labeled data for training robust Named Entity Recognition models. A key step towards this challenge is to adapt models learned on domains where large amounts of annotated training data are available to domains with scarce annotated data. In this paper, we propose methods to effectively adapt models learned on one domain onto other domains using distributed word representations. First we analyze the linguistic variation present across domains to identify key linguistic insights that can boost performance across domains. We propose methods to capture domain specific semantics of word usage in addition to global semantics. We then demonstrate how to effectively use such domain specific knowledge to learn NER models that outperform previous baselines in the domain adaptation setting.
On the Convergent Properties of Word Embedding Methods
May 12, 2016
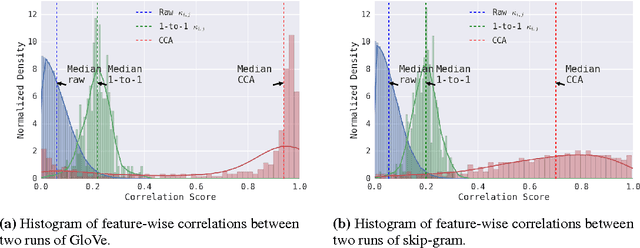
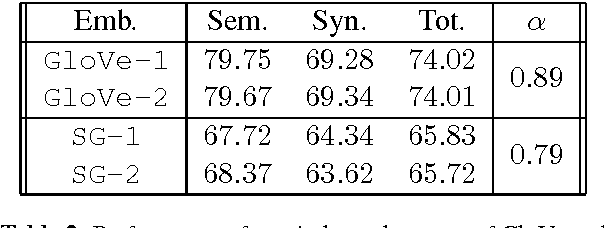
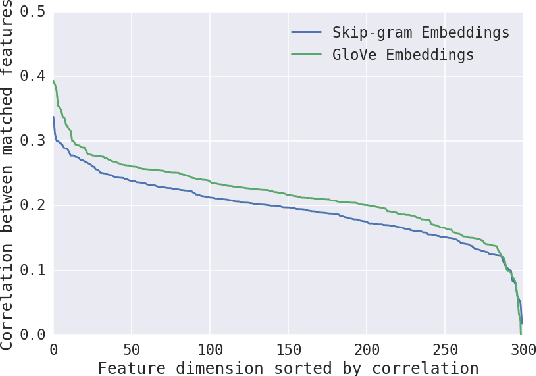
Do word embeddings converge to learn similar things over different initializations? How repeatable are experiments with word embeddings? Are all word embedding techniques equally reliable? In this paper we propose evaluating methods for learning word representations by their consistency across initializations. We propose a measure to quantify the similarity of the learned word representations under this setting (where they are subject to different random initializations). Our preliminary results illustrate that our metric not only measures a intrinsic property of word embedding methods but also correlates well with other evaluation metrics on downstream tasks. We believe our methods are is useful in characterizing robustness -- an important property to consider when developing new word embedding methods.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Freshman or Fresher? Quantifying the Geographic Variation of Internet Language
Mar 07, 2016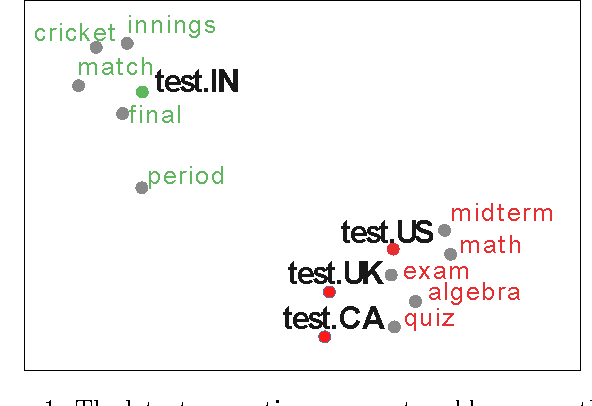

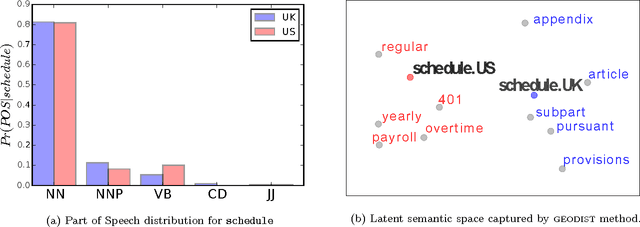
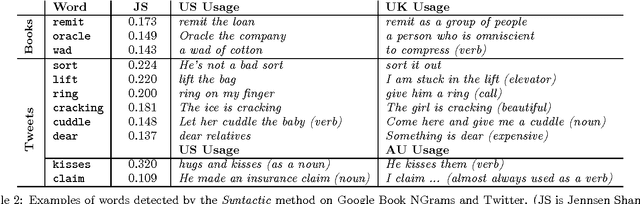
We present a new computational technique to detect and analyze statistically significant geographic variation in language. Our meta-analysis approach captures statistical properties of word usage across geographical regions and uses statistical methods to identify significant changes specific to regions. While previous approaches have primarily focused on lexical variation between regions, our method identifies words that demonstrate semantic and syntactic variation as well. We extend recently developed techniques for neural language models to learn word representations which capture differing semantics across geographical regions. In order to quantify this variation and ensure robust detection of true regional differences, we formulate a null model to determine whether observed changes are statistically significant. Our method is the first such approach to explicitly account for random variation due to chance while detecting regional variation in word meaning. To validate our model, we study and analyze two different massive online data sets: millions of tweets from Twitter spanning not only four different countries but also fifty states, as well as millions of phrases contained in the Google Book Ngrams. Our analysis reveals interesting facets of language change at multiple scales of geographic resolution -- from neighboring states to distant continents. Finally, using our model, we propose a measure of semantic distance between languages. Our analysis of British and American English over a period of 100 years reveals that semantic variation between these dialects is shrinking.
To Drop or Not to Drop: Robustness, Consistency and Differential Privacy Properties of Dropout
Mar 06, 2015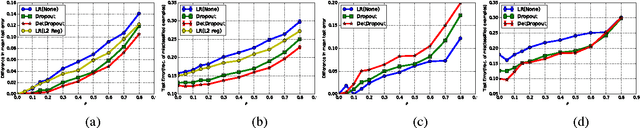
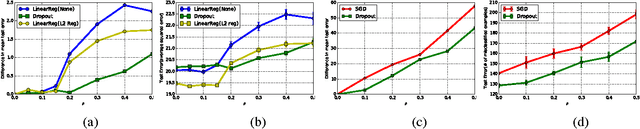
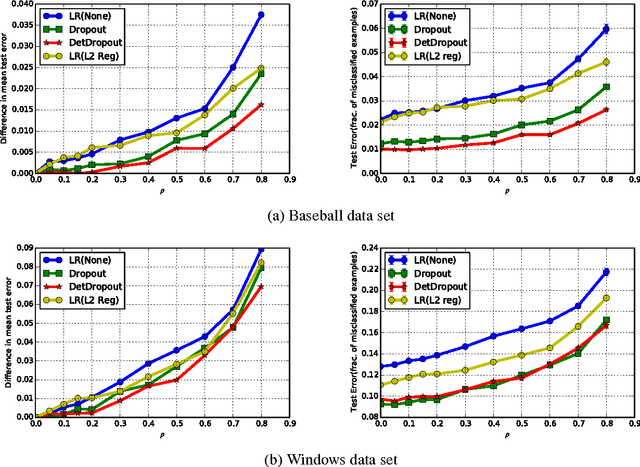
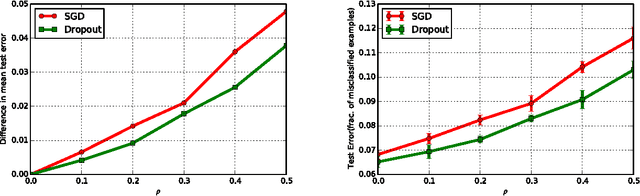
Training deep belief networks (DBNs) requires optimizing a non-convex function with an extremely large number of parameters. Naturally, existing gradient descent (GD) based methods are prone to arbitrarily poor local minima. In this paper, we rigorously show that such local minima can be avoided (upto an approximation error) by using the dropout technique, a widely used heuristic in this domain. In particular, we show that by randomly dropping a few nodes of a one-hidden layer neural network, the training objective function, up to a certain approximation error, decreases by a multiplicative factor. On the flip side, we show that for training convex empirical risk minimizers (ERM), dropout in fact acts as a "stabilizer" or regularizer. That is, a simple dropout based GD method for convex ERMs is stable in the face of arbitrary changes to any one of the training points. Using the above assertion, we show that dropout provides fast rates for generalization error in learning (convex) generalized linear models (GLM). Moreover, using the above mentioned stability properties of dropout, we design dropout based differentially private algorithms for solving ERMs. The learned GLM thus, preserves privacy of each of the individual training points while providing accurate predictions for new test points. Finally, we empirically validate our stability assertions for dropout in the context of convex ERMs and show that surprisingly, dropout significantly outperforms (in terms of prediction accuracy) the L2 regularization based methods for several benchmark datasets.
Statistically Significant Detection of Linguistic Change
Nov 12, 2014

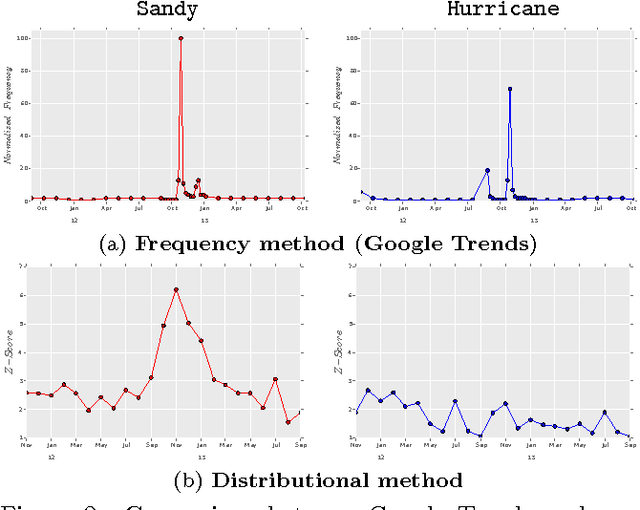
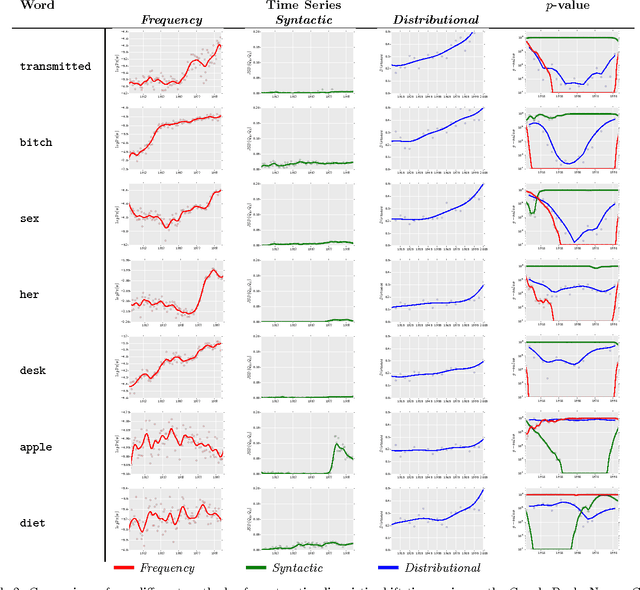
We propose a new computational approach for tracking and detecting statistically significant linguistic shifts in the meaning and usage of words. Such linguistic shifts are especially prevalent on the Internet, where the rapid exchange of ideas can quickly change a word's meaning. Our meta-analysis approach constructs property time series of word usage, and then uses statistically sound change point detection algorithms to identify significant linguistic shifts. We consider and analyze three approaches of increasing complexity to generate such linguistic property time series, the culmination of which uses distributional characteristics inferred from word co-occurrences. Using recently proposed deep neural language models, we first train vector representations of words for each time period. Second, we warp the vector spaces into one unified coordinate system. Finally, we construct a distance-based distributional time series for each word to track it's linguistic displacement over time. We demonstrate that our approach is scalable by tracking linguistic change across years of micro-blogging using Twitter, a decade of product reviews using a corpus of movie reviews from Amazon, and a century of written books using the Google Book-ngrams. Our analysis reveals interesting patterns of language usage change commensurate with each medium.
POLYGLOT-NER: Massive Multilingual Named Entity Recognition
Oct 14, 2014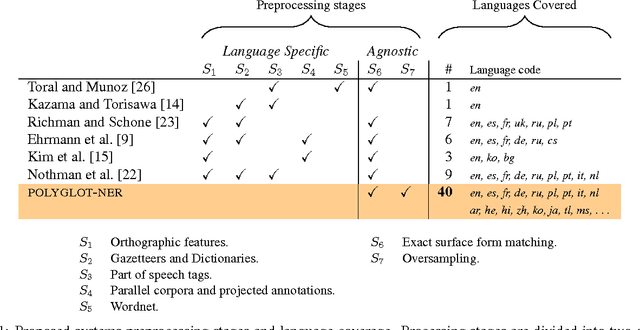
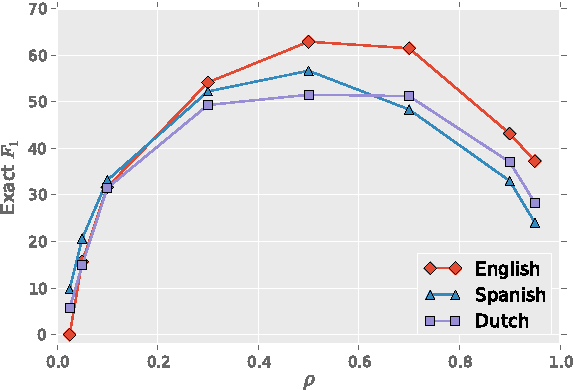
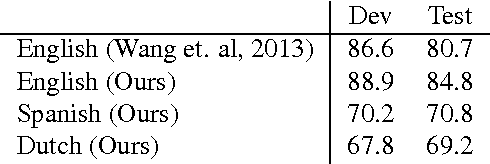
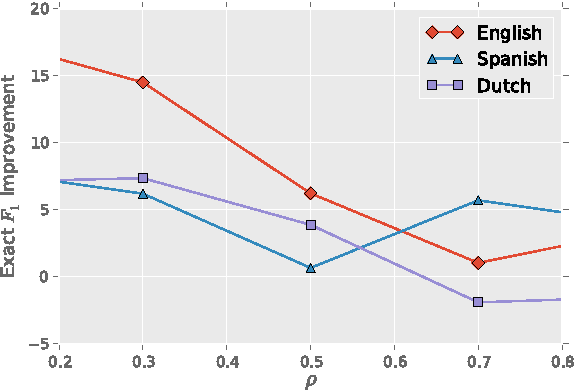
The increasing diversity of languages used on the web introduces a new level of complexity to Information Retrieval (IR) systems. We can no longer assume that textual content is written in one language or even the same language family. In this paper, we demonstrate how to build massive multilingual annotators with minimal human expertise and intervention. We describe a system that builds Named Entity Recognition (NER) annotators for 40 major languages using Wikipedia and Freebase. Our approach does not require NER human annotated datasets or language specific resources like treebanks, parallel corpora, and orthographic rules. The novelty of approach lies therein - using only language agnostic techniques, while achieving competitive performance. Our method learns distributed word representations (word embeddings) which encode semantic and syntactic features of words in each language. Then, we automatically generate datasets from Wikipedia link structure and Freebase attributes. Finally, we apply two preprocessing stages (oversampling and exact surface form matching) which do not require any linguistic expertise. Our evaluation is two fold: First, we demonstrate the system performance on human annotated datasets. Second, for languages where no gold-standard benchmarks are available, we propose a new method, distant evaluation, based on statistical machine translation.