 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Without Forgetting: Adaptation of YOLOv8 Preserves COCO Performance
May 02, 2025The success of large pre-trained object detectors hinges on their adaptability to diverse downstream tasks. While fine-tuning is the standard adaptation method, specializing these models for challenging fine-grained domains necessitates careful consideration of feature granularity. The critical question remains: how deeply should the pre-trained backbone be fine-tuned to optimize for the specialized task without incurring catastrophic forgetting of the original general capabilities? Addressing this, we present a systematic empirical study evaluating the impact of fine-tuning depth. We adapt a standard YOLOv8n model to a custom, fine-grained fruit detection dataset by progressively unfreezing backbone layers (freeze points at layers 22, 15, and 10) and training. Performance was rigorously evaluated on both the target fruit dataset and, using a dual-head evaluation architecture, on the original COCO validation set. Our results demonstrate unequivocally that deeper fine-tuning (unfreezing down to layer 10) yields substantial performance gains (e.g., +10\% absolute mAP50) on the fine-grained fruit task compared to only training the head. Strikingly, this significant adaptation and specialization resulted in negligible performance degradation (<0.1\% absolute mAP difference) on the COCO benchmark across all tested freeze levels. We conclude that adapting mid-to-late backbone features is highly effective for fine-grained specialization. Critically, our results demonstrate this adaptation can be achieved without the commonly expected penalty of catastrophic forgetting, presenting a compelling case for exploring deeper fine-tuning strategies, particularly when targeting complex domains or when maximizing specialized performance is paramount.
ELSA: A Style Aligned Dataset for Emotionally Intelligent Language Generation
Apr 11, 2025Advancements in emotion aware language processing increasingly shape vital NLP applications ranging from conversational AI and affective computing to computational psychology and creative content generation. Existing emotion datasets either lack emotional granularity or fail to capture necessary stylistic diversity, limiting the advancement of effective emotion conditioned text generation systems. Seeking to bridge this crucial gap between granularity and style diversity, this paper introduces a novel systematically constructed dataset named ELSA Emotion and Language Style Alignment Dataset leveraging fine grained emotion taxonomies adapted from existing sources such as dair ai emotion dataset and GoEmotions taxonomy. This dataset comprises multiple emotionally nuanced variations of original sentences regenerated across distinct contextual styles such as conversational, formal, poetic, and narrative, using advanced Large Language Models LLMs. Rigorous computational evaluation using metrics such as perplexity, embedding variance, readability, lexical diversity, and semantic coherence measures validates the datasets emotional authenticity, linguistic fluency, and textual diversity. Comprehensive metric analyses affirm its potential to support deeper explorations into emotion conditioned style adaptive text generation. By enabling precision tuned emotionally nuanced language modeling, our dataset creates fertile ground for research on fine grained emotional control, prompt driven explanation, interpretability, and style adaptive expressive language generation with LLMs.
A Hierarchical Approach for Visual Storytelling Using Image Description
Sep 26, 2019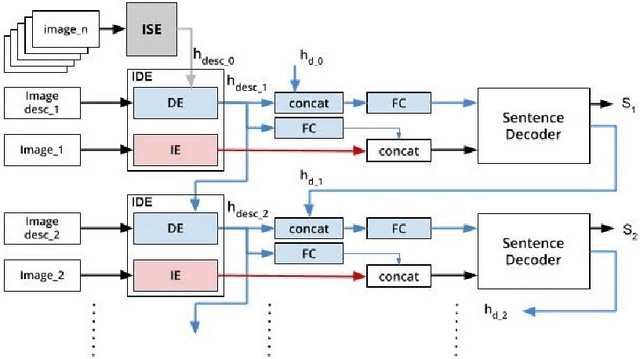
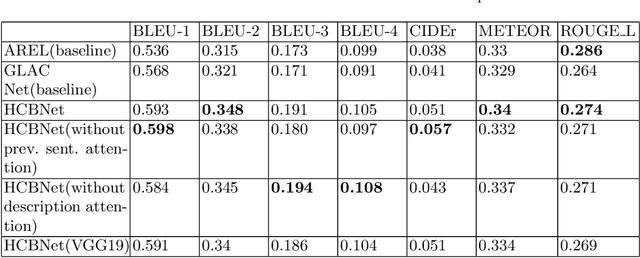
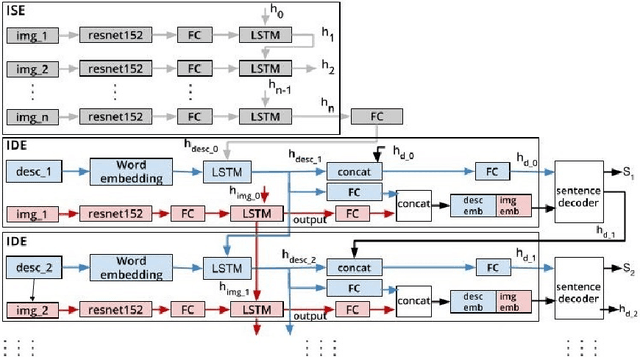
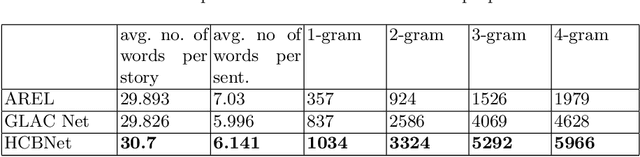
One of the primary challenges of visual storytelling is developing techniques that can maintain the context of the story over long event sequences to generate human-like stories. In this paper, we propose a hierarchical deep learning architecture based on encoder-decoder networks to address this problem. To better help our network maintain this context while also generating long and diverse sentences, we incorporate natural language image descriptions along with the images themselves to generate each story sentence. We evaluate our system on the Visual Storytelling (VIST) dataset and show that our method outperforms state-of-the-art techniques on a suite of different automatic evaluation metrics. The empirical results from this evaluation demonstrate the necessities of different components of our proposed architecture and shows the effectiveness of the architecture for visual storytelling.
Data Centroid Based Multi-Level Fuzzy Min-Max Neural Network
Dec 20, 2016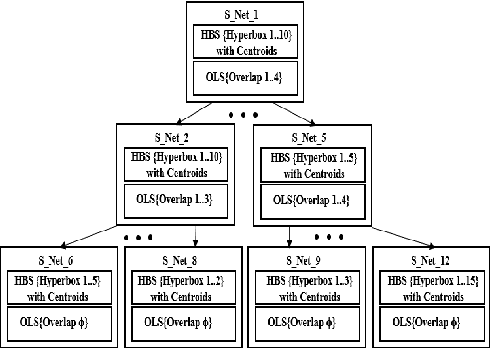
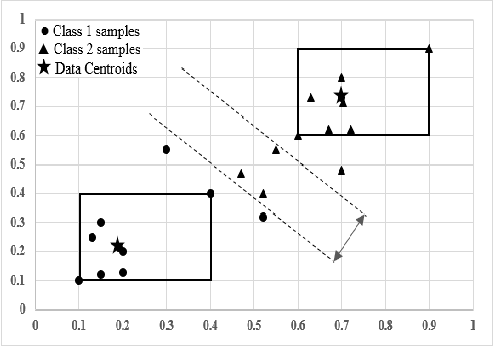
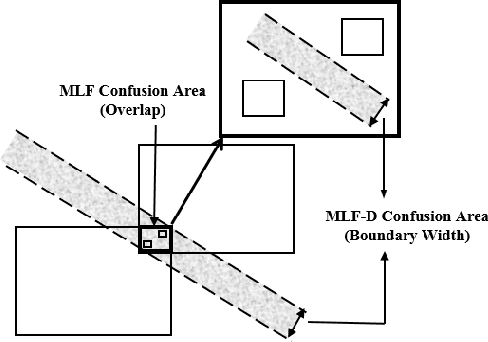
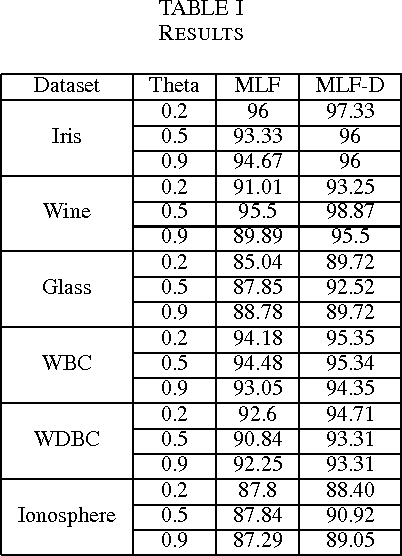
Recently, a multi-level fuzzy min max neural network (MLF) was proposed, which improves the classification accuracy by handling an overlapped region (area of confusion) with the help of a tree structure. In this brief, an extension of MLF is proposed which defines a new boundary region, where the previously proposed methods mark decisions with less confidence and hence misclassification is more frequent. A methodology to classify patterns more accurately is presented. Our work enhances the testing procedure by means of data centroids. We exhibit an illustrative example, clearly highlighting the advantage of our approach. Results on standard datasets are also presented to evidentially prove a consistent improvement in the classification rate.