 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Named Entity Recognition in Online Media with Word Embeddings
Dec 01, 2016
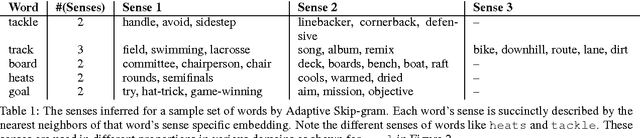
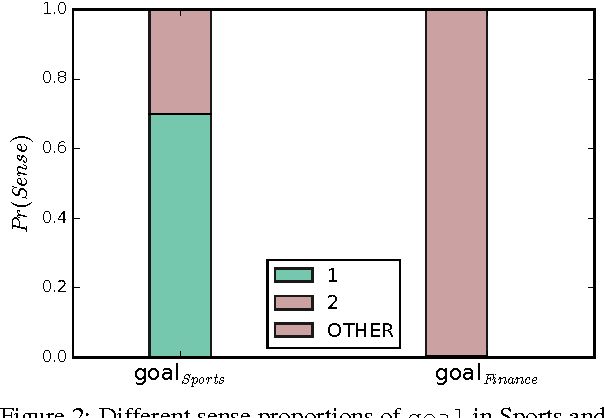

Content on the Internet is heterogeneous and arises from various domains like News, Entertainment, Finance and Technology. Understanding such content requires identifying named entities (persons, places and organizations) as one of the key steps. Traditionally Named Entity Recognition (NER) systems have been built using available annotated datasets (like CoNLL, MUC) and demonstrate excellent performance. However, these models fail to generalize onto other domains like Sports and Finance where conventions and language use can differ significantly. Furthermore, several domains do not have large amounts of annotated labeled data for training robust Named Entity Recognition models. A key step towards this challenge is to adapt models learned on domains where large amounts of annotated training data are available to domains with scarce annotated data. In this paper, we propose methods to effectively adapt models learned on one domain onto other domains using distributed word representations. First we analyze the linguistic variation present across domains to identify key linguistic insights that can boost performance across domains. We propose methods to capture domain specific semantics of word usage in addition to global semantics. We then demonstrate how to effectively use such domain specific knowledge to learn NER models that outperform previous baselines in the domain adaptation setting.
Noisy Inductive Matrix Completion Under Sparse Factor Models
Sep 13, 2016Inductive Matrix Completion (IMC) is an important class of matrix completion problems that allows direct inclusion of available features to enhance estimation capabilities. These models have found applications in personalized recommendation systems, multilabel learning, dictionary learning, etc. This paper examines a general class of noisy matrix completion tasks where the underlying matrix is following an IMC model i.e., it is formed by a mixing matrix (a priori unknown) sandwiched between two known feature matrices. The mixing matrix here is assumed to be well approximated by the product of two sparse matrices---referred here to as "sparse factor models." We leverage the main theorem of Soni:2016:NMC and extend it to provide theoretical error bounds for the sparsity-regularized maximum likelihood estimators for the class of problems discussed in this paper. The main result is general in the sense that it can be used to derive error bounds for various noise models. In this paper, we instantiate our main result for the case of Gaussian noise and provide corresponding error bounds in terms of squared loss.