 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Online Domain Adaptive Object Detection
Apr 11, 2022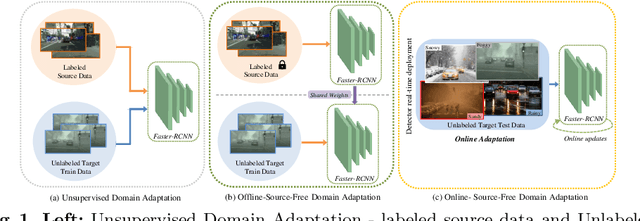
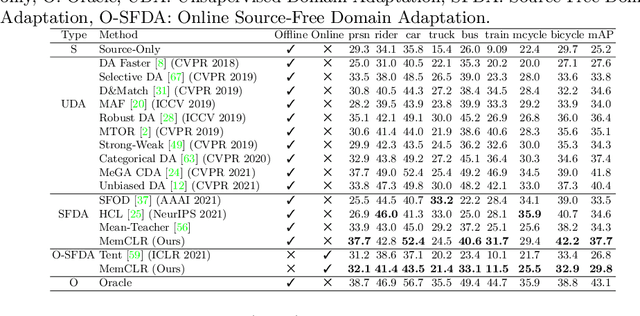
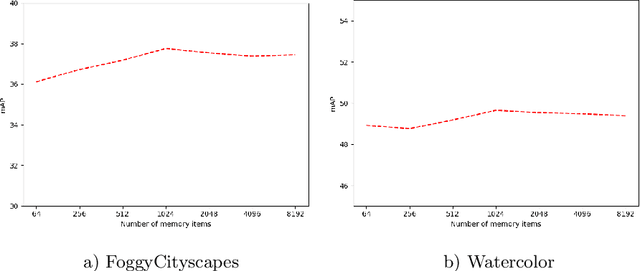
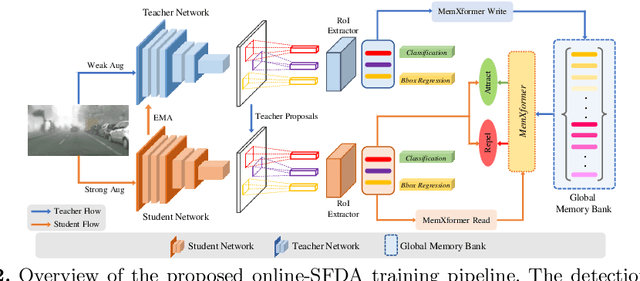
Existing object detection models assume both the training and test data are sampled from the same source domain. This assumption does not hold true when these detectors are deployed in real-world applications, where they encounter new visual domain. Unsupervised Domain Adaptation (UDA) methods are generally employed to mitigate the adverse effects caused by domain shift. Existing UDA methods operate in an offline manner where the model is first adapted towards the target domain and then deployed in real-world applications. However, this offline adaptation strategy is not suitable for real-world applications as the model frequently encounters new domain shifts. Hence, it becomes critical to develop a feasible UDA method that generalizes to these domain shifts encountered during deployment time in a continuous online manner. To this end, we propose a novel unified adaptation framework that adapts and improves generalization on the target domain in online settings. In particular, we introduce MemXformer - a cross-attention transformer-based memory module where items in the memory take advantage of domain shifts and record prototypical patterns of the target distribution. Further, MemXformer produces strong positive and negative pairs to guide a novel contrastive loss, which enhances target specific representation learning. Experiments on diverse detection benchmarks show that the proposed strategy can produce state-of-the-art performance in both online and offline settings. To the best of our knowledge, this is the first work to address online and offline adaptation settings for object detection. Code at https://github.com/Vibashan/online-od
Thermal to Visible Image Synthesis under Atmospheric Turbulence
Apr 06, 2022
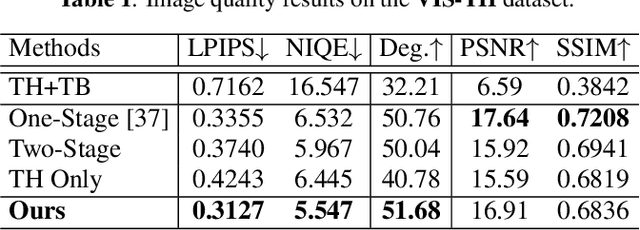
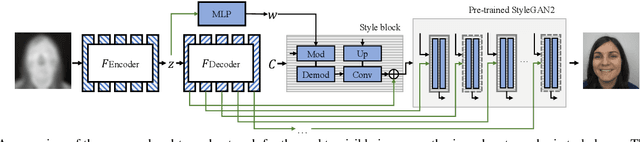
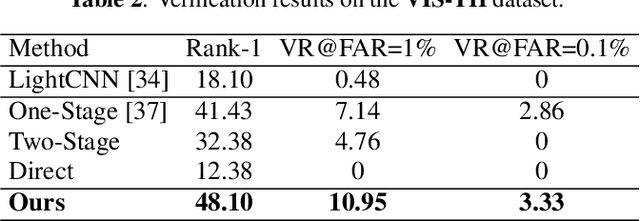
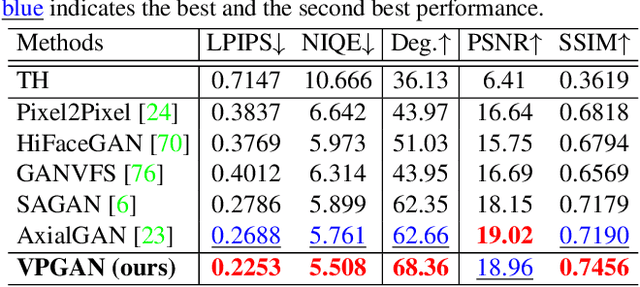
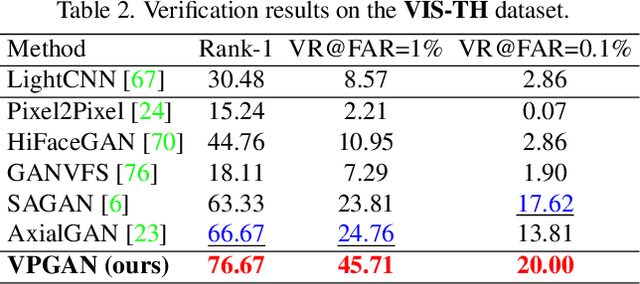
In many practical applications of long-range imaging such as biometrics and surveillance, thermal imagining modalities are often used to capture images in low-light and nighttime conditions. However, such imaging systems often suffer from atmospheric turbulence, which introduces severe blur and deformation artifacts to the captured images. Such an issue is unavoidable in long-range imaging and significantly decreases the face verification accuracy. In this paper, we first investigate the problem with a turbulence simulation method on real-world thermal images. An end-to-end reconstruction method is then proposed which can directly transform thermal images into visible-spectrum images by utilizing natural image priors based on a pre-trained StyleGAN2 network. Compared with the existing two-steps methods of consecutive turbulence mitigation and thermal to visible image translation, our method is demonstrated to be effective in terms of both the visual quality of the reconstructed results and face verification accuracy. Moreover, to the best of our knowledge, this is the first work that studies the problem of thermal to visible image translation under atmospheric turbulence.
Instance Relation Graph Guided Source-Free Domain Adaptive Object Detection
Apr 01, 2022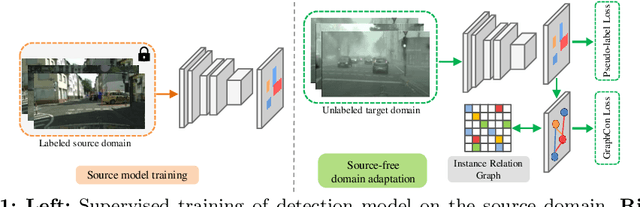
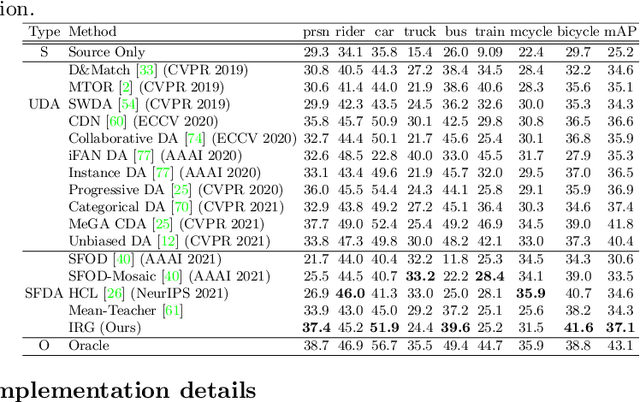
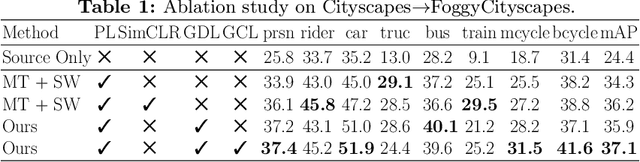
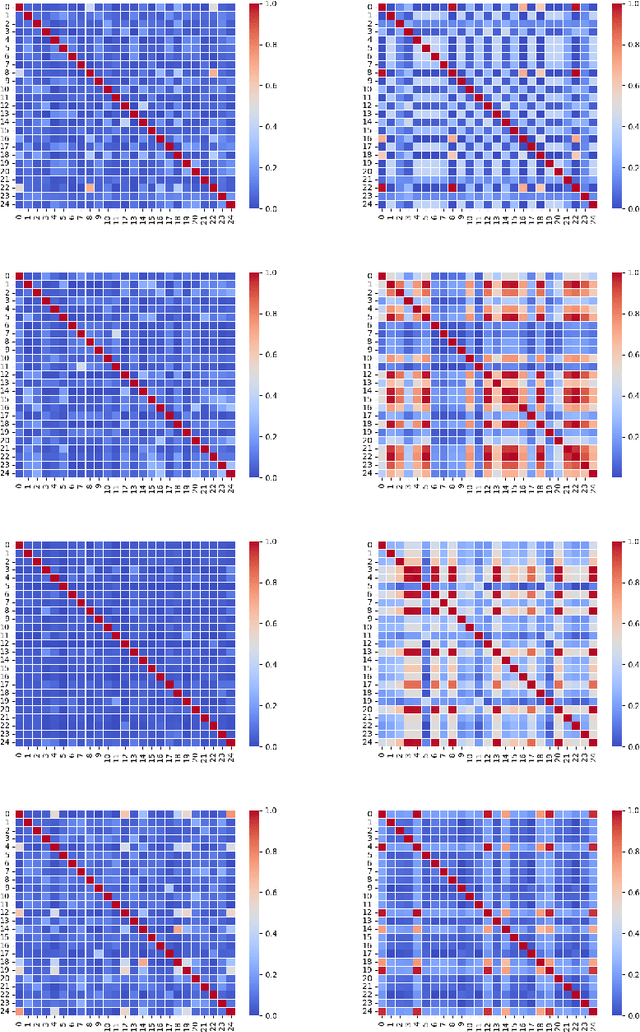
Unsupervised Domain Adaptation (UDA) is an effective approach to tackle the issue of domain shift. Specifically, UDA methods try to align the source and target representations to improve the generalization on the target domain. Further, UDA methods work under the assumption that the source data is accessible during the adaptation process. However, in real-world scenarios, the labelled source data is often restricted due to privacy regulations, data transmission constraints, or proprietary data concerns. The Source-Free Domain Adaptation (SFDA) setting aims to alleviate these concerns by adapting a source-trained model for the target domain without requiring access to the source data. In this paper, we explore the SFDA setting for the task of adaptive object detection. To this end, we propose a novel training strategy for adapting a source-trained object detector to the target domain without source data. More precisely, we design a novel contrastive loss to enhance the target representations by exploiting the objects relations for a given target domain input. These object instance relations are modelled using an Instance Relation Graph (IRG) network, which are then used to guide the contrastive representation learning. In addition, we utilize a student-teacher based knowledge distillation strategy to avoid overfitting to the noisy pseudo-labels generated by the source-trained model. Extensive experiments on multiple object detection benchmark datasets show that the proposed approach is able to efficiently adapt source-trained object detectors to the target domain, outperforming previous state-of-the-art domain adaptive detection methods. Code is available at https://github.com/Vibashan/irg-sfda.
Escaping Data Scarcity for High-Resolution Heterogeneous Face Hallucination
Mar 30, 2022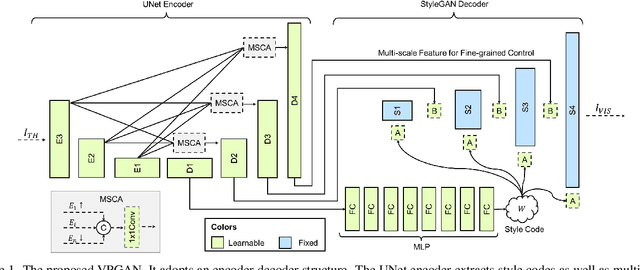
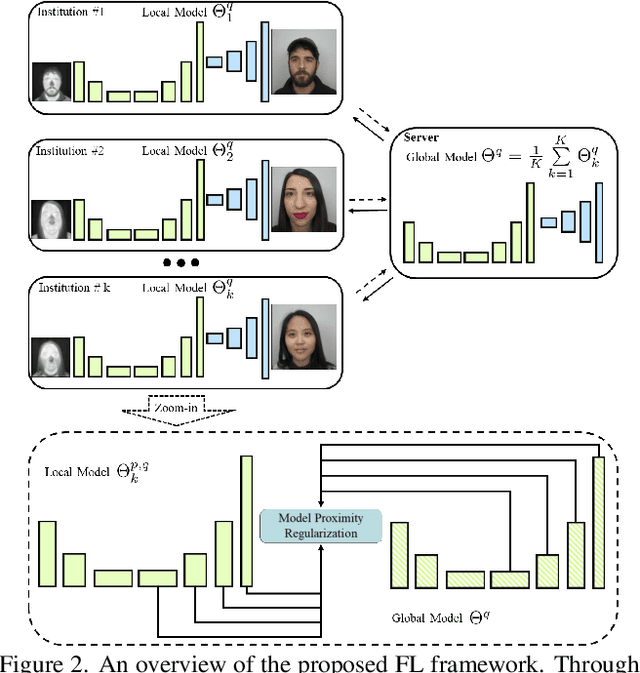
In Heterogeneous Face Recognition (HFR), the objective is to match faces across two different domains such as visible and thermal. Large domain discrepancy makes HFR a difficult problem. Recent methods attempting to fill the gap via synthesis have achieved promising results, but their performance is still limited by the scarcity of paired training data. In practice, large-scale heterogeneous face data are often inaccessible due to the high cost of acquisition and annotation process as well as privacy regulations. In this paper, we propose a new face hallucination paradigm for HFR, which not only enables data-efficient synthesis but also allows to scale up model training without breaking any privacy policy. Unlike existing methods that learn face synthesis entirely from scratch, our approach is particularly designed to take advantage of rich and diverse facial priors from visible domain for more faithful hallucination. On the other hand, large-scale training is enabled by introducing a new federated learning scheme to allow institution-wise collaborations while avoiding explicit data sharing. Extensive experiments demonstrate the advantages of our approach in tackling HFR under current data limitations. In a unified framework, our method yields the state-of-the-art hallucination results on multiple HFR datasets.
Target and Task specific Source-Free Domain Adaptive Image Segmentation
Mar 29, 2022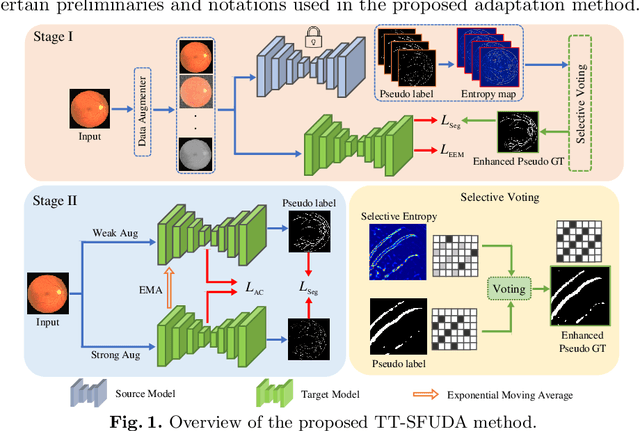
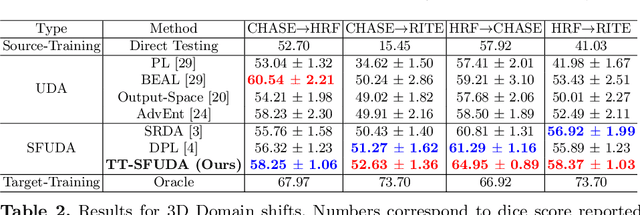

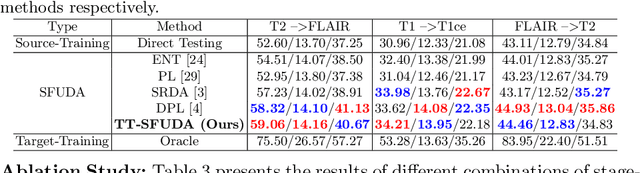
Solving the domain shift problem during inference is essential in medical imaging as most deep-learning based solutions suffer from it. In practice, domain shifts are tackled by performing Unsupervised Domain Adaptation (UDA), where a model is adapted to an unlabeled target domain by leveraging the labelled source domain. In medical scenarios, the data comes with huge privacy concerns making it difficult to apply standard UDA techniques. Hence, a closer clinical setting is Source-Free UDA (SFUDA), where we have access to source trained model but not the source data during adaptation. Methods trying to solve SFUDA typically address the domain shift using pseudo-label based self-training techniques. However, due to domain shift, these pseudo-labels are usually of high entropy and denoising them still does not make them perfect labels to supervise the model. Therefore, adapting the source model with noisy pseudo labels reduces its segmentation capability while addressing the domain shift. To this end, we propose a two-stage approach for source-free domain adaptive image segmentation: 1) Target-specific adaptation followed by 2) Task-specific adaptation. In the first stage, we focus on generating target-specific pseudo labels while suppressing high entropy regions by proposing an Ensemble Entropy Minimization loss. We also introduce a selective voting strategy to enhance pseudo-label generation. In the second stage, we focus on adapting the network for task-specific representation by using a teacher-student self-training approach based on augmentation-guided consistency. We evaluate our proposed method on both 2D fundus datasets and 3D MRI volumes across 7 different domain shifts where we achieve better performance than recent UDA and SF-UDA methods for medical image segmentation. Code is available at https://github.com/Vibashan/tt-sfuda.
HyperTransformer: A Textural and Spectral Feature Fusion Transformer for Pansharpening
Mar 28, 2022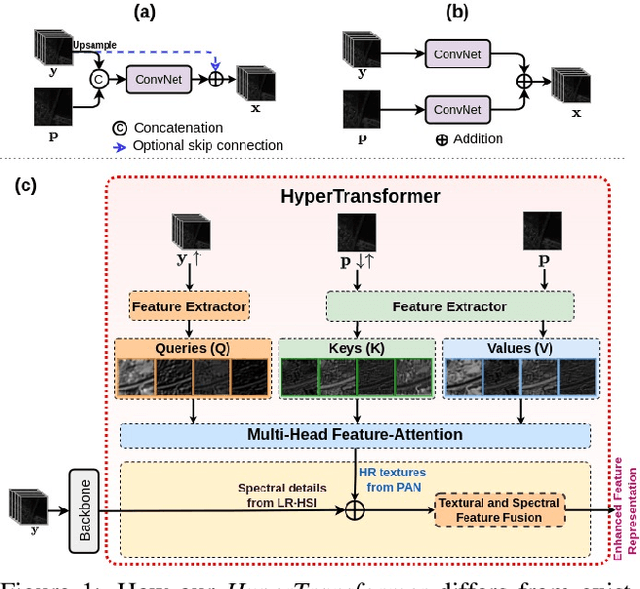
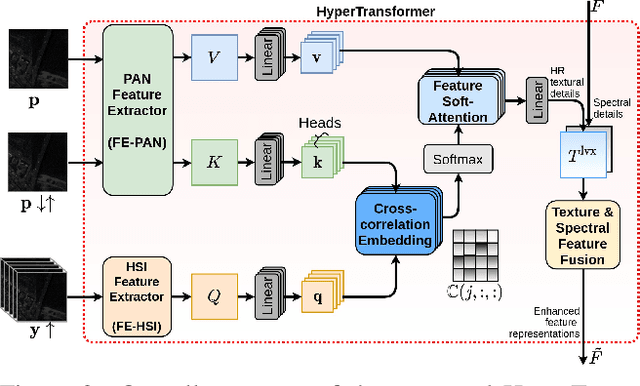
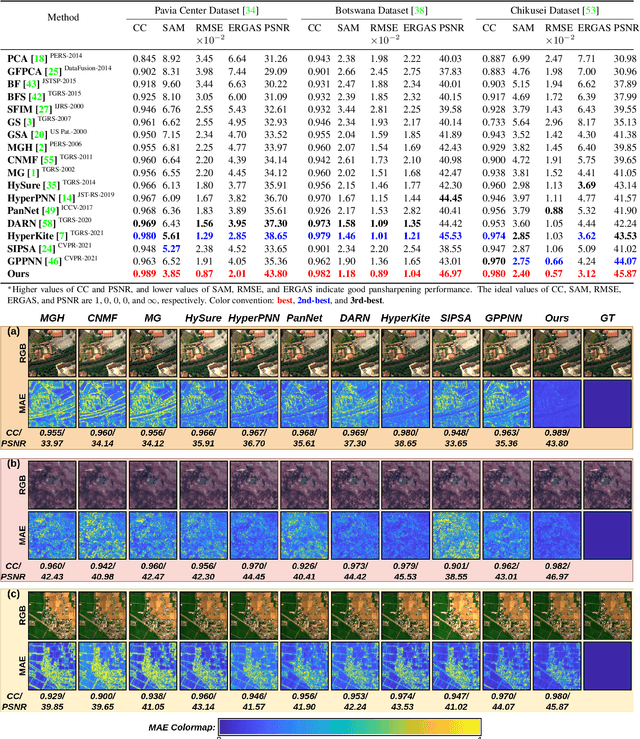
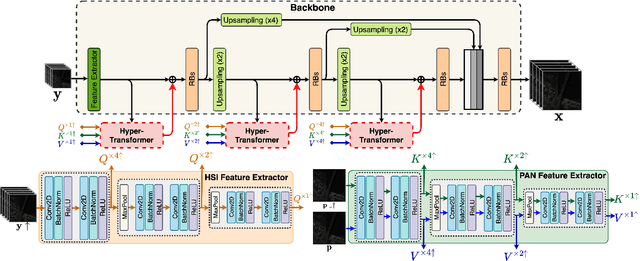
Pansharpening aims to fuse a registered high-resolution panchromatic image (PAN) with a low-resolution hyperspectral image (LR-HSI) to generate an enhanced HSI with high spectral and spatial resolution. Existing pansharpening approaches neglect using an attention mechanism to transfer HR texture features from PAN to LR-HSI features, resulting in spatial and spectral distortions. In this paper, we present a novel attention mechanism for pansharpening called HyperTransformer, in which features of LR-HSI and PAN are formulated as queries and keys in a transformer, respectively. HyperTransformer consists of three main modules, namely two separate feature extractors for PAN and HSI, a multi-head feature soft attention module, and a spatial-spectral feature fusion module. Such a network improves both spatial and spectral quality measures of the pansharpened HSI by learning cross-feature space dependencies and long-range details of PAN and LR-HSI. Furthermore, HyperTransformer can be utilized across multiple spatial scales at the backbone for obtaining improved performance. Extensive experiments conducted on three widely used datasets demonstrate that HyperTransformer achieves significant improvement over the state-of-the-art methods on both spatial and spectral quality measures. Implementation code and pre-trained weights can be accessed at https://github.com/wgcban/HyperTransformer.
Interactive Portrait Harmonization
Mar 15, 2022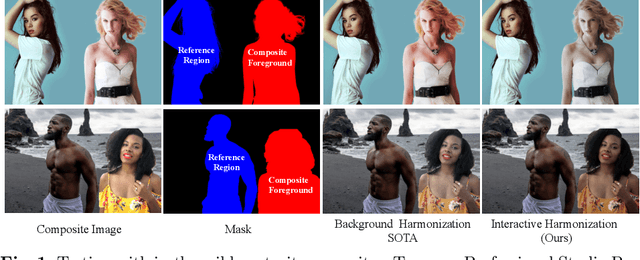
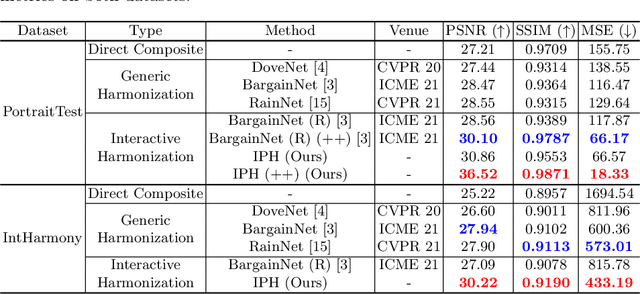

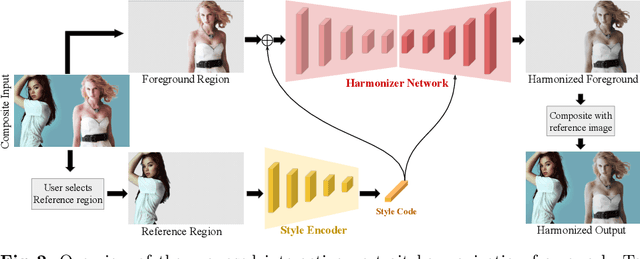
Current image harmonization methods consider the entire background as the guidance for harmonization. However, this may limit the capability for user to choose any specific object/person in the background to guide the harmonization. To enable flexible interaction between user and harmonization, we introduce interactive harmonization, a new setting where the harmonization is performed with respect to a selected \emph{region} in the reference image instead of the entire background. A new flexible framework that allows users to pick certain regions of the background image and use it to guide the harmonization is proposed. Inspired by professional portrait harmonization users, we also introduce a new luminance matching loss to optimally match the color/luminance conditions between the composite foreground and select reference region. This framework provides more control to the image harmonization pipeline achieving visually pleasing portrait edits. Furthermore, we also introduce a new dataset carefully curated for validating portrait harmonization. Extensive experiments on both synthetic and real-world datasets show that the proposed approach is efficient and robust compared to previous harmonization baselines, especially for portraits. Project Webpage at \href{https://jeya-maria-jose.github.io/IPH-web/}{https://jeya-maria-jose.github.io/IPH-web/}
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022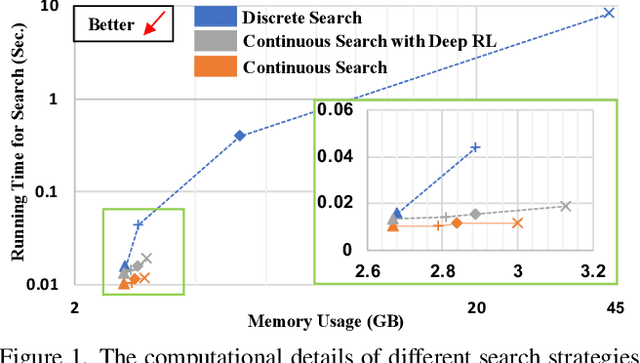

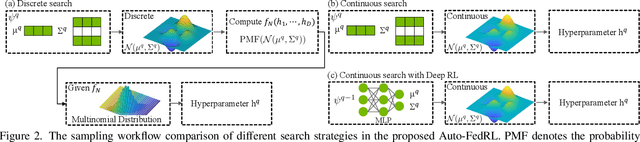

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
On-the-Fly Test-time Adaptation for Medical Image Segmentation
Mar 10, 2022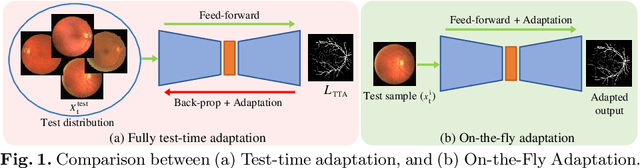

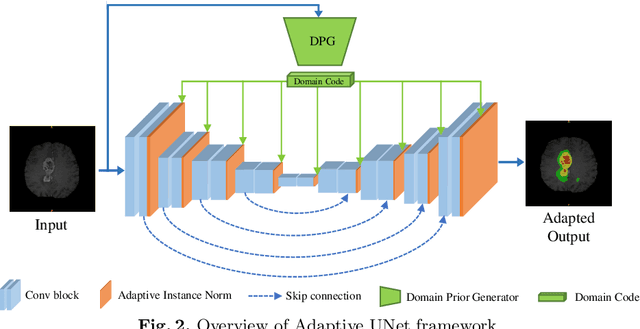
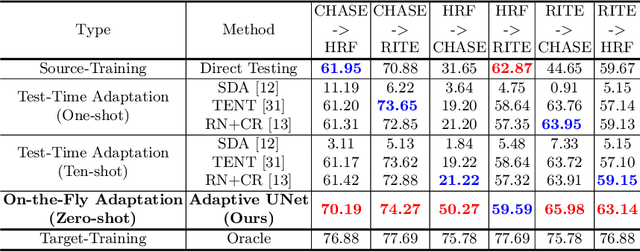
One major problem in deep learning-based solutions for medical imaging is the drop in performance when a model is tested on a data distribution different from the one that it is trained on. Adapting the source model to target data distribution at test-time is an efficient solution for the data-shift problem. Previous methods solve this by adapting the model to target distribution by using techniques like entropy minimization or regularization. In these methods, the models are still updated by back-propagation using an unsupervised loss on complete test data distribution. In real-world clinical settings, it makes more sense to adapt a model to a new test image on-the-fly and avoid model update during inference due to privacy concerns and lack of computing resource at deployment. To this end, we propose a new setting - On-the-Fly Adaptation which is zero-shot and episodic (i.e., the model is adapted to a single image at a time and also does not perform any back-propagation during test-time). To achieve this, we propose a new framework called Adaptive UNet where each convolutional block is equipped with an adaptive batch normalization layer to adapt the features with respect to a domain code. The domain code is generated using a pre-trained encoder trained on a large corpus of medical images. During test-time, the model takes in just the new test image and generates a domain code to adapt the features of source model according to the test data. We validate the performance on both 2D and 3D data distribution shifts where we get a better performance compared to previous test-time adaptation methods. Code is available at https://github.com/jeya-maria-jose/On-The-Fly-Adaptation
UNeXt: MLP-based Rapid Medical Image Segmentation Network
Mar 09, 2022
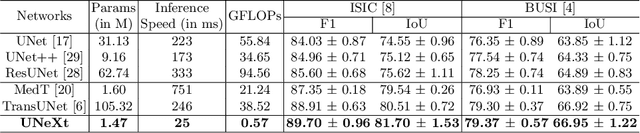
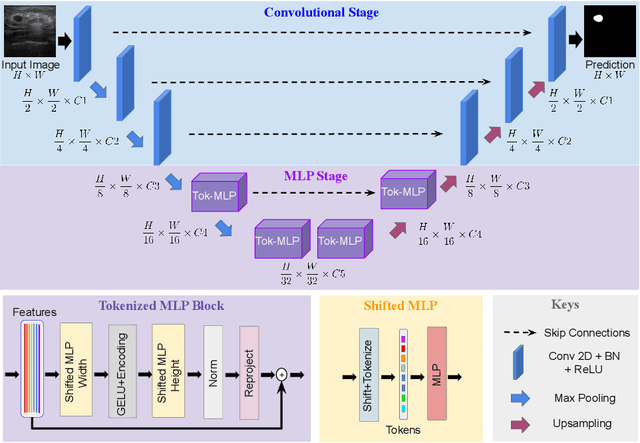
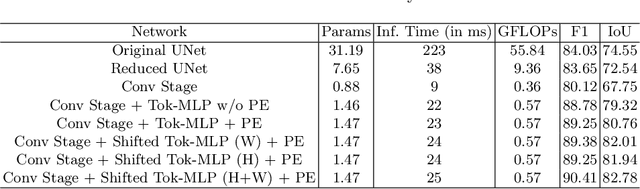
UNet and its latest extensions like TransUNet have been the leading medical image segmentation methods in recent years. However, these networks cannot be effectively adopted for rapid image segmentation in point-of-care applications as they are parameter-heavy, computationally complex and slow to use. To this end, we propose UNeXt which is a Convolutional multilayer perceptron (MLP) based network for image segmentation. We design UNeXt in an effective way with an early convolutional stage and a MLP stage in the latent stage. We propose a tokenized MLP block where we efficiently tokenize and project the convolutional features and use MLPs to model the representation. To further boost the performance, we propose shifting the channels of the inputs while feeding in to MLPs so as to focus on learning local dependencies. Using tokenized MLPs in latent space reduces the number of parameters and computational complexity while being able to result in a better representation to help segmentation. The network also consists of skip connections between various levels of encoder and decoder. We test UNeXt on multiple medical image segmentation datasets and show that we reduce the number of parameters by 72x, decrease the computational complexity by 68x, and improve the inference speed by 10x while also obtaining better segmentation performance over the state-of-the-art medical image segmentation architectures. Code is available at https://github.com/jeya-maria-jose/UNeXt-pytorch